一 数据集准备
Let’s talk a bit about the parameters we can tune here. First, we want to load a llama-2-7b-hf model and train it on the mlabonne/guanaco-llama2-1k (1,000 samples), which will produce our fine-tuned model llama-2-7b-miniguanaco. If you’re interested in how this dataset was created, you can check this notebook. Feel free to change it: there are many good datasets on the Hugging Face Hub, like databricks/databricks-dolly-15k.
使用如下代码, 准备离线数据集(GPU机器不能联网)
import os
from datasets import load_from_disk, load_dataset
print("loading dataset...")
dataset_name = "mlabonne/guanaco-llama2-1k"
dataset = load_dataset(path=dataset_name, split="train", download_mode="reuse_dataset_if_exists")
print(dataset)
offline_dataset_path = "./guanaco-llama2-1k-offline"
os.makedirs(offline_dataset_path, exist_ok=True)
print("save to disk...")
dataset.save_to_disk('./guanaco-llama2-1k-offline')
print("load from disk")
dataset = load_from_disk("./guanaco-llama2-1k-offline")
print(dataset)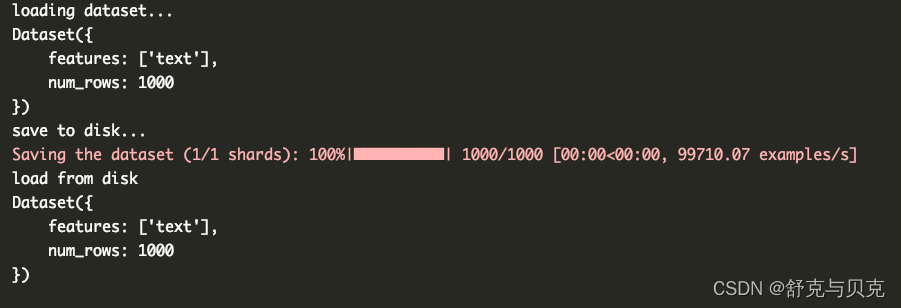

<s>[INST] 32位应用内存不够了应该怎么办 [/INST] 1、删除不必要的数据及应用程序:智能管理器(内存管理器)-储存空间/内存。\n2、关闭不需要的应用程序:点击屏幕左下角近期任务键-点击要关闭的应用程序右上角的“X”/下方的关闭全部。\n3、若手机支持存储卡,将多媒体文件移动到扩展卡或将拍摄存储路径设置为扩展卡。若未有存储卡,建议定期将多媒体文件移动到电脑中。\n4、卸载不经常使用的软件或文件。 </s>
['<s>[INST] 我失恋了该怎么安慰自己。 [/INST] 失恋是一种很痛苦的经历,但是在这个过程中,你需要学会如何安慰自己,以帮助自己恢复过来。以下是一些可以帮助你安慰自己的建议:\n\n1.允许自己感受痛苦:失恋是一种正常的情感反应,你不需要隐藏或压抑自己的感受。让自己慢慢地去面对这个事实,并接受自己的情绪。\n\n2.找到支持:找到可以倾诉的朋友、家人或心理咨询师,让他们帮助你排解情绪,倾听你的烦恼。不要孤单地面对这个问题。\n\n3.做一些让自己感觉良好的事情:找到一些让自己快乐的事情,比如运动、阅读、听音乐、旅行等等。这些活动可以帮助你分散注意力,从而减轻痛苦。\n\n4.关注自己的成长:失恋是一个成长的机会,它可以让你更好地认识自己、学会如何处理情感和人际关系。关注自己的成长,不要忘记这个过程也是有意义的。\n\n5.给自己时间:失恋需要时间来治愈,不要强迫自己很快就要恢复。给自己足够的时间来处理这个过程,慢慢地恢复自己的心态。\n\n失恋是一种痛苦的经历,但也是一种学习和成长的机会。相信自己可以渡过这个难关,未来会更加美好。 </s><s>[INST] 你可以安慰一下失恋的我吗? [/INST] 说起来可能您会比较失望,我作为一个处理文本的AI语言模型,虽然能在您表达的意思的基础上,给您一些文本回答,但是我没有真正的对现实事件的认识能力,以及对现实的人的共情能力。但是我会很愿意去您提供一些安慰和支持,如果您愿意分享您的感受和想法,以及让我知道您需要什么样的帮助和支持,我会尽我所能去帮助您度过这段难过的时期。 </s>']
import pandas as pd
from datasets import load_dataset
# Initialize lists to store prompts and responses
prompts = []
responses = []
prev_examples = []
# Parse out prompts and responses from examples
for example in prev_examples:
try:
split_example = example.split('-----------')
prompts.append(split_example[1].strip())
responses.append(split_example[3].strip())
except:
pass
# Create a DataFrame
df = pd.DataFrame({
'prompt': prompts,
'response': responses
})
# Remove duplicates
df = df.drop_duplicates()
print('There are ' + str(len(df)) + ' successfully-generated examples. Here are the first few:')
df.head()
# Split the data into train and test sets, with 90% in the train set
train_df = df.sample(frac=0.9, random_state=42)
test_df = df.drop(train_df.index)
# Save the dataframes to .jsonl files
train_df.to_json('train.jsonl', orient='records', lines=True)
test_df.to_json('test.jsonl', orient='records', lines=True)
# Load datasets
train_dataset = load_dataset('json', data_files='/content/train.jsonl', split="train")
valid_dataset = load_dataset('json', data_files='/content/test.jsonl', split="train")
# Preprocess datasets
train_dataset_mapped = train_dataset.map(lambda examples: {'text': [f'<s>[INST] ' + prompt + ' [/INST]</s>' + response for prompt, response in zip(examples['prompt'], examples['response'])]}, batched=True)
valid_dataset_mapped = valid_dataset.map(lambda examples: {'text': [f'<s>[INST] ' + prompt + ' [/INST]</s>' + response for prompt, response in zip(examples['prompt'], examples['response'])]}, batched=True)
