列存储(analyze)
- AcquireSampleCStoreRows 函数
- es_get_attnums_to_analyze 函数
- CStoreRelGetCUNumByNow 函数
- CStore::GetLivedRowNumbers 函数
- InitGetValFunc 函数
- CStoreGetfstColIdx 函数
- CStore::GetCUDesc 函数
- CStore::IsTheWholeCuDeleted 函数
- CStore::IsTheWholeCuDeleted 函数
- CStore::CudescTupGetMinMaxDatum 函数
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档
AcquireSampleCStoreRows 函数
在前一章中(列存储(analyze)(三)),我们对函数 acquire_sample_rows 进行了学习,其中acquire_sample_rows 函数的作用是在 PostgreSQL 数据库中执行抽样操作,用于获取数据表的随机样本行。这个函数的主要目的是估计数据表的统计信息和数据分布,以帮助查询优化器生成更有效的执行计划。
本章,我们紧接着来看另一种数据库抽样操作 AcquireSampleCStoreRows ,该函数也是我们所需关注的重点,是本【OpenGauss源码学习 —— 列存储(analyze)】系列的重点和最终学习目标。AcquireSampleCStoreRows 是用于列式存储引擎(如列存储数据库表)的函数。它是为了从列存储表中获取样本数据而设计的,通常用于分析和统计查询中,以获取表的随机样本,以便估计表的统计信息和数据分布。
其中,函数 AcquireSampleCStoreRows 的调用关系与 acquire_sample_rows 相同,如下所示:do_analyze_rel -> get_target_rows -> AcquireSampleCStoreRows。
函数的入参含义如下:
- Relation onerel: 被分析的关系(表)的 Relation 结构,表示要进行样本抽样的目标表。调试信息如下:
- int elevel: 日志消息的错误级别。用于确定错误消息的日志级别。
- HeapTuple* rows: 一个用于存储样本数据的数组。函数将抽样的行数据存储在这个数组中。
- int64 targrows: 目标抽样行数,即希望从表中抽取的行数。
- double* totalrows: 用于存储表的估计总行数的指针。函数将估计的总行数存储在这个指针指向的变量中。
- double* totaldeadrows: 用于存储表的估计死行数的指针。函数将估计的死行数存储在这个指针指向的变量中。
- VacAttrStats** vacattrstats: 一个 VacAttrStats 结构的数组,表示用于分析的每个属性的统计信息。这些统计信息包括样本数据的属性分布等。
- int analyzeAttrNum: 要分析的属性的数量。表示要分析的属性数量。


AcquireSampleCStoreRows 函数的作用和目的是执行列存储表格的抽样操作,以获取列存储表格的随机样本行。AcquireSampleCStoreRows 函数源码如下:(路径:src/gausskernel/optimizer/commands/analyze.cpp)
*
* AcquireSampleCStoreRows -- acquire a random sample of rows from the table
*
* Selected rows are returned in the caller-allocated array rows[], which
* must have at least targrows entries.
* The actual number of rows selected is returned as the function result.
* We also estimate the total number of live and dead rows in the table,
* and return them into *totalrows and *totaldeadrows, respectively.
*
* To improve the analyze efficiency in the condition of severl attrs are selected,
* we add two parameters which record the information of seleced attrs.The perform
* can only used for column storage table.
*
* The returned list of tuples is in order by physical position in the table.
* (We will rely on this later to derive correlation estimates.)
*/
template <bool estimate_table_rownum>
static int64 AcquireSampleCStoreRows(Relation onerel, int elevel, HeapTuple* rows, int64 targrows, double* totalrows,
double* totaldeadrows, VacAttrStats** vacattrstats, int analyzeAttrNum)
{
int64 numrows = 0; /* 当前在样本中的行数 */
int64 delta_numrows = 0; /* 当前在样本中的差异表行数 */
int32 samplerows = 0; /* 收集的总行数 */
int64 liverows = 0; /* 观察到的存活行数 */
int64 deadrows = 0; /* 观察到的已删除行数 */
BlockNumber totalblocks = 0; /* 总块数 */
BlockNumber estBlkNum = 0; /* 估算的块数 */
BlockSamplerData bs; /* 块采样数据结构 */
double rstate; /* 随机状态 */
AnlPrefetch anlprefetch; /* 预取设置 */
int cusize_threshold = maxAnalyzeUseCstoreBufferSize; /* CU大小阈值 */
anlprefetch.blocklist = NULL; /* 预取块列表初始化为空 */
AssertEreport(targrows > 0, MOD_OPT, "采样时目标行数必须大于0");
/*
* 所有系统表都是行存储表,列存储表必须是用户定义的表,
* 因此我们只返回而不采样。
*/
if (IS_PGXC_COORDINATOR) {
*totalrows = 0;
*totaldeadrows = 0;
return 0;
}
/* 为扩展的统计信息准备 */
Bitmapset* bms_attnums = es_get_attnums_to_analyze(vacattrstats, analyzeAttrNum);
int num_attnums = bms_num_members(bms_attnums); /* 统计属性的数量 */
int colTotalNum = onerel->rd_att->natts; /* 表中总的列数 */
int32* attrSeq = NULL; /* 属性顺序 */
int16* colIdx = (int16*)palloc0(sizeof(int16) * num_attnums); /* 列索引数组 */
int* slotIdList = NULL; /* CU槽位索引数组 */
CStoreScanDesc cstoreScanDesc = NULL; /* 列存储扫描描述符 */
CU** cuPtr = NULL; /* CU指针数组 */
Relation deltarel = NULL; /* 差异表 */
double totalRowCnts = 0; /* 总行数 */
double deltarows = 0; /* 差异表的行数 */
double curows = 0; /* CU中的行数 */
double cudeadrows = 0; /* CU中的已删除行数 */
/* 首先考虑差异关系(delta relation) */
Assert(OidIsValid(onerel->rd_rel->reldeltarelid));
/* 打开差异表。我们只需要对其进行 AccessShareLock。 */
deltarel = relation_open((onerel->rd_rel->reldeltarelid), AccessShareLock);
/* 从差异关系中仅获取总行数的估计 */
delta_numrows = acquire_sample_rows<true>(deltarel, elevel, rows, targrows, &deltarows, totaldeadrows);
/* 在这里将 nulls 设置为 true,并且那些不需要分析的属性将始终为 null */
for (int i = 0; i < num_attnums; ++i) {
colIdx[i] = bms_first_member(bms_attnums);
}
/* 为当前分析初始化本地快照(local snapshot)。 */
Snapshot tmpSnapshot = GetActiveSnapshot();
Assert(tmpSnapshot != NULL);
cstoreScanDesc = CStoreBeginScan(onerel, num_attnums, colIdx, tmpSnapshot, false);
// 开始对列存储表进行扫描,准备抽样
// onerel: 当前关系
// num_attnums: 要分析的属性数量
// colIdx: 要分析的属性列的索引
// tmpSnapshot: 当前快照
// false: 是否是 Delta 表的扫描
totalblocks = CStoreRelGetCUNumByNow(cstoreScanDesc);
// 获取当前 CU 的数量,用于统计
curows = (double)cstoreScanDesc->m_CStore->GetLivedRowNumbers(&deadrows);
// 从 CU 中获取存活行数,并更新 deadrows
// curows: CU 中存活的行数
// deadrows: 已删除的行数
if (curows <= 0.0) {
// 如果存活行数小于等于0,则没有需要分析的数据
relation_close(deltarel, AccessShareLock); // 关闭 Delta 表
CStoreEndScan(cstoreScanDesc); // 结束对列存储表的扫描
