一、键控状态
键控状态是根据输入数据流中定义的键(key)来维护和访问的。
Flink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。
二、ValueState
保存单个值. 每个key有一个状态值. 设置使用 update(T), 获取使用 T value()
案例:
检测传感器的水位值,如果连续的两个水位值超过10,就输出报警
package com.lyh.flink09;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class key_Value {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] datas = line.split(",");
return new WaterSensor(
datas[0],
Long.valueOf(datas[1]),
Integer.valueOf(datas[2]));
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private ValueState<Integer> lastValueState;
@Override
public void open(Configuration parameters) throws Exception {
lastValueState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("ValueState",Integer.class));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
Integer lastVc = lastValueState.value();
if (lastVc != null) {
if (lastVc > 10 && value.getVc()>10) {
out.collect(ctx.getCurrentKey() + "连续两次超越告警值。。。。");
}
}
lastValueState.update(value.getVc());
}
}).print();
env.execute();
}
}
三、ListState
针对每个传感器输出最高的3个水位值
package com.lyh.flink09;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
public class key_List {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("hadoop100",9999)
.map(line ->{
String[] datas = line.split(",");
return new WaterSensor(
datas[0],
Long.valueOf(datas[1]),
Integer.valueOf(datas[2])
);
}).keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, List<Integer>>() {
private ListState<Integer> top3Vc;
@Override
public void open(Configuration parameters) throws Exception {
top3Vc = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("top3Vc", Integer.class));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<List<Integer>> out) throws Exception {
top3Vc.add(value.getVc());
Iterable<Integer> it = top3Vc.get();
List<Integer> vcs = new ArrayList<>();
for (Integer vc : top3Vc.get()) {
vcs.add(vc);
}
vcs.sort((o1,o2)->o2-o1);
if (vcs.size()>3) {
vcs.remove(3);
}
top3Vc.update(vcs);
out.collect(vcs);
}
}).print();
env.execute();
}
}
运行结果:
2> [11]
2> [11, 1]
2> [11, 1, 1]
2> [100, 11, 1]
2> [1000, 100, 11]
2> [1000, 100, 99]
2> [1000, 100, 99]
四、ReducingState
计算每个传感器的水位和
package com.lyh.flink09;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class key_Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("hadoop100",9999)
.map(line -> {
String[] datas = line.split(",");
return new WaterSensor(
datas[0],
Long.valueOf(datas[1]),
Integer.valueOf(datas[2]));
}).keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, Integer>() {
private ReducingState<Integer> vcstate;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
vcstate = getRuntimeContext().getReducingState(new ReducingStateDescriptor<Integer>(
"vcstate",
Integer::sum,
Integer.class));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<Integer> out) throws Exception {
vcstate.add(value.getVc());
out.collect(vcstate.get());
}
}).print();
env.execute();
}
}
运行:
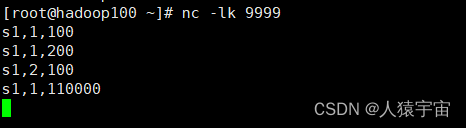
运行结果:

五、AggregatingState
计算每个传感器的平均水位
package com.lyh.flink09;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class key_Agg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("hadoop100",9999)
.map(line ->{
String[] datas = line.split(",");
return new WaterSensor(
datas[0],
Long.valueOf(datas[1]),
Integer.valueOf(datas[2])
);
}).keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, Double>() {
private AggregatingState<Integer, Double> avgState;
@Override
public void open(Configuration parameters) throws Exception {
AggregatingStateDescriptor<Integer, Tuple2<Integer, Integer>, Double>
Avg = new AggregatingStateDescriptor<>(
"Avg",
new AggregateFunction<Integer,
Tuple2<Integer, Integer>,
Double>() {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0,0);
}
@Override
public Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> integerTuple2) {
return Tuple2.of(integerTuple2.f0 + value,integerTuple2.f1 + 1);
}
@Override
public Double getResult(Tuple2<Integer, Integer> integerTuple2) {
return integerTuple2.f0*1D/integerTuple2.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
return Tuple2.of(a.f0 + b.f0 , a.f1 + b.f1);
}
}, Types.TUPLE(Types.INT,Types.INT));
avgState = getRuntimeContext().getAggregatingState(Avg);
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<Double> out) throws Exception {
avgState.add(value.getVc());
out.collect(avgState.get());
}
}).print();
env.execute();
}
}
运行:

结果:
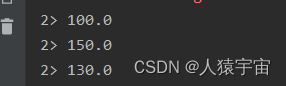
六、MapState
去重: 去掉重复的水位值. 思路: 把水位值作为MapState的key来实现去重, value随意
package com.lyh.flink09;
import com.lyh.bean.WaterSensor;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
public class key_Map {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("hadoop100",9999)
.map(line ->{
String[] datas = line.split(",");
return new WaterSensor (
datas[0],
Long.valueOf(datas[1]),
Integer.valueOf(datas[2]));
}).keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, WaterSensor>() {
private MapState<Integer, String> mapState;
@Override
public void open(Configuration parameters) throws Exception {
mapState = this.getRuntimeContext().getMapState(new MapStateDescriptor<Integer, String>("mapState", Integer.class, String.class));
}
@Override
public void processElement(WaterSensor values,
Context ctx,
Collector<WaterSensor> out) throws Exception {
if (!mapState.contains(values.getVc())) {
out.collect(values);
mapState.put(values.getVc(),"随意");
}
}
}).print();
env.execute();
}
}
运行:

结果: