开发环境
ANACONDA
官网:Anaconda | The World’s Most Popular Data Science Platform
cmd窗口验证安装成功

CUDA
官网:CUDA Toolkit Archive | NVIDIA Developer
选择匹配pytorch的版本下载安装
命令窗口验证安装成功
PyTorch
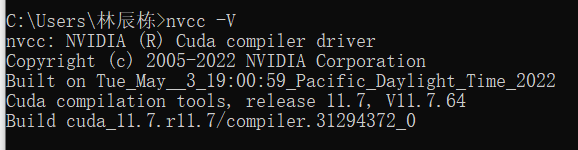
官网:PyTorch
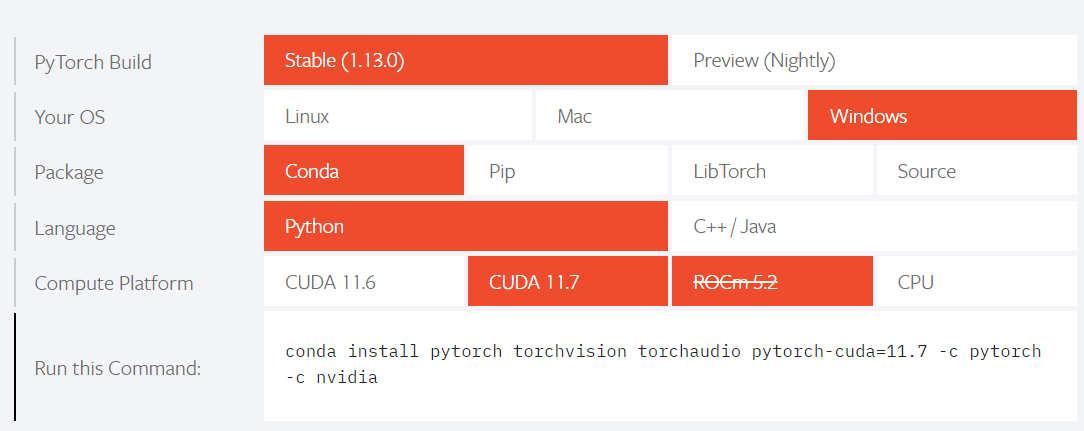
复制命令,管理员权限运行命令窗口完成安装

PyCharm
官网:PyCharm: the Python IDE for Professional Developers by JetBrains
新建项目:
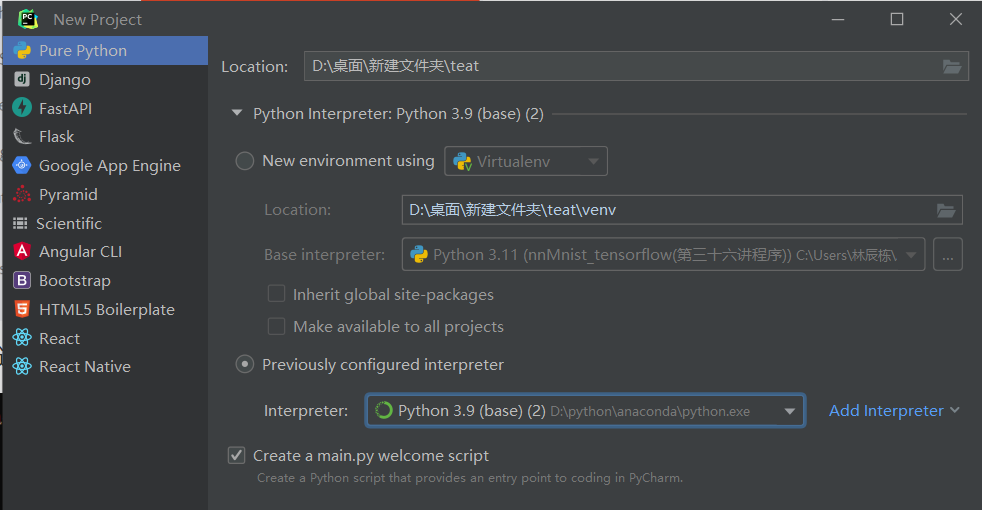
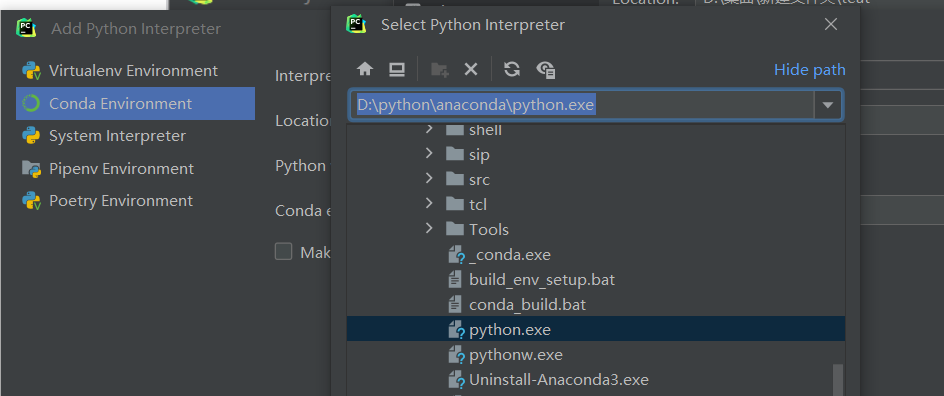
添加编译器
选择Conda环境下,anaconda的安装目录下的python.exe
在新建项目中测试
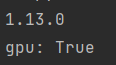
import torch
print(torch.__version__)
print('gpu:', torch.cuda.is_available())
简单回归问题
讨论用梯度下降法解决一个简单线性回归问题 y = WX + b
定义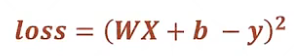
目标:使得所有点的loss之和最小,即均方差最小
梯度下降法: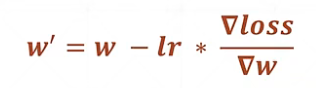
每次循环根据梯度下降法来改变未知变量:W和b的值,直到loss最小时的W和b的值即为解
新参数 = 旧参数 - 学习率*loss对该参数求偏导
其中学习率lr是为了防止梯度下降过快
分类问题
以手写体数字识别为例,可以看作是由简单函数推导到深度学习的过程

假设每个数字图片的像素为28*28,将矩阵铺平变一维X=[v1, v2, …, v784]
以H1 = XW1T + b1 ,…, Hi = Hi-1 WiT + bi ,这里假设构造三层函数关系
最终得到 H3 = [1, d3] ,然后在同 y 去比较计算loss
对于输出的分类采用one-hot的规则:以一个n维向量的变量 1 所在的维数来分类

最后得到的 H3 基本不会是单纯的01的格式,可能为[0.1, 0.8, 0.03…],令其与[0,1,0 …]作比较即可
总结
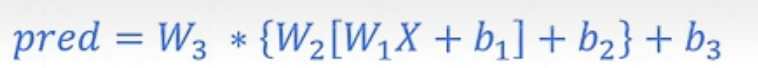
显然一个线性的函数组合无法很好地得到区分手写数字的效果
为了得到一个非线性的结果,对于每一个 H 在传入下一层计算前,进行依次非线性变换,这就是DL中的激活函数
训练的过程就是随机选定 W 和 b 的值,代入运算得到 loss,通过梯度下降的方法改变 W 和 b 的值,最终使得 loss 最小的 W 和 b 就是所需要的结果
基础知识
基本数据类型
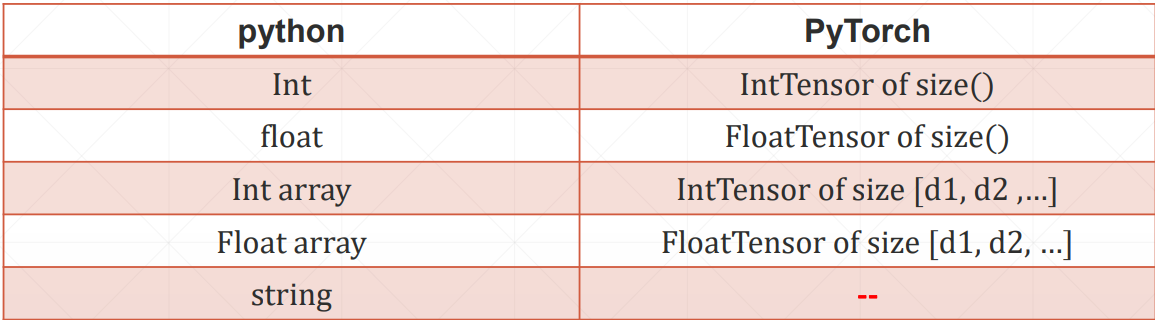
对应python中的基本数据类型,PyTorch中有相应的Tensor(张量)类型,相当于数学中的向量