pfree_ext(colIdx); // 释放 colIdx 的内存
pfree_ext(bms_attnums); // 释放 bms_attnums 的内存
return 0; // 返回0,表示没有进行抽样
}
*totalrows = totalRowCnts = curows + deltarows;
// 设置总行数为存活行数加上 Delta 表的行数
// totalrows: 总行数
// totalRowCnts: 存活行数加上 Delta 表的行数
cudeadrows = (double)deadrows;
*totaldeadrows += cudeadrows;
// 更新总的已删除行数
deadrows = 0; // 在非 pretty 模式下重用 deadrows 来存储已删除元组的数量
/* for pretty mode we just return actual lived rows */
if (estimate_table_rownum && SUPPORT_PRETTY_ANALYZE) {
// 如果是 "pretty" 模式并且需要估算表的行数
// "pretty" 模式通常用于漂亮的输出,返回实际存活的行数,而不进行估算
/* only get estimate rows, free delta rows and close relation */
// 只获取估算的行数,释放 Delta 表的行并关闭关系
for (int i = 0; i < delta_numrows; i++) {
if (rows[i]) {
pfree_ext(rows[i]); // 释放行的内存
rows[i] = NULL;
}
}
relation_close(deltarel, AccessShareLock); // 关闭 Delta 表
CStoreEndScan(cstoreScanDesc); // 结束对列存储表的扫描
pfree_ext(colIdx); // 释放 colIdx 的内存
pfree_ext(bms_attnums); // 释放 bms_attnums 的内存
return 0; // 返回0,表示没有进行抽样
}
attrSeq = (int*)palloc0(sizeof(int32) * num_attnums);
// 分配内存以存储属性的顺序
slotIdList = (int*)palloc0(sizeof(int) * num_attnums);
// 分配内存以存储槽位的列表
cuPtr = (CU**)palloc0(sizeof(CU*) * colTotalNum);
// 分配内存以存储 CU 指针的数组
if (!estimate_table_rownum) {
// 如果不需要估算表的行数(非 pretty 模式)
/* free rows */
// 释放之前分配的行内存
for (int i = 0; i < delta_numrows; i++) {
if (rows[i]) {
pfree_ext(rows[i]);
rows[i] = NULL;
}
}
int64 deltatargrows = 0;
// 初始化 Delta 表的目标行数为0
/* recalculate target num */
// 重新计算目标行数,以根据 Delta 表的情况进行调整
if (deltarows > 0) {
// 如果 Delta 表中有存活的行
deltatargrows = (int)rint(targrows * deltarows / totalRowCnts);
// 根据存活行数比例重新计算目标行数
/* Make sure we don't overrun due to roundoff error */
// 确保不因四舍五入误差而超出目标行数
deltatargrows = Min(deltatargrows, targrows);
// 限制目标行数不超过原始目标行数
if (deltatargrows > 0) {
double trows = 0;
double tdrows = 0;
/* Fetch a random sample of the delta table's rows */
// 从 Delta 表中获取随机样本行
delta_numrows = acquire_sample_rows<false>(deltarel, elevel, rows, deltatargrows, &trows, &tdrows);
// 重新抽样 Delta 表
/* fix total rows */
// 更新总行数和已删除行数
*totalrows = trows + curows;
*totaldeadrows = tdrows + cudeadrows;
}
}
/* change cstore target num */
// 调整列存储表的目标行数
int64 temp_target = (int)rint(targrows * curows / totalRowCnts);
/* Make sure we don't overrun due to roundoff error */
// 确保不因四舍五入误差而超出目标行数
temp_target = Min(temp_target, targrows - deltatargrows);
targrows = temp_target;
/*
* calculate cu number by following formula
* 1. get lived row number
* 2. estimate row size by suppose the width of each column is 4
* 3. estimate how many pages needed if it's row-stored
* 4. evaluate how many CUs needed to sample
*/
// 通过以下公式计算 CU 数:
// 1. 获取存活行数
// 2. 假定每列的宽度为4,估算行大小
// 3. 估算如果是按行存储需要多少页
// 4. 评估需要采样的 CU 数
int totalwidth = 0;
int relpages = 0;
BlockNumber sampleCUs = 0;
totalwidth = 4 * onerel->rd_att->natts;
relpages = ceil(*totalrows * totalwidth / BLCKSZ);
if (relpages == 0) {
relpages = 1;
}
sampleCUs = ceil((double)targrows / relpages * totalblocks);
sampleCUs = (sampleCUs > totalblocks) ? totalblocks : sampleCUs;
elog(DEBUG2, "ANALYZE INFO : sample %u cu from totoal %u cu", sampleCUs, totalblocks);
// 输出采样的 CU 数和总 CU 数
BlockSampler_Init(&bs, totalblocks, sampleCUs);
} else {
AssertEreport(!SUPPORT_PRETTY_ANALYZE, MOD_OPT, "");
// 如果需要估算表的行数,并且不支持 "pretty" 模式分析,则直接采样指定数量的行
BlockSampler_Init(&bs, totalblocks, targrows);
elog(DEBUG2, "ANALYZE INFO : sample %ld rows from totoal %u cu", targrows, totalblocks);
}
rstate = anl_init_selection_state(targrows);
// 初始化行采样状态
/* Prepare for sampling rows */
// 为行采样做准备
CStore* cstore = cstoreScanDesc->m_CStore;
Form_pg_attribute* attrs = cstore->m_relation->rd_att->attrs;
GetValFunc* getValFuncPtr = (GetValFunc*)palloc(sizeof(GetValFunc) * colTotalNum);
/* change sample rows pointer */
// 移动指针以指向下一个要采样的行
rows += delta_numrows;
for (int col = 0; col < num_attnums; ++col) {
int colSeq = attrSeq[col] = colIdx[col] - 1;
// 获取列的顺序,并将其保存在 attrSeq 数组中
InitGetValFunc(attrs[colSeq]->attlen, getValFuncPtr, colSeq);
// 初始化获取列值的函数指针
}
ADIO_RUN()
{
uint32 quantity = (uint32)CSTORE_ANALYZE_PREFETCH_QUANTITY;
// 获取预取数量
anlprefetch.fetchlist1.size = (uint32)((quantity > (totalblocks / 2 + 1)) ? (totalblocks / 2 + 1) : quantity);
// 设置第一个预取列表的大小,限制在总块数的一半加一以内
anlprefetch.fetchlist1.blocklist = (BlockNumber*)palloc(sizeof(BlockNumber) * anlprefetch.fetchlist1.size);
// 为第一个预取列表分配内存
anlprefetch.fetchlist1.anl_idx = 0;
anlprefetch.fetchlist1.load_count = 0;
anlprefetch.fetchlist2.size = anlprefetch.fetchlist1.size;
// 第二个预取列表与第一个相同大小
anlprefetch.fetchlist2.blocklist = (BlockNumber*)palloc(sizeof(BlockNumber) * anlprefetch.fetchlist2.size);
// 为第二个预取列表分配内存
anlprefetch.fetchlist2.anl_idx = 0;
anlprefetch.fetchlist2.load_count = 0;
anlprefetch.init = false;
// 初始化预取状态为未完成
ereport(DEBUG1,
(errmodule(MOD_ADIO),
errmsg("analyze prefetch for %s prefetch quantity(%u)",
RelationGetRelationName(onerel),
anlprefetch.fetchlist1.size)));
// 发送调试信息,表示进行分析预取,显示表名和预取数量