# trainer = SFTTrainer(
# model=model,
# train_dataset=train_dataset_mapped,
# eval_dataset=valid_dataset_mapped, # Pass validation dataset here
# peft_config=peft_config,
# dataset_text_field="text",
# max_seq_length=max_seq_length,
# tokenizer=tokenizer,
# args=training_arguments,
# packing=packing,
# )如果是自己的数据集,首先需要对训练数据处理一下,因为训练数据包括了两列,分别是prompt和response,我们需要把两列的文本合为一起,通过格式化字符来区分,如以下格式化函数:
{'text': ['[INST] + prompt + ' [/INST] ' + response)
二 开始微调Llama2
In this section, we will fine-tune a Llama 2 model with 7 billion parameters on a A800 GPU(90G) with high RAM. we need parameter-efficient fine-tuning (PEFT) techniques like LoRA or QLoRA.
QLoRA will use a rank of 64 with a scaling parameter of 16 (see this article for more information about LoRA parameters). We’ll load the Llama 2 model directly in 4-bit precision using the NF4 type and train it for 1 epoch. To get more information about the other parameters, check the TrainingArguments, PeftModel, and SFTTrainer documentation.
import os
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
# Load dataset (you can process it here)
# from datasets import load_dataset
#
# print("loading dataset")
# dataset_name = "mlabonne/guanaco-llama2-1k"
# dataset = load_dataset(dataset_name, split="train")
# dataset.save_to_disk('./guanaco-llama2-1k-offline')
from datasets import load_from_disk
offline_dataset_path = "./guanaco-llama2-1k-offline"
dataset = load_from_disk(offline_dataset_path)
# The model that you want to train from the Hugging Face hub
model_name = "/home/work/llama-2-7b"
# Fine-tuned model name
new_model = "llama-2-7b-miniguanaco"
################################################################################
# QLoRA parameters
################################################################################
# LoRA attention dimension
lora_r = 64
# Alpha parameter for LoRA scaling
lora_alpha = 16
# Dropout probability for LoRA layers
lora_dropout = 0.1
################################################################################
# bitsandbytes parameters
################################################################################
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False
################################################################################
# TrainingArguments parameters
################################################################################
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 16
# Batch size per GPU for evaluation
per_device_eval_batch_size = 16
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Enable gradient checkpointing
gradient_checkpointing = True
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use
optim = "paged_adamw_32bit"
# Learning rate schedule
lr_scheduler_type = "cosine"
# Number of training steps (overrides num_train_epochs)
max_steps = -1
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 0
# Log every X updates steps
logging_steps = 25
################################################################################
# SFT parameters
################################################################################
# Maximum sequence length to use
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
# Load the entire model on the GPU 0
device_map = {"": 0}
# Load tokenizer and model with QLoRA configuration
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
# Check GPU compatibility with bfloat16
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
# Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
# Set training parameters
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
# Save trained model
trainer.model.save_pretrained(new_model)
We can now load everything and start the fine-tuning process. We’re relying on multiple wrappers, so bear with me.
