前缀树
前缀树,又称作字典树,用一个树状的数据结构储存字典中的所有单词。
列,一个包含can、cat、come、do、i、in、inn的前缀树如下图所示:
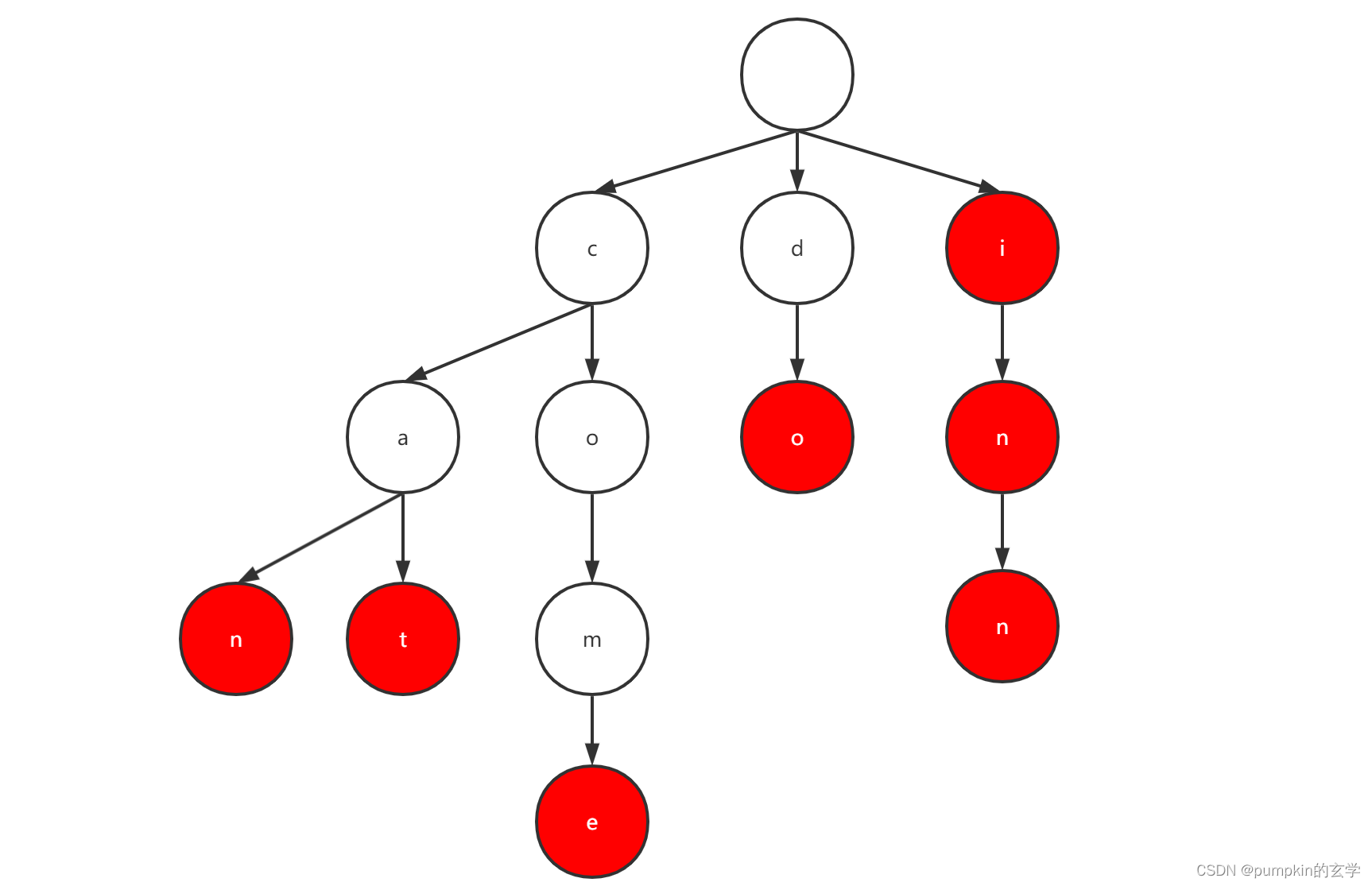
- 前缀树是一个多叉树,一个节点可能存在多个节点。
- 除根节点外,每个节点表示一个字符串的一个字符,整个字符串由前缀树的路径进行表示。
- 字符串在前缀树的路径并不一定全部都是终止于叶节点,比如
in对应的则是字符串inn的一部分。
前缀树的实现
接下来设计一颗前缀树PrefixTree,其包含如下的操作。
insert,在前缀树中添加一个字符串。search,查找,如果该前缀树中存在该字符串,则返回true。startWith,查找字符串前缀,如果前缀树中存在包含该字符串的前缀,则返回true,否则返回false。matchingStartWith,查找所有包含该前缀的字符串,返回前缀树中所有包含该前缀的字符串,如果不存在则返回null。
首先定义前缀树的数据结构,注意这里我们只考虑实现小写英文字母(具体可以根据业务逻辑调整),因为小写英文字母只有26个,所以我们可以将其放到一个容量为26的数组之中去。数组中第一个元素则是对应a的节点,第二个元素则是对应b的节点,依次往下。需要说明的是,不需要专门一个字段表示当前节点的字符,因为可以根据其在父节点对应的位置,从而得知对应的字符信息。
另外我们需要一个boolean类型的字段,去判断该节点的路径对应的字符串是否是一个完整的字符。
综上,数据结构可以定义为如下所示:
kotlin
class PrefixTree {
private val root = Node()
class Node {
val childNode = Array<Node?>(26) { null }
var isWord = false
}
}
java
class PrefixTree {
private Node root =new Node();
class Node {
Node[] childNode = new Node[26];
boolean isWord = false;
}
}
insert函数实现