}
ADIO_END();
MemoryContext sample_context; // 用于存储抽样数据的内存上下文
MemoryContext old_context; // 保存当前内存上下文,以便稍后恢复
BlockNumber targblock; // 目标块号
int fstColIdx = CStoreGetfstColIdx(onerel); // 获取列存储表的第一列索引
Datum* constValues = (Datum*)palloc(sizeof(Datum) * colTotalNum); // 存储常量值的数组
bool* nullValues = (bool*)palloc(sizeof(bool) * colTotalNum); // 存储空值信息的数组
Datum* values = (Datum*)palloc0(sizeof(Datum) * colTotalNum); // 存储数据值的数组,初始化为零
bool* nulls = (bool*)palloc0(sizeof(bool) * colTotalNum); // 存储是否为 null 值的数组,初始化为 false
int* funcIdx = (int*)palloc0(sizeof(int) * colTotalNum); // 存储函数索引的数组,初始化为零
List* sampleTupleInfo = NIL; // 存储抽样元组信息的列表
sample_tuple_cell* st_cell = NULL; // 抽样元组单元格
ListCell* cell1 = NULL; // 用于遍历列表的 ListCell 指针
ListCell* cell2 = NULL; // 用于遍历列表的 ListCell 指针
ListCell* cell3 = NULL; // 用于遍历列表的 ListCell 指针
// 创建一个新的内存上下文,用于存储抽样数据,设置上下文名称和大小参数
sample_context = AllocSetContextCreate(CurrentMemoryContext,
"sample cstore rows for analyze",
ALLOCSET_DEFAULT_MINSIZE,
ALLOCSET_DEFAULT_INITSIZE,
ALLOCSET_DEFAULT_MAXSIZE);
while (
InvalidBlockNumber != (targblock = BlockSampler_GetBlock<true>(
cstoreScanDesc, &bs, &anlprefetch, num_attnums, attrSeq, estimate_table_rownum))) {
List* valueLocation = NIL; // 存储值的位置信息的列表
List* targoffsetList = NIL; // 存储目标偏移量的列表
int location = 0; // 当前位置
CUDesc cuDesc; // 列存储单元描述
uint16 targoffset = 0; // 目标偏移量
uint16 maxoffset; // 最大偏移量
int64 total_cusize = 0; // 总共的列存储单元大小
int start_col = -1; // 起始列索引
int end_col = -1; // 结束列索引
bool first_batch = true; // 是否是第一批次
bool all_in_buffer = true; // 是否所有数据都在缓冲区内
targblock = targblock + FirstCUID + 1; // 计算目标块号
// 如果获取列存储单元描述失败,则继续下一次循环
if (cstoreScanDesc->m_CStore->GetCUDesc(fstColIdx, targblock, &cuDesc, tmpSnapshot) != true)
continue;
// 如果启用工作负载控制,进行 IO 调度和更新
if (ENABLE_WORKLOAD_CONTROL)
IOSchedulerAndUpdate(IO_TYPE_READ, 1, IO_TYPE_COLUMN);
cstore->GetCUDeleteMaskIfNeed(targblock, tmpSnapshot); // 获取列存储单元删除掩码
// 如果该列存储单元内的所有元组都已删除,则继续下一次循环
if (cstore->IsTheWholeCuDeleted(cuDesc.row_count))
continue;
maxoffset = cuDesc.row_count;
if (estimate_table_rownum) {
liverows = maxoffset;
estBlkNum++;
if (liverows > 0)
break;
ereport(DEBUG1,
(errmsg("ANALYZE INFO : estimate total rows of \"%s\" - no lived rows in cuid: %u",
RelationGetRelationName(onerel),
targblock)));
totalblocks--;
continue;
}
/* 重置 null 标志和常量值标志以供下一个块使用 */
errno_t rc;
// 将 nulls 数组的所有元素设置为 true
rc = memset_s(nulls, sizeof(bool) * colTotalNum, true, sizeof(bool) * colTotalNum);
securec_check(rc, "\0", "\0");
// 将 nullValues 数组的所有元素设置为 false
rc = memset_s(nullValues, sizeof(bool) * colTotalNum, false, sizeof(bool) * colTotalNum);
securec_check(rc, "\0", "\0");
// 将 constValues 数组的所有元素设置为 0
rc = memset_s(constValues, sizeof(Datum) * colTotalNum, 0, sizeof(Datum) * colTotalNum);
securec_check(rc, "\0", "\0");
/* copy data from cu buffer */
#define copy_sample_dataum(dest, col_num, offset) \
do { \
old_context = MemoryContextSwitchTo(sample_context); \
Datum dm = getValFuncPtr[colNum][funcIdx[colNum]](cuPtr[colNum], (offset)); \
int16 valueTyplen = attrs[(col_num)]->attlen; \
bool valueTypbyval = attrs[(col_num)]->attlen == 0 ? false : true; \
if (valueTyplen < 0) \
(dest) = PointerGetDatum(PG_DETOAST_DATUM_COPY(dm)); \
else \
(dest) = datumCopy(dm, valueTypbyval, valueTyplen); \
(void)MemoryContextSwitchTo(old_context); \
} while (0)
/*
* 检查是否选择了特定的行进行分析
* 1. 跳过已删除的行(死行)
* 2. 如果已获取的行数 < 目标行数,则获取所有行
* 3. 随机选择一个位置替换一个元组
*/
#define check_match_tuple(copyTuple) \
do { \
(copyTuple) = false; \
if (cstore->IsDeadRow((uint32)targblock, (uint32)targoffset)) { \
deadrows++; \
} else if (numrows < targrows) { \
(copyTuple) = true; \
location = numrows; \
numrows++; \
samplerows++; \
} else { \
if (0 >= anl_get_next_S(samplerows, targrows, &rstate)) { \
location = (int64)(targrows * anl_random_fract()); \
(copyTuple) = true; \
AssertEreport(location >= 0 && location < targrows, MOD_OPT, ""); \
} \
samplerows++; \
} \
} while (0)
#define load_cu_data(s_col, e_col, values, nulls, copy) \
do { \
for (int col1 = (s_col); col1 <= (e_col); ++col1) { \
int colNum = attrSeq[col1]; \
if (cuPtr[colNum]) { \
if (cuPtr[colNum]->IsNull(targoffset)) { \
(nulls)[colNum] = true; \
(values)[colNum] = 0; \
} else { \
(nulls)[colNum] = false; \
if (copy) \
copy_sample_dataum((values)[colNum], colNum, targoffset); \
else \
(values)[colNum] = getValFuncPtr[colNum][funcIdx[colNum]](cuPtr[colNum], targoffset); \
} \
} else { \
(nulls)[colNum] = nullValues[colNum]; \
(values)[colNum] = constValues[colNum]; \
} \
} \
} while (0)
/*
* 试图加载所有的CU数据到cstore_buffers中:
* 1. 如果总CU大小小于cstore_buffers的1/8,将所有CU加载到CU缓冲区。
* 2. 如果总CU大小大于或等于cstore_buffers的1/8,将样本数据复制到临时内存以避免固定太多的CU。
*/
for (int col = 0; col < num_attnums; ++col) {
int colNum = attrSeq[col];
cuPtr[colNum] = NULL;
slotIdList[col] = CACHE_BLOCK_INVALID_IDX;
// 如果是当前处理的第一个列
if (-1 == start_col)
start_col = col;
end_col = col;
// 获取CU描述符
