文章目录
- 版权声明
- 一 数据库操作
- 二 Hive数据表操作
- 2.1 表操作语法和数据类型
- 2.2 Hive表分类
- 2.3 内部表Vs外部表
- 2.4 内部表操作
- 2.4.1 创建内部表
- 2.4.2 其他创建内部表的形式
- 2.4.3 数据分隔符
- 2.4.4 自定义分隔符
- 2.4.5 删除内部表
- 2.5 外部表操作
- 2.5.1 创建外部表
- 2.5.2 操作演示
- 2.5.3 演示先建表后移动数据
- 2.5.4 演示先存在数据后建表
- 2.5.5 删除外部表
- 2.6 Hive内外表转化
- 2.7 Hive数据加载和导出
- 2.7.1 数据加载-LOAD语法
- 2.7.2 数据加载-insert select语法
- 2.7.3 数据加载-两种语法的选择
- 2.7.4 hive表数据导出-insert overwrite方式
- 2.7.5 hive表数据导出-hive shell
- 2.8 分区表
- 2.8.1 创建分区
- 2.8.2 加载数据
- 2.8.3 查看分区
- 2.8.4 添加分区
- 2.8.5 修改分区位置
- 2.8.6 修改分区值
- 2.8.7 删除分区
- 2.9 分桶表
- 2.9.1 创建分桶表
- 2.9.2 分桶表数据加载
- 2.9.3 原因解释
- 2.9.4 分桶表的性能提升
- 2.10 修改表
- 2.11 复杂类型
- 2.11.1 array类型
- 2.11.2 map类型
- 2.11.3 struct类型
- 2.11.4 三种结构总结
版权声明
- 本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利人所有。本博客的目的仅为个人学习和交流之用,并非商业用途。
- 我在整理学习笔记的过程中尽力确保准确性,但无法保证内容的完整性和时效性。本博客的内容可能会随着时间的推移而过时或需要更新。
- 若您是黑马程序员或相关权利人,如有任何侵犯版权的地方,请您及时联系我,我将立即予以删除或进行必要的修改。
- 对于其他读者,请在阅读本博客内容时保持遵守相关法律法规和道德准则,谨慎参考,并自行承担因此产生的风险和责任。
一 数据库操作
- 创建数据库
create database if not exists myhive; use myhive; - 查看数据库详细信息
desc database myhive; - 数据库本质上就是HDFS上的文件夹。默认数据库的存放路径位于HDFS的
/user/hive/warehouse内 - 创建数据库并指定hdfs存储位置
# 使用location关键字,指定数据库在HDFS的存储路径
create database myhive2 location '/myhive2 ';
- 删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database myhive;
- 强制删除数据库,包含数据库下面的表一起删除
drop database myhive2cascade;
二 Hive数据表操作
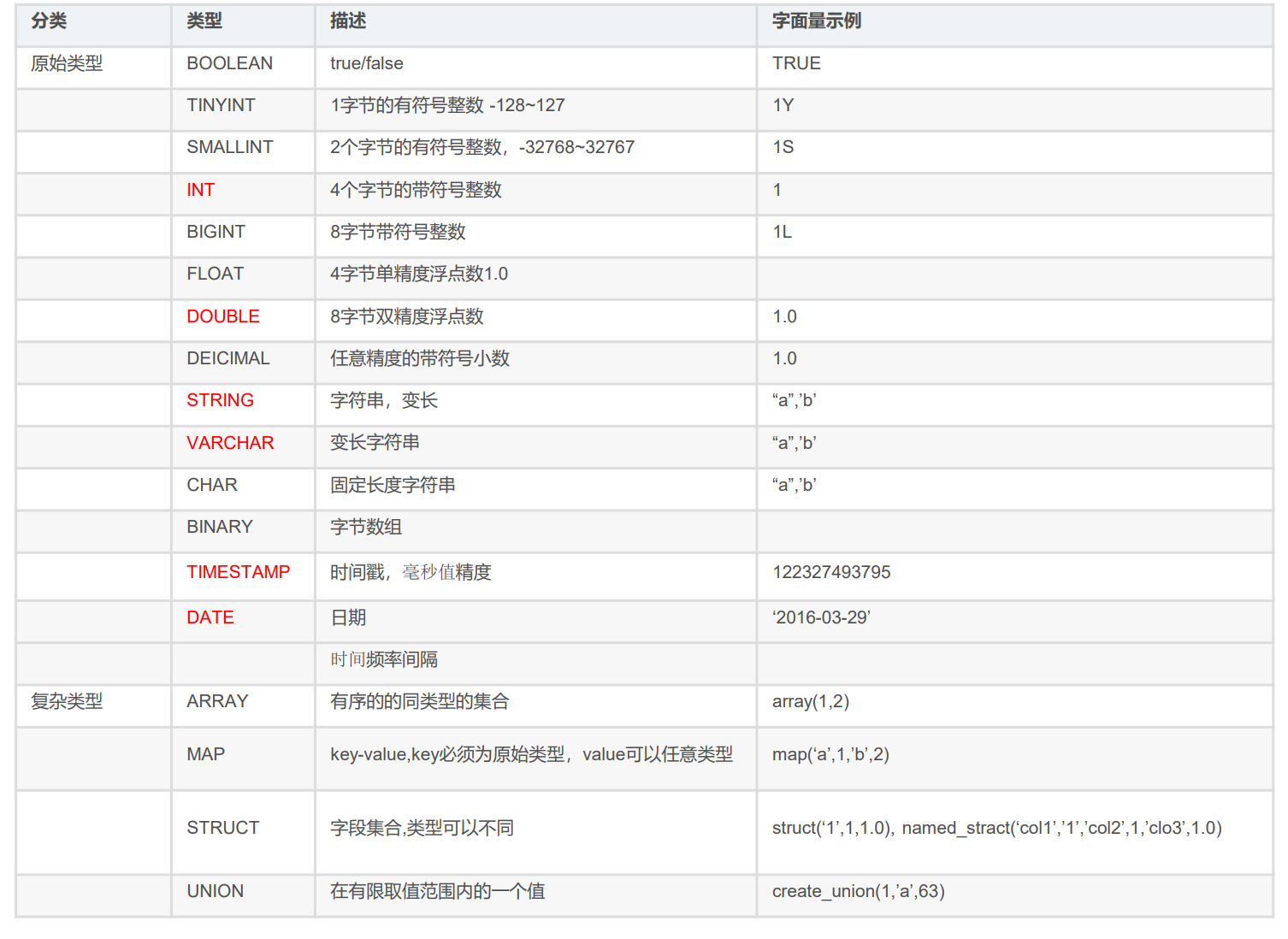
2.1 表操作语法和数据类型
CREATE [EXTERNAL] TABLE[IF NOT EXISTS] tabLe_name
[(col_namedata_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [CoMMENTcol_comment], ...)]
[CLUSTERED BY (col_name,col_name,...)