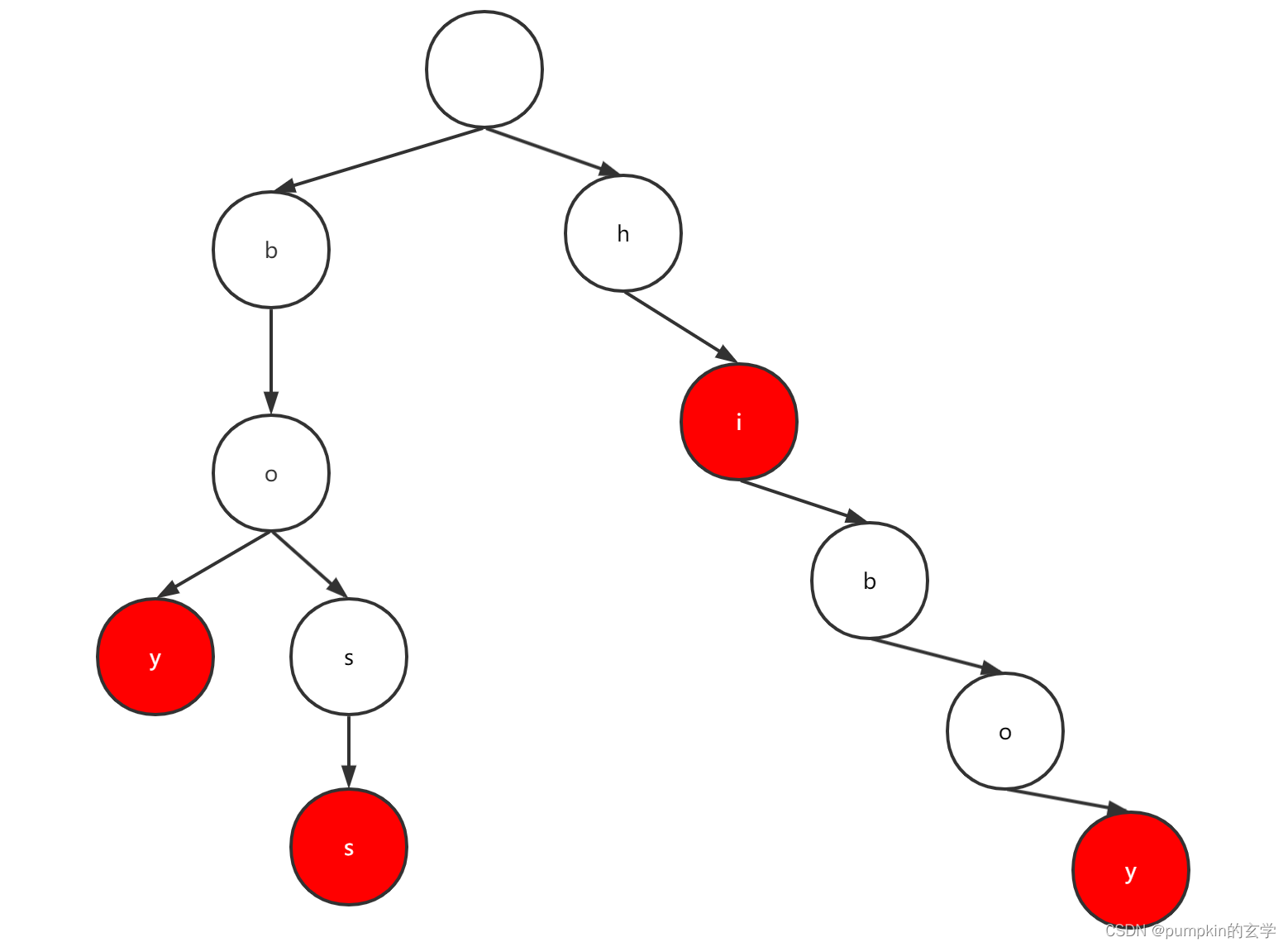
我们添加boy、boss、hiboy、hi四个单词,具体分析一下前缀树添加的过程:
- 添加
boy,逐个添加字母b、o和y对应的节点,并将最后一个字母y对应的节点的isWord标记为true - 添加
boss,此时前两个字母b和o对应的节点之前已经创建出来,因此只需要创建两个对应s的节点,并将第2个s对应节点的字段isWord标记为true - 添加
hiboy,虽然之前有添加过b、o、y三个单词,但是其并不是hiboy的前缀,所以需要为hiboy每个单词创建节点,并将最后的节点置为true - 添加
hi,由于hi为前缀,所以不需要创建节点添加,只需要将i对应的节点的isWord置为ture即可
所以,插入的代码可以做如下的实现
kotlin
fun insert(word: String) {
var localRoot = root
word.toCharArray().forEach { char ->
val index = char - 'a'
if (localRoot.childNode[index] == null) {
localRoot.childNode[index] = Node()
}
localRoot = localRoot.childNode[index]!!
}
localRoot.isWord = true
}
java
public void insert(String world){
Node localRoot = root;
for (char c :world.toCharArray()){
int index = c - 'a';
if (localRoot.childNode[index]==null){
localRoot.childNode[index] = new Node();
}
localRoot = localRoot.childNode[index]
}
localRoot.isWord = true;
}
search函数实现