(void)cstore->GetCUDesc(colNum, targblock, &cuDesc, tmpSnapshot);
if (cuDesc.IsNullCU()) {
nullValues[colNum] = true;
constValues[colNum] = 0;
elog(DEBUG2,
"ANALYZE INFO - 表 \"%s\":attnum(%d),cuid(%u) 为空",
RelationGetRelationName(onerel),
colNum,
targblock);
continue;
} else if (cuDesc.IsSameValCU()) {
bool shoulFree = false;
nullValues[colNum] = false;
// 从CU描述符中获取常量值
old_context = MemoryContextSwitchTo(sample_context);
constValues[colNum] = CStore::CudescTupGetMinMaxDatum(&cuDesc, attrs[colNum], true, &shoulFree);
(void)MemoryContextSwitchTo(old_context);
elog(DEBUG2,
"ANALYZE INFO - 表 \"%s\":attnum(%d),cuid(%u) 包含常量值",
RelationGetRelationName(onerel),
colNum,
targblock);
continue;
} else {
nullValues[colNum] = false;
constValues[colNum] = 0;
// 获取CU数据并缓存
cuPtr[colNum] = cstore->GetCUData(&cuDesc, colNum, attrs[colNum]->attlen, slotIdList[col]);
funcIdx[colNum] = cuPtr[colNum]->HasNullValue() ? 1 : 0;
// 在每个CU的IO操作之前检查是否开启了Vacuum延迟。如果可以从CU缓存中获取CU数据,我们应该减少AMAP的调用次数。
vacuum_delay_point();
// 断言CU数据不是压缩的
AssertEreport(!cuPtr[colNum]->m_cache_compressed, MOD_OPT, "");
total_cusize += cuPtr[colNum]->GetUncompressBufSize();
/*
* 如果总CU大小小于cusize_threshold并且(或者是最后一列,以确保所有样本CU数据都已加载到临时内存中),
* 则继续下一列的处理。
*/
if (total_cusize < cusize_threshold && (first_batch || (num_attnums - 1) != col))
continue;
if (NIL == sampleTupleInfo) {
ereport(LOG,
(errmsg(
"ANALYZE INFO - 表 \"%s\":从CU缓冲区复制数据", RelationGetRelationName(onerel)),
errdetail("增加cstore_buffers的大小以避免复制数据")));
}
elog(DEBUG2,
"ANALYZE INFO - 表 \"%s\":复制列数据 [%d, %d] 从CU缓冲区",
RelationGetRelationName(onerel),
start_col,
end_col);
}
all_in_buffer = false;
if (first_batch) {
/* 处理第一个批次的CU数据,我们应该首先初始化sample_tuple_cell */
bool copyTuple = false;
cell1 = list_head(sampleTupleInfo) ? list_head(sampleTupleInfo) : NULL;
for (targoffset = FirstOffsetNumber - 1; targoffset < maxoffset; targoffset++) {
check_match_tuple(copyTuple);
if (!copyTuple)
continue;
if (cell1 != NULL) {
errno_t rc;
st_cell = (sample_tuple_cell*)lfirst(cell1);
rc = memset_s(st_cell->nulls, sizeof(bool) * colTotalNum, true, sizeof(bool) * colTotalNum);
securec_check(rc, "\0", "\0");
rc = memset_s(st_cell->values, sizeof(Datum) * colTotalNum, 0, sizeof(Datum) * colTotalNum);
securec_check(rc, "\0", "\0");
} else {
errno_t rc;
st_cell = (sample_tuple_cell*)palloc0(sizeof(sample_tuple_cell));
sampleTupleInfo = lappend(sampleTupleInfo, st_cell);
st_cell->nulls = (bool*)palloc(sizeof(bool) * colTotalNum);
rc = memset_s(st_cell->nulls, sizeof(bool) * colTotalNum, true, sizeof(bool) * colTotalNum);
securec_check(rc, "\0", "\0");
st_cell->values = (Datum*)palloc0(sizeof(Datum) * colTotalNum);
}
valueLocation = lappend_int(valueLocation, location);
targoffsetList = lappend_int(targoffsetList, targoffset);
// 加载CU数据
load_cu_data(start_col, end_col, st_cell->values, st_cell->nulls, true);
cell1 = (cell1 && lnext(cell1)) ? lnext(cell1) : NULL;
}
for (int col1 = start_col; col1 <= end_col; ++col1) {
if (IsValidCacheSlotID(slotIdList[col1]))
CUCache->UnPinDataBlock(slotIdList[col1]);
}
first_batch = false;
AssertEreport(sampleTupleInfo, MOD_OPT, "");
} else {
/* 已经建立了sample_tuple_cell,只需将数据从缓冲区复制到临时内存中 */
AssertEreport(sampleTupleInfo, MOD_OPT, "");
forboth(cell1, sampleTupleInfo, cell3, targoffsetList)
{
st_cell = (sample_tuple_cell*)lfirst(cell1);
targoffset = lfirst_int(cell3);
// 加载CU数据
load_cu_data(start_col, end_col, st_cell->values, st_cell->nulls, true);
}
for (int col1 = start_col; col1 <= end_col; ++col1) {
if (IsValidCacheSlotID(slotIdList[col1]))
CUCache->UnPinDataBlock(slotIdList[col1]);
}
}
start_col = -1;
}
if (all_in_buffer) {
/* 已经将所有的CU加载到CU缓冲区,直接使用CU缓冲区数据构建元组 */
bool copyTuple = false;
// 断言已处理的列范围正确
AssertEreport(0 == start_col && end_col == num_attnums - 1, MOD_OPT, "");
for (targoffset = FirstOffsetNumber - 1; targoffset < maxoffset; targoffset++) {
check_match_tuple(copyTuple);
if (!copyTuple)
continue;
// 加载CU数据到元组
load_cu_data(0, num_attnums - 1, values, nulls, false);
tableam_tops_free_tuple(rows[location]);
// 使用CU数据构建HeapTuple
rows[location] = (HeapTuple)tableam_tops_form_tuple(onerel->rd_att, values, nulls, HEAP_TUPLE);
ItemPointerSet(&(rows[location])->t_self, targblock, targoffset + 1);
}
for (int col1 = 0; col1 < num_attnums; ++col1) {
if (IsValidCacheSlotID(slotIdList[col1]))
CUCache->UnPinDataBlock(slotIdList[col1]);
}
} else {
/* 使用临时内存中的数据构建元组 */
AssertEreport(end_col == num_attnums - 1, MOD_OPT, "");
forthree(cell1, sampleTupleInfo, cell2, valueLocation, cell3, targoffsetList)
{
st_cell = (sample_tuple_cell*)lfirst(cell1);
location = lfirst_int(cell2);
targoffset = lfirst_int(cell3);
tableam_tops_free_tuple(rows[location]);
// 使用临时内存中的数据构建HeapTuple
rows[location] = (HeapTuple)tableam_tops_form_tuple(onerel->rd_att, st_cell->values, st_cell->nulls, HEAP_TUPLE);
ItemPointerSet(&(rows[location])->t_self, targblock, targoffset + 1);
}
// 释放临时列表
list_free_ext(valueLocation);
list_free_ext(targoffsetList);
