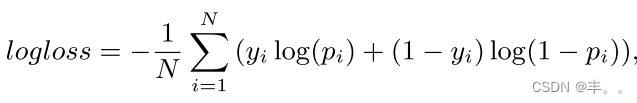三、CPU Cache的数据结构和读取过程
本文知识来源小林Coding阅读整理思考,原文链接请见该篇文章
Cache结构
CPU Cache 是由很多个 Cache Line 组成的,Cache Line 是 CPU 从内存读取数据的基本单位,而 Cache Line 是由各种**标志(Tag)+ 数据块(Data Block)**组成。
注:后续 线程、进程的单位结构 ,拿来一起对比。
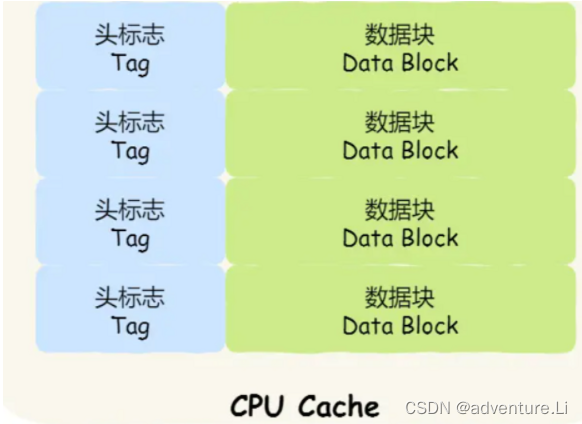
CPU 读取数据的时候,无论数据是否存放到 Cache 中,CPU 都是先访问 Cache,只有当 Cache 中找不到数据时,才会去访问内存,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
- Redis缓存一致性问题:https://www.nowcoder.com/discuss/420184343761424384
- 解决Redis、数据库双写不一致性的手段:https://www.nowcoder.com/discuss/385370932511076352
CPU访问内存、Cache的具体过程
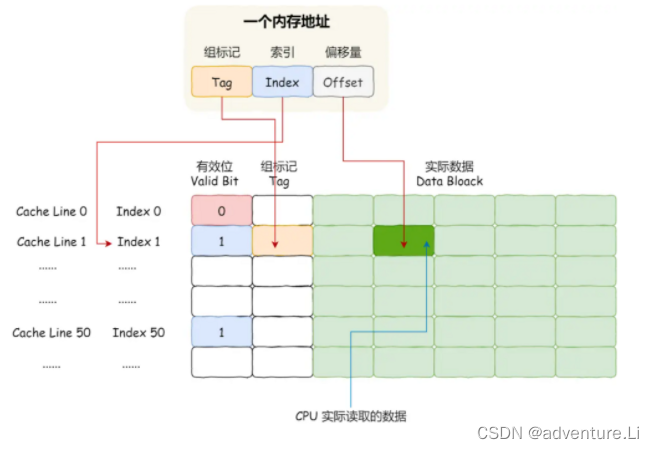
Cache和内存的映射
CPU 访问内存数据时,是一小块一小块数据读取的,具体这一小块数据的大小,取决于 coherency_line_size 的值,一般 64 字节。在内存中,这一块的数据我们称为内存块(Block),读取的时候我们要拿到数据所在内存块的地址。
对于直接映射 Cache 采用的策略,就是把内存块的地址始终「映射」在一个 CPU Cache Line(缓存块) 的地址,至于映射关系实现方式,则是使用「取模运算」,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块) 的地址。
具体过程
如果内存中的数据已经在 CPU Cahe 中了,那 CPU 访问一个内存地址的时候,会经历以下步骤:
- 经过 指令周期的取码、译码—中指令的值,都是指令的内存地址【回顾CPU的执行过程】,需要去访问 内存地址,获取数据 进行 操作。
- 根据内存地址中索引信息,计算在 CPU Cahe 中的索引,也就是找出对应的 CPU Cache Line 的地址;【对比MySQL的B+树索引去映射管理文件】
- 找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
- 根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
提升程序执行效率
- 数据缓存
- 指令缓存
- 多核情况
→ 提升缓存的命中率!
对于数据缓存:
当访问地址时,CPU 会一次从内存中加载CPU Cache Line ( coherency_line_size,Linux通常为64字节) 大小的数据到 CPU Cache 。
而编程语言中的常见类型 一般在16字节以下;在操作数据时必然可一下子访问更多的数据,多余的数据则可缓存【缓存的是地址,而非具体数据】至Cache,那么在下次操作数据时,该数据正好时上次访问过的,则无需再去内存访问,则提升了命中率。
- 遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
- 声明数组时的范围 也可按照 64字节/ 类型字节数 的倍数来声明,
对于指令缓存:
- CPU的分支预测器
对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
对于多核CPU提升Cache命中率
在单核 CPU,虽然只能执行一个线程,但是操作系统给每个线程分配了一个时间片,时间片用完了,就调度下一个线程,于是各个线程就按时间片交替地占用 CPU,从宏观上看起来各个线程同时在执行。【线程上下文切换:几十微妙级别:测试方法见 https://www.modb.pro/db/415579 】
而现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果线程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。