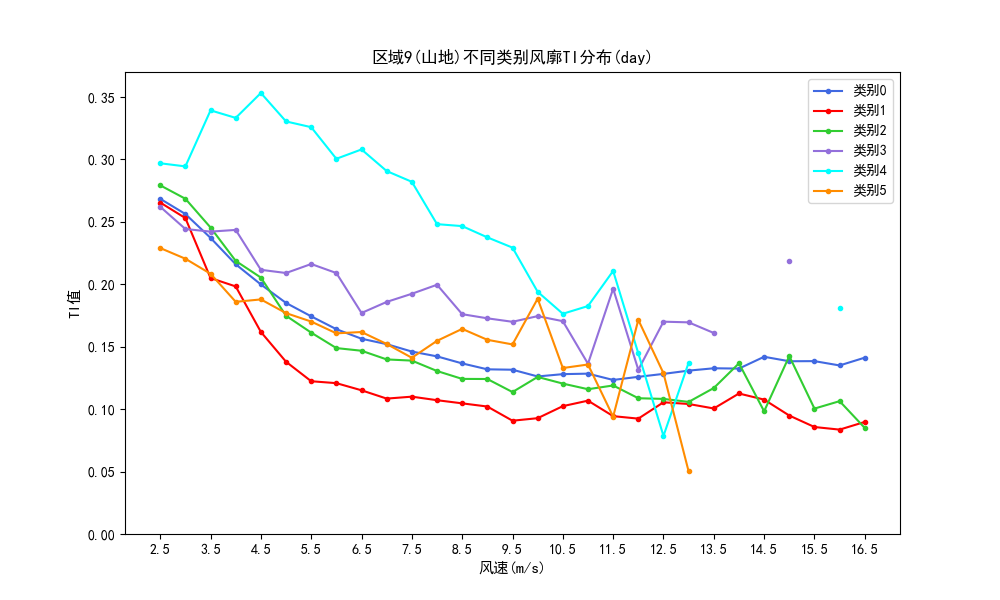
一个关于时延统计分布的小测试,用 netem delay jitter distribution pareto 模拟,得到下面的结果:
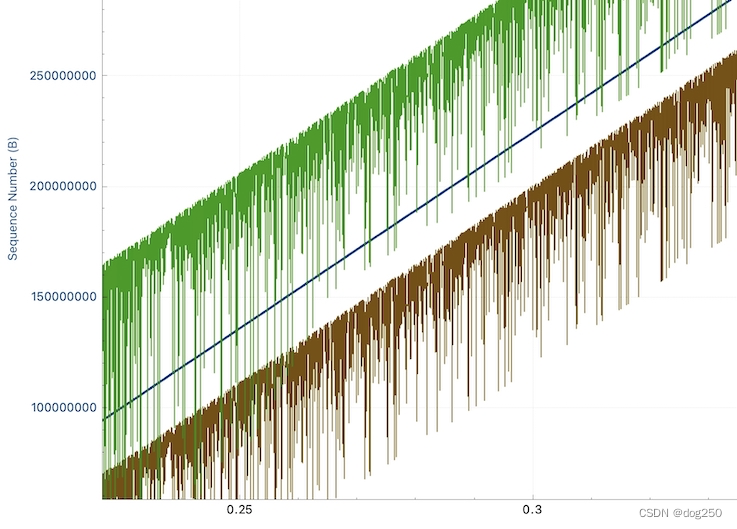
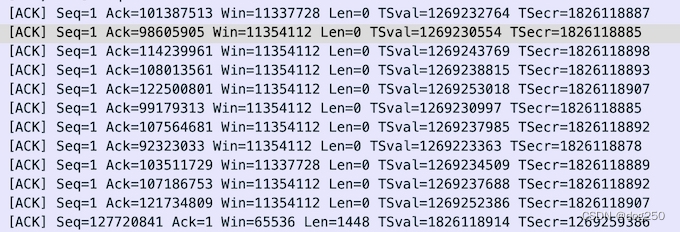
netem 的 jitter 并不是真 jitter,只是通过延时阻滞部分报文模拟 jitter,对保序流而言,就表现为乱序,如下图所示,通过 ack 号和时间戳均能看出:
netem 的局限有目共睹,这里不纠结。问题是,如果现实中真的发生 ack 乱序会怎样。
Linux kernel TCP 单独处理了 old_ack:
if (before(ack, prior_snd_una)) {
goto old_ack;
}
...
old_ack:
/* If data was SACKed, tag it and see if we should send more data.
* If data was DSACKed, see if we can undo a cwnd reduction.
