目录
一、日志收集
1、日志简介
2、日志的级别
3、日志代码实现分析
4、日志使用
二、全量字段校验
1、简介和安装
2、JSON Schema⼊⻔
2.1 入门案例
2.2 校验方式
3、JSON Schema语法
3.1 type关键字
3.2 properties关键字
3.3 required关键字
3.4 const关键字
3.5 pattern关键字
3.6 综合案例应用
三、IHRM实战
1、使用全量字段校验
2、日志的使用
3、构造员工id
一、日志收集
1、日志简介
- 什么是日志
- 日志也叫 log,通常对应的 xxx.log 的日志文件。文件的作用是记录系统运行过程中,产生的信息。
- 搜集日志的作用
- 查看系统运行是否正常。
- 分析、定位 bug
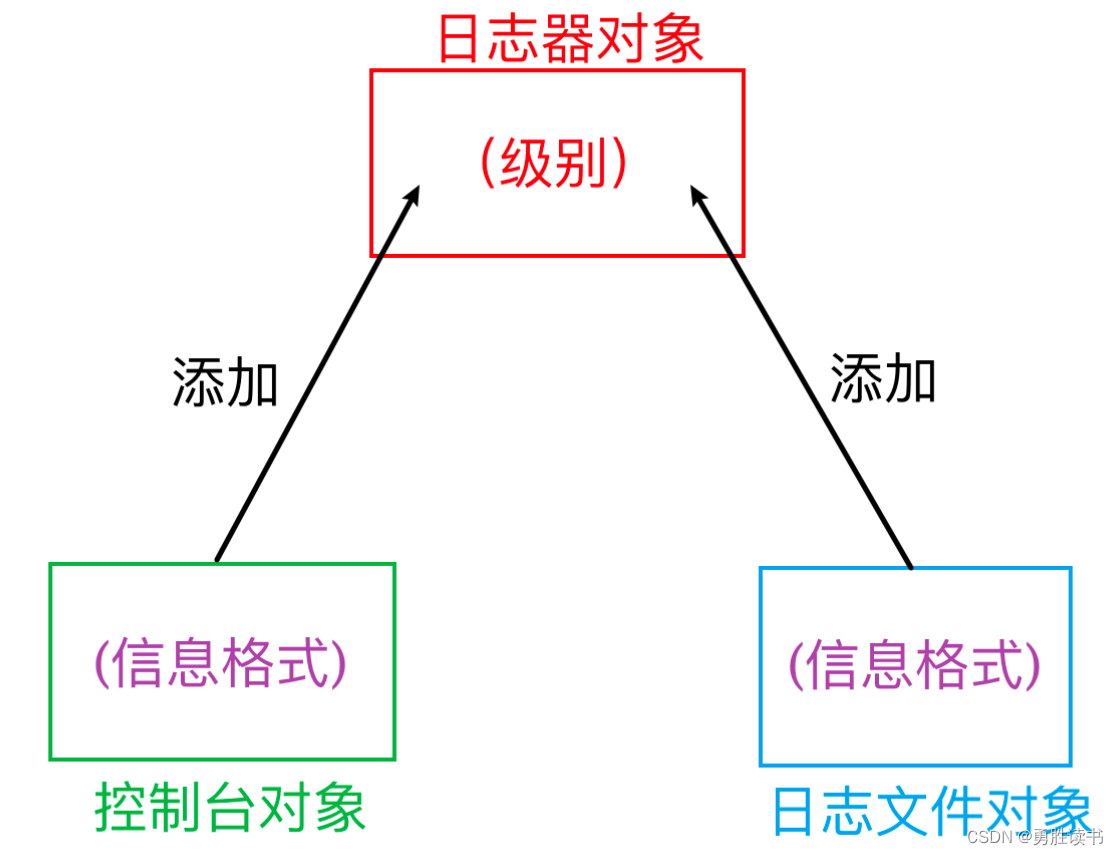
2、日志的级别
- logging.DEBUG:调试级别【高】
- logging.INFO:信息级别【次高】
- logging.WARNING:警告级别【中】
- logging.ERROR:错误级别【低】
- logging.CRITICAL:严重错误级别【极低】
特性:
- 日志级别设定后,只有比该级别低的日志会写入日志。
- 如:设定日志级别为 info。 debug 级别的日志信息,不会写入。infowarning、error、critical 会写入

3、日志代码实现分析
日志代码,无需手写实现。会修改、调用即可!