}
// 重置内存上下文
MemoryContextReset(sample_context);
/* 步骤 4:释放内存 */
pfree_ext(nullValues);
pfree_ext(constValues);
pfree_ext(nulls);
pfree_ext(values);
pfree_ext(attrSeq);
pfree_ext(colIdx);
pfree_ext(funcIdx);
pfree_ext(cuPtr);
pfree_ext(slotIdList);
pfree_ext(getValFuncPtr);
list_free_ext(sampleTupleInfo);
pfree_ext(bms_attnums);
/* 删除内存上下文 */
MemoryContextDelete(sample_context);
ADIO_RUN()
{
pfree_ext(anlprefetch.fetchlist1.blocklist);
pfree_ext(anlprefetch.fetchlist2.blocklist);
}
ADIO_END();
/* 步骤 5:关闭 delta 表并结束 cstore 扫描 */
relation_close(deltarel, AccessShareLock);
CStoreEndScan(cstoreScanDesc);
if (estimate_table_rownum) {
/* 在非 pretty 模式下估算总行数 */
AssertEreport(!SUPPORT_PRETTY_ANALYZE, MOD_OPT, "");
if (totalblocks == 0 || (totalblocks > 0 && liverows > 0)) {
*totalrows = liverows * totalblocks + deltarows;
} else {
/* 目标 300 行的所有块都是死行。 */
*totalrows = INVALID_ESTTOTALROWS + targrows;
}
ereport(elevel,
(errmsg("ANALYZE INFO : \"%s\":扫描了 %u 个 CU,目标 cuid:%u,"
"包含 %ld 个活动行, %ld 个死亡行,估计总行数 %.0f",
RelationGetRelationName(onerel),
estBlkNum,
totalblocks,
targblock,
liverows,
deadrows,
*totalrows)));
return numrows + delta_numrows;
}
/*
* 步骤 6:对行进行排序并估算 reltuples
*
* 如果我们没有找到所需数量的元组,则无需排序,因为它们已经有序。
*
* 否则,我们需要根据位置(itempointer)对收集的元组进行排序。
* 不值得担心已经有序的边界情况。
*/
if (numrows == targrows)
qsort((void*)rows, numrows, sizeof(HeapTuple), compare_rows);
/* 在数据节点中,输出一些有趣的关系信息 */
if (IS_PGXC_DATANODE) {
ereport(elevel,
(errmsg("ANALYZE INFO : \"%s\":扫描了 %d 个 CU,样本 %ld 行,估算总 %.0f 行",
RelationGetRelationName(onerel),
bs.m,
totalblocks,
numrows,
*totalrows)));
}
return numrows + delta_numrows;
该函数的关键部分和作用如下:
- 获取样本数据: 函数通过对表格的列存储块进行抽样,获取一定数量的行数据,这些行数据将用于后续的分析和统计。
- 估算总行数和死行数: 函数会估算列存储表格的总行数和死行数。总行数是表格中的所有行数,而死行数是已标记为删除的行数。
- 处理 delta 表: 如果表格具有 delta 表(差异表),函数会首先尝试从 delta 表中获取样本数据,以提高估算的准确性。
- 数据处理: 函数根据样本数据中的 null 值、常量值等信息进行数据处理,包括处理列的数据类型和 null 值。
- 样本数据排序: 如果成功获取了样本数据,并且样本数据数量达到了目标数量,函数会对样本数据进行排序,以确保它们按照物理位置在表格中的顺序排列。
- 输出结果: 函数会返回实际获取的样本数据行数,以及估算的总行数和死行数。这些信息将用于查询优化和统计信息收集。
- 其他功能: 函数还包括一些额外的功能,例如处理样本数据的方式(复制到临时内存或直接在 CU 缓冲区中操作)、IO 调度(根据优化器的要求进行数据加载)等。
es_get_attnums_to_analyze 函数
es_get_attnums_to_analyze 函数用于获取需要进行分析的所有列的 attnum(属性号),包括单列统计和多列统计。
- 参数:
- vacattrstats:VacAttrStats 数组,包含要分析的列的统计信息。
- vacattrstats_size:VacAttrStats 数组的大小。
- 返回值:
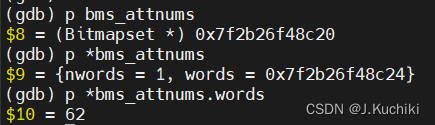
- Bitmapset*:一个位图集合,包含所有需要分析的列的 attnum。调试信息如下:
- 函数逻辑:
- 创建一个名为 bms_attnum 的位图集合,用于存储需要分析的列的 attnum。
- 使用两个嵌套的循环遍历 vacattrstats 数组和其中的每个 VacAttrStats 元素。
(1)外循环遍历 vacattrstats 数组。
(2)内循环遍历每个 VacAttrStats 元素的属性列表,属性列表存储在 attrs 成员中。- 在内循环中,获取每个属性的 attnum(属性号)并将其添加到 bms_attnum 中,使用 bms_add_member 函数。
- 最终,函数返回一个位图集合 bms_attnum,其中包含了需要进行分析的所有列的 attnum。
函数源码如下:(路径:src/common/backend/utils/adt/extended_statistics.cpp)
/*
* es_get_attnums_to_analyze
* get all attnums to be analyzed, including single column stats and multi-column stats
*
* @param (in) vacattrstats:
* the VacAttrStats array
* @param (in) vacattrstats_size:
* the size of the VacAttrStats array
*
* @return:
* a Bitmapset including all columns' attnum
*/
Bitmapset* es_get_attnums_to_analyze(VacAttrStats** vacattrstats, int vacattrstats_size)
{
Bitmapset* bms_attnum = NULL;
for (int i = 0; i < vacattrstats_size; ++i) {
for (unsigned int j = 0; j < vacattrstats[i]->num_attrs; ++j) {
int2 attnum = vacattrstats[i]->attrs[j]->attnum;
bms_attnum = bms_add_member(bms_attnum, attnum);
}
}
return bms_attnum;
}
CStoreRelGetCUNumByNow 函数
CStoreRelGetCUNumByNow 函数用于获取一个列存储(Column Store)表在当前时刻的压缩单元(CU)数量。
- 参数:
- cstoreScanState:列存储扫描描述符,包含了对列存储表的扫描状态信息。
- 返回值:
- uint32:表示当前时刻列存储表的压缩单元数量。
- 函数逻辑:
- 获取与列存储表关联的元组描述符(TupleDesc)和关联(Relation)。
- 打开与列存储表关联的 CUDesc(压缩单元描述)关系和其索引。
(1)cudesc_rel:CUDesc 表的关系。
(2)cudesc_tupdesc:CUDesc 表的元组描述符。
(3)idx_rel:CUDesc 表的索引关系。- 获取列存储表的第一个属性的属性号 attid。
(1)如果第一个属性已经被删除(attisdropped 为真),则获取列存储表中第一个未被删除属性的属性号(fstColIdx 指示第一个未被删除属性的索引)。- 初始化用于检索 CUDesc 表的索引扫描键(ScanKey),以便按照属性号(col_id)查找对应的压缩单元描述。
- 开始有序系统表扫描(SysScanDesc),以获取与指定属性号匹配的压缩单元描述。
- 初始化一个变量 max_cuid,用于存储找到的最大压缩单元编号。将其初始化为 FirstCUID 的值。
- 通过反向扫描(BackwardScanDirection)系统表,查找匹配的压缩单元描述。如果找到匹配的描述,则将其压缩单元编号存储在 max_cuid 中。
- 结束有序系统表扫描。
- 关闭 CUDesc 表的索引和关系。
- 返回压缩单元数量,计算方式为 max_cuid - FirstCUID,即找到的最大压缩单元编号减去起始压缩单元编号 FirstCUID。
函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
// CStoreRelGetCUNumByNow
// 获取当前时刻关系的CU(压缩单元)数量
uint32 CStoreRelGetCUNumByNow(CStoreScanDesc cstoreScanState)
{
ScanKeyData key;
HeapTuple tup;
bool isnull = false;
Relation relation = cstoreScanState->m_CStore->m_relation;
/*
* 打开CUDesc关系和其索引。
* CUDesc关系存储了列存储关系中每个列的CU(压缩单元)的描述信息,
* 索引用于快速检索特定列的CU信息。
*/
Relation cudesc_rel = heap_open(relation->rd_rel->relcudescrelid, AccessShareLock);
TupleDesc cudesc_tupdesc = cudesc_rel->rd_att;
Relation idx_rel = index_open(cudesc_rel->rd_rel->relcudescidx, AccessShareLock);
int attid = relation->rd_att->attrs[0]->attnum;
// 如果列已删除(attisdropped),则选择关系的第一个非删除列。
if (relation->rd_att->attrs[0]->attisdropped) {