*/
if (TCP_SKB_CB(skb)->sacked) {
flag |= tcp_sacktag_write_queue(sk, skb, prior_snd_una,
&sack_state);
tcp_fastretrans_alert(sk, prior_snd_una, num_dupack, &flag,
&rexmit);
tcp_newly_delivered(sk, delivered, flag);
tcp_xmit_recovery(sk, rexmit);
}
return 0;
注意 tcp_sacktag_write_queue 调用,它会将 sack_block in old_ack 累加到当前 tp->delivered 字段,累加过去的 sack_block 会过估当前 delivery rate。
这是一个明确的 ack 乱序导致的 tp->delivered 延后累加,先再次解释 delivery rate 的计算方法:
- 找到当前 ack 中被 ack/sack 的最晚发送的报文 p;
- 确认 p 被发送的时间 t_p 及当时成功 delivered 的数据量 n_p;
- 计算速率 r = (n_curr - n_p) / (t_curr - t_p)
整件事可用下面的 tcptrace 时空图解释:
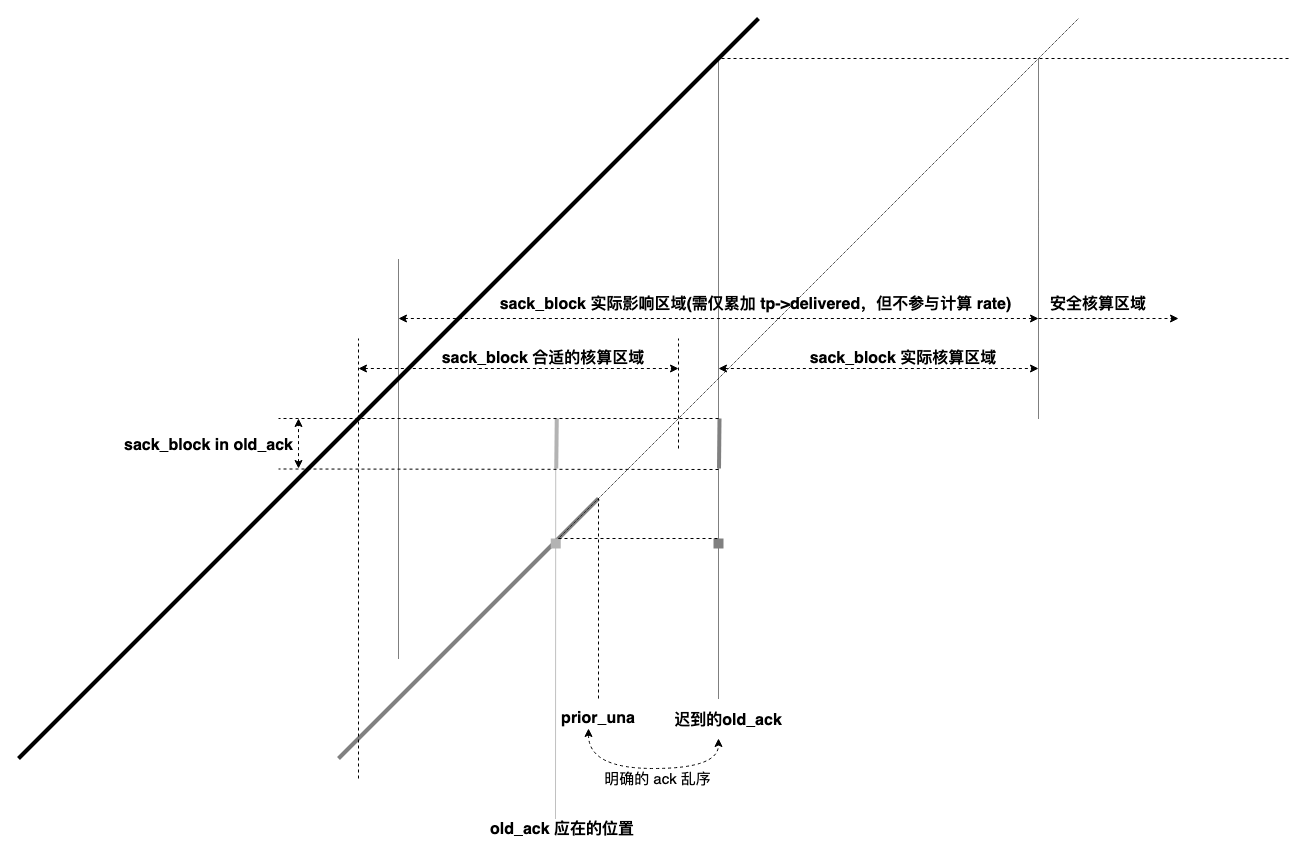
当 old_ack 到达时发送的报文被 ack 后,迟到累加的 tp->delivered 对带宽的过估影响才能消除。否则在 sack_block in old_ack 的实际核算区域,计算 delivery rate 时均要减去本 sack_block 覆盖的数据量,由于 old_ack 迟到造成的此前带宽低估就随它去吧。
这个修改背后的思想是合理的,任何时间序列(而不是空间)中,历史的误判不应让未来买单,要及时止损,否则可能面临双倍惩罚。如果前面一个 rtt 低估了带宽,低估就低估吧,不要以下一个 rtt 高估带宽来弥补。
像 bbr 类 rate-based 算法,低估带宽不可怕,它自己的状态机(比如 probe up)能搞定,但高估带宽甚至直接打乱状态机的正常运行,比如 buffer 以非预期方式被占用,竟然因为高估带宽而不是 probe up,则 0.75x drain 就没用了,就像飞机失速很难改出一样。
简单的例子,bbr 流故意高估带宽,带来更大的 delivery rate 被记住,几乎没有任何机制排空 buffer,这是个相当不稳定的状态。如果抖动真由 buffer 带入,很容易由于瞬时 minrtt 造成带宽高估(这也是 netem 靠乱序模拟抖动时吞吐更高的原因,但凡有几个极小的 rtt 就赢了),将状态机引入难以控制的未知。
本文内容实在想不通就考虑 old_ack 丢了,但丝毫不影响传输的场景,丢就丢了呗,为什么要为过去的事揪心呢,迟到了就是晚了,就当它丢了得了。为过去的事,搅乱当前的安排(schedule),不值当,那就干脆点,全部干掉好了,广义地说,maybe undo 和 maybe retrans 也不要才好,那就把 old_ack 这个 label 去掉吧。
皮鞋没有蹬上,露着白袜子。
浙江温州皮鞋湿,下雨进水不会胖。

![CUDA说明和安装[window]](https://img-blog.csdnimg.cn/img_convert/bebf45183e54509b2d7ba66fecd63ba1.png)