[SORTED BY (col_name[ASC|DESC],...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- EXTERNAL:创建外部表
- PARTITIONED BY:分区表
- CLUSTERED BY:分桶表
- STORED AS:存储格式
- LOCATION:存储位置
2.2 Hive表分类
- 在Apache Hive中,可以创建不同类型的表,包括内部表(Managed Table)、外部表(External Table)、分区表(Partitioned Table)和分桶表(Bucketed Table)。
- 内部表(Managed Table):
- 内部表也称为托管表,是Hive的默认表类型。
- 数据和元数据都由Hive管理,存储在Hive的默认文件系统(通常是Hadoop分布式文件系统)中。当删除内部表时,Hive也会删除相关的数据和元数据。
- 内部表适合于数据集完全由Hive管理和控制的情况。
- 外部表(External Table):
- 外部表是指数据和元数据都存储在外部存储系统中,例如Hadoop分布式文件系统(HDFS)或云存储服务(如Amazon S3)。
- 与内部表不同,当删除外部表时,Hive只删除元数据而不会删除实际的数据。这种特性使得外部表适合于与其他系统共享数据或将已有数据引入Hive的场景。
- 分区表(Partitioned Table):
- 分区表将数据按照一或多个分区键(如日期、地区等)切分成不同的分区存储,这样可以更高效地管理和查询数据。
- 分区表允许用户在查询时只加载特定分区的数据,而不必加载整个表。
- 分区表适用于按照某种规则对数据进行组织和查询的场景。
- 分桶表(Bucketed Table):
- 分桶表是在分区表的基础上进一步细分数据的方法。
- 分桶表将每个分区划分为固定数量的桶(buckets),其中数据根据特定的列哈希算法进行分桶。
- 分桶表可以改善查询性能,特别是当你经常需要基于某个列进行连接操作时。分桶表通常与分区表结合使用。
- 总结
- 内部表适合完全由Hive管理的数据集,外部表适合与其他系统共享或引入数据,分区表适合按照特定规则组织和查询数据,而分桶表则是进一步细分数据以改善查询性能的一种方式。
2.3 内部表Vs外部表
| 内部表(Managed Table) | 外部表(External Table) | |
|---|---|---|
| 创建语法 | CREATE TABLE table_name … | CREATE EXTERNAL TABLE table_name … LOCATION … |
| 存储位置 | 由Hive管理,存储在Hive默认文件系统中 | 可在任何位置,通过LOCATION关键字指定 |
| 元数据和数据 | Hive管理和控制元数据和数据 | 仅Hive管理元数据,不控制实际数据 |
| 删除表时的行为 | 删除表会同时删除元数据和存储的数据 | 仅删除表的元数据,不删除实际数据 |
| 适用场景 | 数据集完全由Hive管理和控制的情况 | 与其他系统共享数据,引入已有数据的场景 |
| 与其他工具的共享性 | 不适合与其他工具共享数据 | 可以随意临时连接到外部数据上 |
- 内部表(Managed Table)是由Hive管理和控制的表,数据和元数据由Hive存储和管理。删除内部表时会删除相关的数据和元数据。适合数据完全由Hive管理和控制的场景。
- 外部表(External Table)是关联到外部数据的表,数据存储位置可以在任何地方,通过LOCATION关键字指定。删除外部表时仅删除元数据,不会删除实际数据。适合与其他系统共享数据或引入已有数据的场景。
2.4 内部表操作
2.4.1 创建内部表
- 内部表创建语法
CREATE TABLE table_name ... - 演示