每一个在CPU中的Tensor加载到GPU中会转换为对应的cuda…Tensor
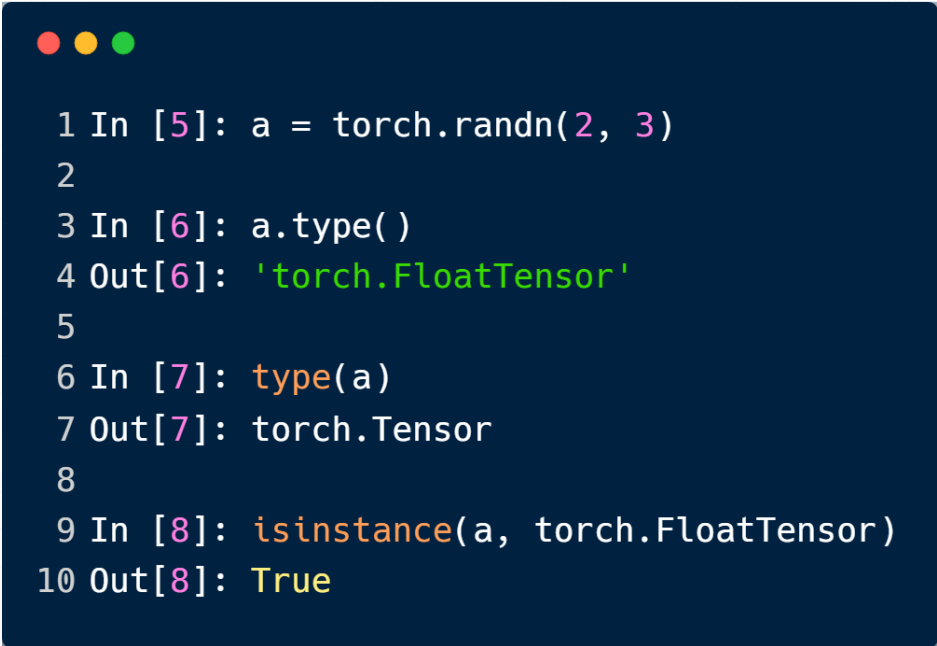
上例中通过torch中的方法创建了一个2*3的矩阵,其类型为FloatTensor
每一个Tensor都有其Dimension(维度)属性,是一个具体的数字
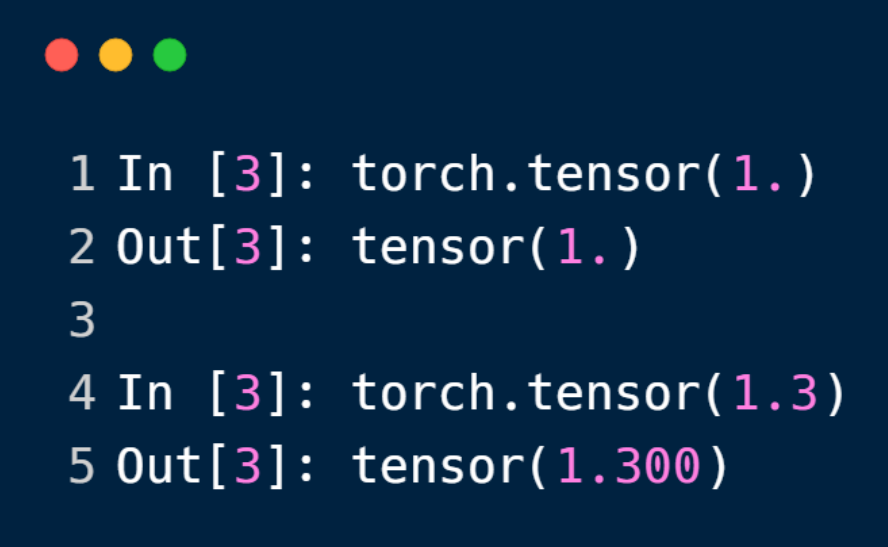
如上,在PyTorch一个纯数字是一个dim为0的特殊tensor
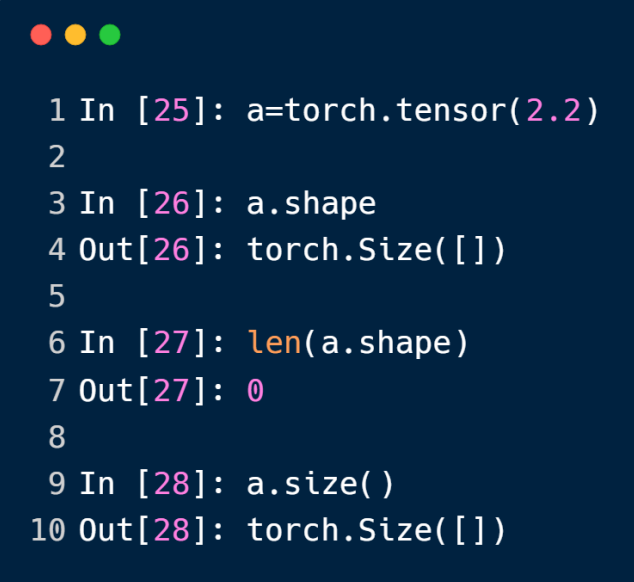
每一个tensor的shape或者size属性是指这个张量(矩阵)的形状
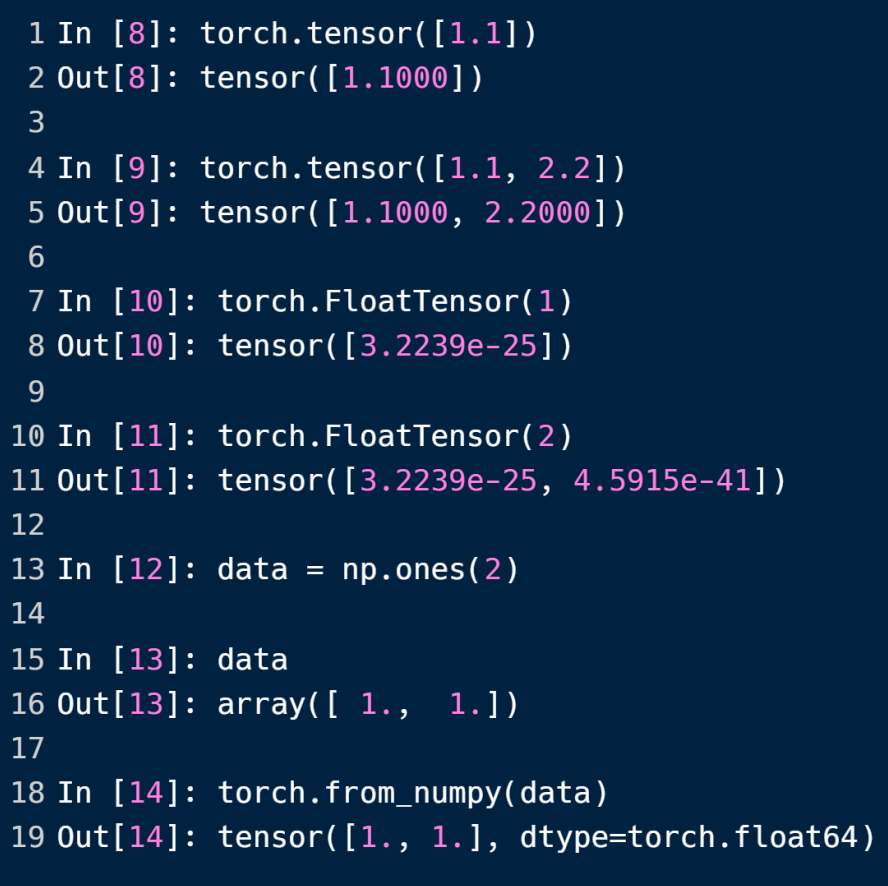
用torch.tensor方法创建dim为1的tensor就必须以[]包含参数,否则创建的是dim为0的
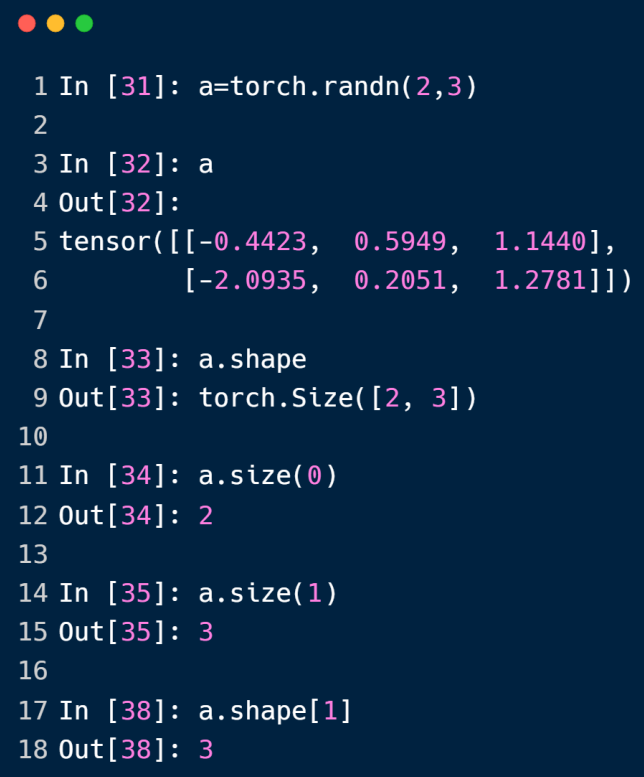
tensor的shape和size
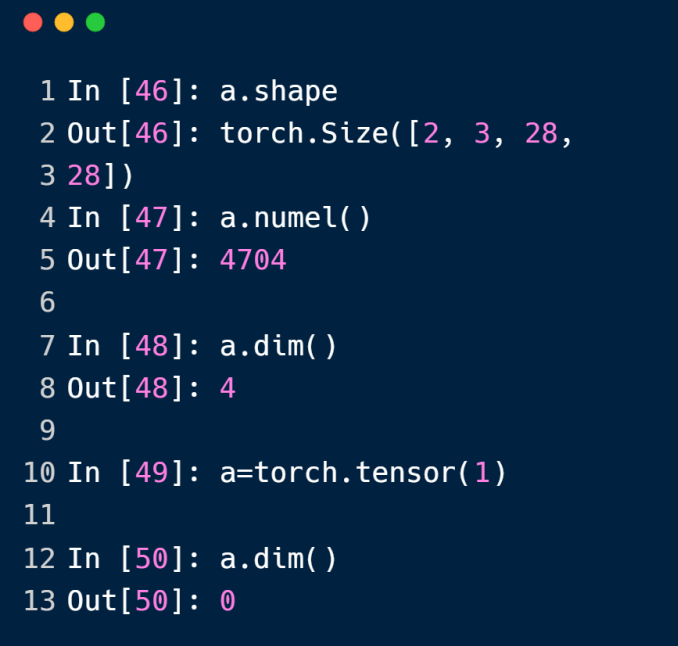
numel方法返回python中的size值
dim方法返回dim值
创建Tensor
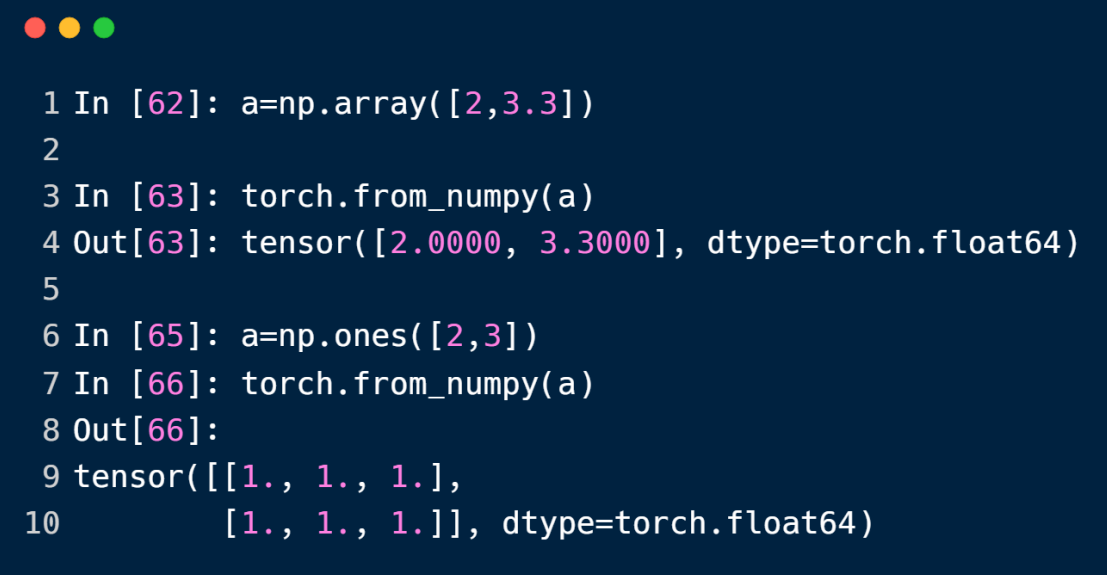
从numpy中导入数据创建tensor,其中array方法的参数为List,ones方法的参数为shape
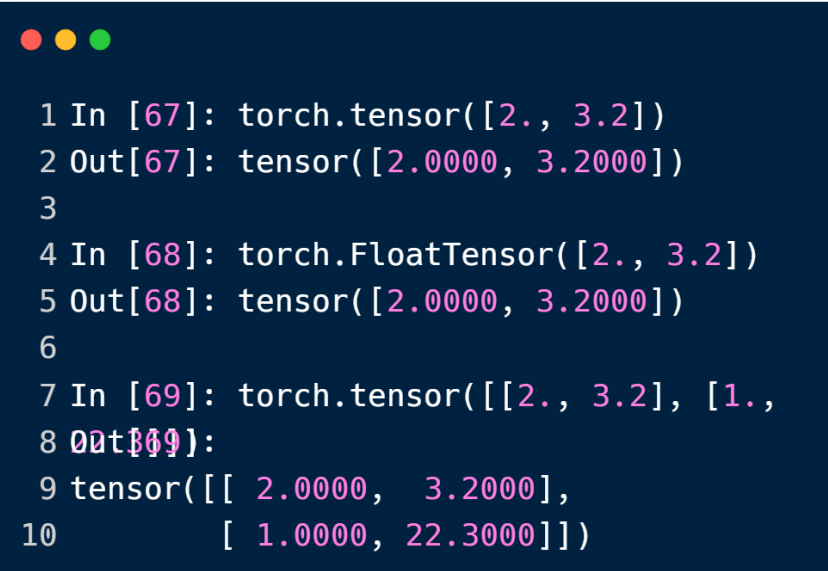
tensor方法以一个list作为具体数据创建一个tensor
Tensor或者XXXTensor方法则以多参数作为shape来创建对应的tensor,也可以只用一个list作为参数但不推荐
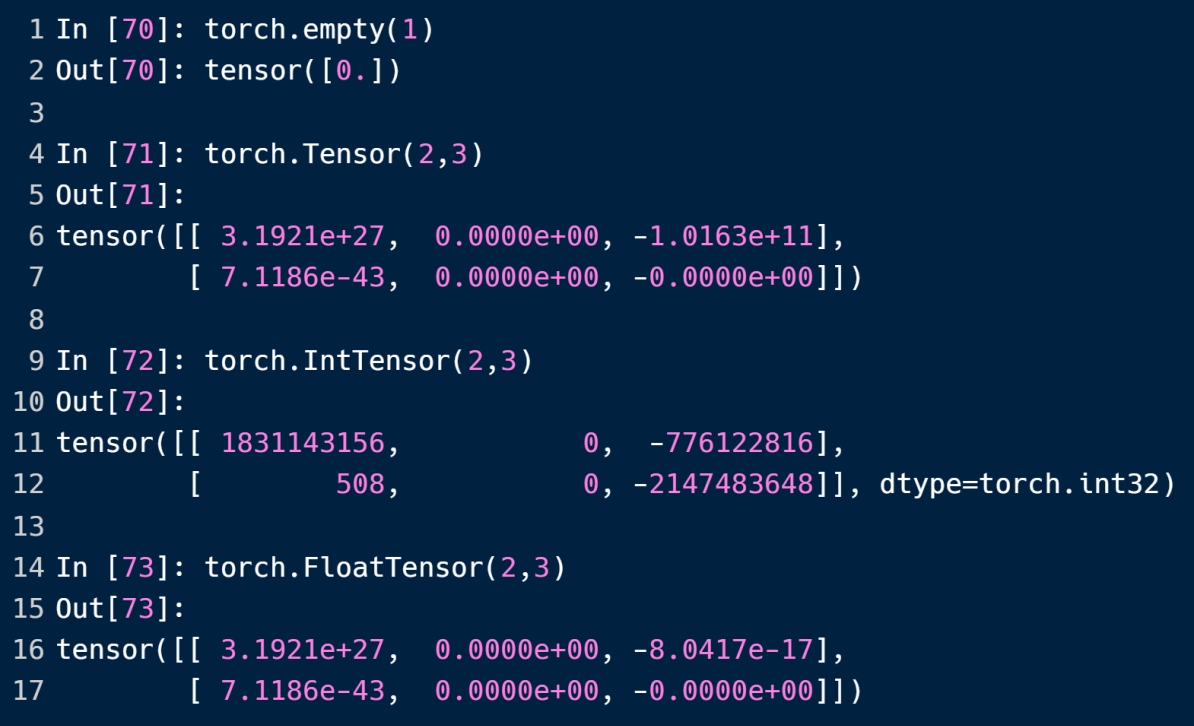
直接用上面的方法创建的tensor是未初始化的,数据分布往往比较极端
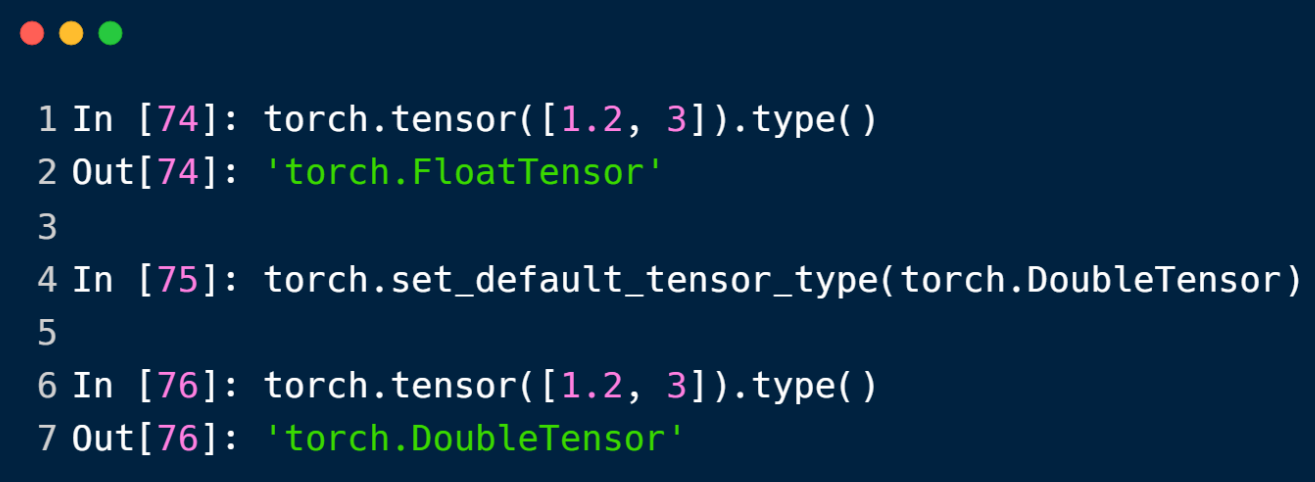
对于使用tensor方法来创建的tensor的默认类型可以按照上面的来修改
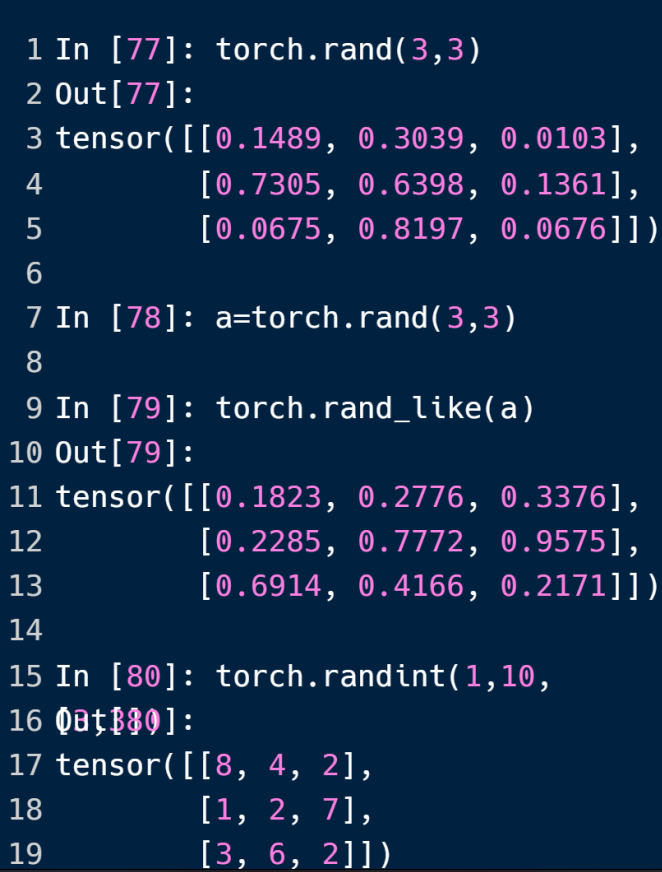
rand方法创建的tensor中的数据在[0,1]中随机取值
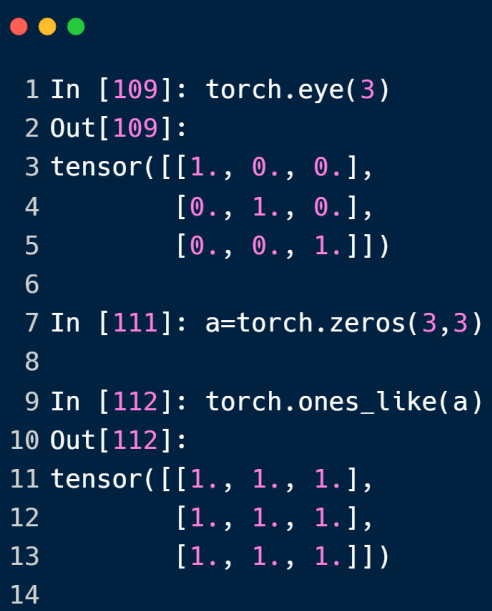
*_like方法可以按照参数的shape来创建tensor
randint方法在[min,max)中随机取整数,以第三个list参数为shape创建tensor
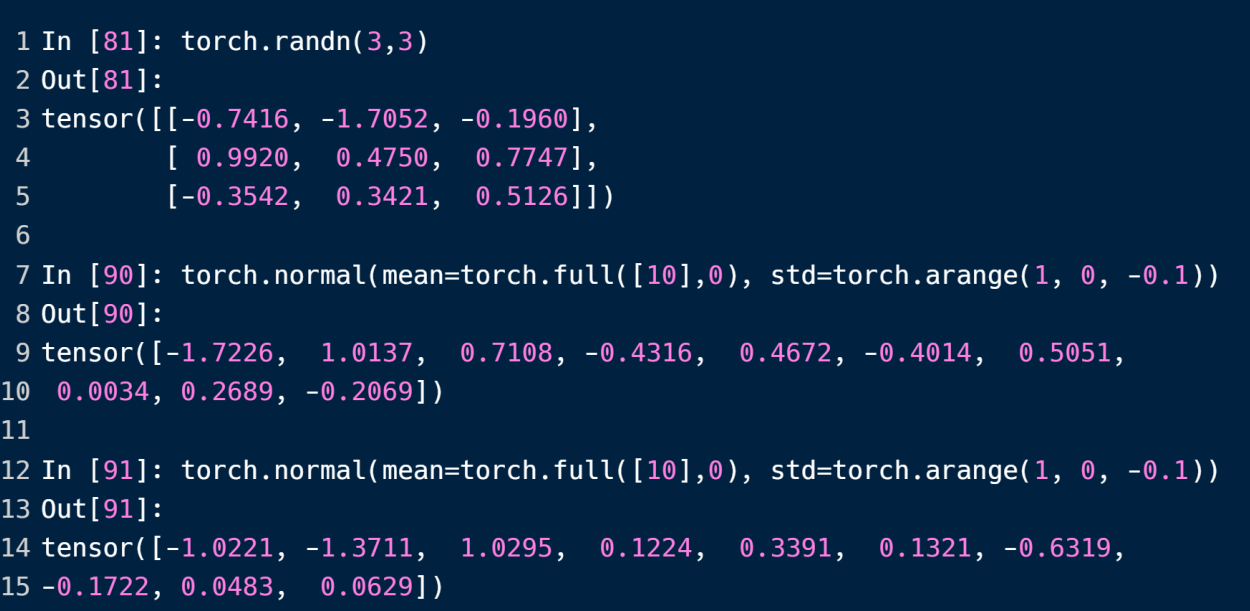
randn以正态分布N(0,1)来取值创建tensor
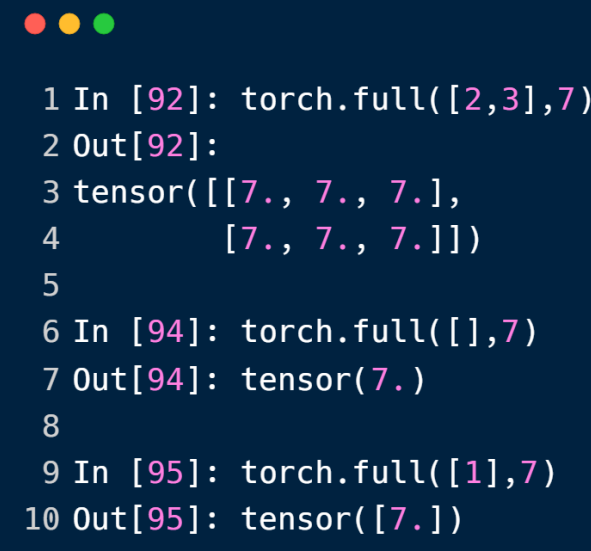
full方法以同一个值来创建tensor
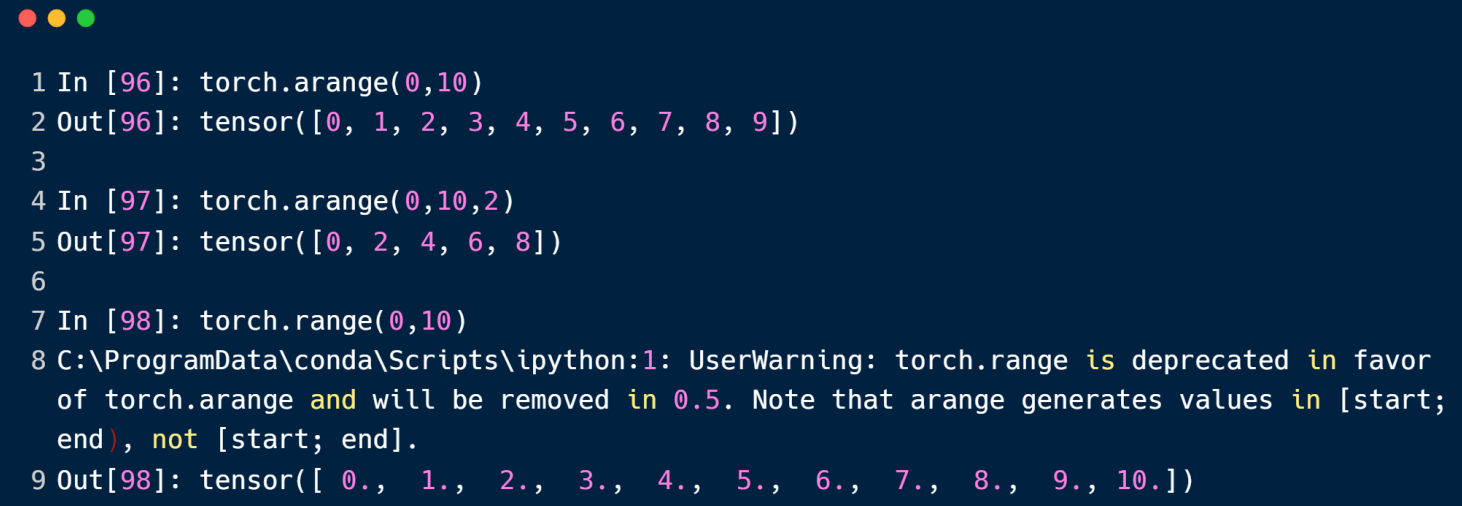
arange方法以等差数列来创建tensor
range不推荐使用
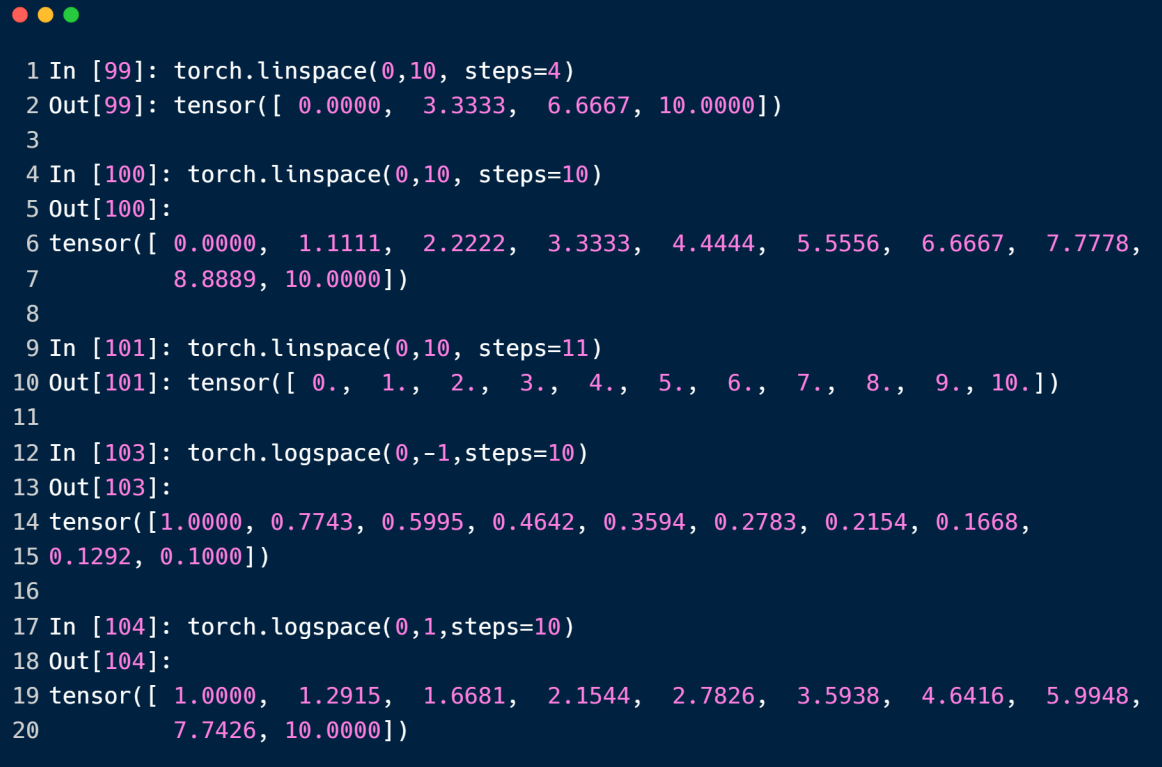
linspace方法等分取值范围来创建tensor
logspace方法以等分的取值作为指数,计算10x 来创建tensor
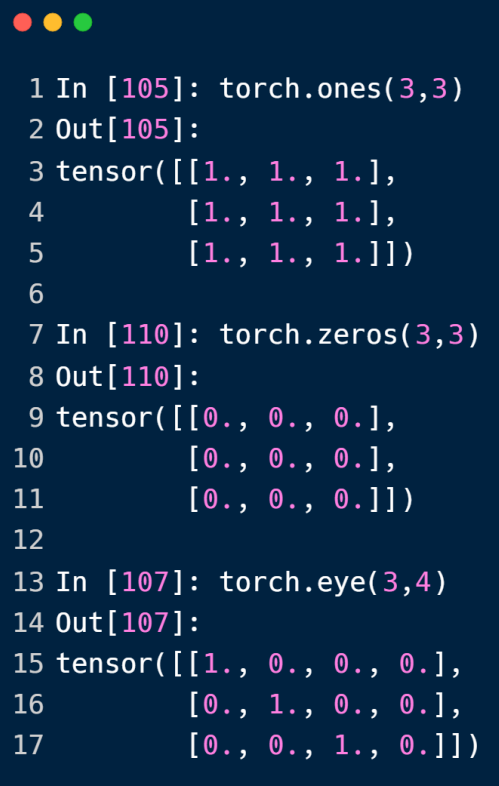
ones 方法创建全 1 的 tensor
zeros 方法创建全 0 的 tensor
eye 方法创建单位矩阵