代码分析
""" 步骤: # 0. 导包 # 1. 创建日志器对象 # 2. 设置日志打印级别 # logging.DEBUG 调试级别 # logging.INFO 信息级别 # logging.WARNING 警告级别 # logging.ERROR 错误级别 # logging.CRITICAL 严重错误级别 # 3. 创建处理器对象 # 创建 输出到控制台 处理器对象 # 创建 输出到日志文件 处理器对象 # 4. 创建日志信息格式 # 5. 将日志信息格式设置给处理器 # 设置给 控制台处理器 # 设置给 日志文件处理器 # 6. 给日志器添加处理器 # 给日志对象 添加 控制台处理器 # 给日志对象 添加 日志文件处理器 # 7. 打印日志 """ import logging.handlers import logging import time # 1. 创建日志器对象 logger = logging.getLogger() # 2. 设置日志打印级别 logger.setLevel(logging.DEBUG) # logging.DEBUG 调试级别 # logging.INFO 信息级别 # logging.WARNING 警告级别 # logging.ERROR 错误级别 # logging.CRITICAL 严重错误级别 # 3.1 创建 输出到控制台 处理器对象 st = logging.StreamHandler() # 3.2 创建 输出到日志文件 处理器对象 fh = logging.handlers.TimedRotatingFileHandler('a.log', when='midnight', interval=1, backupCount=3, encoding='utf-8') # when 字符串,指定日志切分间隔时间的单位。midnight:凌晨:12点。 # interval 是间隔时间单位的个数,指等待多少个 when 后继续进行日志记录 # backupCount 是保留日志文件的个数 # 4. 创建日志信息格式 fmt = "%(asctime)s %(levelname)s [%(filename)s(%(funcName)s:%(lineno)d)] - %(message)s" formatter = logging.Formatter(fmt) # 5.1 日志信息格式 设置给 控制台处理器 st.setFormatter(formatter) # 5.2 日志信息格式 设置给 日志文件处理器 fh.setFormatter(formatter) # 6.1 给日志器对象 添加 控制台处理器 logger.addHandler(st) # 6.2 给日志器对象 添加 日志文件处理器 logger.addHandler(fh) # 7. 打印日志 while True: # logging.debug('我是一个调试级别的日志') # logging.info('我是一个信息级别的日志') logging.warning('test log sh-26') # logging.error('我是一个错误级别的日志') # logging.critical('我是一个严重错误级别的日志') time.sleep(1)
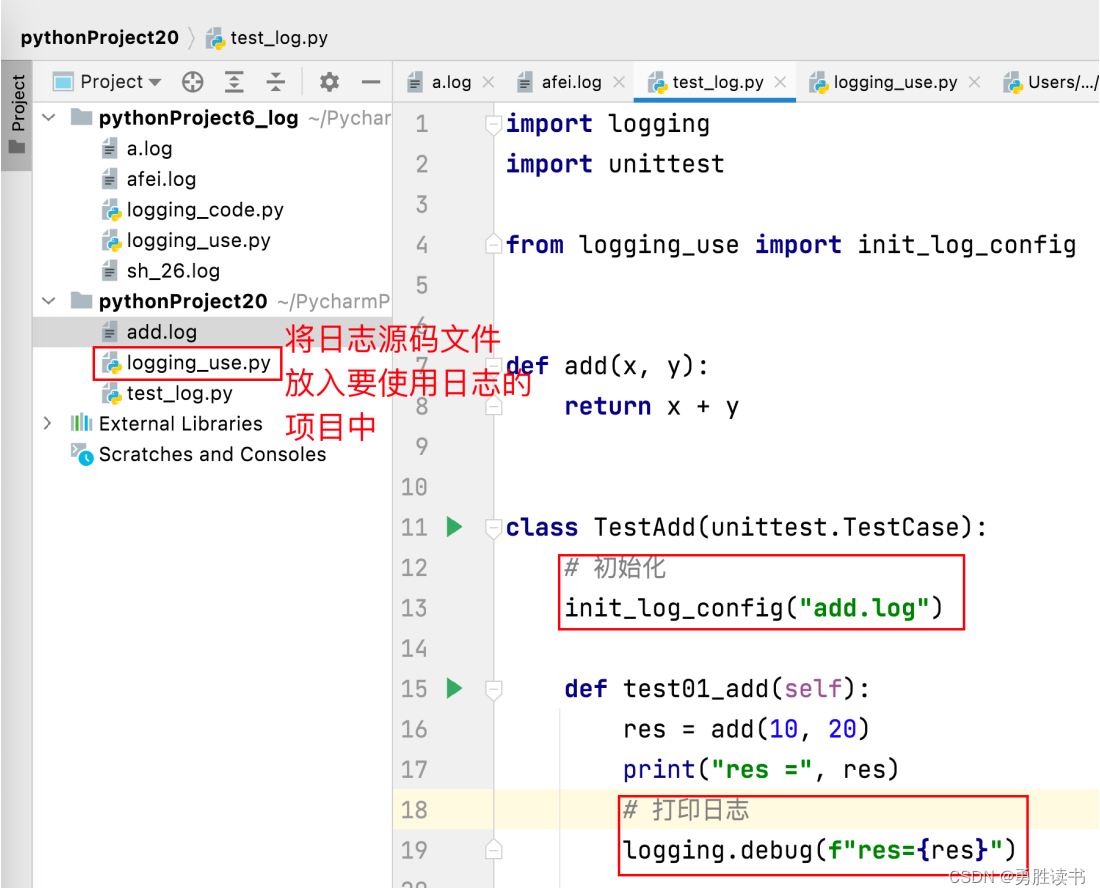
4、日志使用
可修改的位置
使用步骤:
1. 调用 init_log_config() 函数,初始化日志信息。
2. 指定 日志级别,打印 日志信息。源码文件下载:https://download.csdn.net/download/u010217055/87313711

二、全量字段校验
1、简介和安装
- 概念:校验接⼝返回响应结果的全部字段(更进一步的断言)
- 校验内容:
- 字段值
- 字段名 或 字段类型
- 校验流程:
- 定义json语法校验格式
- ⽐对接口实际响应数据是否符合json校验格式
- 安装jsonschema:
pip install jsonschema -i https://pypi.douban.com/simple/
- 查验:
- pip 查验:pip list 或 pip show jsonschema
- pycharm 中 查验:file --- settings --- 项目名中查看 python解释器列表。
2、JSON Schema⼊⻔
2.1 入门案例
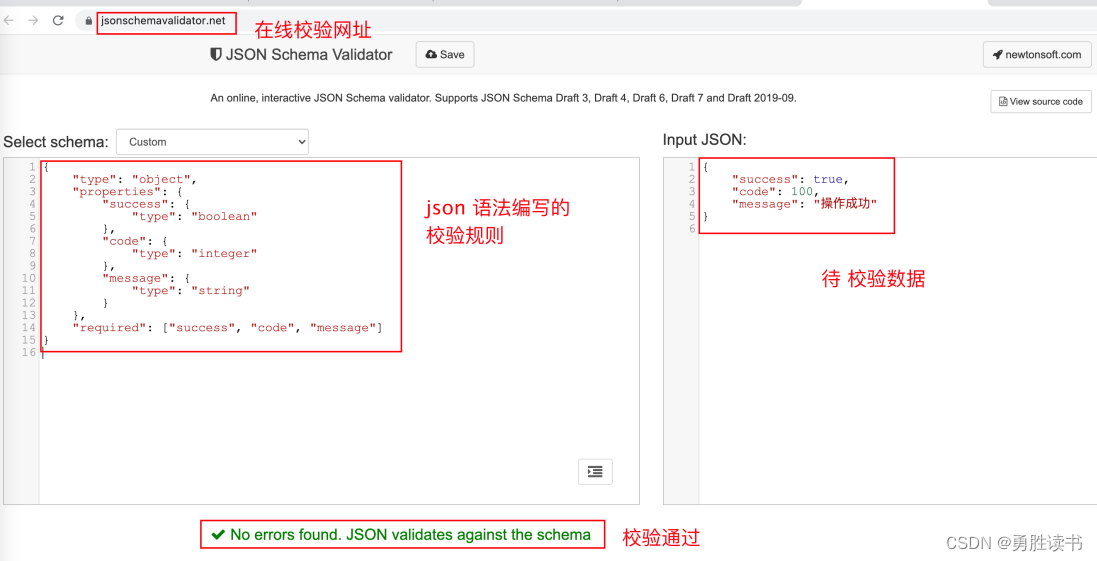
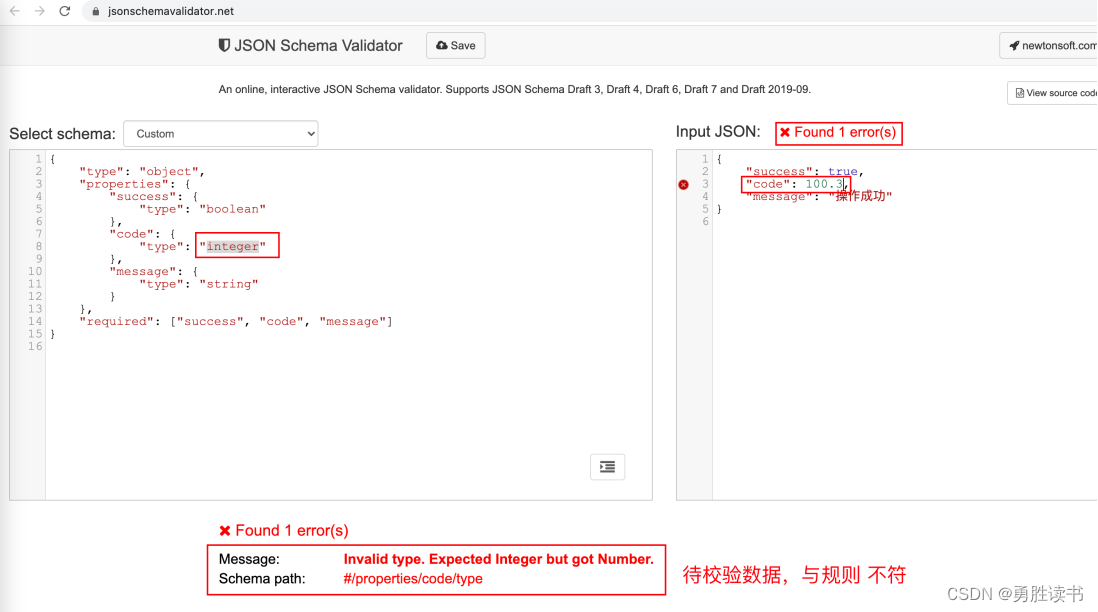
{ "type": "object", "properties": { "success": {"type": "boolean"}, "code": {"type": "integer"}, "message": {"type": "string"} }, "required": ["success", "code", "message"] }

2.2 校验方式
在线工具校验
http://json-schema-validator.herokuapp.com
https://www.jsonschemavalidator.net 【推荐】
python代码校验
- 实现步骤:
- 导包 import jsonschema
- 定义 jsonschema格式 数据校验规则
- 调⽤ jsonschema.validate(instance="json数据", schema="jsonshema规则")
- 查验校验结果:
- 校验通过:返回 None
- 校验失败
- schema 规则错误,返回 SchemaError
- json 数据错误,返回 ValidationError
- 案例:
# 1. 导包 import jsonschema # 2. 创建 校验规则 schema = { "type": "object", "properties": { "success": { "type": "boolean" }, "code": { "type": "int" }, "message": { "type": "string" } }, "required": ["success", "code", "message"] } # 准备待校验数据 data = { "success": True, "code": 10000, "message": "操作成功" } # 3. 调用 validate 方法,实现校验 result = jsonschema.validate(instance=data, schema=schema) print("result =", result) # None: 代表校验通过 # ValidationError:数据 与 校验规则不符 # SchemaError: 校验规则 语法有误
3、JSON Schema语法

3.1 type关键字
作用:约束数据类型
integer —— 整数 string —— 字符串 object —— 对象 array —— 数组 --> python:list 列表 number —— 整数/⼩数 null —— 空值 --> python:None boolean —— 布尔值 语法: { "type": "数据类型" }示例
import jsonschema # 准备校验规则 schema = { "type": "object" # 注意 type 和 后面的 类型,都要放到 ”“ 中! } # 准备数据 data = {"a": 1, "b": 2} # 调用函数 res = jsonschema.validate(instance=data, schema=schema) print(res)
3.2 properties关键字
说明:是 type关键字的辅助。用于 type 的值为 object 的场景。
作用:指定 对象中 每个字段的校验规则。 可以嵌套使用。语法: { "type": "object", "properties":{ "字段名1":{规则}, "字段名2":{规则}, ...... } }案例1:
{ "success": true, "code": 10000, "message": "操作成功", "money": 6.66, "address": null, "data": { "name": "tom" }, "luckyNumber": [6, 8, 9] }import jsonschema # 准备校验规则 schema = { "type": "object", "properties": { "success": {"type": "boolean"}, "code": {"type:": "integer"}, "message": {"type": "string"}, "money": {"type": "number"}, "address": {"type": "null"}, "data": {"type": "object"}, "luckyNumber": {"type": "array"} } } # 准备测试数据 data = { "success": True, "code": 10000, "message": "操作成功", "money": 6.66, "address": None, "data": { "name": "tom" }, "luckyNumber": [6, 8, 9] } # 调用方法进行校验 res = jsonschema.validate(instance=data, schema=schema) print(res)案例2:要求定义JSON对象中包含的所有字段及数据类型
data = { "success": True, "code": 10000, "message": "操作成功", "money": 6.66, "address": None, "data": { "name": "tom", "age": 18, "height": 1.78 }, "luckyNumber": [6, 8, 9] }import jsonschema # 准备校验规则 schema = { "type": "object", "properties": { "success": {"type": "boolean"}, "code": {"type:": "integer"}, "message": {"type": "string"}, "money": {"type": "number"}, "address": {"type": "null"}, "data": { "type": "object", "properties": { # 对 data 的对象值,进一步进行校验 "name": {"type": "string"}, "age": {"type": "integer"}, "height": {"type": "number"} } }, "luckyNumber": {"type": "array"} } } # 准备测试数据 data = { "success": True, "code": 10000, "message": "操作成功", "money": 6.66, "address": None, "data": { "name": "tom", "age": 18, "height": 1.78 }, "luckyNumber": [6, 8, 9] } # 调用方法进行校验 res = jsonschema.validate(instance=data, schema=schema) print(res)
3.3 required关键字
作用:校验对象中必须存在的字段。字段名必须是字符串,且唯⼀
语法: { "required": ["字段名1", "字段名2", ...] }import jsonschema # 测试数据 data = { "success": True, "code": 10000, "message": "操作成功", "data": None, } # 校验规则 schema = { "type": "object", "required": ["success", "code", "message", "data"] } # 调用方法校验 res = jsonschema.validate(instance=data, schema=schema) print(res)