- 创建一个基础的表
create database if not exists myhive; use myhive; create table if not exists stu(id int, name string); insert into stu values ( 1,"zhangsan"),(2, "wangwu"); select *from stu;- 查看表的数据存储
hadoop fs -ls /user/hive/warehouse/myhive.db/stu hadoop fs -cat /user/hive/warehouse/myhive.db/stu/*

2.4.2 其他创建内部表的形式
- 基于查询结果建表
CREATE TABLE table_name as
-- 示例
create table stu3 as select * from stu2;
- 基于已存在的表结构建表
CREATE TABLE table_namelike
-- 示例
create table stu4 like stu2;
- 使用DESCFORMATTEDtable_name,查看表类型和详情
DESC FORMATTED Stu2;
2.4.3 数据分隔符
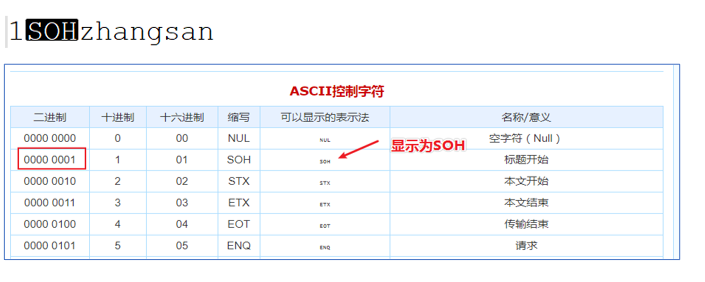
- 数据在HDFS上也是以明文文件存在的。奇怪的是,列ID和列NAME,好像没有分隔符,而是挤在一起的。
- 默认的数据分隔符是:"\001"是一种特殊字符,是ASCII值,键盘是打不出来
- 在某些文本编辑器中是显示为SOH的。
2.4.4 自定义分隔符
create table if not exists stu2(id int ,name string) row format delimited fields terminated by '\t' ;
row format delimited fields terminated by '\t' ;表示使用\t分隔
2.4.5 删除内部表
- 删除内部表时会删除相关的数据和元数据
drop table table_name;
2.5 外部表操作
2.5.1 创建外部表
- 创建外部表语法
CREATE EXTERNAL TABLE table_name ... LOCATION ...
- 外部表,创建表被
EXTERNAL关键字修饰,从概念是被认为并非Hive拥有的表,只是临时关联数据去使用。 - 外部表和数据是相互独立的,即: 可以先有表,然后把数据移动到表指定的LOCATION中。也可以先有数据,然后创建表通过LOCATION指向数据
2.5.2 操作演示
- 在Linux上创建新文件,test_external.txt,并填入如下内容,数据列使用
\t分隔:
1 hello
2 world
3 hadoop
2.5.3 演示先建表后移动数据
- 演示先创建外部表,然后移动数据到
LOCATION目录- 首先检查:
hadoop fs -ls /tmp,确认不存在/tmp/test_ext1目录 - 创建外部表:
create external table test_ext1(id int,name string) row format delimited fields terminated by '\t' location ' /tmp/test_ext1';- 创建成功后,查看表数据内容为空
select * from test_ext1- 上传数据,即可看到数据结果
- 首先检查:
hadoop fs -put test_external.txt /tmp/test_ext1. select * from test_ext1
2.5.4 演示先存在数据后建表
hadoop fs -mkdir /tmp/test_ext2
