时序数据在许多领域中具有广泛的应用,例如金融市场分析、气象预测、交通流量监测、生产过程监控等,时序数据通常是大规模的、高维度的、需要实时计算和分析,针对时序数据的特点与其所带来的挑战,针对时序数据处理所面临的挑战,通用数据库处理大规模数据效率低下,且无法提供丰富的数据保留策略、连续查询、灵活的时间聚合等功能。时序数据库则是为处理时序数据而设计的数据库,目的是实现时序数据的高效采集、存储、计算和应用。
01 时序数据
时序数据(Time Series Data)是按照时间顺序记录的数据集合。它是在一段时间内按照一定时间间隔或时间戳进行采集、记录或观测的数据。
时序数据通常由两个主要部分组成:时间戳和对应的观测值
- 时间戳表示数据点的时间点或时间段,可以是日期、时间、时间戳等形式
- 观测值是在给定时间点上或时间段内测量或记录的数值、指标或事件
时序数据在许多领域中具有广泛的应用,例如金融市场分析、气象预测、交通流量监测、生产过程监控等,例如下图中展示了部分关于地区风速风向相关的时序数据。对时序数据的分析可以帮助发现趋势、季节性、周期性和异常情况,从而支持决策和预测。(图片来自网络,如有侵权请告知)

时序数据的特点:
- 以时间为中心: 时间是一个主轴,数据记录总是有时间戳
- 仅追加:写入的数据几乎是新数据,及总是执行 INSERT 操作,UPDATE 和 DELETE 等数据纠正操作都是异常状态操作,而追加是常态
- 时间相邻:数据通常按时间顺序写入,新数据通常与最近的时间间隔有关,很少更新或回填有关旧时间间隔的缺失数据。
时序数据处理的挑战:
- 规模大:时序数据通常是大规模的,特别是在高频率数据的情况下,处理大量的数据可能需要更多的计算资源和更高效的算法。
- 高维度:时序数据通常是高维度的,每个时间点可能有多个特征或指标,这增加了数据的复杂性和处理的难度。
- 查询分析:时序数据需要实时计算和分析,以便于实时检测异常并告警,延迟可能会导致故障和业务影响。
- 时间性:时序数据的查询一般都会带上查询时间范围,一方面是根据时间范围计算聚合时间窗口,另一方面是为了更高效的检索数据,提高查询效率,避免大量无效数据的扫描。
02 时序数据库
针对时序数据处理所面临的挑战,通用数据库处理大规模数据效率低下,且无法提供丰富的数据保留策略、连续查询、灵活的时间聚合等功能。
时序数据库是为处理时序数据而设计的数据库,目的是实现时序数据的高效采集、存储、计算和应用。时序数据库的基本设计目标是高效插入、存储和查询。(图片来自网络,如有侵权请告知)

更加具体的,时序数据库通常需要具备如下特点:
- 高吞吐和低延迟:时序数据库针对高频率的数据写入和查询场景进行了优化,可以提供高吞吐量和低延迟的数据处理能力。这对于实时监控、物联网和金融交易等应用非常重要。
- 高效存储和检索:时序数据库采用了专门的数据结构和索引技术,可以高效地存储和检索时序数据。它们通常使用压缩算法和数据切分等技术来降低存储空间和提高查询性能。
- 数据分析和预测能力:时序数据库通常集成了数据分析和预测功能,可以支持时序数据的统计分析、模型建立和预测,提供了丰富的时序分析函数和算法,可以帮助用户从时序数据中挖掘有价值的信息。
- 扩展性和可伸缩性:时序数据库具备良好的扩展性和可伸缩性,可以支持大规模的时序数据存储和处理,可以通过水平扩展和分布式架构来应对数据量的增长和负载的增加。
03 TimescaleDB
TimescaleDB 是一个开源的关系型数据库管理系统(RDS),专门设计用于处理时间序列数据。它是基于PostgreSQL 开发的,并通过在 PostgreSQL 上添加一个扩展来实现,通过这种方式将一个普通 PostgreSQL 数据库转化为一个 TimesacleDB。 所以,实际应用中如下图,一个 PostgreSQL 服务器上 TimescaleDB 和 PostgreSQL 数据库可以共存。