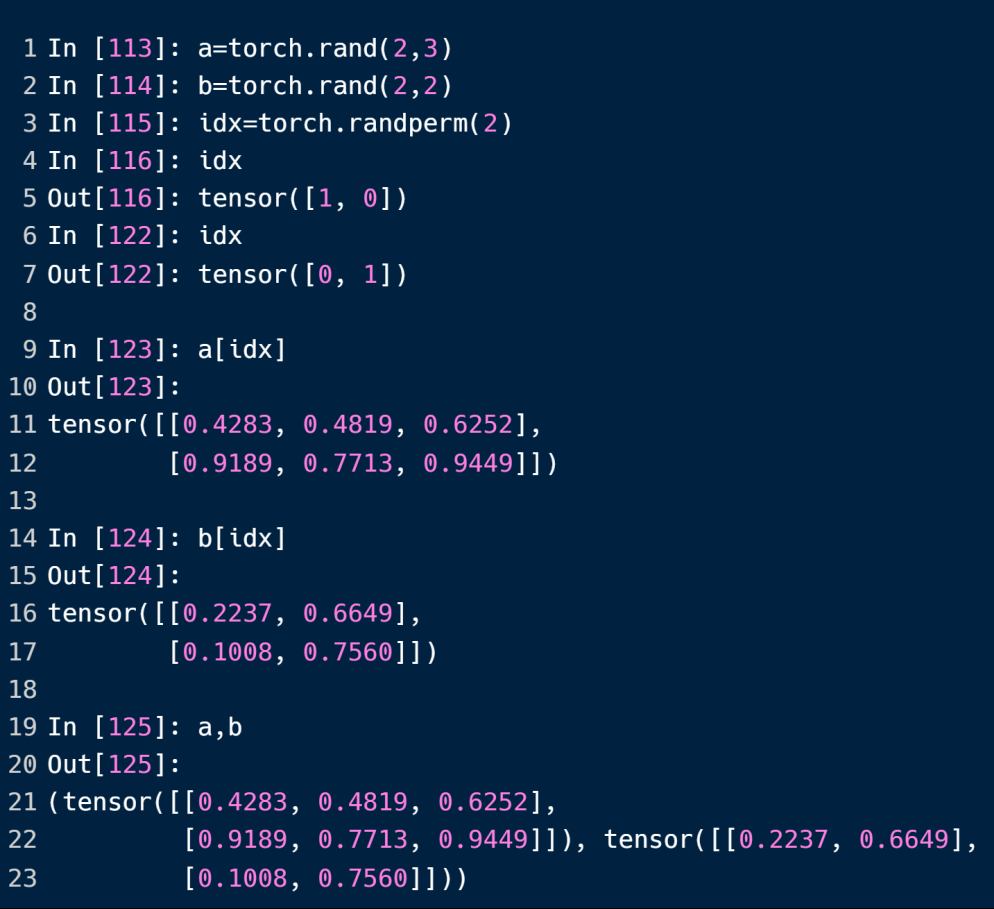
randperm 方法构造一个参数范围内的随机序列组合,简单来讲就是随机打乱[min,max)之间所有的整数
索引与切片
与python数组的索引与切片并没有什么大的不同
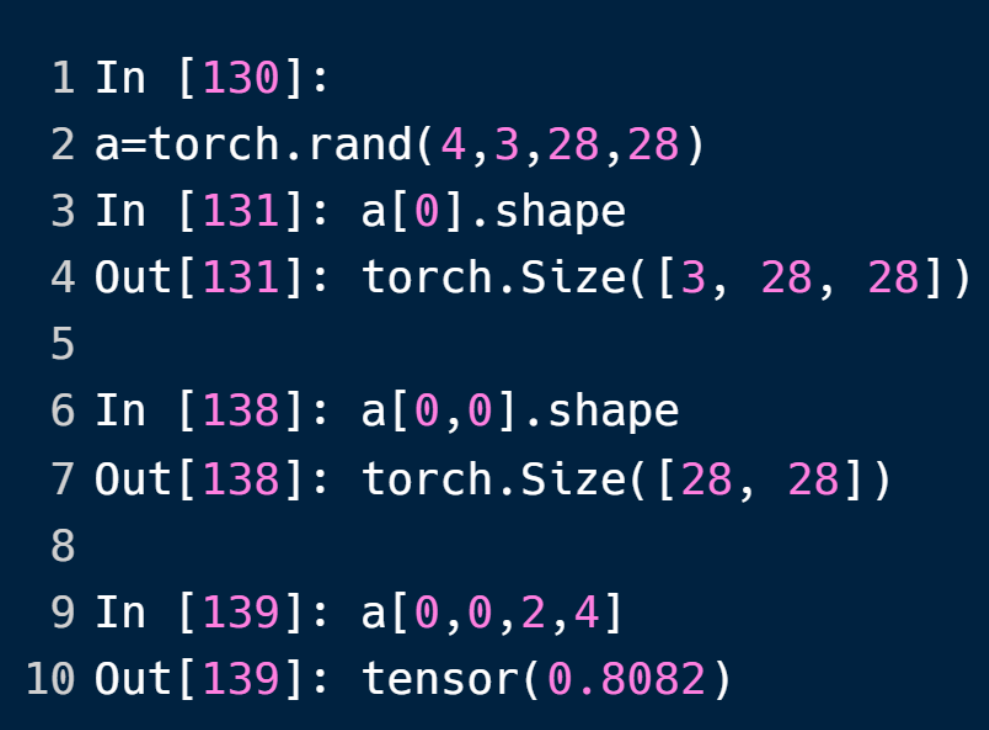
简单的索引
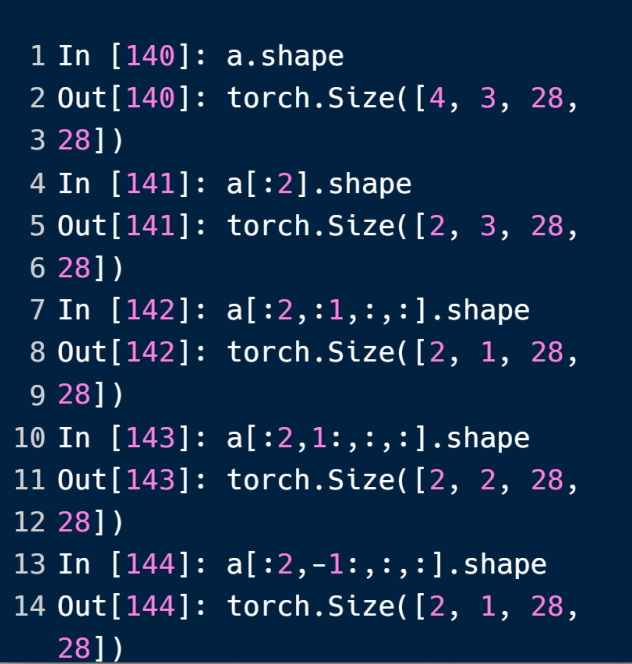
通过冒号(:)来实现切片的功能,左闭右开;没有数字则表示边界;负数索引从-1开始,代表末尾
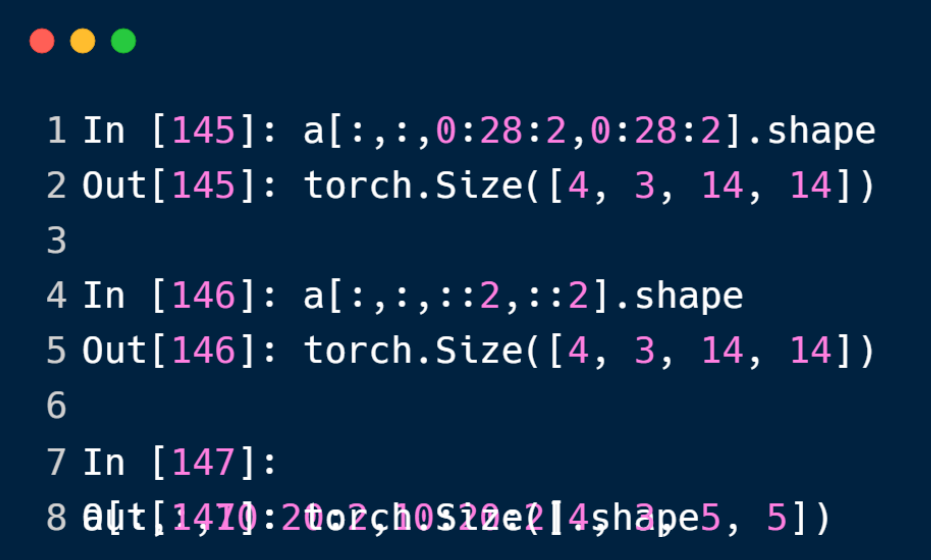
双冒号来表示带有步长的切片操作,第三个参数表示步长
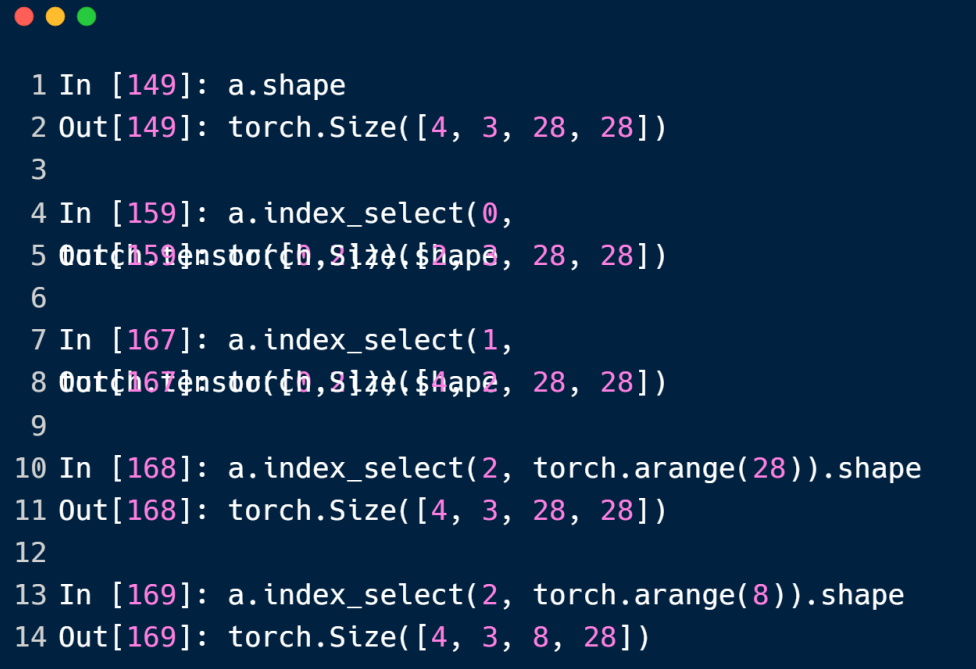
index_select 方法通过索引torch来切片,第一个参数为所切的维度,第二个torch参数为在该维上的索引号
其中第一个被遮掩的部分为 torch.tensor([0,2])).shape
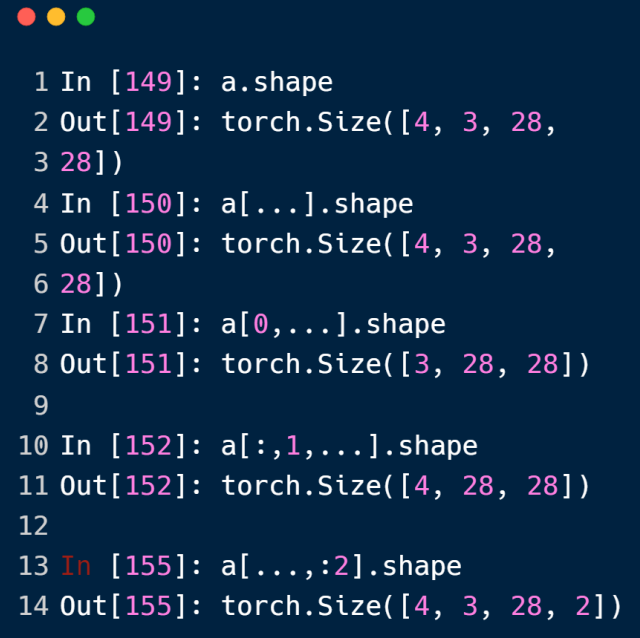
… 三个点来表示省略
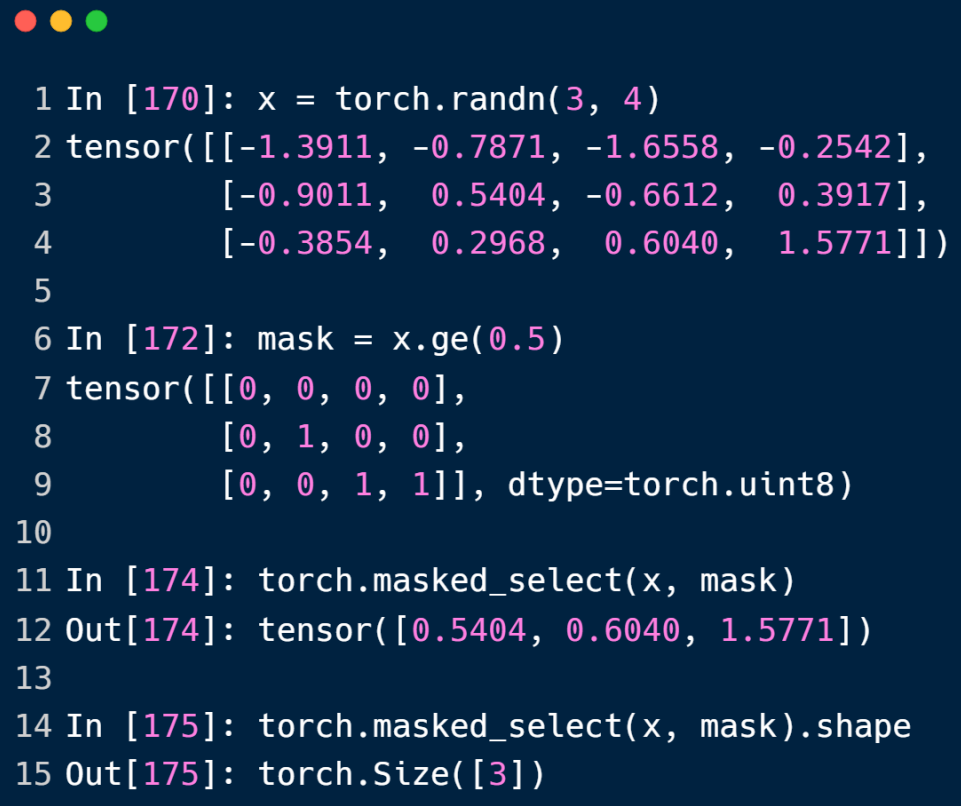
masked_select 方法实现掩码匹配的效果,但结果是以dim为1的tensor返回的
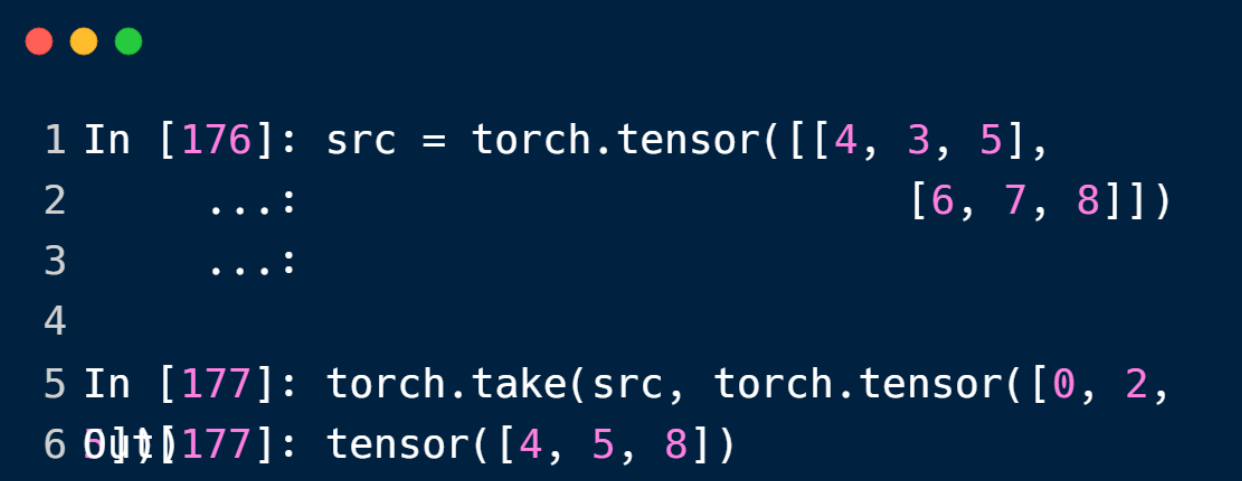
和 index_select 差不多,但是他的第二个参数始终是一个dim为1的tensor,最终一直返回一个dim为1的tensor,即下一行的首个数的索引为上一行末数的索引 +1,src被平铺了
维度变换
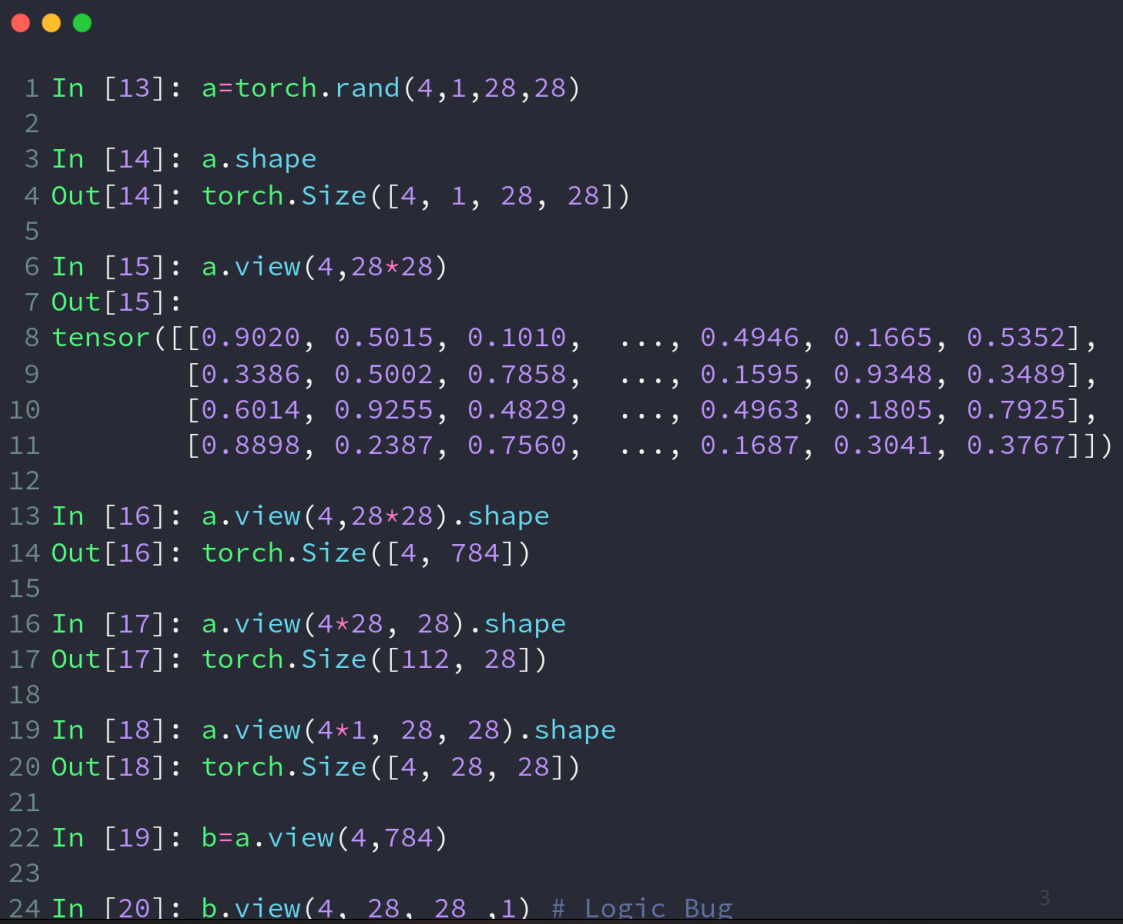
view方法实现维度合并,参数的使用看上图即可,需保证数据不丢失
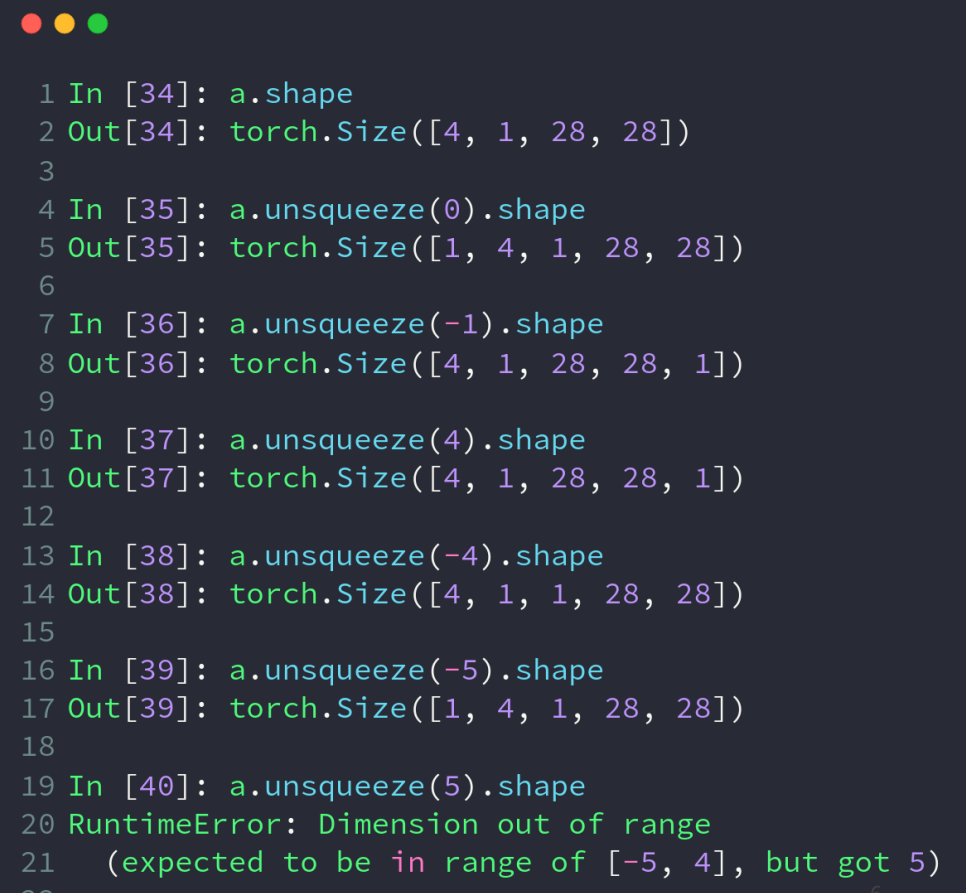
unsqueeze方法实现维度拓展,以参数为索引号,在对应位置增加维度,正数索引是把原来的维度往后推再插入,负数索引则是往前推再插入;参数的范围比索引的范围大 1 ,对于 len(tensor)则是在末尾增加一个维度,对于 -len(tensor)-1则是在首位增加一个维度
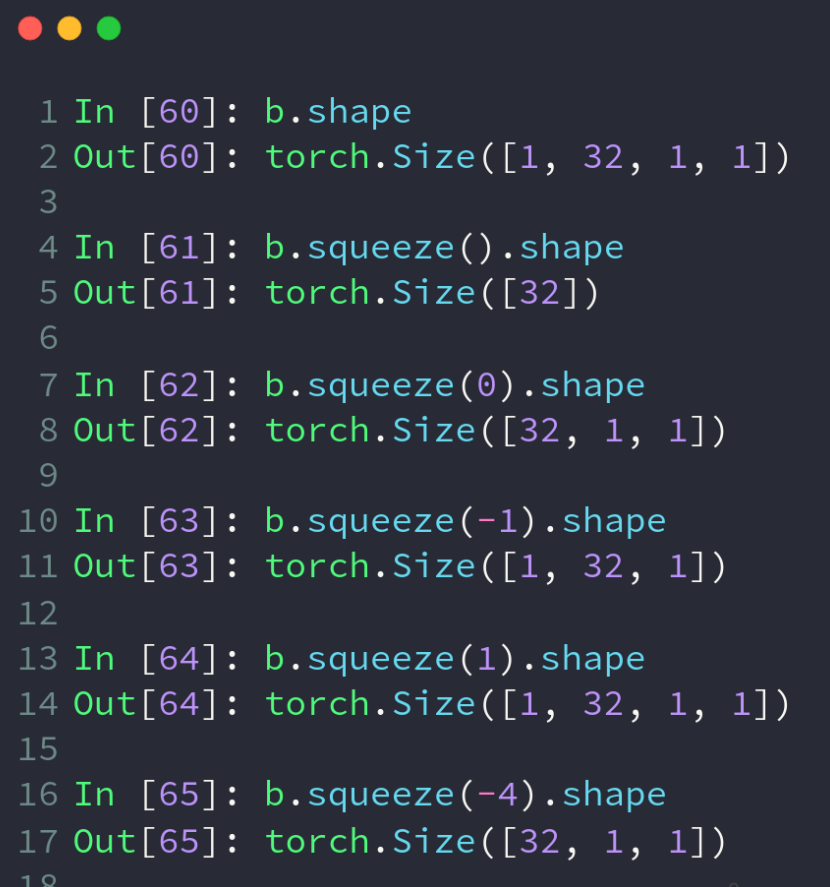
squeeze方法实现维度压缩,规则和unsqueeze差不多,若没有参数则压缩所有可压缩的维度