hadoop fs -put test_external.txt /tmp/test_ext2/
create external table test_ext2(id int,name string) row format delimited fieldsterminated by '\t' location '/tmp/test_ext2';
select * from test_ext2;
2.5.5 删除外部表
- 删除外部表语句
DROP TABLE table_name;
- 注意:DROP TABLE语句仅会删除表的元数据,不会删除外部表所关联的实际数据。 执行这个语句后,Hive会删除指定的外部表的元数据信息,包括表结构、分区信息和位置等,但并不会删除外部表所关联的实际数据。如果你想要同时删除外部表的数据,可以手动删除存储在外部位置的数据文件或目录。
2.6 Hive内外表转化
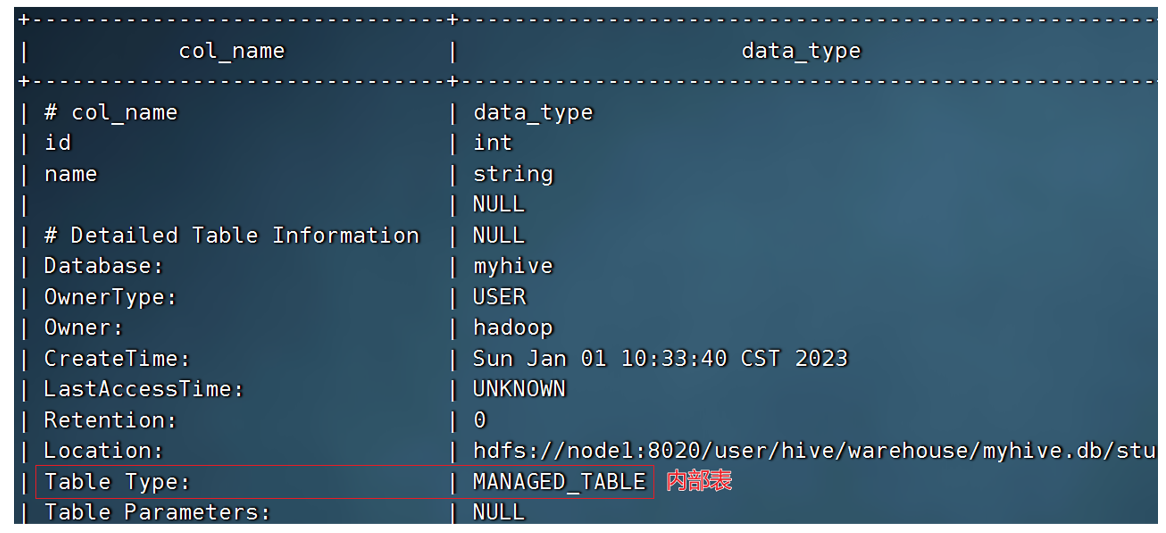
-
查看表类型:
desc formatted table_name;
-
Hive可以很简单的通过SQL语句转换内外部表。
-
内部表转外部表
alter table table_name set tblproperties('EXTERNAL'='TRUE'); -
外部表转内部表
alter table table_name set tblproperties('EXTERNAL'='FALSE'); -
要注意:(‘EXTERNAL’=‘FALSE’)或(‘EXTERNAL’=‘TRUE’)为固定写法,区分大小写! ! !
2.7 Hive数据加载和导出
2.7.1 数据加载-LOAD语法
- 语法
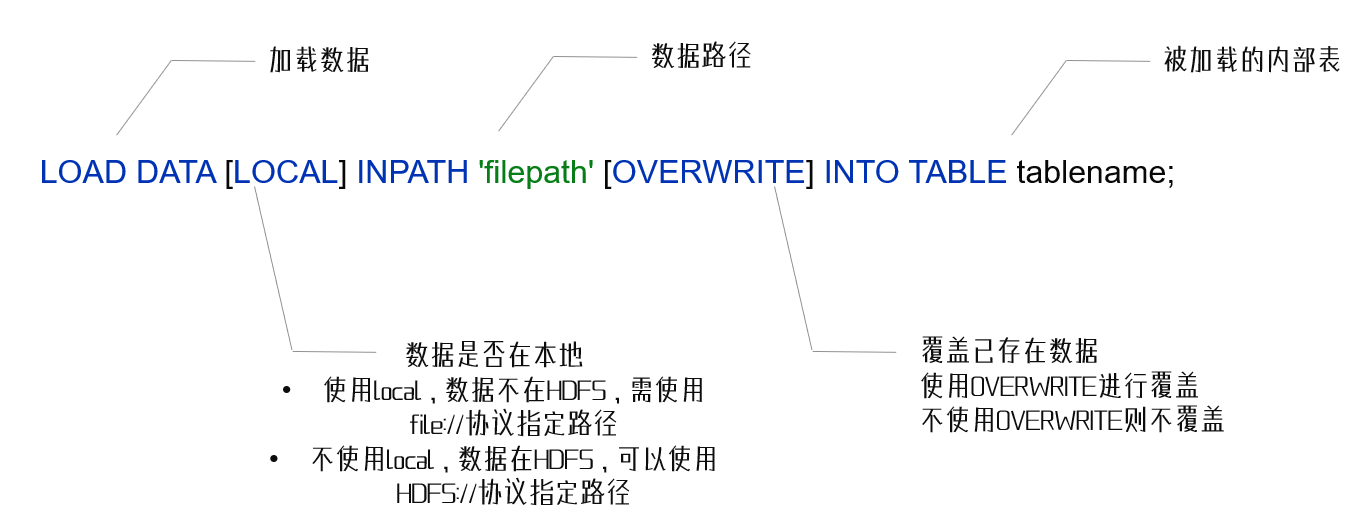
- 注意,基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中)


- 示例
load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load; load data inpath '/tmp/search_log.txt' overwrite into table myhive.test_load;
2.7.2 数据加载-insert select语法
- 语法
INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol=vall, partcol2=val2 ...) [TF NOTEXISTS]] select_statement1 FROM from_statement;
- 将SELECT查询语句的结果插入到其它表中,被SELECT查询的表可以是内部表或外部表。
2.7.3 数据加载-两种语法的选择

2.7.4 hive表数据导出-insert overwrite方式
- 语法:
insert overwrite [local] directory 'path' select_statement1 FROM from_statement;
-
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysq|等等
-
将查询的结果导出到本地-使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
- 将查询的结果导出到本地-指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
- 将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
2.7.5 hive表数据导出-hive shell