由于 TimescaleDB 的实现方式,它兼容了 PostgreSQL 的诸多特性:
- SQL 语法:TimescaleDB 支持标准的 SQL 语法,包括查询语句、数据操作语句和DDL语句等,这使得使用TimescaleDB 与使用传统的关系型数据库非常相似。
- 数据类型:TimescaleDB 支持和扩展了 PostgreSQL 的数据类型,包括数值类型、字符串类型、日期时间类型、数组类型等。此外,TimescaleDB 还提供了专门用于处理时间序列数据的数据类型,如时间戳、时间段等。
- 索引:TimescaleDB 支持 PostgreSQL 的各种索引类型,包括 B 树索引、哈希索引、全文索引等。此外,TimescaleDB 还引入了时间序列索引,用于加速时间范围查询和时间序列插入操作。
- 事务管理:TimescaleDB 继承了 PostgreSQL 的强大的事务管理功能,它支持 ACID(原子性、一致性、隔离性、持久性)特性,允许用户进行原子性和一致性的数据操作,并提供了多种隔离级别。
- 视图和触发器:TimescaleDB 支持创建视图和触发器,这使得用户可以根据需要定义和操作虚拟表和自动化操作。
- 扩展性:TimescaleDB 允许用户根据需要安装和使用 PostgreSQL 的扩展,这意味着用户可以利用PostgreSQL 生态系统中的各种扩展和插件,以增强 TimescaleDB 的功能和性能。
3.1 Hypertable 与 Chunk
TimescaleDB 实现中有两个核心概念 hypertable(超表)和 chunk(数据块),hypertable 可以是一个逻辑概念,chunk 则是数据存储的实际单元,一个超表可以包含多个块。
如下图所示,hypertable 是基于普通的 PostgreSQL 表创建,这让用户可以使用标准 SQL 语法对超表进行插入和查询等操作,与此同时,在普通表的基础上超表添加了自动分区、压缩和连续聚合的功能,以更高效地存储和查询时间序列数据;而 chunk 则是 hypertable 按照时间范围分割成的多个连续的数据块来实际存储时序数据。

hypertable 只是一个逻辑概念,当一个 hypertable 被创建或使用时,它会自动按时间进行分区,也可以添加空间分区。hypertable 每有一个这样的分区就对应一个 chunk 数据块,按时间分区 hypertable 的每个 chunk 都被指定了一个时间范围,块中只包含该范围中的数据;如果 hypertable 也按空间分区,则每个块也被分配空间值的子集。
(1)时间分区
按时间分区的 hypertable 的每个 chunk 仅保存特定时间范围的数据,当向 hypertable 的一个还没有对应 chunk 的时间范围插入数据时,Timescale 会自动创建一个新 chunk 来存储它。
创建 hypertable 时如果没有指定分区时间间隔,该值默认是 7 天,可以通过 chunk_time_interval 参数指定时间间隔。如下图所示,设置分区时间间隔为 1 天,即 chunk_time_interval = “1 day”,那么 普通表中存储的时序数据在 hypertable 中会被转换成 3 个按日期划分的 chunk 中,这三个 chunk 作为 hypertable 的子表存储在数据库节点上。

(2)空间分区
空间分区则是将时间序列数据按照其他维度进行分割,例如设备ID、地理位置等,每个分区代表一个特定的维度值,这种分区方式用于将数据分割成具有相似特征的子集。
空间分区在创建超表时使用 partitioning_column 指定分区列,完成创建之后插入数据时分区也是自动创建和管理的,无需手动操作。
通常不建议使用空间分区,因为不进行空间分区可以使用单表查询提高 I/O 性能。
当然,如果有多个物理磁盘,每个磁盘对应一个单独的表空间,空间分区就非常有用,这样在每个磁盘都可以存储一些空间分区。如果不使用此设置按空间进行分区,则会增加查询规划的复杂性,而不会提高I/O性能。
3.2 后台作业管理
TimescaleDB 通过后台工作进程执行一系列数据管理策略来提供数据压缩、连续聚合和数据保留等高级功能。
其中数据压缩策略、连续聚合刷新策略和数据保留策略关系如下图:

这些策略在后台执行时是相互影响的,例如,在使用连续聚合时,有些情况下需要保留历史数据的统计数据,但不需要保留原始数据,这时候就可以通过将数据保留与连续聚合相结合来减少旧数据的采样。要在删除原始数据的同时保留聚合,需要注意连续聚合刷新策略和数据保留策略时间的指定,要保证数据保留策略删除的旧数据不包含在连续聚合刷新策略指定的时间范围内。
因为在刷新连续聚合时,TimescaleDB 会根据刷新窗口内的原始数据更新连续聚合,如果原始数据已被删除,连续聚合数据也会被删除。如果要防止这种情况,需要确保连续聚合的刷新窗口不与任何已删除的数据重叠。
3.2.1 数据压缩策略
时序数据相较于事务数据规模更大,有效的数据压缩不但可以降低数据存储成本,还可以在数据传输过程中节约网带宽资源,降低数据同步时间。TimescaleDB 提供自动的数据压缩策略,支持多种压缩算法,包括 Delta-Delta,Simple8b 和 Gorilla 等压缩算法。
在 TimescaleDB 中,每个数据块(chunk)都有一个压缩状态,用于表示该数据块是否已经被压缩,其压缩状态有以下几种:
- Active(Uncompressed):数据块的初始状态,表示数据块尚未被压缩。数据块处于活动状态时,TimescaleDB 尚未对其进行压缩操作。
- Compression candidate(Uncompressed):数据块的中间状态,表示数据块已经被标记为压缩候选。当压缩策略生效时,TimescaleDB 将评估数据块是否满足压缩条件,并将其标记为压缩候选。
- Compressed:数据块的最终状态,表示数据块已经被成功压缩。当 TimescaleDB 检测到数据块符合压缩策略,并且执行压缩操作后,数据块的状态将更改为已压缩。

如果后台作业中包含数据压缩策略,则当压缩策略生效时,TimescaleDB 将检测到的符合压缩策略的 chunk 进行压缩并修改状态为已压缩。
其压缩过程如下图,在 hypertable 中待压缩数据块的列上根据数据类型使用对应压缩算法对数据进行压缩

压缩完成之后,hypertable 中的多条数据根据 segmentby 分段列被聚合到单行记录中,分段列中的内容是单个条目(single entry),其他列内容是一个类似数组地数据结构,用于保存多行压缩地数据

3.2.2 连续聚合刷新策略
连续聚合(Continuous aggregates)是增强地 PG 物化视图,也是一种超表,它在添加新数据或修改旧数据时在后台自动刷新。连续聚合不需要在每次刷新时都从头开始创建,所以其维护成本要比 PG 物化视图低得多。
连续聚合可以设定不同的刷新策略(refresh policy),在后台自动刷新连续聚合,如下图刷新策略使用start_offset 和 end_offset 两个参数设置时间范围,当刷新被触发时,刷新过程中对范围内的数据重新执行聚合计算等操作,生成新的聚合结果。