3.4 const关键字
作用:校验字段值是⼀个固定值。
语法: { "字段名":{"const": 具体值} }import jsonschema # 测试数据 data = { "success": True, "code": 10000, "message": "操作成功", "data": None, } #校验规则 schema = { "type": "object", "properties": { "success": {"const": True}, "code": {"const": 10000}, "message": {"const": "操作成功"}, "data": {"const": None} }, "required": ["success", "code", "message", "data"] } # 调用方法校验 res = jsonschema.validate(instance=data, schema=schema) print(res)
3.5 pattern关键字
作用:指定正则表达式,对字符串进行模糊匹配
基础正则举例: 1 包含字符串:hello 2 以字符串开头 ^: ^hello 如:hello,world 3 以字符串结尾 $: hello$ 如:中国,hello 4 匹配[]内任意1个字符[]: [0-9]匹配任意⼀个数字 [a-z]匹任意一个小写字母 [cjfew9823]匹配任意一个 5 匹配指定次数{}: [0-9]{11}匹配11位数字。 匹配 手机号:^[0-9]{11}$ 语法: { "字段名":{"pattern": "正则表达式"} }import jsonschema # 测试数据 data = { "message": "!jeklff37294操作成功43289hke", "mobile": "15900000002" } # 校验规则 schema = { "type": "object", "properties": { "message": {"pattern": "操作成功"}, "mobile": {"pattern": "^[0-9]{11}$"} } } # 调用方法校验 res = jsonschema.validate(instance=data, schema=schema) print(res)
3.6 综合案例应用
# 测试数据
import jsonschema
data = {
"success": False,
"code": 10000,
"message": "xxx登录成功",
"data": {
"age": 20,
"name": "lily"
}
}
# 校验规则
schema = {
"type": "object",
"properties": {
"success": {"type": "boolean"},
"code": {"type": "integer"},
"message": {"pattern": "登录成功$"},
"data": {
"type": "object",
"properties": {
"name": {"const": "lily"},
"age": {"const": 20}
},
"required": ["name", "age"]
}
},
"required": ["success", "code", "message", "data"]
}
# 调用测试方法
res = jsonschema.validate(instance=data, schema=schema)
print(res)三、IHRM实战
1、使用全量字段校验
import unittest
import jsonschema
from api.ihrm_login_api import IhrmLoginApi
class TestIhrmLogin(unittest.TestCase):
# 登录成功
def test01_login_success(self):
# 组织请求数据
json_data = {"mobile": "13800000002", "password": "123456"}