- 基本语法:(hive -f/-e 执行语句或者脚本> file)
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
bin/hive -f export.sql > /home/hadoop/export4/export4.txt
2.8 分区表
- 在Hive中,分区表(Partitioned Table)是一种将数据按照特定列的值进行逻辑分区的表。分区表可以加速查询和提高数据的管理效率。

- 同时Hive也支持多个字段作为分区,多分区带有层级关系
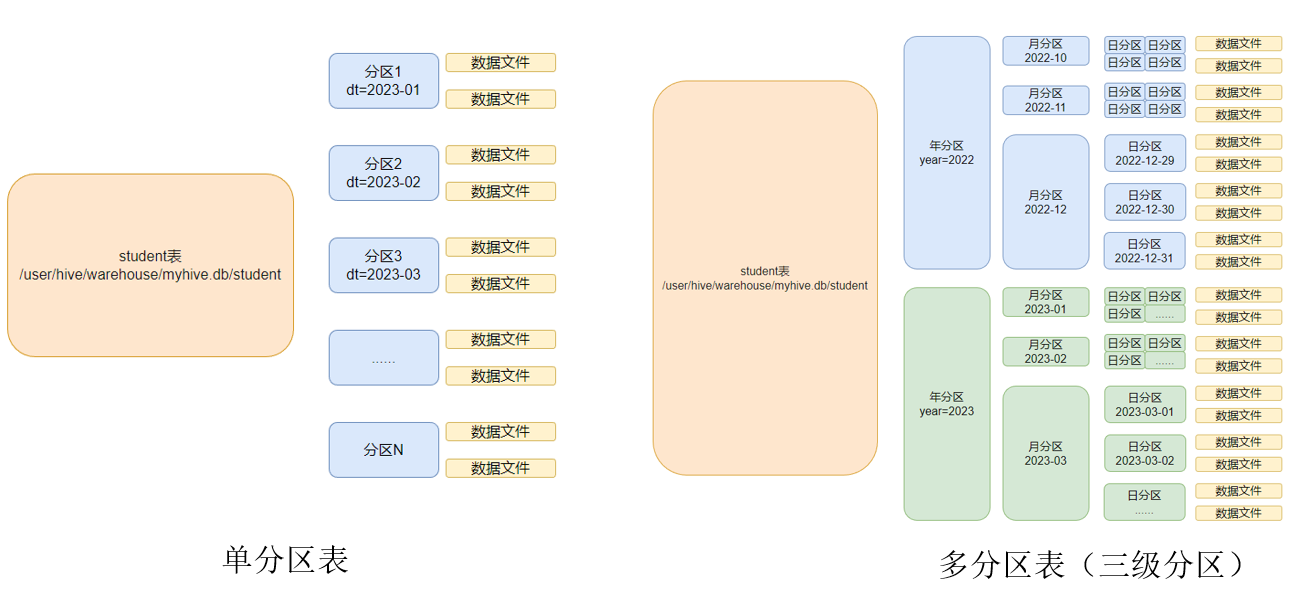
2.8.1 创建分区
- 创建分区表语法
CREATE TABLE table_name ( column1 data_type, column2 data_type, ... ) PARTITIONED BY (partition_column1 data_type, partition_column2 data_type, ...);
- 演示
create tables core( sid string, cid string, sscore int ) partitioned by(month string) row format delimited fields terminated by't'; - 创建一个表带多个分区
create table score2 (sid string,c_id string,sscore int) partitioned by(year string,month string,day string) row format delimited fields terminated by'\t';
2.8.2 加载数据
- 加载数据到分区表中
load data local inpath '/export/server/hivedatas/score.txt' into table score partition (month='202006'); - 加载数据到一个多分区的表中去
load data local inpath '/export/server/hivedatas/score.txt' into table score2 partition(year='2020',month='06',day='01'); - 插入数据到分区表
INSERT INTO TABLE table_name PARTITION (partition_column1 = value1, partition_column2 = value2, ...) VALUES (value1, value2, ...);INSERT INTO TABLE sales PARTITION (year = 2023, month = 9) VALUES (1, 'Product A', '2023-09-08', 100.0);
2.8.3 查看分区
- 查看分区
show partitions score;
2.8.4 添加分区
- 添加一个分区
alter table score add partition(month='202005') - 同时添加多个分区
alter table score add partition(month='202004') partition(month='202003'); - 注意:添加分区之后就可以在hdfs文件系统当中看到表下面多了一个文件夹
2.8.5 修改分区位置
ALTER TABLE table_name PARTITION (partition_column1 = value1, partition_column2 = value2, ...)