expend方法实现维度增加,参数数量为dim,参数值为要增加到多少,若为 -1 则是保持不变

repeat方法同expend效果相同,但是参数值表示在该维上增加的倍数,并且增加的数据由原先的拷贝而来
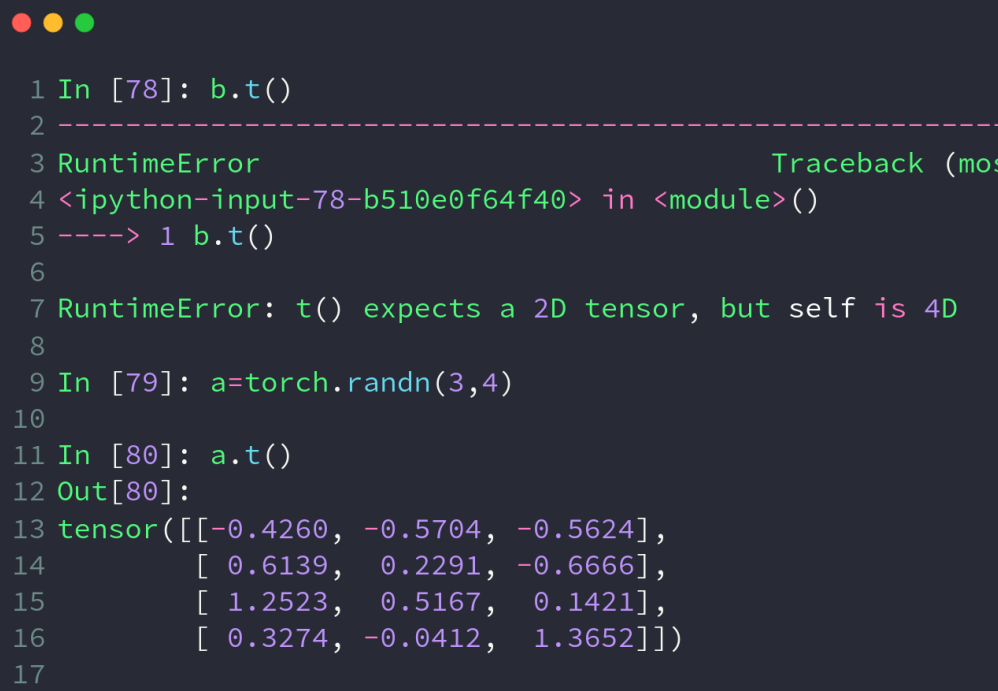
t方法实现矩阵转置
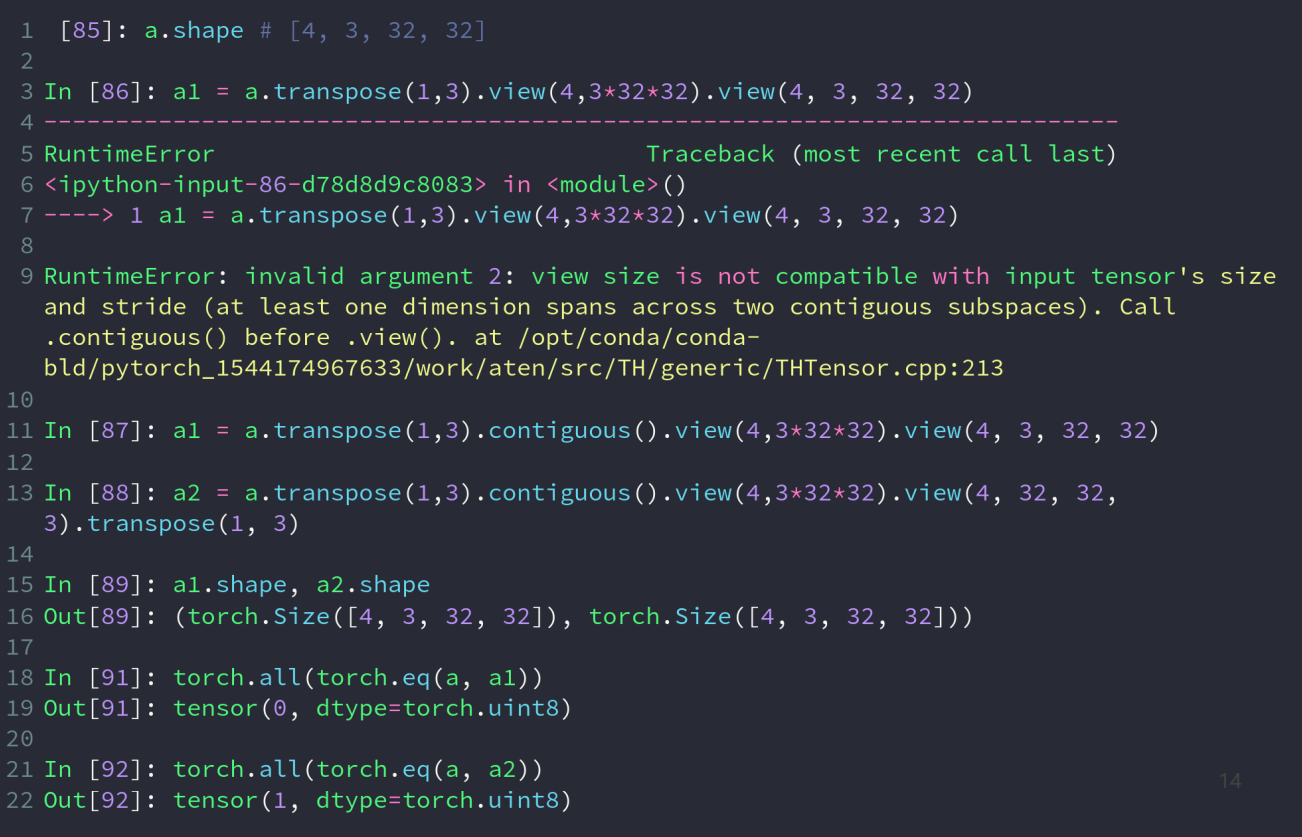
transpose方法交换两个维度

permute方法,参数的数量为dim值,以索引号为准重新排列维度
Broadcast自动扩展
在pytorch中shape不同两个tensor作相加操作有可能会触发Broadcast机制(因为tensor的相加需要满足shape相同的要求),要满足两种情况