int fstColIdx = CStoreGetfstColIdx(relation);
attid = relation->rd_att->attrs[fstColIdx]->attnum;
}
/* 设置扫描键以通过列ID从索引中获取数据。 */
ScanKeyInit(&key, (AttrNumber)CUDescColIDAttr, BTEqualStrategyNumber, F_INT4EQ, Int32GetDatum(attid));
// 开始有序扫描CUDesc关系以获取与列相关的最后一个CU描述。
SysScanDesc cudesc_scan = systable_beginscan_ordered(cudesc_rel, idx_rel, SnapshotNow, 1, &key);
uint32 max_cuid = FirstCUID;
/*
* 优化以获取列的最后一个CU(压缩单元)描述。
* 使用BackwardScanDirection扫描以获取最新的CU描述信息。
*/
if ((tup = systable_getnext_ordered(cudesc_scan, BackwardScanDirection)) != NULL) {
max_cuid = DatumGetUInt32(fastgetattr(tup, CUDescCUIDAttr, cudesc_tupdesc, &isnull));
}
systable_endscan_ordered(cudesc_scan);
index_close(idx_rel, AccessShareLock);
heap_close(cudesc_rel, AccessShareLock);
// 返回最后一个CU的ID,并将其与FirstCUID相减以获得CU的数量。
return (max_cuid - FirstCUID);
}
该函数通常在列存储数据库的查询优化和统计信息收集过程中使用,以了解关系中当前 CU 的数量。
CStore::GetLivedRowNumbers 函数
CStore::GetLivedRowNumbers 函数的作用是计算 CStore 存储引擎中指定关系的存活(未删除)行数,并提供了总删除行数。这个函数通过遍历列存储单元(CU)的描述信息来实现这一目标。
代码的主要步骤如下:
- 初始化变量 rowNumbers 为0,该变量用于存储存活行数。
- 初始化变量 * totaldeadrows 为0,该变量用于存储已删除行数。
- 使用 LoadCUDescCtl 对象 loadInfo 初始化,该对象用于加载CU(压缩单元)的描述信息。
- 进入循环,通过 GetCURowCount 函数获取CU的行数信息,并存储在 loadInfo 中。
- 遍历每个CU的描述信息,获取其行数以及检查是否存在已删除的行。
- 如果存在已删除的行,通过计算位掩码中设置的位数来更新存活行数和已删除行数。
- 继续加载下一个CU的描述信息,直到所有CU都被处理。
- 销毁 loadInfo 对象,释放相关资源。
- 返回存活行数。
其函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/*
* 获取CStore关系的存活行数。
* 该函数计算CStore关系中存活(未删除)行的数量,
* 并提供总删除行数。
*
* @param (out) totaldeadrows:
* 指向存储总删除行数的变量的指针。
*
* @return:
* CStore关系中存活(未删除)行的数量。
*/
int64 CStore::GetLivedRowNumbers(int64* totaldeadrows)
{
int64 rowNumbers = 0; // 初始化变量以存储存活行数。
LoadCUDescCtl loadInfo(m_startCUID); // 创建用于加载CU描述符的控制对象。
*totaldeadrows = 0; // 将总删除行数初始化为零。
// 遍历CU描述符。
while (GetCURowCount(m_firstColIdx, &loadInfo, m_snapshot)) {
CUDesc* cuDescArray = loadInfo.cuDescArray;
// 遍历当前加载的CU描述符数组。
for (uint32 i = 0; i < loadInfo.curLoadNum; ++i) {
GetCUDeleteMaskIfNeed(cuDescArray[i].cu_id, m_snapshot);
// 增加存活行数。
rowNumbers += cuDescArray[i].row_count;
if (m_hasDeadRow) {
int nBytes = (cuDescArray[i].row_count + 7) / 8;
// 遍历位图字节,计算总删除行数。
for (int j = 0; j < nBytes; ++j) {
*totaldeadrows += NumberOfBit1Set[m_cuDelMask[j]];
rowNumbers -= NumberOfBit1Set[m_cuDelMask[j]];
}
}
}
}
loadInfo.Destroy();
InitGetValFunc 函数
InitGetValFunc 函数的主要作用是根据数据类型的字节长度 attlen 初始化一个函数指针数组 getValFuncPtr,用于获取不同数据类型的值。这个函数在分析过程中非常有用,因为它允许针对不同的数据类型选择正确的函数来获取列数据,以确保数据的正确性和高效性。
具体来说,这个函数的作用如下:
- 根据传入的 attlen 参数,确定数据类型的字节长度,以便后续选择合适的函数来处理数据。
- 根据数据类型的字节长度,为该列初始化两个函数指针,一个用于处理带符号的数据,另一个用于处理无符号的数据。这些函数指针会存储在 getValFuncPtr 数组中的特定列中。
- 这些函数指针在分析期间用于获取列数据。根据列的数据类型和是否带符号,选择适当的函数指针,以确保正确地获取数据值。
- 如果传入的 attlen 值不匹配任何已知的数据类型,函数会引发错误,报告不支持的数据类型。
总结:InitGetValFunc 函数为分析过程提供了必要的工具,以根据不同的数据类型获取正确的列数据,确保了数据分析的准确性和效率。
其函数源码如下:(路径:src/gausskernel/optimizer/commands/analyze.cpp)
void InitGetValFunc(int attlen, GetValFunc* getValFuncPtr, int col)
{
switch (attlen) {
case sizeof(uint8): {
getValFuncPtr[col][0] = &GetValue<1, false>;
getValFuncPtr[col][1] = &GetValue<1, true>;
break;
}
case sizeof(uint16): {
getValFuncPtr[col][0] = &GetValue<2, false>;
getValFuncPtr[col][1] = &GetValue<2, true>;
break;
}
case sizeof(uint32): {
getValFuncPtr[col][0] = &GetValue<4, false>;
getValFuncPtr[col][1] = &GetValue<4, true>;
break;
}
case sizeof(uint64): {
getValFuncPtr[col][0] = &GetValue<8, false>;
getValFuncPtr[col][1] = &GetValue<8, true>;
break;
}
case 12: {
getValFuncPtr[col][0] = &GetValue<12, false>;
getValFuncPtr[col][1] = &GetValue<12, true>;
break;
}
case 16: {
getValFuncPtr[col][0] = &GetValue<16, false>;
getValFuncPtr[col][1] = &GetValue<16, true>;
break;
}
case -1: {
getValFuncPtr[col][0] = &GetValue<-1, false>;
getValFuncPtr[col][1] = &GetValue<-1, true>;
break;
}
case -2: {
getValFuncPtr[col][0] = &GetValue<-2, false>;
getValFuncPtr[col][1] = &GetValue<-2, true>;
break;
}
default:
ereport(ERROR, (errcode(ERRCODE_DATATYPE_MISMATCH), errmsg("unsupported datatype")));
}
}
CStoreGetfstColIdx 函数
CStoreGetfstColIdx 函数的主要功能是遍历给定关系 rel 的所有列,并找到第一个未被删除(未被标记为 dropped)的列,然后返回该列的索引(列号)。这个函数通常用于在处理表或关系的列时,需要忽略已删除的列,从而准确地获取第一个有效的列。如果没有未被删除的列,它将返回 0,表示第一列未被删除。其函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/*
* @Description: get the first colum index that is not dropped
* @Param[IN] rel: the target relation
* @Return: the first column index that is not dropped
* @See also:
*/
int CStoreGetfstColIdx(Relation rel)
{
for (int i = 0; i < rel->rd_att->natts; i++) {
if (!rel->rd_att->attrs[i]->attisdropped)
return i;
}
return 0;
}
CStore::GetCUDesc 函数
CStore::GetCUDesc 函数的作用是根据给定的列号(col)和 CU ID(cuid)获取列的 CUDesc(列存储单元描述)。它主要完成以下任务:
- 初始化相关变量和上下文。
- 打开 CUDesc 表和其索引。
- 设置用于索引扫描的扫描键。
- 执行索引扫描,找到匹配的 CUDesc 记录。
- 解析 CUDesc 记录,提取其中的信息并存储到 cuDescPtr 结构中。
- 关闭相关的数据库对象,释放资源。
- 返回是否找到匹配的 CUDesc 记录。如果找到,返回 true;否则,返回 false。
其函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/*
* Get CUDesc of column according to cuid.