SET LOCATION '/new/partition/location';
2.8.6 修改分区值
alter table table_name partition(month='2002005') rename to partition(month='201105')
2.8.7 删除分区
alter table table_name drop partition(month='202006');
- 对分区的修改和删除操作,实际是修改源数据表,并不会修改hdfs中的数据内容!【不建议修改分区】
2.9 分桶表
- 分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式。
- 但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
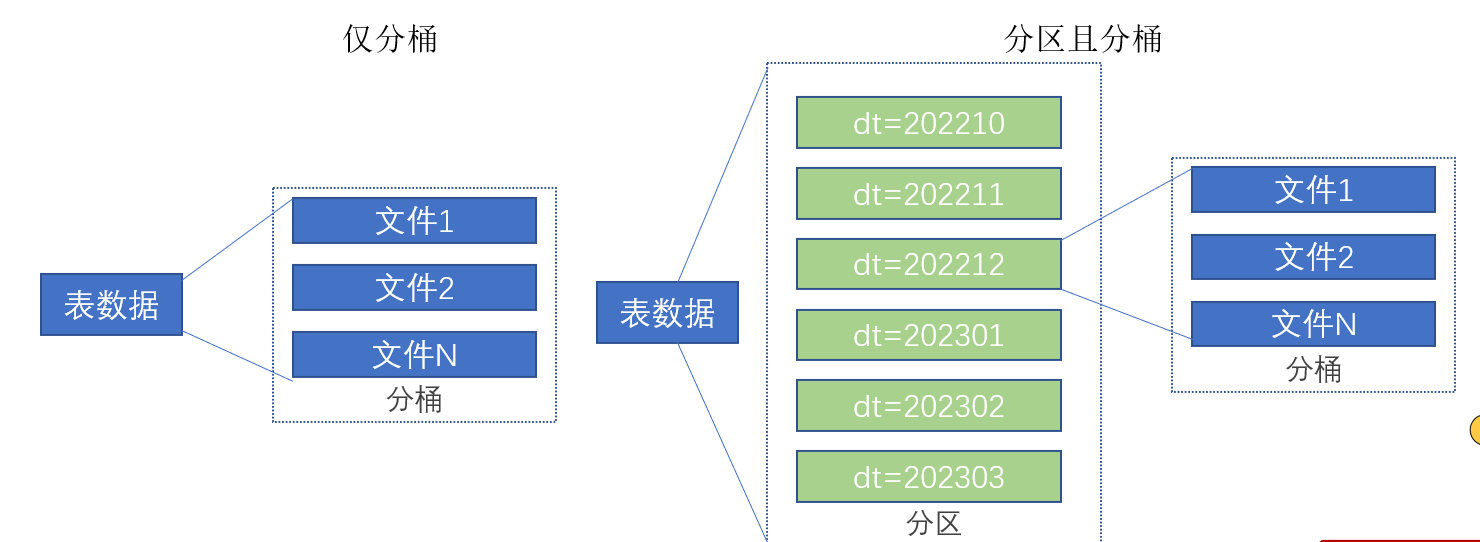
2.9.1 创建分桶表
- 开启分桶的自动优化(自动匹配reducetask数量和桶数量一致)
set hive.enforce.bucketing=true;
- 创建分桶表
create table course (
c_id string,
c_name string,
t_id string
) clustered by(c_id) into 3 buckets
row format delimited fields terminated by '\t';
2.9.2 分桶表数据加载
- 桶表的数据加载通过load data无法执行,只能通过insert select.
- 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
- 然后通过insert select 从临时表向桶表插入数据
- 创建普通表:
create table course_common (
c_id string,
c_name string,
t_id string
) rowformat delimited fields terminated by 't';
- 普通表中加载数据
load data local inpath '/export/server/hivedatas/course.txt' into table course_common; - 通过
insert overwrite给桶表中加载数据insert overwrite table course select * from course_common cluster by(cid);
2.9.3 原因解释
- 桶表的数据加载通过load data无法执行,只能通过insert select.