这个思考起来比较简单一点,直接从根节点开始查找,如果要查找的字符串对应的字符在根节点中不存在,则直接返回false,如果存在则前往该节点,在该节点查找是否存在与字符串对应的第二个字符的节点,没有返回false,如果存在则继续往下查找,直到查找完最后一个字符,最终判断如果isWord为true则返回true,否则则返回false。
所以代码如下所示:
kotlin
fun search(word: String): Boolean {
var localRoot = root
word.toCharArray().forEach { char: Char ->
val index = char - 'a'
if (localRoot.childNode[index] != null) {
localRoot = localRoot.childNode[index]!!
} else {
return false
}
}
return localRoot.isWord
}
java
public boolean search(String world){
Node localRoot = root;
for (char c :world.toCharArray()){
int index = c - 'a';
if (localRoot.childNode[index]!=null){
localRoot = localRoot.childNode[index];
}else {
return false;
}
}
return localRoot.isWord;
}
startWith函数实现
函数startWith和search不同,只要前缀树中存在以输入的前缀开头的单词就应该返回true。因此,函数startWith的返回值和函数search不同之外,其他代码是一样的。
kotlin
fun startWith(word: String): Boolean {
var localRoot = root
word.toCharArray().forEach { char: Char ->
val index = char - 'a'
if (localRoot.childNode[index] != null) {
localRoot = localRoot.childNode[index]!!