拆分与合并
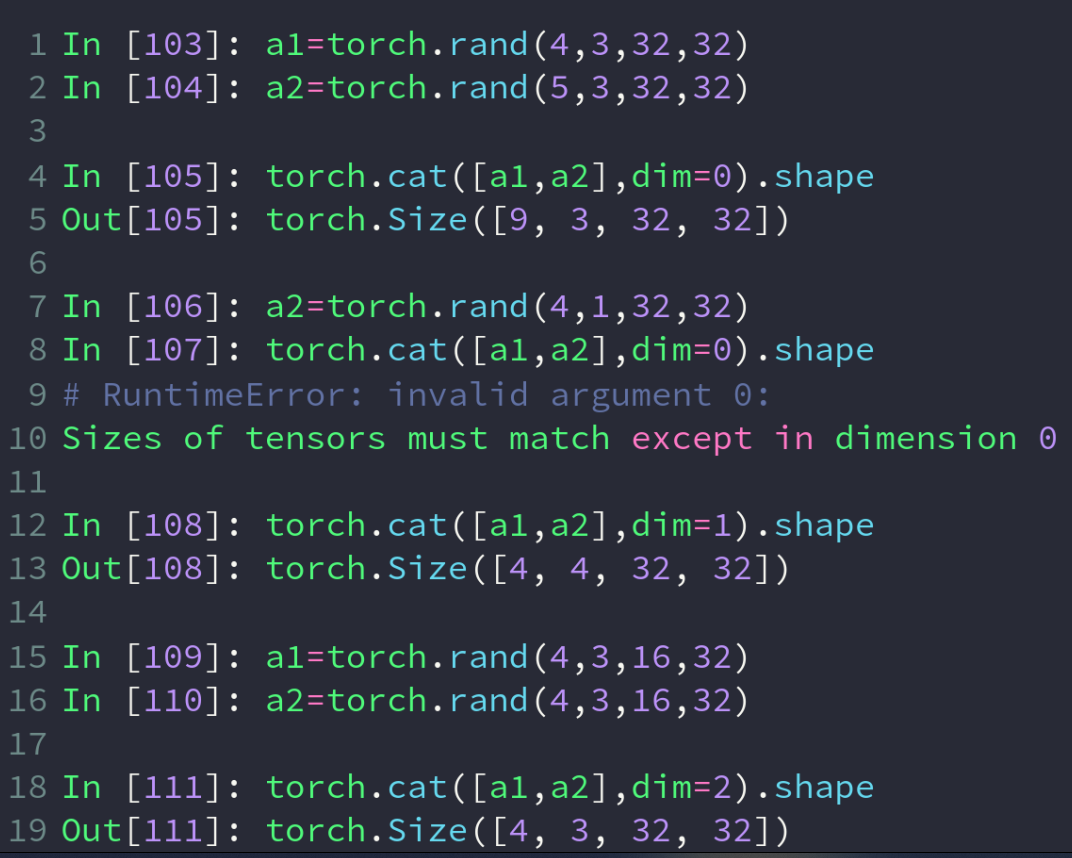
cat操作将tensor合并,并指定合并的维度,其余维度的size需相同

stack方法以在指定的维度前增加一个新的维度的方式来合并tensor,指定的维度的size需相同具体自己看
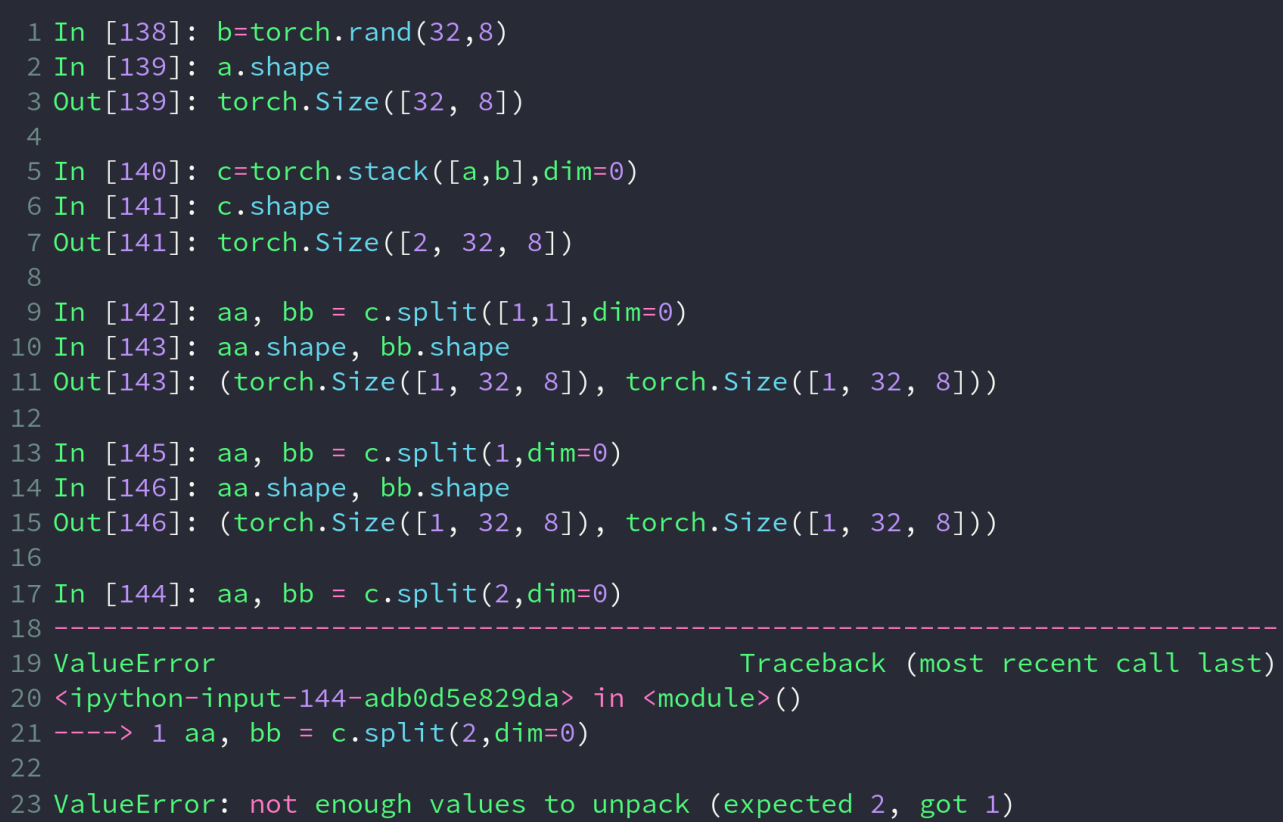
split操作拆分一个tensor,当参数为 list 时,按照 list 的值拆成对应大小的tensor;当参数为一个标量时,则以该标量为大小做拆分;第二个参数为被拆分的维度
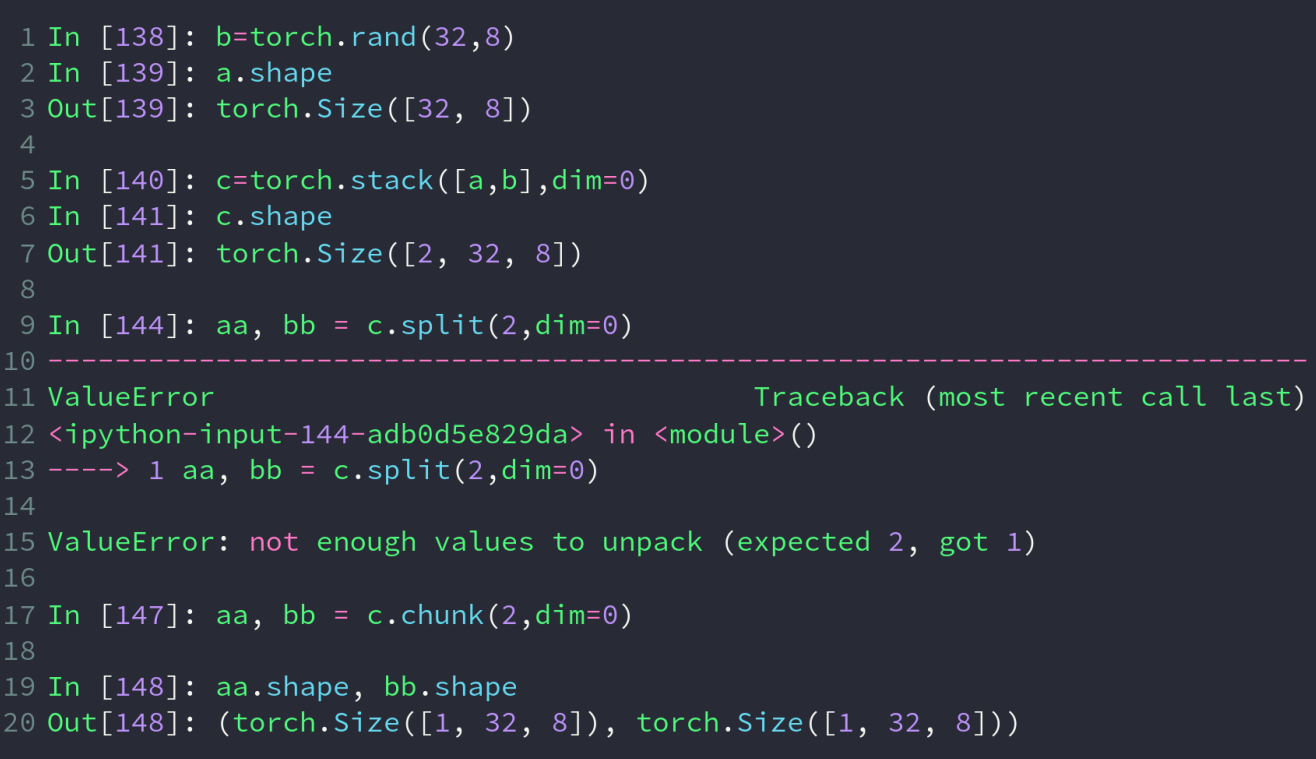
chunk操作类似于split,但是其第一个参数的含义为拆成的份数(num)
数学运算
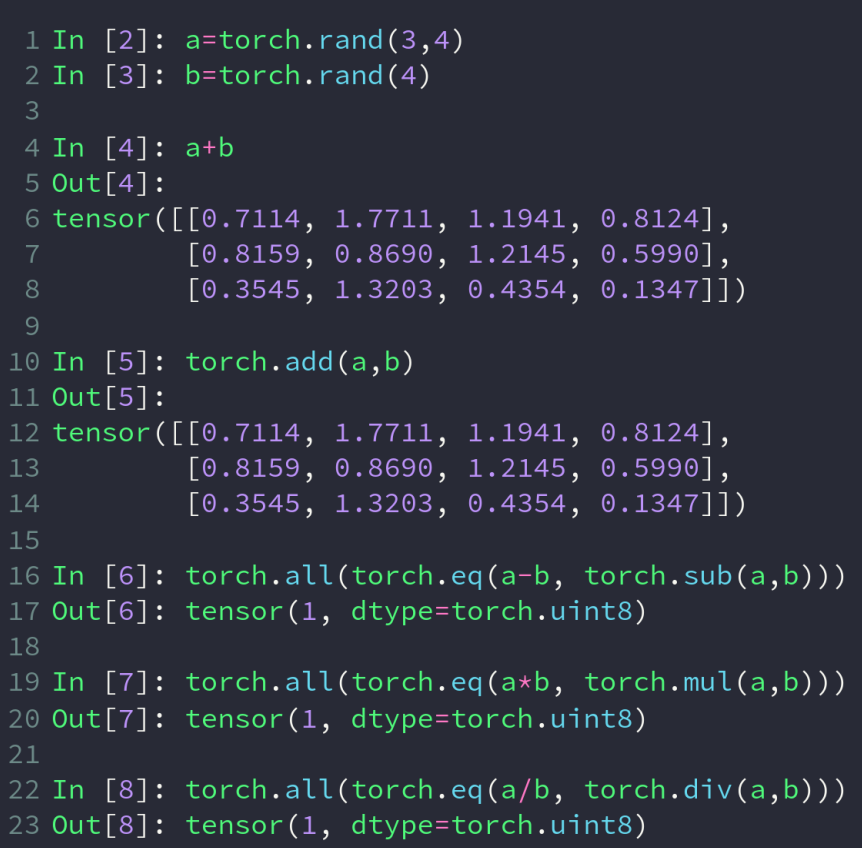
基本的加减乘除运算,其中乘除就是简单的对应位置的数作乘除运算,与矩阵无关

matmul为矩阵乘法,mm方法的参数被限制为2d的tensor所以不推荐使用,当matmul操作dim大于2的两个tensor时,只会对最后两个维度所构成的矩阵作矩阵乘法操作
下面是通过 @ 实现矩阵的降维过程

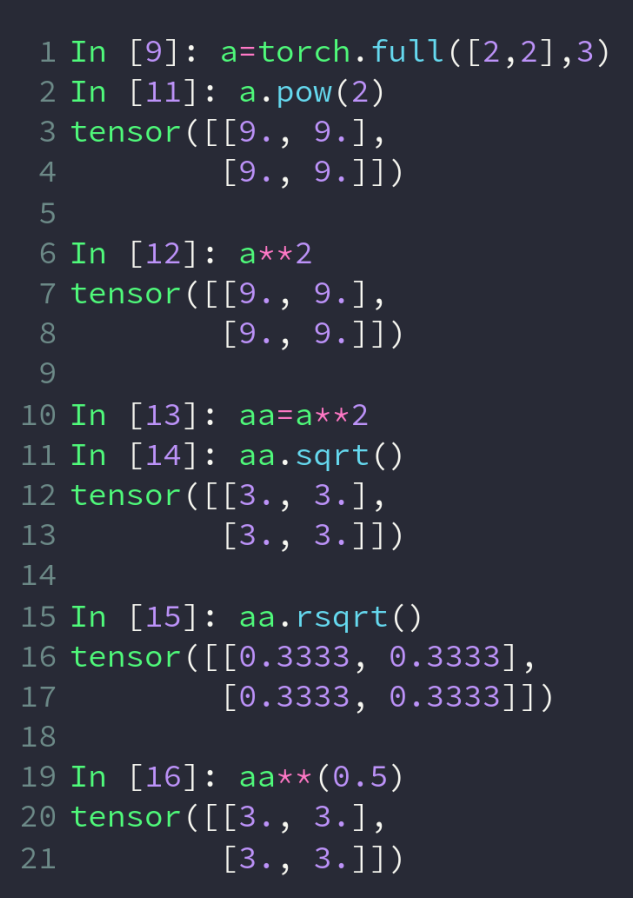
pow和 ** 都是次方操作,sqrt为开平方,rsqrt为取平方根后再取倒数
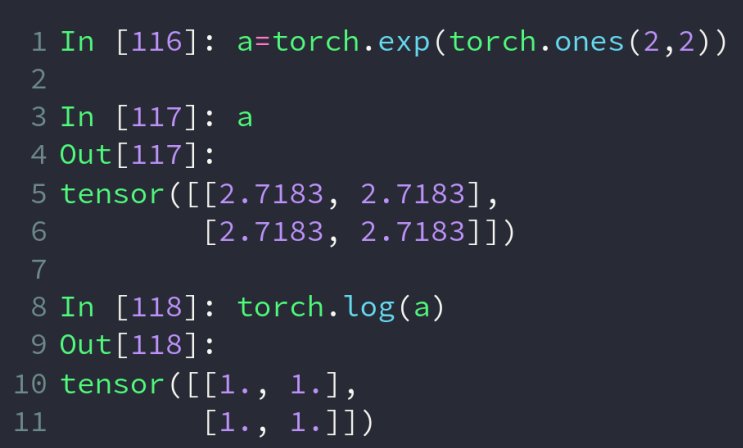
exp和log为指数和对数操作
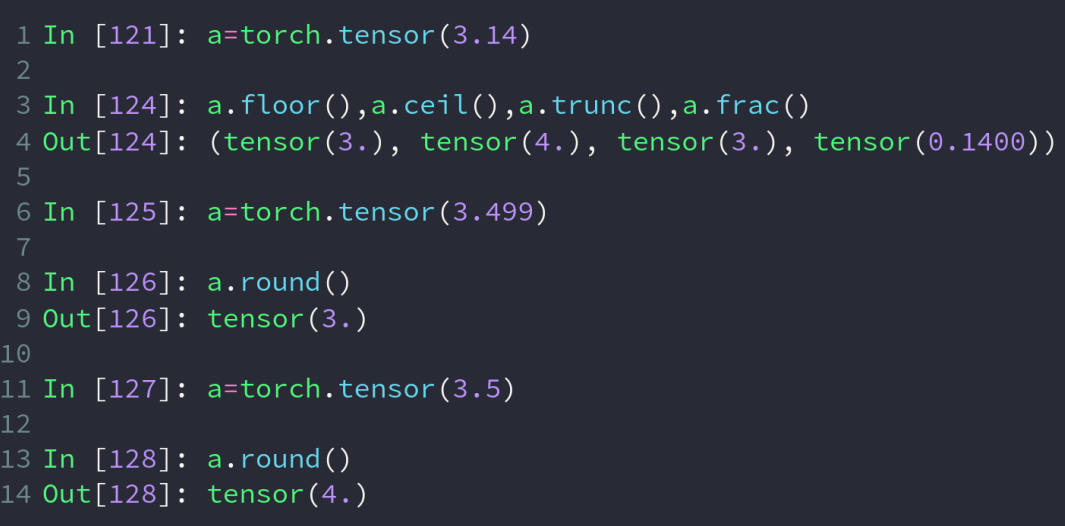
floor 向上取整 ceil 向下取整 trunc 取整数部分 frac 取小数部分 round 四舍五入

