身为程序员,总能遇见那些神奇的bug。我前段时间遇到了 “中国黄金” 和 “中国黄⾦”,我咋看咋觉得是同一个词,但是程序就是判定不一致,十分郁闷,多方搜索,最后发现2个金居然不是一个字。真是个神奇的bug,故整理下相关情况,希望大家若能遇见此类问题,可以快速排查。
一、情况回顾
1.1 工具推荐
这里推荐2个在线网站,供大家参考:
在线文本对比
在线字符编码查询
1.2 排查路线
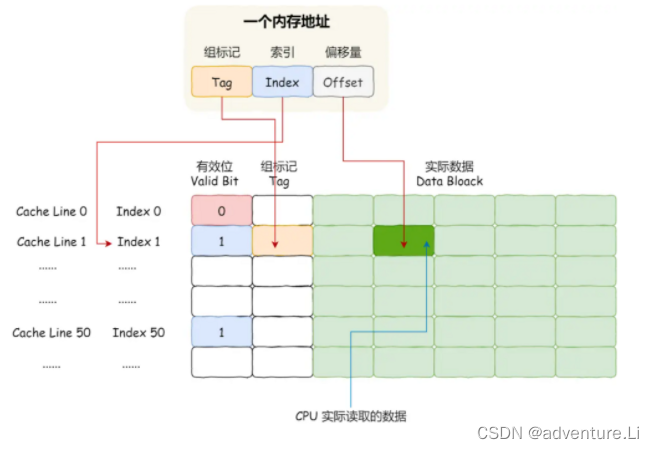
step1. 打开在线对比网站,逐字对比,发现问题出现在 “金” 字这里,此时可判定并非同一个字。
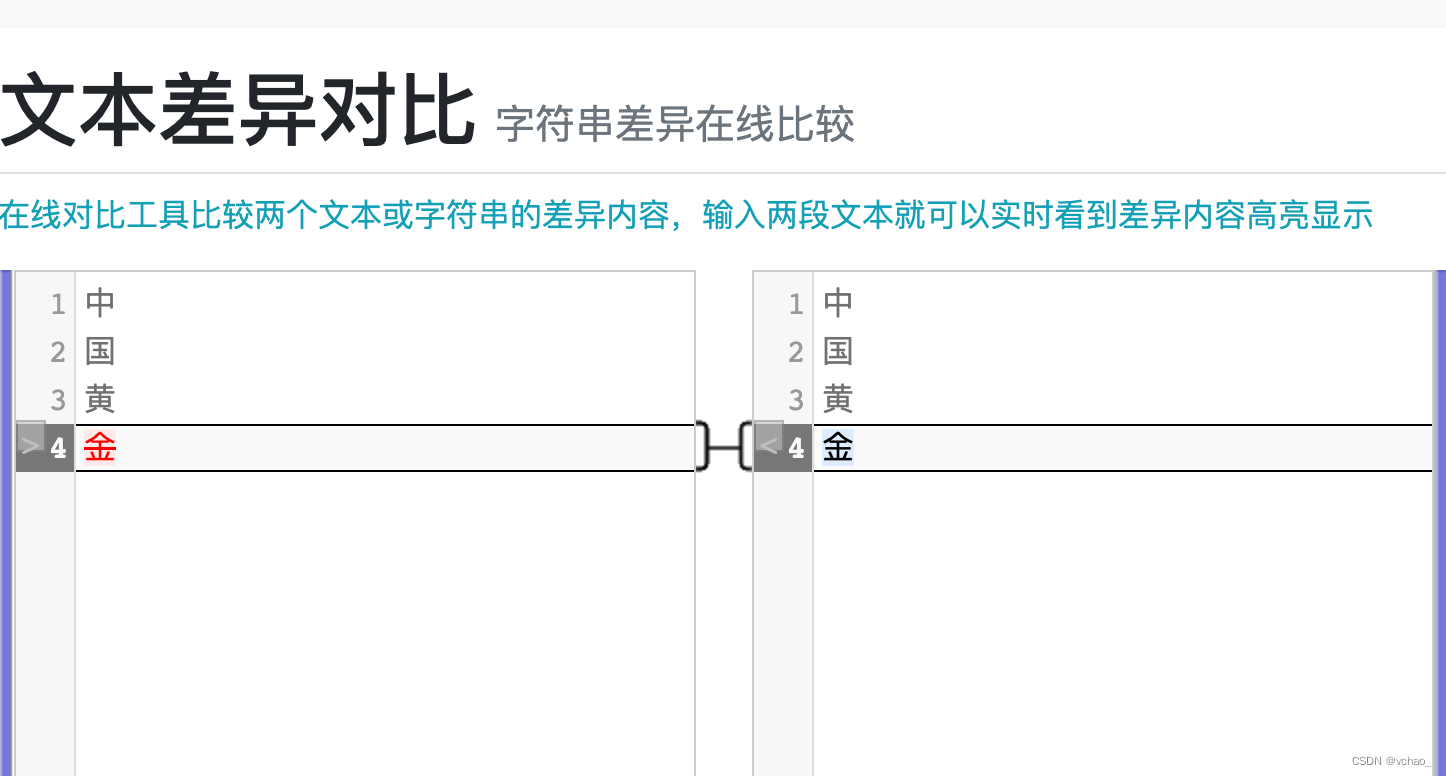
step2. 打开在线字符编码查询网站,分别查一下其编码