* 根据 cuid 获取列的 CUDesc(列存储单元描述)。
*/
bool CStore::GetCUDesc(_in_ int col, _in_ uint32 cuid, _out_ CUDesc* cuDescPtr, _in_ Snapshot snapShot)
{
ScanKeyData key[2];
HeapTuple tup;
bool found = false;
errno_t rc = EOK;
Assert(col >= 0);
// 当切换到下一批 cudesc 数据时,我们将重置 m_perScanMemCnxt。
// 因此,仅在此批次中使用的空间应由 m_perScanMemCnxt 管理。
AutoContextSwitch newMemCnxt(m_perScanMemCnxt);
/*
* 打开 CUDesc 关系和其索引
*/
Relation cudesc_rel = heap_open(m_relation->rd_rel->relcudescrelid, AccessShareLock);
TupleDesc cudesc_tupdesc = cudesc_rel->rd_att;
Relation idx_rel = index_open(cudesc_rel->rd_rel->relcudescidx, AccessShareLock);
bool isFixedLen = m_relation->rd_att->attrs[col]->attlen > 0 ? true : false;
// 转换逻辑 ID 为属性的物理 ID
int attid = m_relation->rd_att->attrs[col]->attnum;
/*
* 设置扫描键以通过 attid 从索引中获取。
*/
ScanKeyInit(&key[0], (AttrNumber)CUDescColIDAttr, BTEqualStrategyNumber, F_INT4EQ, Int32GetDatum(attid));
ScanKeyInit(&key[1], (AttrNumber)CUDescCUIDAttr, BTEqualStrategyNumber, F_OIDEQ, UInt32GetDatum(cuid));
snapShot = (snapShot == NULL) ? GetActiveSnapshot() : snapShot;
Assert(snapShot != NULL);
SysScanDesc cudesc_scan = systable_beginscan_ordered(cudesc_rel, idx_rel, snapShot, 2, key);
// 仅循环一次
while ((tup = systable_getnext_ordered(cudesc_scan, ForwardScanDirection)) != NULL) {
Datum values[CUDescCUExtraAttr] = {0};
bool isnull[CUDescCUExtraAttr] = {0};
char* valPtr = NULL;
heap_deform_tuple(tup, cudesc_tupdesc, values, isnull);
uint32 cu_id = DatumGetUInt32(values[CUDescCUIDAttr - 1]);
Assert(!isnull[CUDescCUIDAttr - 1] && cu_id == cuid && found == false);
cuDescPtr->xmin = HeapTupleGetRawXmin(tup);
cuDescPtr->cu_id = cu_id;
// 将最小值放入 cudesc->cu_min
if (!isnull[CUDescMinAttr - 1]) {
char* minPtr = cuDescPtr->cu_min;
char len_1 = MIN_MAX_LEN;
valPtr = DatumGetPointer(values[CUDescMinAttr - 1]);
if (!isFixedLen) {
*minPtr = (char)VARSIZE_ANY_EXHDR(valPtr);
minPtr = minPtr + 1;
len_1 -= 1;
}
rc = memcpy_s(minPtr, len_1, VARDATA_ANY(valPtr), VARSIZE_ANY_EXHDR(valPtr));
securec_check(rc, "", "");
}
// 将最大值放入 cudesc->cu_max
if (!isnull[CUDescMaxAttr - 1]) {
char* maxPtr = cuDescPtr->cu_max;
char len_2 = MIN_MAX_LEN;
valPtr = DatumGetPointer(values[CUDescMaxAttr - 1]);
if (!isFixedLen) {
*maxPtr = VARSIZE_ANY_EXHDR(valPtr);
maxPtr = maxPtr + 1;
len_2 -= 1;
}
rc = memcpy_s(maxPtr, len_2, VARDATA_ANY(valPtr), VARSIZE_ANY_EXHDR(valPtr));
securec_check(rc, "", "");
}
cuDescPtr->row_count = DatumGetInt32(values[CUDescRowCountAttr - 1]);
Assert(!isnull[CUDescRowCountAttr - 1]);
// 将 CUMode 放入 cudesc->cumode
cuDescPtr->cu_mode = DatumGetInt32(values[CUDescCUModeAttr - 1]);
Assert(!isnull[CUDescCUModeAttr - 1]);
// 将 cusize 放入 cudesc->cu_size
cuDescPtr->cu_size = DatumGetInt32(values[CUDescSizeAttr - 1]);
Assert(!isnull[CUDescSizeAttr - 1]);
// 将 CUPointer 放入 cudesc->cuPointer
char* cu_ptr = DatumGetPointer(values[CUDescCUPointerAttr - 1]);
Assert(!isnull[CUDescCUPointerAttr - 1] && cu_ptr);
rc = memcpy_s(&cuDescPtr->cu_pointer, sizeof(CUPointer), VARDATA_ANY(cu_ptr), sizeof(CUPointer));
securec_check(rc, "", "");
Assert(VARSIZE_ANY_EXHDR(cu_ptr) == sizeof(CUPointer));
cuDescPtr->magic = DatumGetUInt32(values[CUDescCUMagicAttr - 1]);
Assert(!isnull[CUDescCUMagicAttr - 1]);
found = true;
}
systable_endscan_ordered(cudesc_scan);
index_close(idx_rel, AccessShareLock);
heap_close(cudesc_rel, AccessShareLock);
return found;
}
CStore::IsTheWholeCuDeleted 函数
CStore::IsTheWholeCuDeleted 函数的作用是根据给定的 cuid(列存储单元 ID)加载相应的删除掩码,以标识是否存在已删除的行。它完成以下任务:
- 初始化相关变量。
- 如果已加载相同的删除掩码,直接返回,无需再次加载。
- 在进行扫描之前,切换到新的内存上下文以管理分配的内存。
- 打开 CUDesc 关系和其索引,以准备执行索引扫描。
- 设置用于索引扫描的扫描键。
- 如果未提供快照,则使用当前活动快照。
- 开始按顺序扫描 CUDesc 关系,查找匹配的记录。
- 如果找到匹配的记录,则提取 CUPointer(列存储单元指针)并相应地处理删除掩码。
- 结束索引扫描并关闭相关的数据库对象。
- 处理异常情况
函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
ull = false;
errno_t rc = EOK;
bool found = false;
// 如果删除掩码已加载,无需再次加载,直接返回
if (m_delMaskCUId == cuid)
return;
// 当切换到下一批 cudesc 数据时,我们将重置 m_perScanMemCnxt。
// 因此,仅在此批次中使用的空间应由 m_perScanMemCnxt 管理。
AutoContextSwitch newMemCnxt(m_perScanMemCnxt);
// 打开 CUDesc 关系和其索引
Relation cudesc_rel = heap_open(m_relation->rd_rel->relcudescrelid, AccessShareLock);
TupleDesc cudesc_tupdesc = cudesc_rel->rd_att;
Relation idx_rel = index_open(cudesc_rel->rd_rel->relcudescidx, AccessShareLock);
// 设置扫描键以通过 attid 从索引中获取。
ScanKeyInit(&key[0], (AttrNumber)CUDescColIDAttr, BTEqualStrategyNumber, F_INT4EQ, Int32GetDatum(VitrualDelColID));
ScanKeyInit(&key[1], (AttrNumber)CUDescCUIDAttr, BTEqualStrategyNumber, F_OIDEQ, UInt32GetDatum(cuid));
// 如果未提供快照,则使用当前活动快照
snapShot = (snapShot == NULL) ? GetActiveSnapshot() : snapShot;
Assert(snapShot != NULL);
// 开始按顺序扫描 cudesc 关系
SysScanDesc cudesc_scan = systable_beginscan_ordered(cudesc_rel, idx_rel, snapShot, 2, key);
if ((tup = systable_getnext_ordered(cudesc_scan, ForwardScanDirection)) != NULL) {
// 将 CUPointer 放入 cudesc->cuPointer
Datum v = fastgetattr(tup, CUDescCUPointerAttr, cudesc_tupdesc, &isnull);
if (isnull)
m_hasDeadRow = false;
else {
m_hasDeadRow = true;
int8* bitmap = (int8*)PG_DETOAST_DATUM(DatumGetPointer(v));
rc = memcpy_s(m_cuDelMask, MaxDelBitmapSize, VARDATA_ANY(bitmap), VARSIZE_ANY_EXHDR(bitmap));
securec_check(rc, "", "");
// 因为可能创建了新的内存,所以我们必须检查并及时释放。