clamp 起到裁剪的效果,设置一个tensor的最大最小值
统计属性
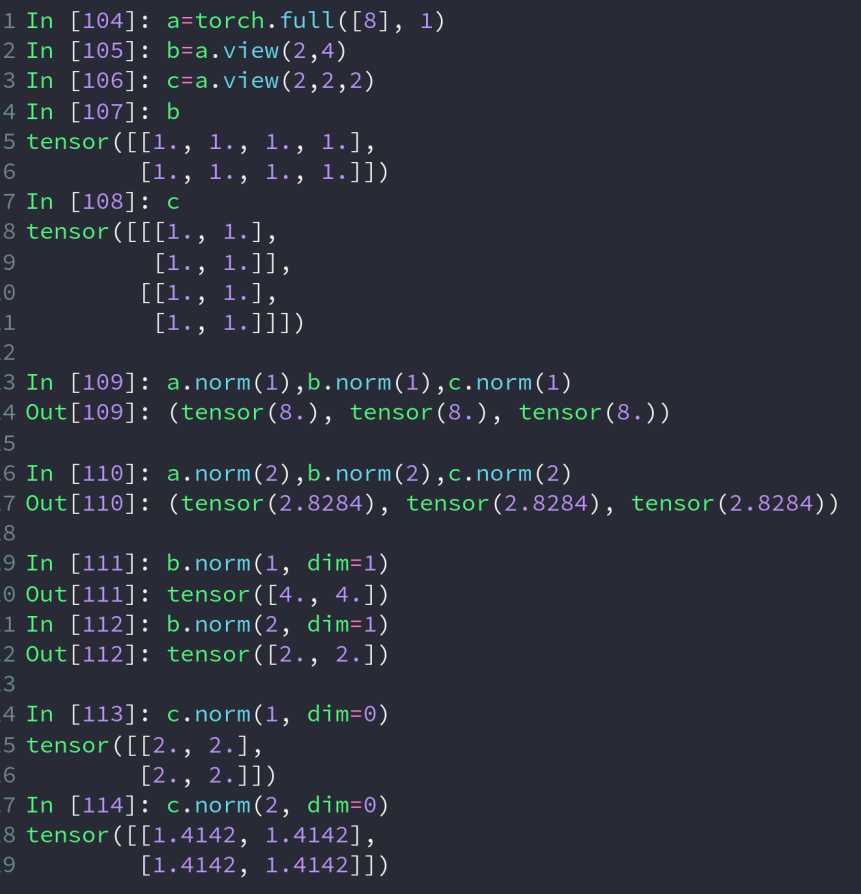
norm() 求范数,深入了解可百度
当参数为 1 时,求整个 tensor 的和;当参数为 2 时,求整个 tensor 的平方和再开更号
当拥有第二个参数 dim 时,对 dim 维作范数运算
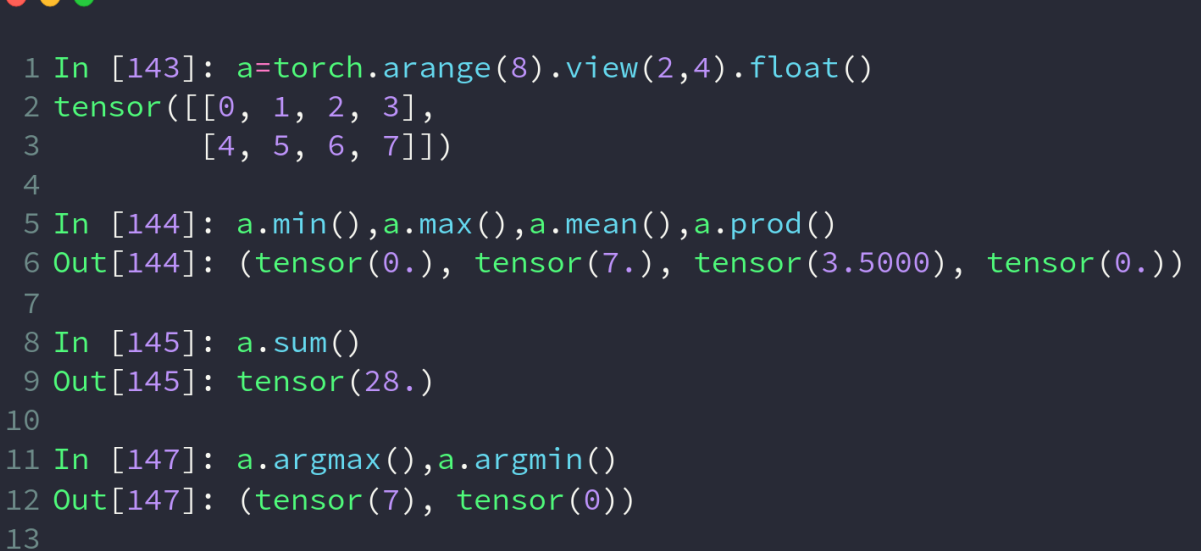
min 最小值, max 最大值, mean 均值, prod 累乘, sum 求和, argmax 最大值的下标, argmin 最小值的下标
其中 argXXX 得到的下标都是原 tensor 平铺展开后的下标
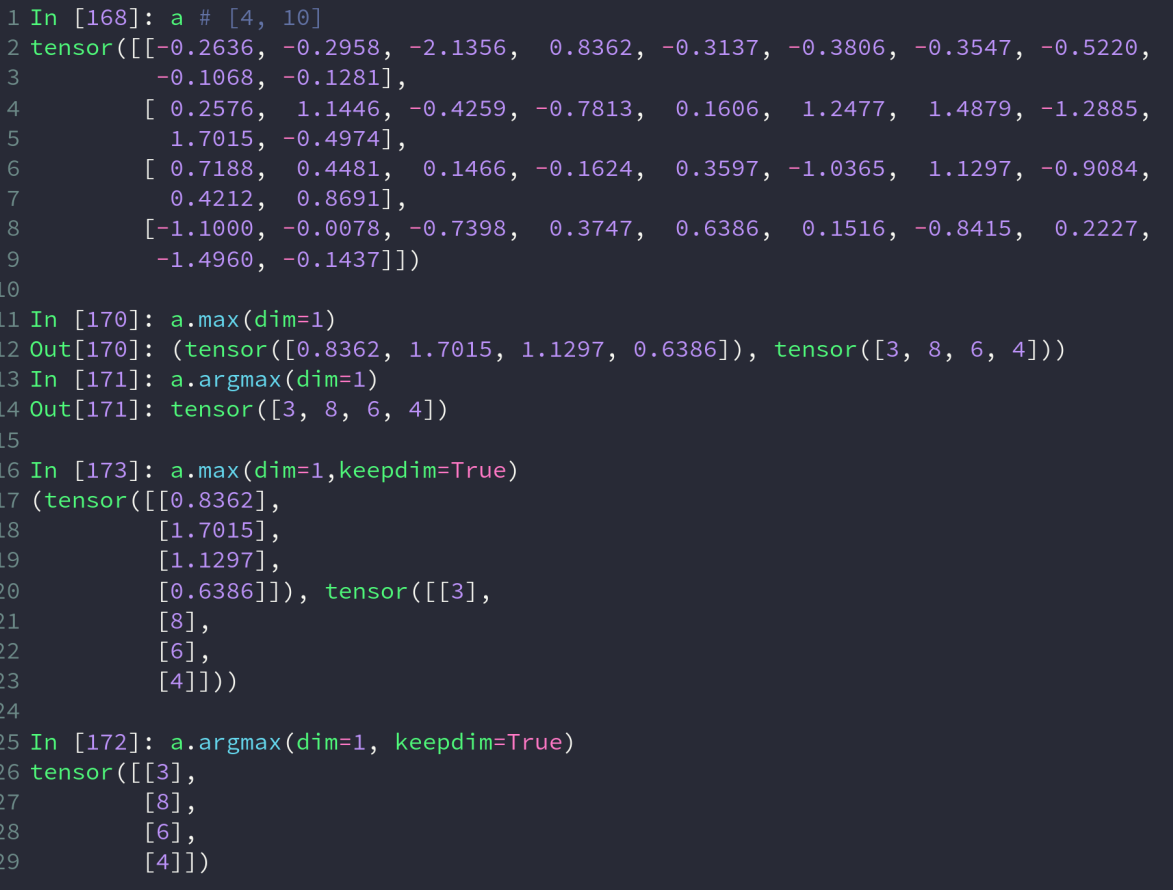
前几种操作都有 dim 和 deepdim 参数,下面的操作也有
dim:表示对该维度做某种操作,如图中 dim=1,则对每一组数求取最大值
keepdim:为 true 则输出的结果仍然保留原来的 dim 值
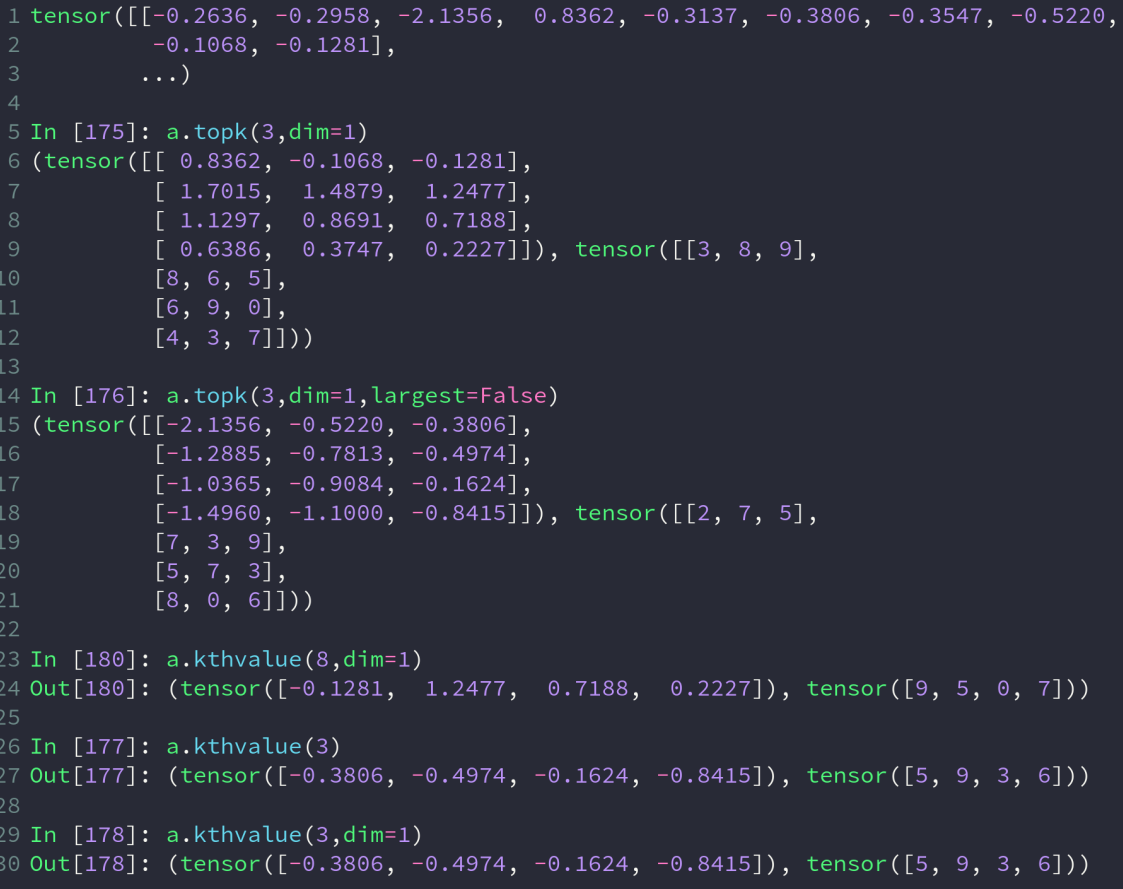
topk() 取前 k 大的数
kthvalue() 取第 k 大的数
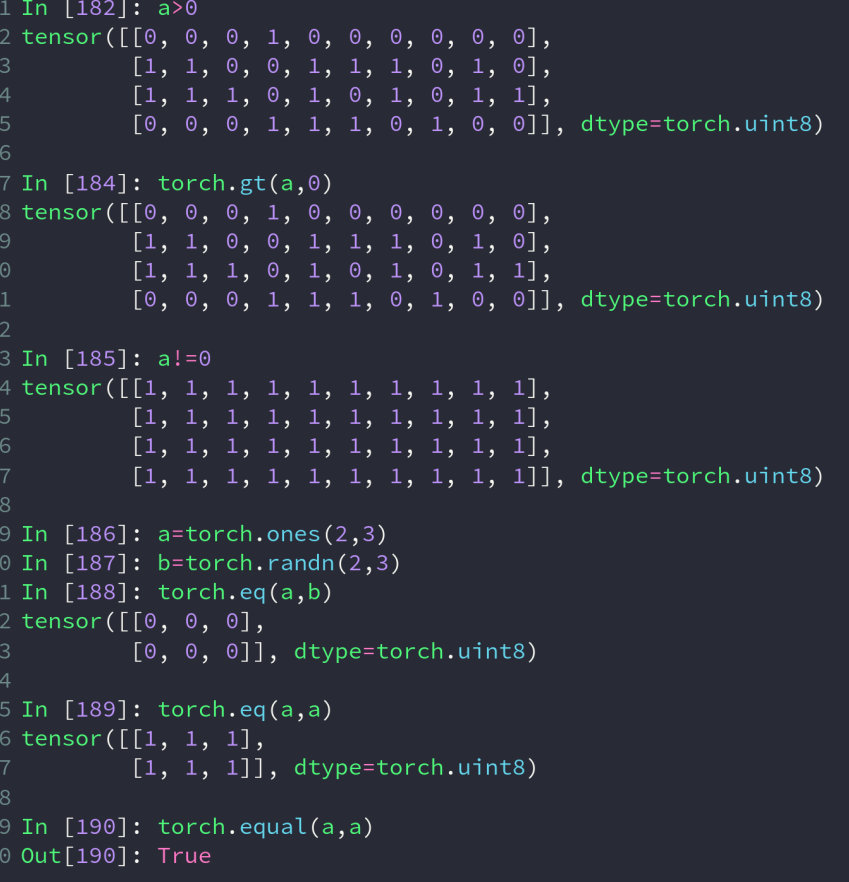
 比较操作,结果返回一个由 0 和 1 构成的tensor
比较操作,结果返回一个由 0 和 1 构成的tensor
高阶操作
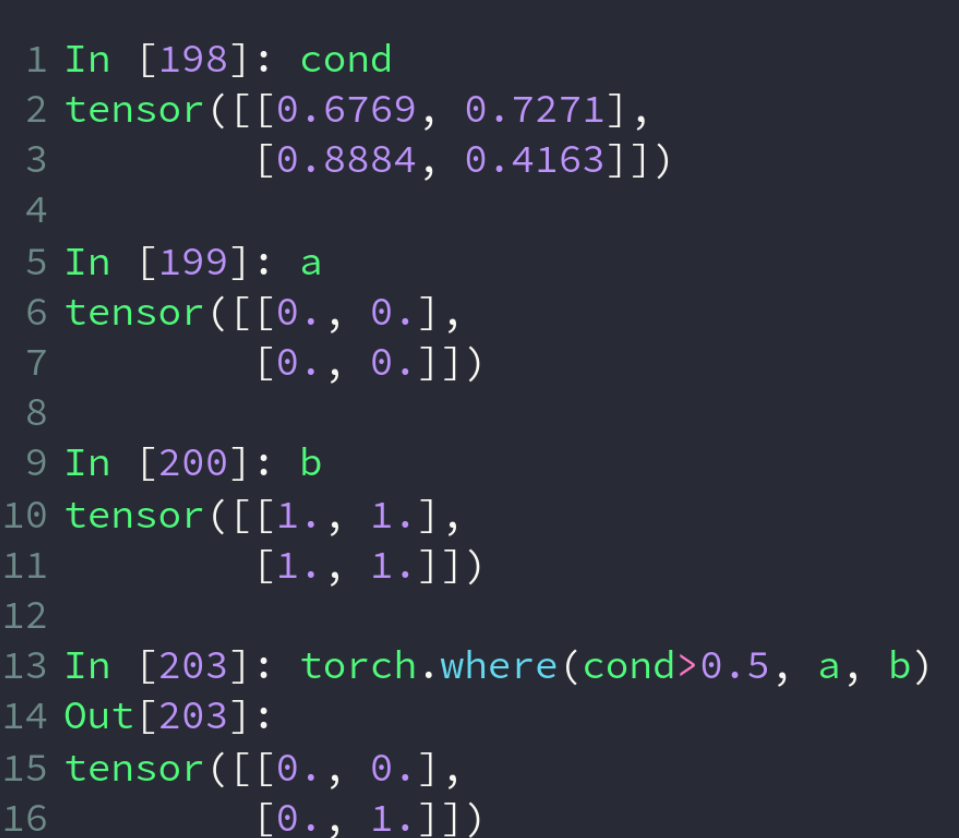
where 操作
torch.where(condition, x, y):
condition:判断条件
x:若满足条件,则取x中元素
y:若不满足条件,则取y中元素
所以要求三个参数的 shape 一样
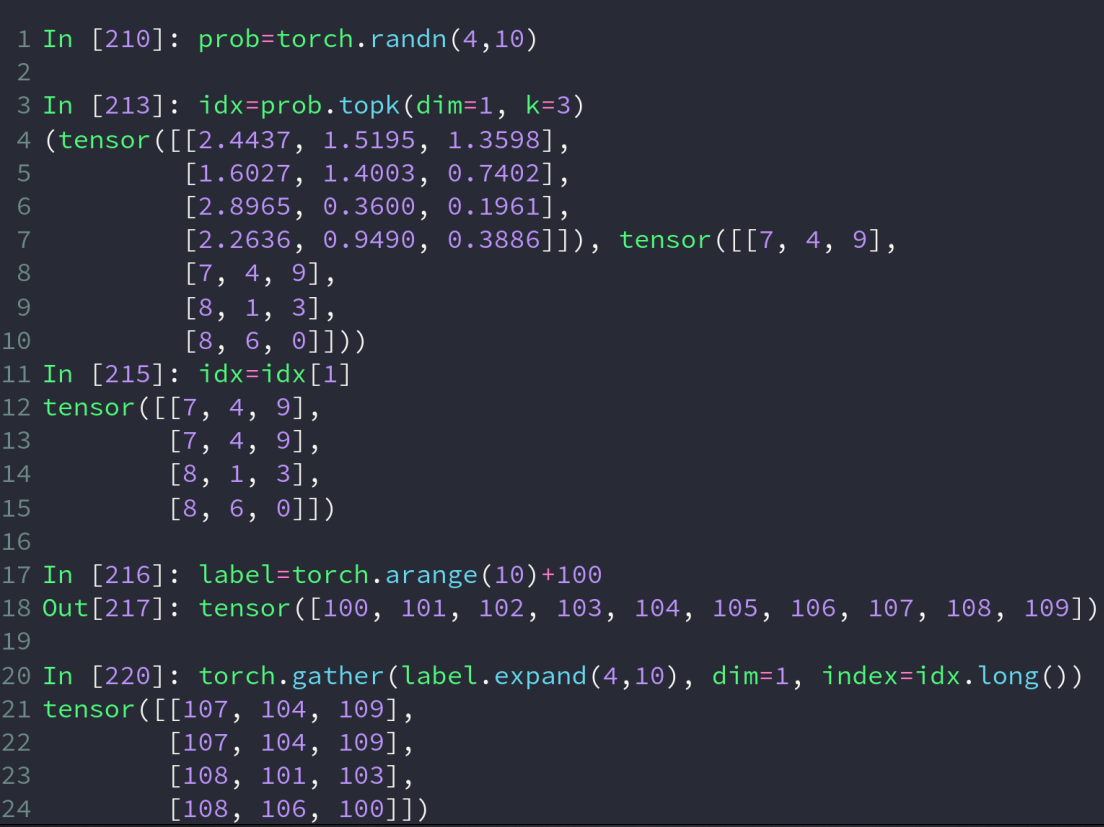
gather 操作