“金”码位值相关信息如下:
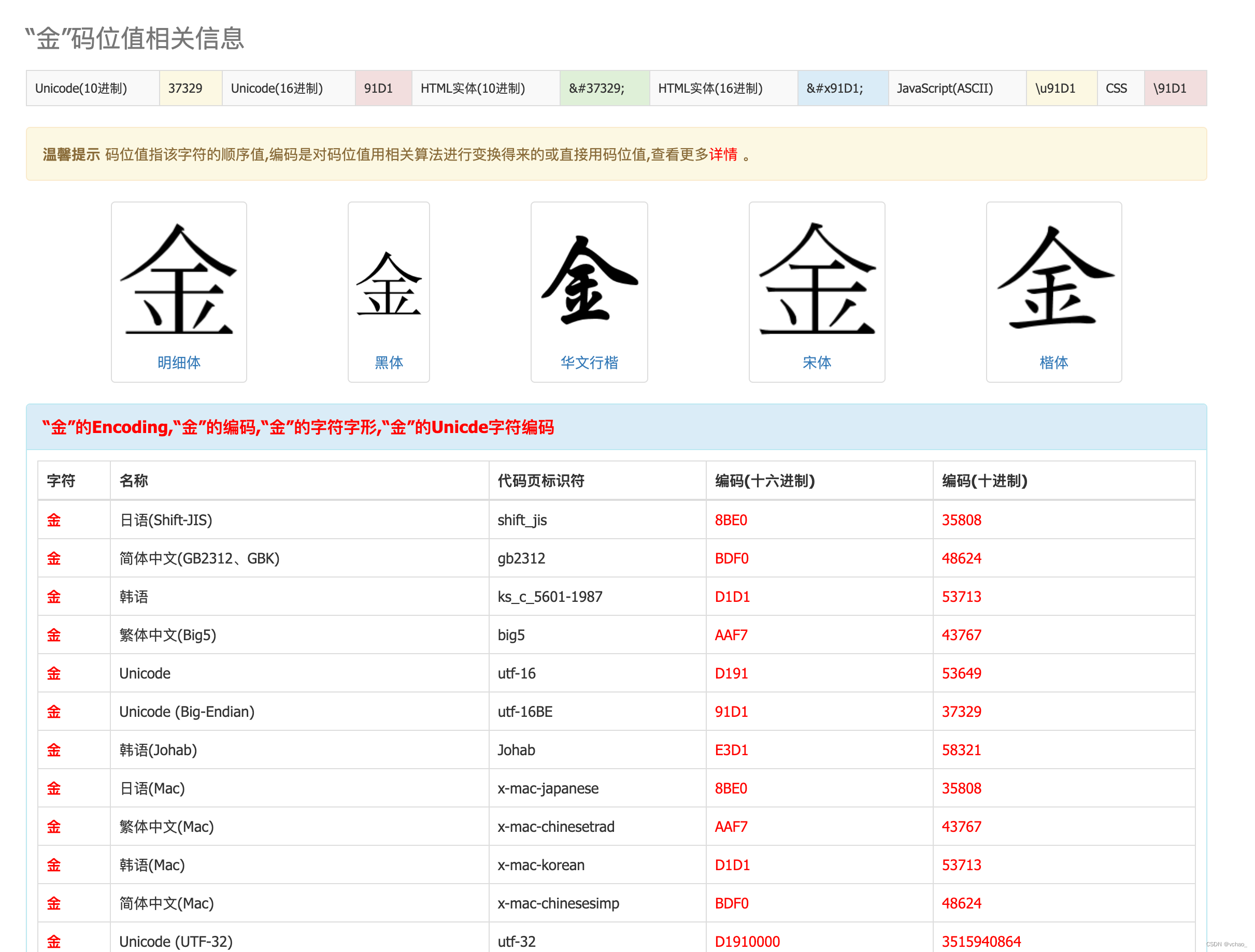
“⾦”码位值相关信息
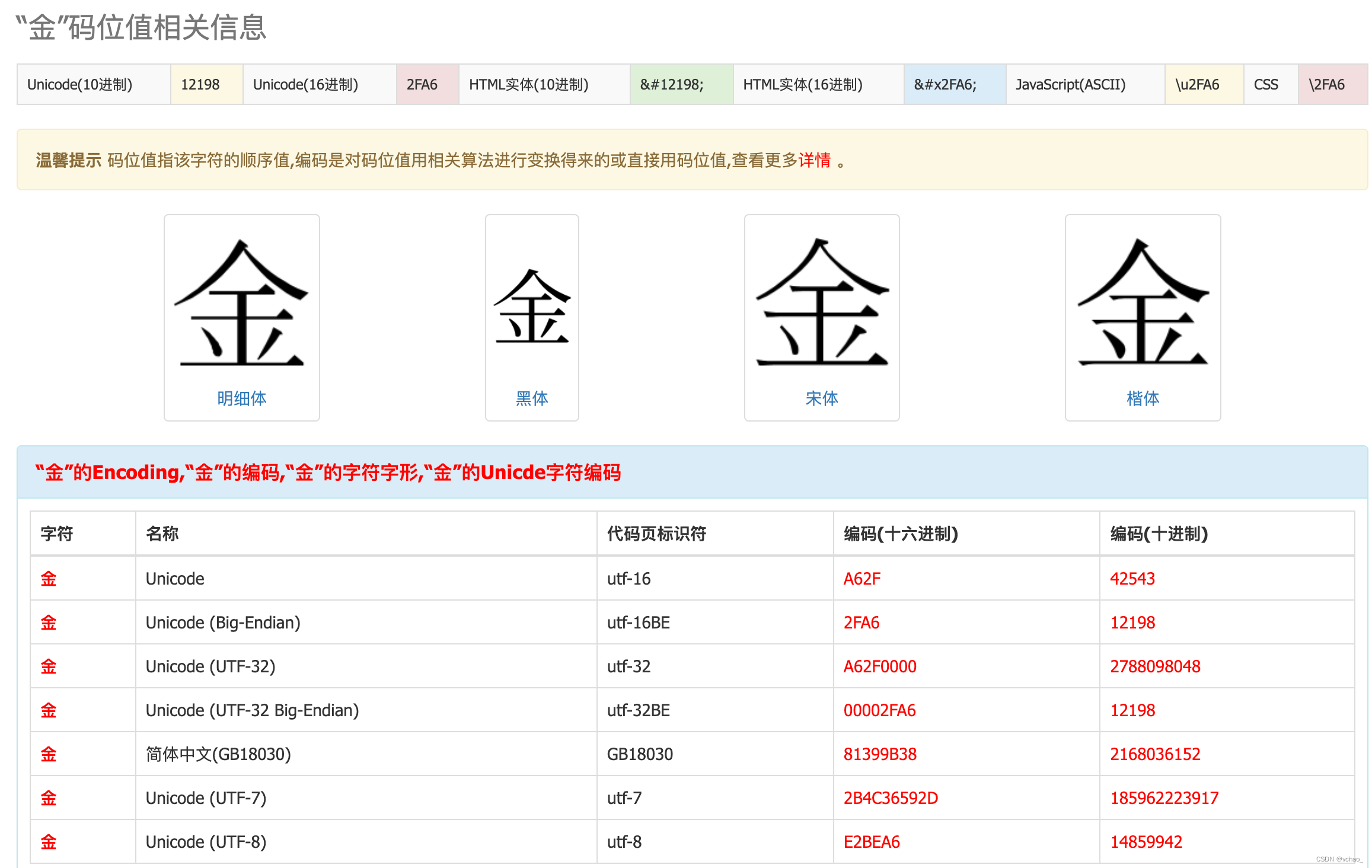
由此可以看出2个字的编码完全不同,故程序判定不一致是正常现象。至此,本次问题已梳理清楚,统一字符即可。
经过后续查询,发现 “⾦” 实际为康熙词典中的部首。
step3. 啥原因导致的这个情况发生呢?
项目前期,部分文本以图片形式提供, 因不想手动打字,所以采用了OCR进行文本识别。
嗯……OCR的锅,不过话说回来,也不能全怪OCR,也许图片显示确实与后者更相近。
使用OCR录入数据的大家注意了哈!
二、举一反三、延伸扩展
由这件事开始,那么扩展想一下,还有那些从程序视角审视完全不一样,但是肉眼难以区分的情况呢?
我这里仅是抛砖引玉,欢迎大家在评论区补充哈。
2.1 压根不是一个字
这类字字形极为相似,OCR中也极容易误判,但是多数有细微差别。
| 常用字 | 近似字 |
|---|---|
| 采 | ⾤ |
| 口 | 囗 |
| 市 | 巿 |
| 金 | ⾦ |
2.2 全角半角不同
全角一个字符占用两个标准字符位置的状态,也就是字母、数字等与汉字占等宽位置。
半角一个字符占用一个标准字符的位置。
ASCII表中的字符,在默认情况下输入的字母数字和字符都是半角的。
举例如下:
| 半角 | 全角 |
|---|---|
| a | a |
| b | b |
| c | c |
如果你还遇到过其他的情况,欢迎补充哈~~