if ((Pointer)bitmap != DatumGetPointer(v)) {
pfree_ext(bitmap);
}
}
found = true;
}
systable_endscan_ordered(cudesc_scan);
index_close(idx_rel, AccessShareLock);
heap_close(cudesc_rel, AccessShareLock);
// 如果未找到对应的删除掩码,则处理异常情况
if (!found) {
TransactionId currGlobalXmin = pg_atomic_read_u64(&t_thrd.xact_cxt.ShmemVariableCache->recentGlobalXmin);
Assert(snapShot->xmin > 0);
if (TransactionIdPrecedes(snapShot->xmin, currGlobalXmin))
ereport(ERROR,
(errcode(ERRCODE_SNAPSHOT_INVALID),
(errmsg("Snapshot too old."),
errdetail("Could not get the old version of CUDeleteBitmap, RecentGlobalXmin: %lu, "
"snapShot->xmin: %lu, snapShot->xmax: %lu",
currGlobalXmin,
snapShot->xmin,
snapShot->xmax),
errhint("This is a safe error report, will not impact data consistency, retry your query if "
"needed."))));
else {
if (m_useBtreeIndex)
m_delMaskCUId = InValidCUID;
else {
// 处理异常情况:CU 删除位图丢失
ereport(PANIC,
(errmsg("CU Delete bitmap is missing."),
errdetail("There might be some issue about cu %u delete bitmap, Please contact HW engineers "
"for support.",
cuid)));
}
}
} else {
// 记录已加载的删除掩码的 cuid
m_delMaskCUId = cuid;
}
return;
}
CStore::IsTheWholeCuDeleted 函数
CStore::IsTheWholeCuDeleted 函数的作用是 判断指定的列存储单元(CU)是否已经完全删除。函数接受一个参数 rowsInCu,表示列存储单元中的行数。
函数内部的逻辑如下:
- 首先,它检查成员变量 m_hasDeadRow 是否为 true,这个变量表示当前列存储中是否包含已删除的行。如果没有已删除的行,那么整个列存储单元就不可能被删除。
- 如果 m_hasDeadRow 为 true,则调用 IsTheWholeCuDeleted 函数来进一步检查列存储单元的删除状态。它将 m_cuDelMask(删除掩码)和 rowsInCu 作为参数传递给 IsTheWholeCuDeleted 函数,以确定列存储单元是否已完全删除。
其中,函数 IsTheWholeCuDeleted 被定义为两个版本,一个版本接受 int 类型的参数,另一个版本接受 char* 类型的参数。目的是优化性能,当没有已删除的行时,不需要执行更复杂的检查,直接返回结果。只有在存在已删除的行时,才需要进一步检查删除状态。
函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
bool CStore::IsTheWholeCuDeleted(int rowsInCu)
{
return m_hasDeadRow && IsTheWholeCuDeleted((char*)m_cuDelMask, rowsInCu);
}
/**
* @Description: 检查该CU内的所有元组是否已删除。
* 如果是,则返回true;否则返回false。
* @param rowsInCu: CU内包含的元组数量
* @param delBitmapPtr: 删除位图
* @return: 如果该位图内的所有元组都已删除,则返回true。
* 如果有任何一个元组是活跃的,则返回false。
* @See also:
*/
bool CStore::IsTheWholeCuDeleted(char* delBitmapPtr, int rowsInCu)
{
// 预先计算用于快速比较的映射数组
static const uint8 map[] = {0, 0x01, 0x03, 0x07, 0x0F, 0x1F, 0x3F, 0x7F, 0xFF};
unsigned int numUint64 = 0;
unsigned int numUint8 = 0;
unsigned int mapIdx = 0;
/*
* numUint64 表示当值的数量为 rowsInCu 时,使用多少个 Uint64 数据;
* 这等于 (rowsInCu/64),因为 Uint64 可以保存 64 位。
* numUint8 表示使用多少个 Uint8 数据,不包括 (numUint64 * 64) 个值;
* 这等于 ((rowsInCu - numUint64 * 64) / 8)。同时我们排除了最后半字节。
*/
compute_factors_of_n((unsigned int)rowsInCu, numUint64, numUint8, mapIdx);
/* 通过将 *delBitmapPtr* 视为 uint64 数组来进行快速比较。*/
uint64* uint64Item = (uint64*)delBitmapPtr;
for (unsigned int i = 0; i < numUint64; ++i) {
if (*uint64Item != 0xFFFFFFFFFFFFFFFF) {
return false;
}
++uint64Item;
}
/* 将剩余部分视为 char 数组来进行比较。*/
uint8* uint8Item = (uint8*)uint64Item;
for (unsigned int i = 0; i < numUint8; ++i) {
if (*uint8Item != 0xFF) {
return false;
}
++uint8Item;
}
/*
* 如果 (rowsInCu != 8*N),则必须特殊处理最后一个字节。
* 我们将使用 *map[]* 直接进行快速比较。
*/
if (mapIdx != 0) {
return (*uint8Item == map[mapIdx]);
}
/* 没问题,整个 CU 已被删除。 */
return true;
}
CStore::CudescTupGetMinMaxDatum 函数
CStore::CudescTupGetMinMaxDatum 函数的作用是从 CUDesc 结构中提取并返回最小或最大值的 Datum 表示。该函数针对不同的列属性信息(pColAttr)以及最小或最大值标志(min),处理不同数据类型和大小的数据,并返回一个 Datum 表示。函数还通过 shouldFree 参数返回一个布尔值,指示是否应该释放提取的数据。函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/**
* @Description: 从CUDesc结构中提取并返回最小或最大值的Datum表示。
* 该函数根据提供的列属性信息,处理不同的数据类型和大小。
* @param pCudesc: CUDesc结构指针,包含了最小和最大值
* @param pColAttr: 列属性的指针,描述了列的数据类型和大小
* @param min: 为true表示提取最小值,为false表示提取最大值
* @param shouldFree: 返回一个布尔值,指示是否应该释放提取的数据
* @return: 表示最小或最大值的Datum
* @See also:
*/
Datum CStore::CudescTupGetMinMaxDatum(
_in_ CUDesc* pCudesc, _in_ Form_pg_attribute pColAttr, _in_ bool min, _out_ bool* shouldFree)
{
// 确保CUDesc结构表示了相同的值(即min和max相同)
Assert(pCudesc->IsSameValCU());
*shouldFree = false; // 默认情况下不需要释放数据
char* value = NULL;
char* dataPtr = min ? pCudesc->cu_min : pCudesc->cu_max; // 根据需要选择最小或最大值的指针
errno_t rc = EOK;
if (pColAttr->attbyval) {
// 情况1:attlen > 0 && attlen <= sizeof(Datum)
// 数据可以直接按值传递
return (*(Datum*)dataPtr);
}
*shouldFree = true; // 数据需要释放
if (pColAttr->attlen > (int)sizeof(Datum)) {
// 情况2:attlen > sizeof(Datum) && attlen <= MIN_MAX_LEN
Assert(pColAttr->attlen <= MIN_MAX_LEN);
value = (char*)palloc(pColAttr->attlen); // 为数据分配内存
rc = memcpy_s(value, pColAttr->attlen, dataPtr, pColAttr->attlen); // 复制数据
securec_check(rc, "", "");
} else if (pColAttr->attlen == -1) {
// 情况3:attlen == -1,包括空字符串(非空字符串)
Assert((int)dataPtr[0] >= 0 && (int)dataPtr[0] < MIN_MAX_LEN);
value = (char*)palloc(dataPtr[0] + VARHDRSZ_SHORT); // 为字符串数据分配内存
SET_VARSIZE_SHORT(value, dataPtr[0] + VARHDRSZ_SHORT); // 设置字符串头部大小
if (dataPtr[0] > 0) {
rc = memcpy_s(value + VARHDRSZ_SHORT, dataPtr[0], dataPtr + 1, dataPtr[0]); // 复制字符串数据
securec_check(rc, "", "");
}
} else {
// 情况4:attlen == -2,包括非空字符串
Assert((int)dataPtr[0] > 0 && (int)dataPtr[0] < MIN_MAX_LEN);
Assert(dataPtr[(int)dataPtr[0]] == '\0');
value = (char*)palloc(dataPtr[0]); // 为字符串数据分配内存
rc = memcpy_s(value, dataPtr[0], dataPtr + 1, dataPtr[0]); // 复制字符串数据
securec_check(rc, "", "");
}
return PointerGetDatum(value); // 返回表示最小或最大值的Datum
}