用一个 tensor a 去查另一个 tensor b,得到的结果 tensor c 的 shape 与 a 一样(即遍历 a,每经过一个数字都会对应去b 中查一个数字来组成 c),查找的规则取决于 dim 的取值,即查找的下标于此时 a 的下标除了 dim 指向的维度外其余都不变,dim 指向的维度的下标变为 a 中当前位置的值
梯度
梯度,gradient,与导数相似,不过梯度是一个向量,它代表了所有方向的一个综合趋势
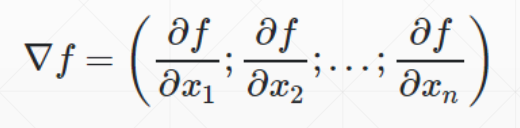
利用梯度求最小值
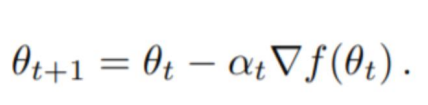
例如
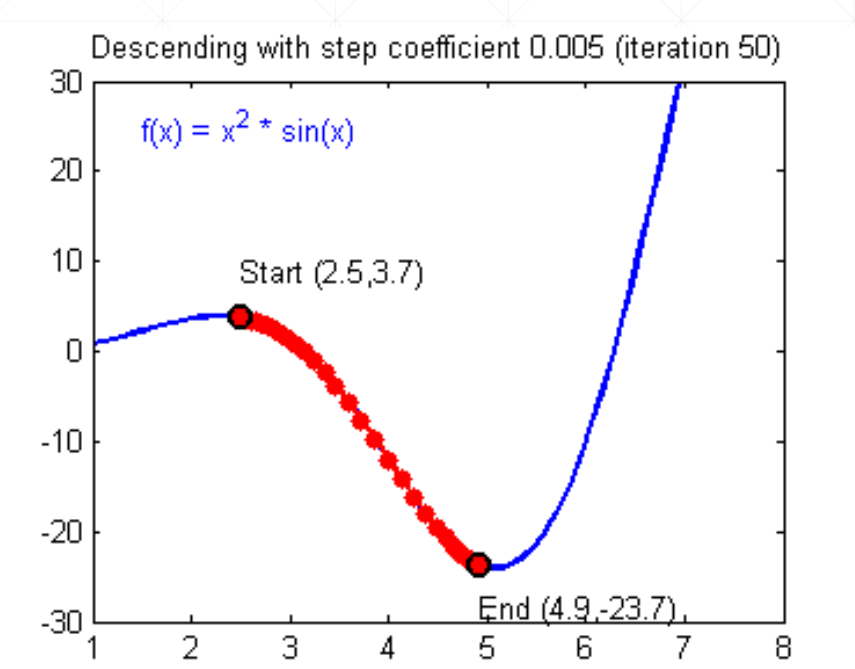
局部最小值问题
对于复杂的函数可能只能得到局部最小值,例如下面这个
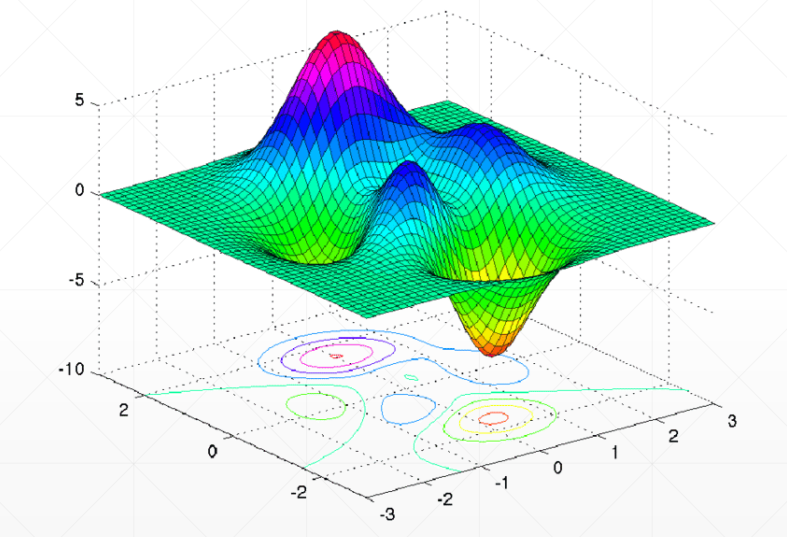
鞍点问题
存在鞍点,其又是 “极小值” 又是 “极大值”,在复杂函数中更为常见

学习率问题
参数 αt 的大小影响梯度下降的快慢,过大会导致再极小值处震荡,过小则导致收敛过慢
激活函数
激活函数源于神经元对于多个刺激的相应是非线性的
Sigmoid
其基本形式为:
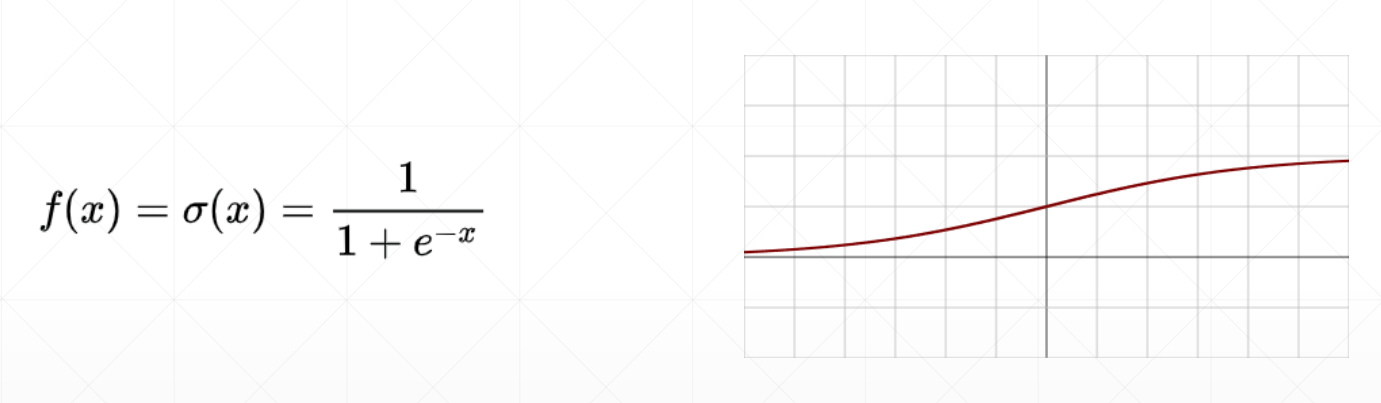

在PyTorch中实现

Tanh

其导数为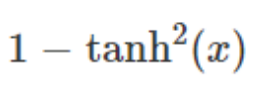
在PyTorch中实现

ReLU
Rectified Linear Unit
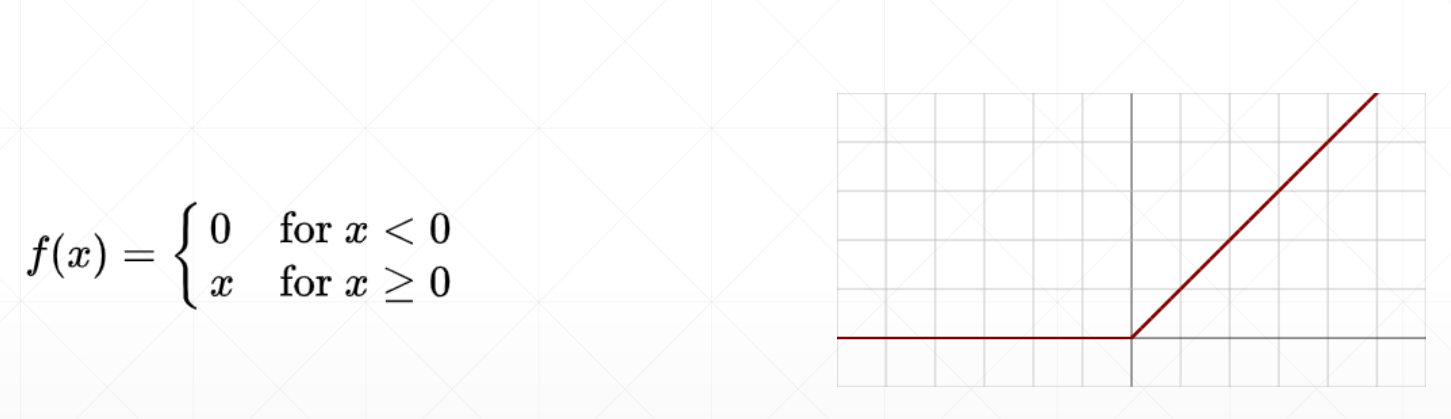
其导数为其本身
在PyTorch中实现

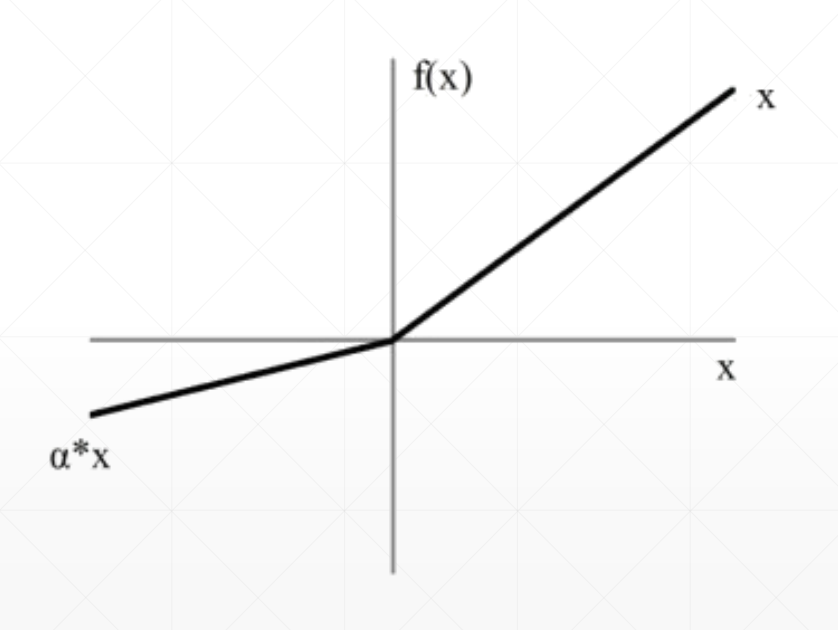
Leaky ReLU
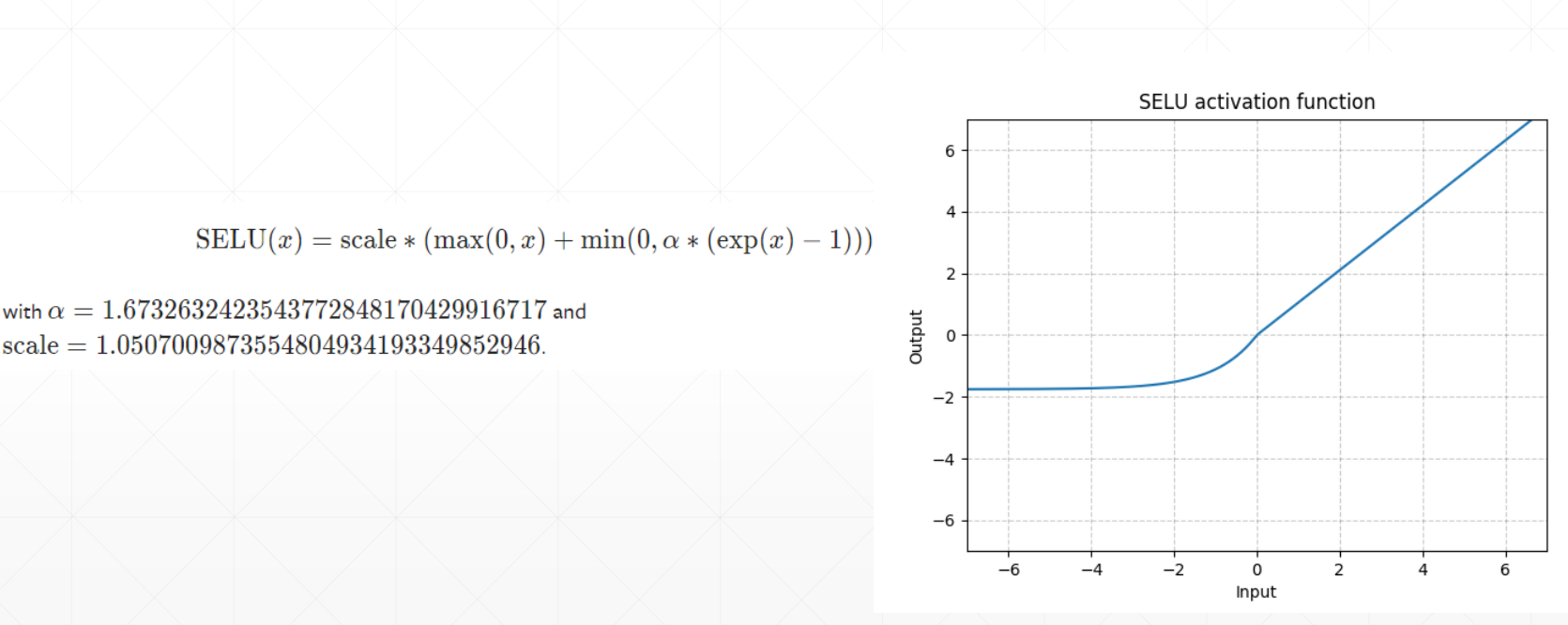
SELU
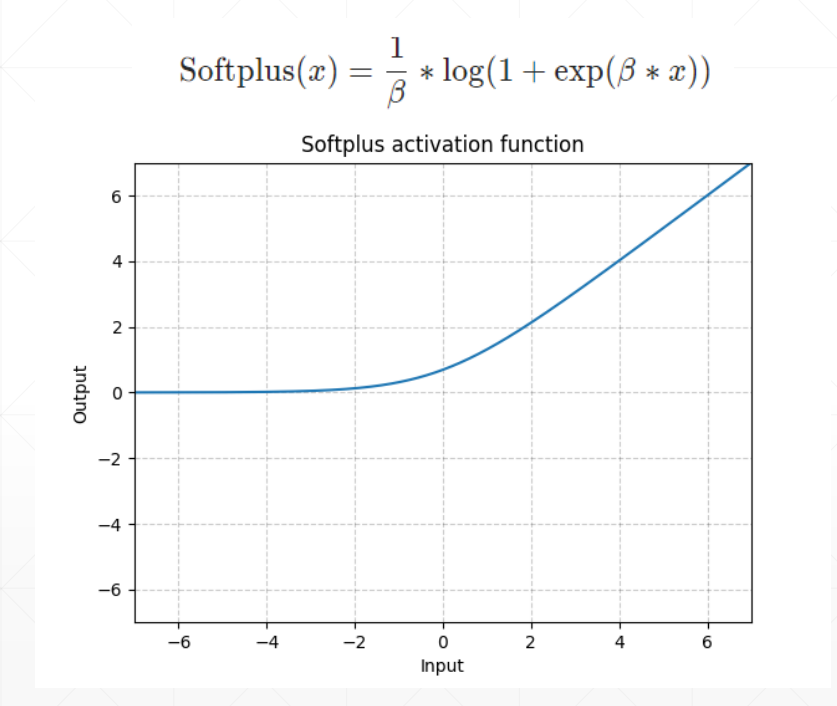
softplus
LOSS
Mean Squared Error
均方差损失