} else {
return false
}
}
return true
}
java
public boolean startWith(String world){
Node localRoot = root;
for (char c :world.toCharArray()){
int index = c - 'a';
if (localRoot.childNode[index]!=null){
localRoot = localRoot.childNode[index];
}else {
return false;
}
}
return true;
}
matchingStartWith函数实现
该函数要求返回所有匹配到前缀的单词。
所以分为以下两个步骤:
- 匹配前缀,如果匹配不到直接返回null
- 匹配到之后,在该前缀的节点进行深度优先搜索,将遍历到的所有单词全部加入集合进行返回
所以代码如下所示:
kotlin
fun matchingStartWith(word: String): List<String>? {
val wordResultPre = StringBuilder()
var localRoot = root
word.toCharArray().forEach { char: Char ->
val index = char - 'a'
if (localRoot.childNode[index] != null) {
wordResultPre.append(char)
localRoot = localRoot.childNode[index]!!
} else {
return null
}
}
//深度优先搜索 所有的剩余单词
val result = ArrayList<String>()
dfs(localRoot, StringBuilder(),wordResultPre,result)
return result
}
private fun dfs(node: Node, str: StringBuilder, wordResultPre: StringBuilder, result: ArrayList<String>) {
val childNodes = node.childNode
for (index in childNodes.indices) {
val childNode = childNodes[index]
if (childNode != null) {
str.append(('a' + index).toChar())
if (childNode.isWord) {
result.add(wordResultPre.toString() + str.toString())
}
dfs(childNode,str, wordResultPre, result)
}
}
}
java
public List<String> matchingStartWith(String world){
StringBuilder wordResultPre = new StringBuilder();
Node localRoot = root;
for (char c :world.toCharArray()){
int index = c - 'a';
if (localRoot.childNode[index]!=null){
wordResultPre.append(c);
localRoot = localRoot.childNode[index];
}else {
return null;
}
}
//深度优先搜索 所有的剩余单词
List<String> result =new ArrayList<>();
dfs(localRoot,new StringBuilder(),wordResultPre,result);
return result;
}
private void dfs(Node node, StringBuilder stringBuilder, StringBuilder wordResultPre, List<String> result) {
Node[] childNodes = node.childNode;
for (int i =0 ;i<childNodes.length;i++){
Node childNode = childNodes[i];
if (childNode!=null){
stringBuilder.append('a'+i);
if (childNode.isWord){
result.add(wordResultPre.toString()+stringBuilder.toString());
}
dfs(childNode,stringBuilder,wordResultPre,result);
}
}
}
前缀树应用
题目
输入一个包含n个单词的数组,可以把它们编码成一个字符串和n个下标。例如,单词数组["time","me","bell"]可以编码成一个字符串"time#bell#",然后这些单词就可以通过下标[0,2,5]得到。对于每个下标,都可以从编码得到的字符串中相应的位置开始扫描,直到遇到’#'字符前所经过的子字符串为单词数组中的一个单词。所以如果输入的是字符串数组["time","me","bell"],那么编码之后最短的字符串是"time#bell#",长度是10。
分析
题目的目标是得到最短的编码,因此,如果一个单词是另一个单词的后缀,那么单词在编码字符串中就不需要单独出现,这是因为单词可以通过在单词中偏移下标得到。
所以我们很容易想到前缀树,但是题目是关于字符串的后缀。所以,我们可以反转字符串,之后使用前缀树。
根据题目信息,我们不需要关心每个单词,只需要遍历每个叶子节点对应的字符串的长度,然后加在一起即可。但是注意,字符串和字符串之间存在#,所以需要对长度进行额外+1。
总体来说使用深度优先搜索,代码参考如下:
public void minLength(String [] words){
PrefixTree.Node node = build(words);
int [] total = {0};
dfs(node,1,total);
}
private void dfs(PrefixTree.Node node, int length, int[] total) {
boolean isLeaf = true;
for (PrefixTree.Node childNode : node.getChildNode()) {
if (childNode != null) {
isLeaf = false;
dfs(childNode, length + 1, total);
}
}
if (isLeaf) {
total[0] += length;
}
}
🙆♀️。欢迎技术探讨噢!





![[ 数据结构 -- 手撕排序算法第六篇 ] 快速排序](https://img-blog.csdnimg.cn/a66f33245a62495fbda32023d66f2235.png)