# 调用自己封装的接口
resp = IhrmLoginApi.login(json_data)
print("登录成功:", resp.json())
# 断言
# assert_util(self, resp, 200, True, 10000, "操作成功")
# 断言 校验响应状态码
self.assertEqual(200, resp.status_code)
# 使用全量字段校验,替换 断言
# 校验规则
schema = {
"type": "object",
"properties": {
"success": {"const": True},
"code": {"const": 10000},
"message": {"pattern": "操作成功"},
"data": {"type": "string"}
},
"required":["success", "code", "message", "data"]
}
# 调用jsonschema校验函数
jsonschema.validate(instance=resp.json(), schema=schema)2、日志的使用
1. 将 包含 init_log_config() 函数的 日志文件,存放到 项目目录 common/ 下。
2. 在 项目入口文件中, 调用 init_log_config() 函数,指定 日志文件名,及 其他参数。
3. 在 所有 需要打印输出的 ,将 logging.级别() 替换 调用 print 输出!
4. 去 生成的日志文件中,查看日志信息。

3、构造员工id
1. 测试 查询员工接口前(setUp),保证 使用的 员工id 已存在!使用 insert SQL语句 插入一个 员工id
2. 使用这个 员工id,进行查询员工接口测试
3. 测试查询员工接口结束(tearDown)时,删除这个 员工idimport logging import unittest from api.ihrm_emp_curd import IhrmEmpCURD from common.db_util import DBUtil from common.get_header import get_header class TestEmpQuery(unittest.TestCase): header = None @classmethod def setUpClass(cls) -> None: cls.header = get_header() def setUp(self) -> None: insert_sql = "insert into bs_user(id, mobile, username) values('11232738248634','13974837801', '随便打打');" DBUtil.uid_db(insert_sql) def tearDown(self) -> None: delete_sql = "delete from bs_user where id = '11232738248634';" DBUtil.uid_db(delete_sql) # 测试 查询员工 def test01_query_emp(self): # 使用 数据库 切实存在的 emp_id 传入 resp = IhrmEmpCURD.query_emp("11232738248634", self.header) print("查询员工:", resp.json())

![[C++]类和对象【中】](https://img-blog.csdnimg.cn/fb7efb77258e4cef80c5f2616d527f4e.png)


![[附源码]Nodejs计算机毕业设计基于响应式交友网站Express(程序+LW)](https://img-blog.csdnimg.cn/41828d29e8d64e56a5611df5aacf9d0f.png)


![[leetcode 739] 每日温度](https://img-blog.csdnimg.cn/2eb8970ba2e646028d3fb8fb92c990ab.png)