如果没有分桶设置,插入(加载)数据只是简单的将数据放入到:
-
表的数据存储文件夹中(没有分区)
-
表指定分区的文件夹中(带有分区)

-
一旦有了分桶设置,比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3当数据插入的时候,需要一分为3,进入三个桶文件内。

-
问题:如何将数据分成三份,划分的规则是什么?
-
数据的三份划分基于分桶列的值进行hash取模来决定。由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已,所以无法用于分桶表数据插入。
2.9.4 分桶表的性能提升
- 分区表的性能提升是:在指定分区列的前提下,减少被操作的数据量,从而提升性能。
- 分桶表的性能提升是:基于分桶列的特定操作,如:过滤、JOIN、分组,均可带来性能提升。

2.10 修改表
- 表重命名
alter table old_table_namerename to new_table_name;
- 修改表属性
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties:(property_name=property_value,property_name=property_value,...)
- 如:
ALTER TABLE table_name SETTBLPROPERTIES("EXTERNAL"="TRUE")修改内外部表属性 - 如:
ALTER TABLE table_name SETTBLPROPERTIES('comment'=new_comment修改表注释 - 添加列
alter table table_name add columns(v1 int,v2 string);
- 修改列名
alter table table_name change v1 v1new int;
- 删除表
drop table table_name;
- 清空表
-- 只能清空内部表
truncate table table_name;
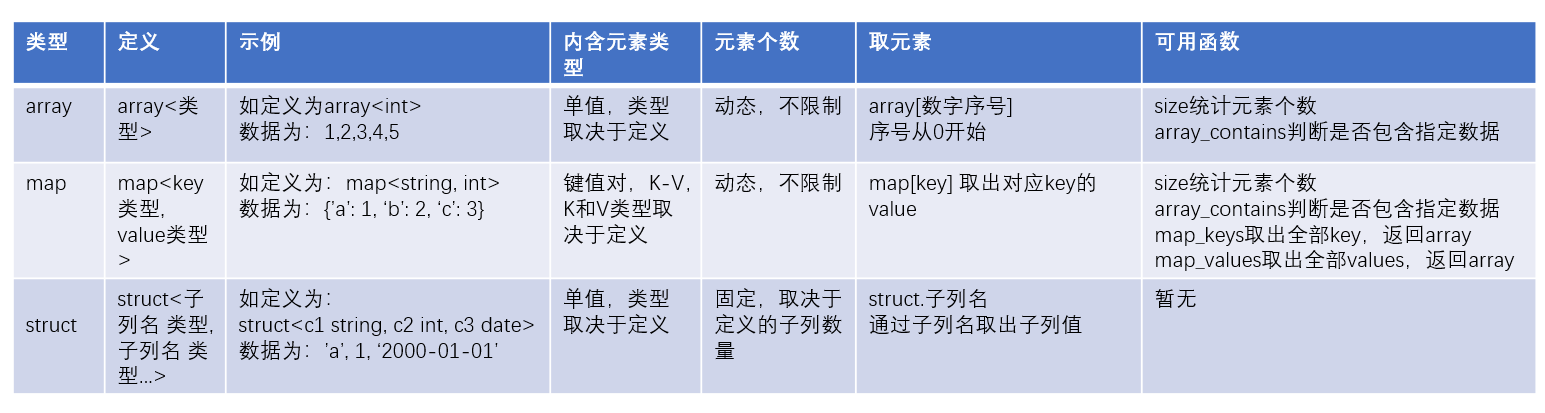
2.11 复杂类型
2.11.1 array类型
-
Hive支持的数据类型很多,除了基本的: int、string、varchar、timestamp等还有一些复杂的数据类型:array(数组类型)、map(映射类型)、struct(结构类型)
-
data_for_array_type.txt文件内容如下
zhangsan beijing,shanghai,tianjin,hangzhou wangwu changchun,chengdu,wuhan,beijin- 说明:name与locations之间制表符分隔,locations中元素之间逗号分隔

- 说明:name与locations之间制表符分隔,locations中元素之间逗号分隔
-
建表语句
create table myhive.test_array(name string,work_locations array<string>) row format delimited fields terminated by ' \t' COLLECTION ITEMS TERMINATED BY ',';row format delimited fields terminated by '\t′表示列分隔符是\t.COLLECTION ITEMS TERMINATED BY ',’表示集合(array)元素的分隔符是逗号
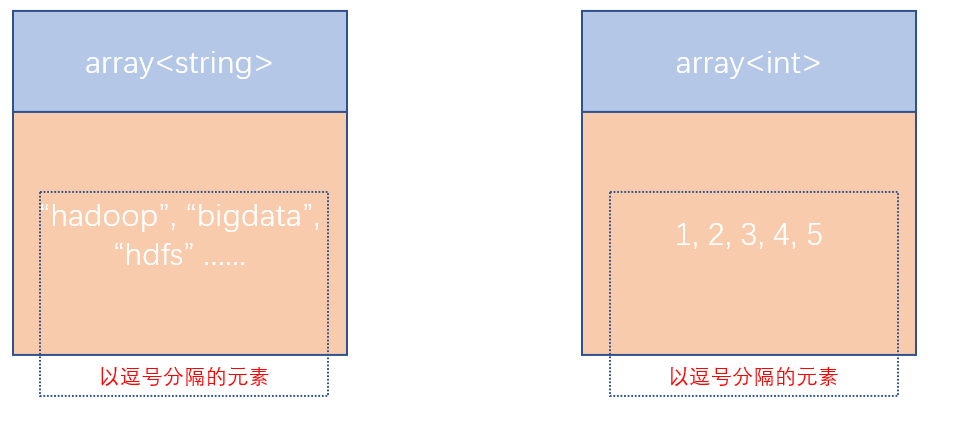
-
导入数据
load data local inpath '/home/ hadoop/data_for_array_type.txt' overwrite into table myhive.test_array; -
常用array类型查询:
-- 查询所有数据 select * from myhive.test_array; -- 查询loction数组中第一个元素 select name, work_locations[0] location from myhive.test_array; -- 查询location数组中元素的个数 select name, size(work_locations) location from myhive.test_array; -- 查询location数组中包含tianjin的信息 select * from myhive.test_array where array_contains(work_locations,'tianjin');