连续聚合的另一个特性是,即使底层超表中的原始数据被删除,可以保留已经生成的连续聚合。基于这种特性可以在数据达到一定年龄时降低数据的粒度,从而释放空间,而且仍然可以支持长期的数据分析。
3.2.3 数据保留策略
TimescaleDB 中就是通过设定数据保留策略来删除不需要的旧数据以节省磁盘空间
而在 TimescaleDB 中删除数据是以 chunk 为单位而不是按行删除的,按 chunk 删除数据可以避免对每一行进行单独的删除操作,比按行删除数据更高效。
TimescaleDB 可以根据数据保留策略自动删除旧数据:使用 add_retention_policy 函数为指定 hypertable 或连续聚合配置一个数据保留期限,即保留多长时间的数据。一旦数据的时间值超过这个数据保留期限,TimescaleDB 将自动删除超过保留期限的旧数据。
3.3 分布式超表 Distributed Hypertable
TimescaleDB 的分布式超表(Distributed Hypertable)用于实现在处理大规模时序数据时的扩展性,它允许用户在多个节点上分布数据,跨越多个物理 TimescaleDB 实例运行 PB 级的工作负载。
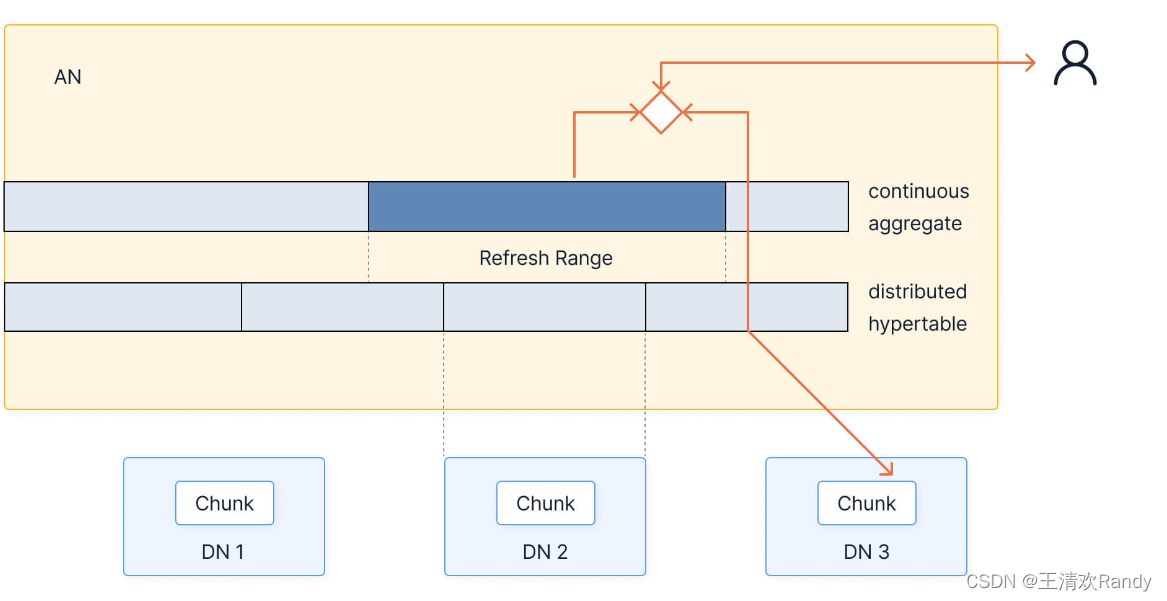
如下图所示,多节点的 TimescaleDB 架构由访问节点(Access Node,AN)和一组数据节点(Data Node,DN)组成,其中 AN 存储分布式超表的元数据并跨集群执行查询规划,DN 则存储分布式超表的单个数据块 chunk,并在本地针对这些 chunk 执行查询。

分布式超表在逻辑上是一个单表,但在物理上分布在多个节点上,每个节点都有自己的数据存储和计算资源。这和 hypertable 的理念一样,分布式超表仅作为一个逻辑概念,数据根据时间或空间被自动划分为多个数据块并在 DN 上自动创建,但在整体上为用户提供的是跨越所有时间的单个连续表
下图是一个在分布式超表上执行查询的过程,首先通过 AN 计算获取数据分区,并将查询发送到指定 DN,多个 DN 并行地执行查询,并在完成查询执行之后返回数据给 AN,最后,AN 将所有 DN 返回的结果聚合返回给用户

同样也可以在分布式超表上查询连续聚合,但是需要保证连续聚合在 AN 节点上,连续聚合刷新过程获取数据与上述查询过程相似。但如果查询地连续聚合涉及还未被刷新的新数据,如下图所示,则在查询时将 AN 上的预聚合数据与来自 DN 中尚未物化的数据进行组合,这种方式中大多数结果已经在 AN 上预先计算,并且仅在查询时从指定 DN 获取尚未物化的最新数据,比直接查询原始数据要有效得多。
如果文章对你有帮助,欢迎一键三连 👍 ⭐️ 💬 。如果还能够点击关注,那真的是对我最大的鼓励 🔥 🔥 🔥 。
参考资料
Timescale Documentation | About hypertables
Timescale Documentation | About compression
Timescale Documentation | About continuous aggregates
Timescale Documentation | About data retention
什么是时序数据库?我们为什么需要时序数据库?|时序数据库 - TDengine - 涛思数据 (taosdata.com)
时序数据到底是什么,为什么我们需要时序数据库?_数据库_InfoQ写作社区
YMatrix - 涅槃:时序数据库的终局与重生
大象时序TimescaleDB在专网领域的应用 - 知乎 (zhihu.com)
Hypertable 和 chunk 超表和块_hyper chunk_殇莫忆的博客-CSDN博客
TimescaleDB的结构初识_timescaledb架构_殇莫忆的博客-CSDN博客