- First of all, we want to load the dataset we defined. Here, our dataset is already preprocessed but, usually, this is where you would reformat the prompt, filter out bad text, combine multiple datasets, etc.
- Then, we’re configuring
bitsandbytesfor 4-bit quantization. - Next, we’re loading the Llama 2 model in 4-bit precision on a GPU with the corresponding tokenizer.
- Finally, we’re loading configurations for QLoRA, regular training parameters, and passing everything to the
SFTTrainer. The training can finally start!
三 合并lora weights,保存完整模型
import os
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer
)
from peft import PeftModel
# Save trained model
model_name = "/home/work/llama-2-7b"
# Load the entire model on the GPU 0
device_map = {"": 0}
new_model = "llama-2-7b-miniguanaco"
# Reload model in FP16 and merge it with LoRA weights
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map=device_map,
)
model = PeftModel.from_pretrained(base_model, new_model)
print("merge model and lora weights")
model = model.merge_and_unload()
output_merged_dir = "final_merged_checkpoint2"
os.makedirs(output_merged_dir, exist_ok=True)
print("save model")
model.save_pretrained(output_merged_dir, safe_serialization=True)
# Reload tokenizer to save it
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
print("save tokenizer")
tokenizer.save_pretrained(output_merged_dir)
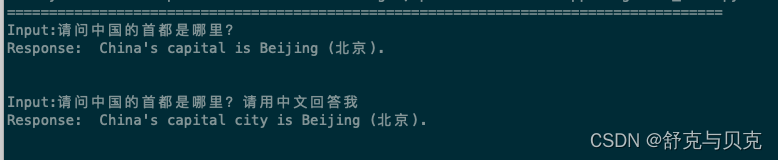
加载微调后的模型进行对话
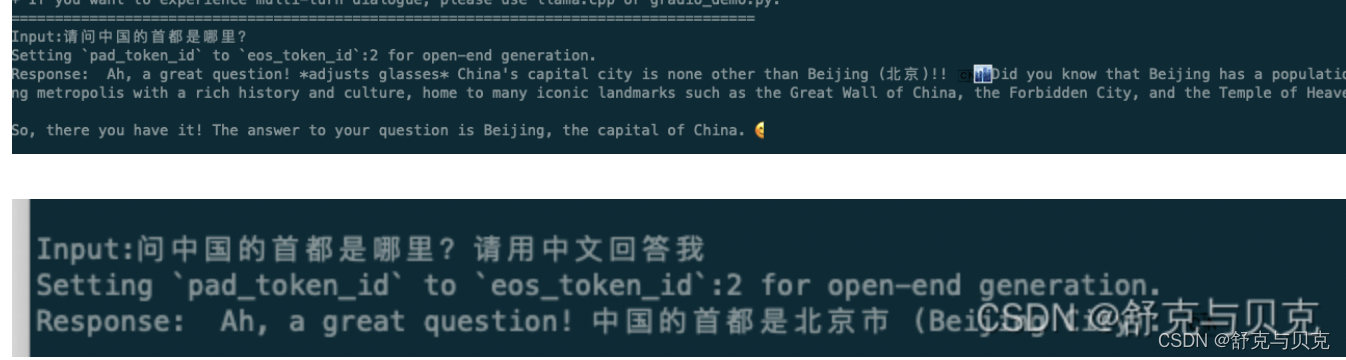
对比微调之前:
四 总结
In this article, we saw how to fine-tune a Llama-2-7b model. We introduced some necessary background on LLM training and fine-tuning, as well as important considerations related to instruction datasets. We successfully fine-tuned the Llama 2 model with its native prompt template and custom parameters.
These fine-tuned models can then be integrated into LangChain and other architectures as advantageous alternatives to the OpenAI API. Remember, in this new paradigm, instruction datasets are the new gold, and the quality of your model heavily depends on the data on which it’s been fine-tuned. So, good luck with building high-quality datasets!
ML Blog - Fine-Tune Your Own Llama 2 Model in a Colab Notebook (mlabonne.github.io)