2.11.2 map类型
- map类型是: Key-Value型数据格式。

- 有如下数据文件,其中members字段是key-value型数据字段与字段分隔符: “,”;需要map字段之间的分隔符:“#” ; map内部k-v分隔符:“:”
1,林杰均,father:林大明#mother:小甜甜#brother:小甜,28
2,周杰伦,father:马小云#mother:黄大奕#brother:小天,22
3,王葱,father:王林#mother:如花#sister:潇潇,29
4,马大云,father:周街轮#mother:美美,26
- 建表语句
create table myhive.test_map(id int, name string, members map, age int)
row format delimited fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ';';
MAP KEYS TERMINATED BY表示key-value之间用:分隔
- 导入数据
load data local inpath '/home / hadoop/data_for_map_type.txt' overwrite into table myhive.test_map;
- 常用查询
#查询全部
select * from myhive.test_map;
#查询father、mother这两个map的key
select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map;
#查询全部map的key,使用map_keys函数,结果是array类型
select id, name, map_keys(members) as relation from myhive.test_map;
#查询全部map的value,使用mapvalues函数,结果是array类型
select id, name, map_values(members) as relation from myhive.test_map;
#查询map类型的KV对数量
select id,name,size(members) num from myhive.test_map;
#查询map的key中有brother的数据
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
2.11.3 struct类型
-
struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称。
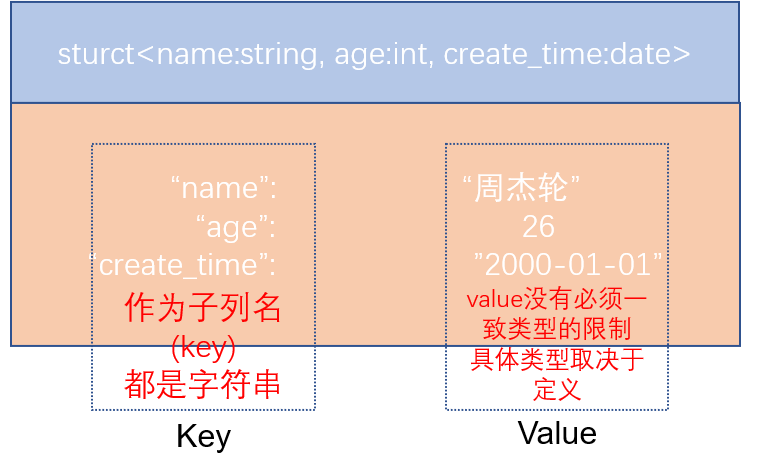
-
有如下数据文件,说明:字段之间#分割,struct之间冒号分割
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23
- 建表语句
create table myhive.test struct(id string, info struct) row format delimited fields terminated by '#' COLLECTION ITEMS TERMINATED BY ':'; - 导入数据
load data local inpath ' /home /hadoop/data_for_struct_type.txt' into table - 常用查询
select * from hive struct; #直接使用列名。子列名即可从struct中取出子列查询 select ip,info.name from hive struct;
2.11.4 三种结构总结









![【SpringMVC]获取参数的六种方式](https://img-blog.csdnimg.cn/d322583089054b0dbc51fc415d5691ea.png)