如果用norm表示的话
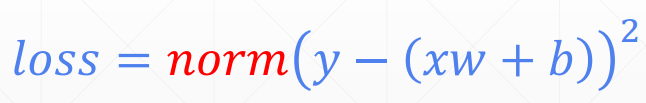
其梯度为
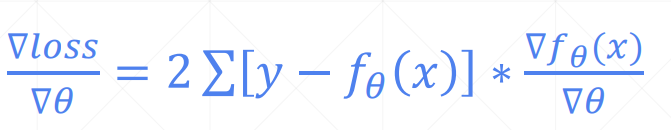
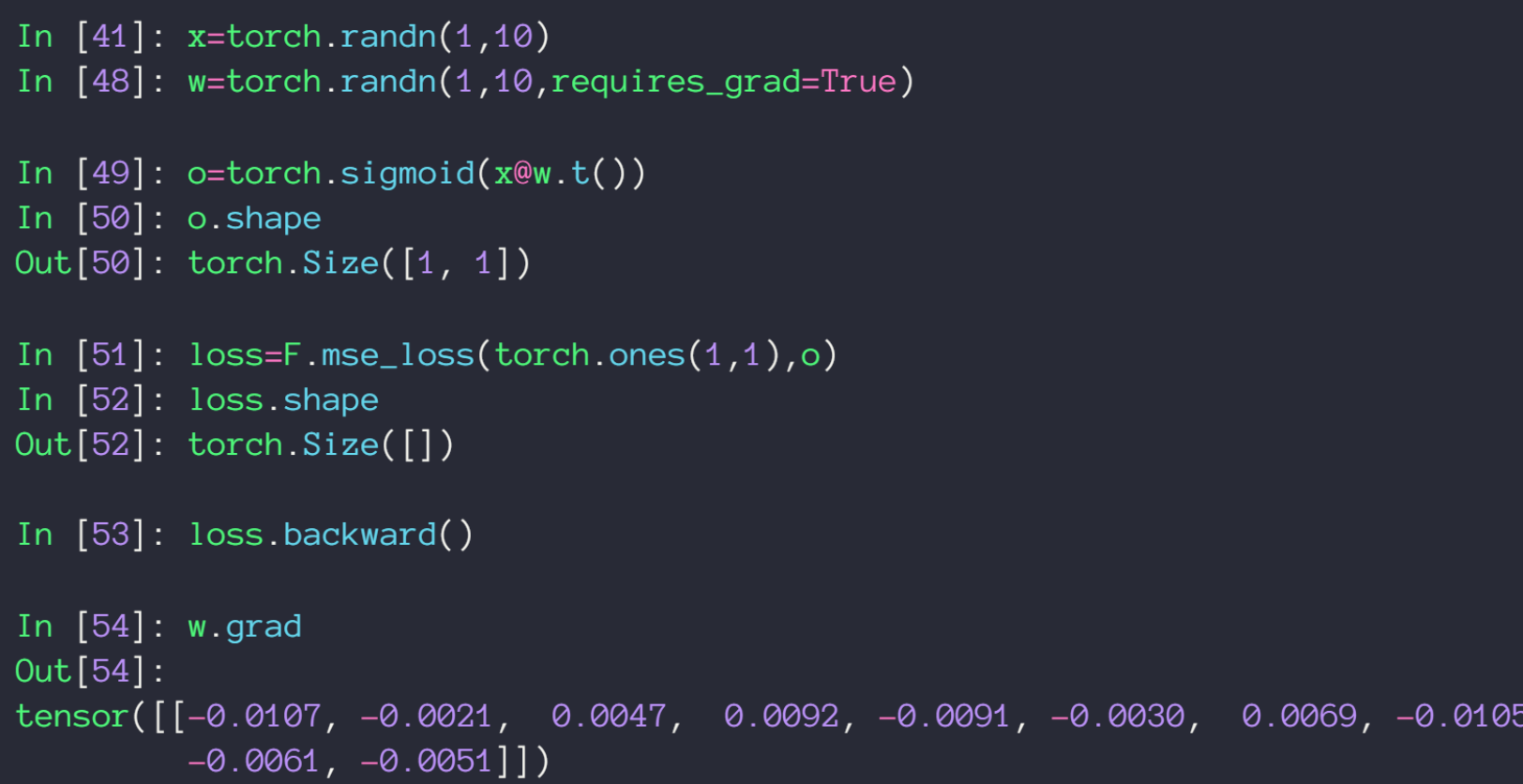
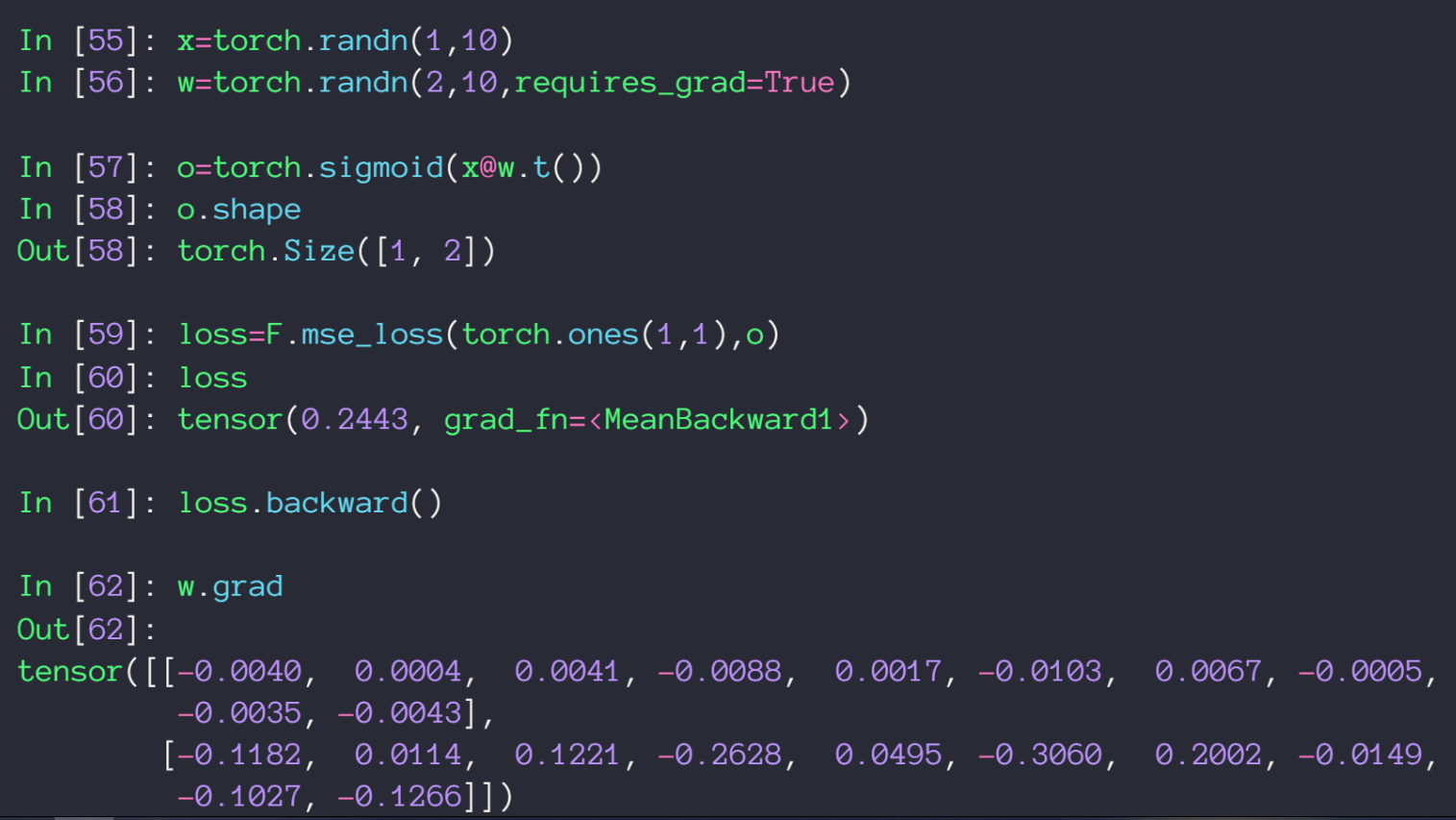
在PyTorch中用autograd.grad() 求梯度
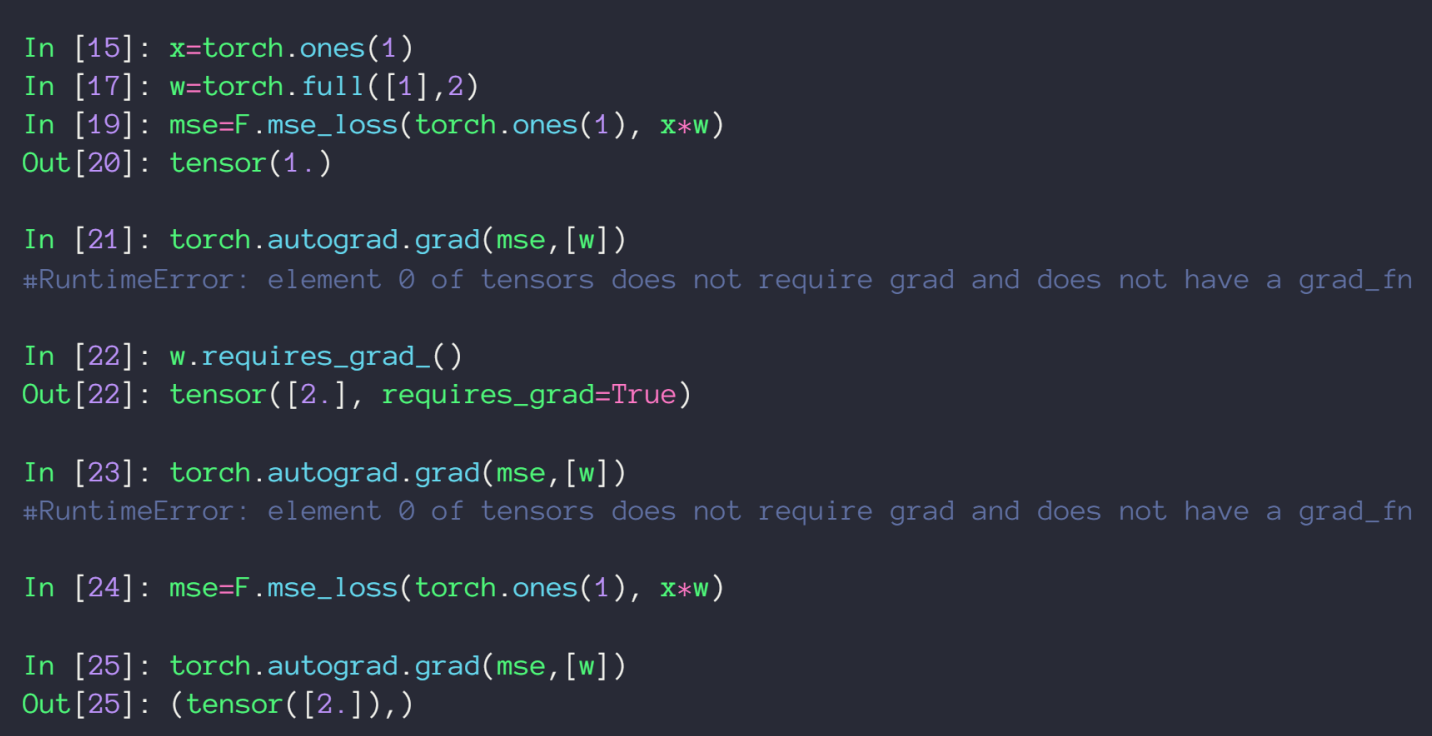
mes_loss() 构造 loss 函数,参数代表平方和中的减数与被减数
autograd.grad() 第一个参数为 loss 函数,第二个函数为对那个未知数求梯度,但有个前提条件该未知数在定义是其 requirs_grad 参数为 true(默认为false),也可以通过 requires_grad_() 方法来修改已创建的tensor
用 loss.backward() 求梯度
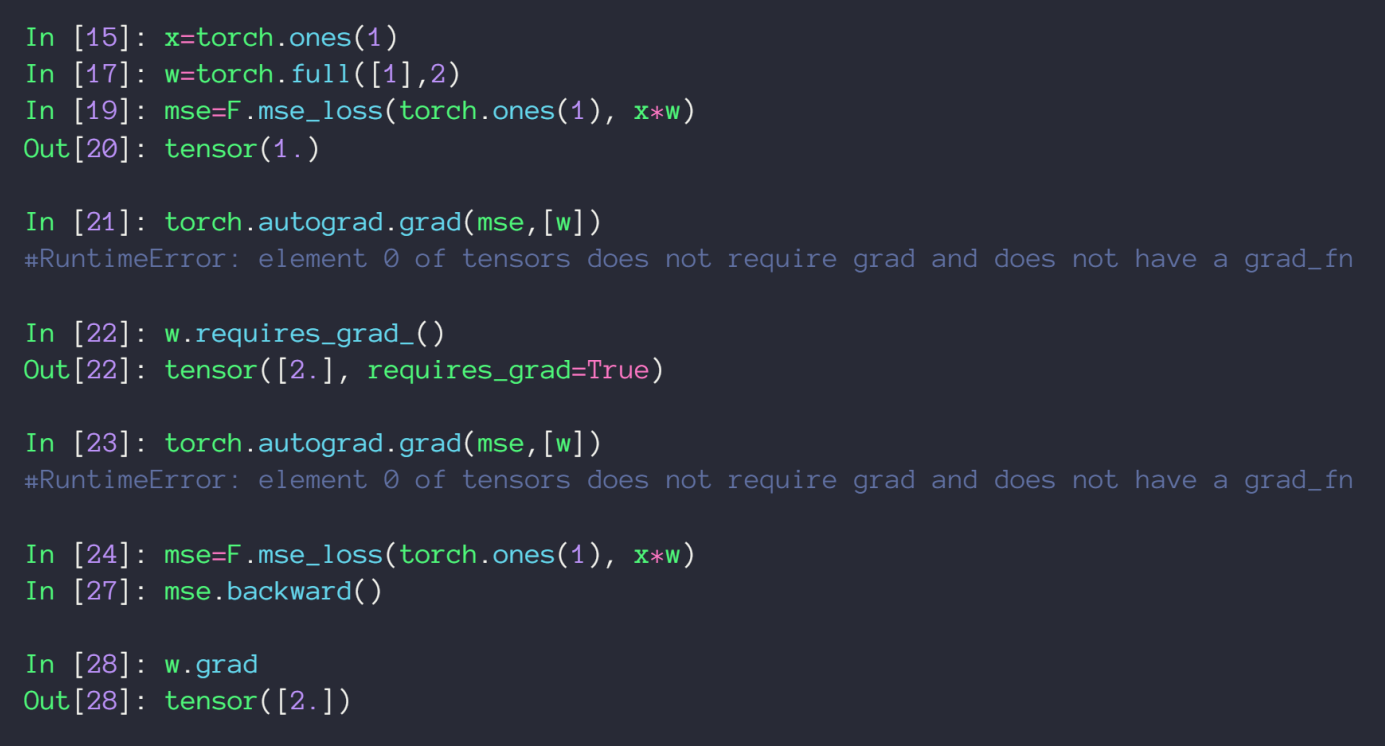
不同于 autograd.grad() 会把求出的梯度值以 tensor 形式返回,loss.backward() 只会把梯度值赋值给变量的 grad 属性
总结

Cross Entropy Loss
Softmax
其转换方式如下
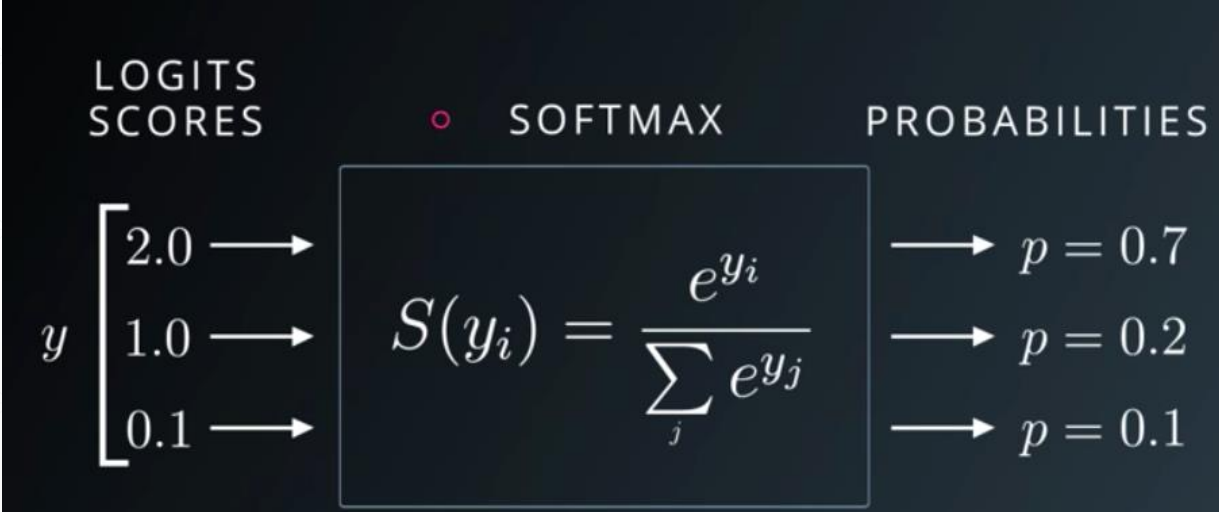
求导结果为
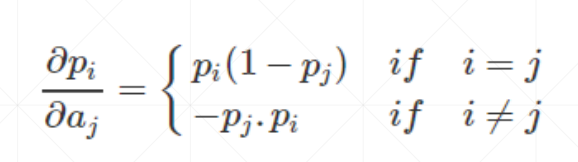
在PyTorch中使用:
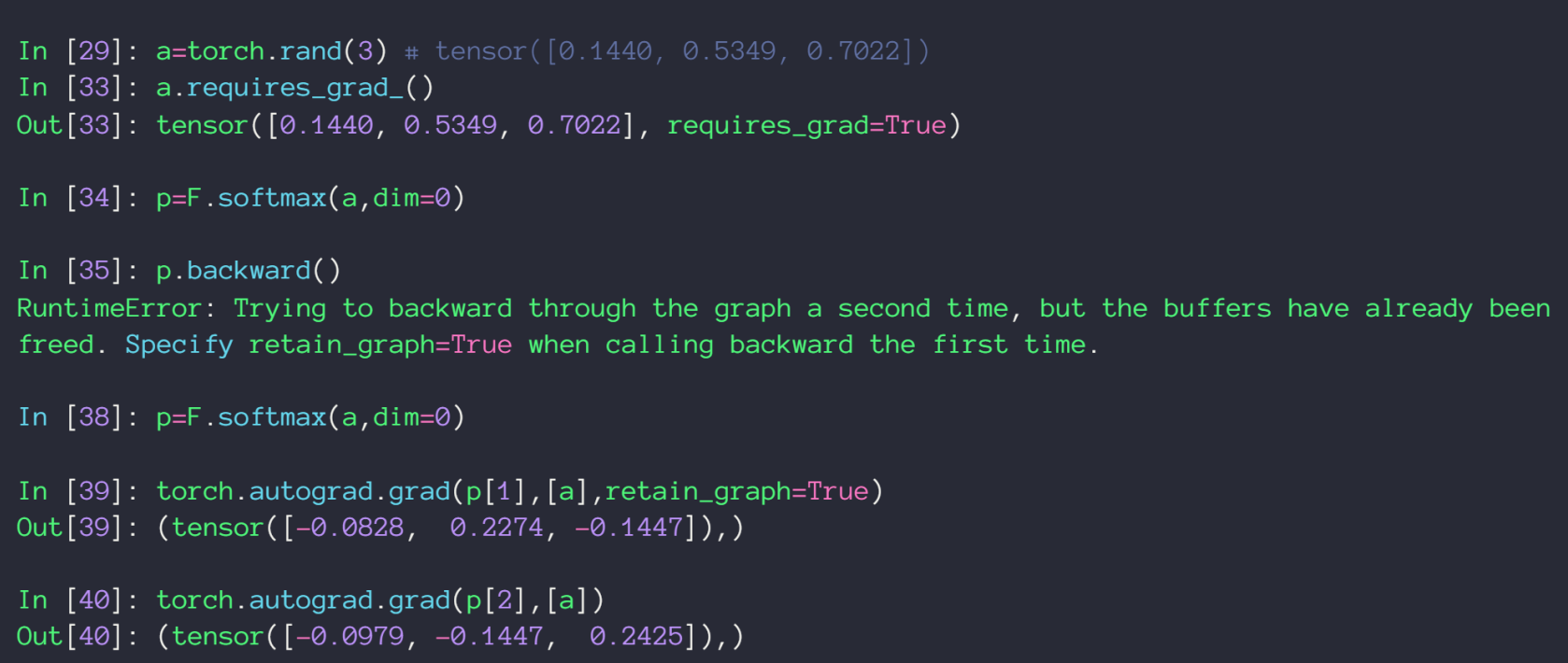
在34-35之间还有一次 backward() 的调用才导致了下面的报错,因为每次使用 backword() 后,合成的图会被删除,除非是 p.backward(retain_graph=True)
合成的 p 是一个 dim 为 3 的 tensor,而 autograd.grad() 只能是以一个 dim 为 1 的 tensor 去对某个值求导,所以只接受p[i]
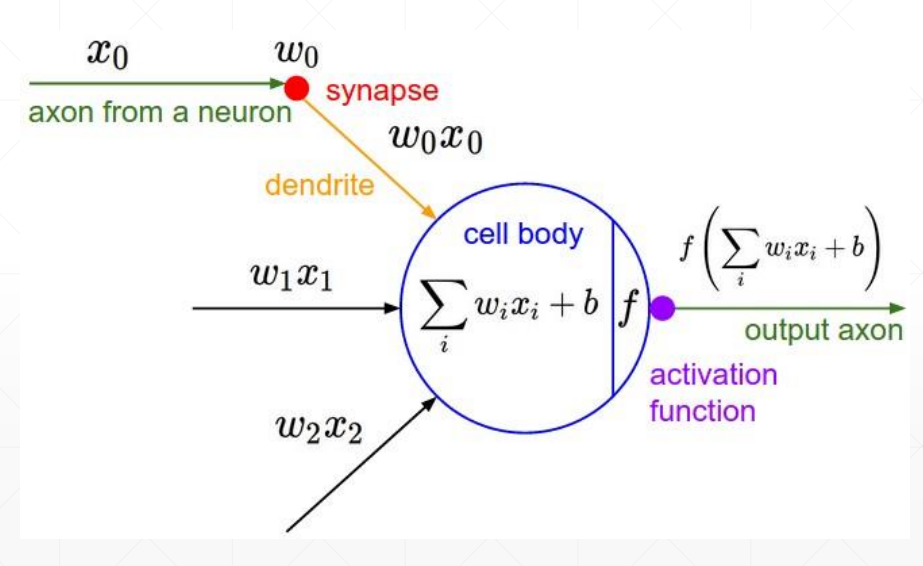
感知机
单输出感知机模型
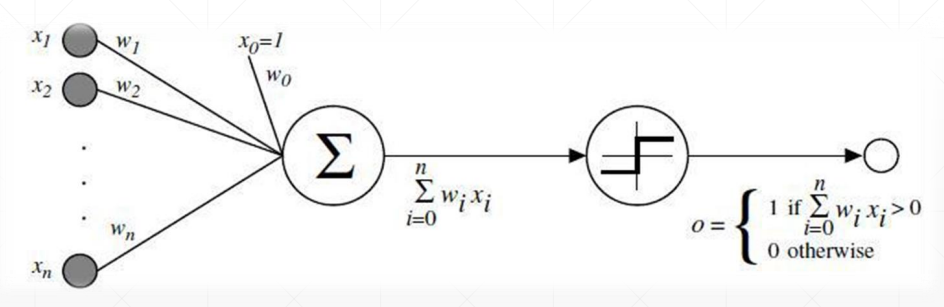

求导
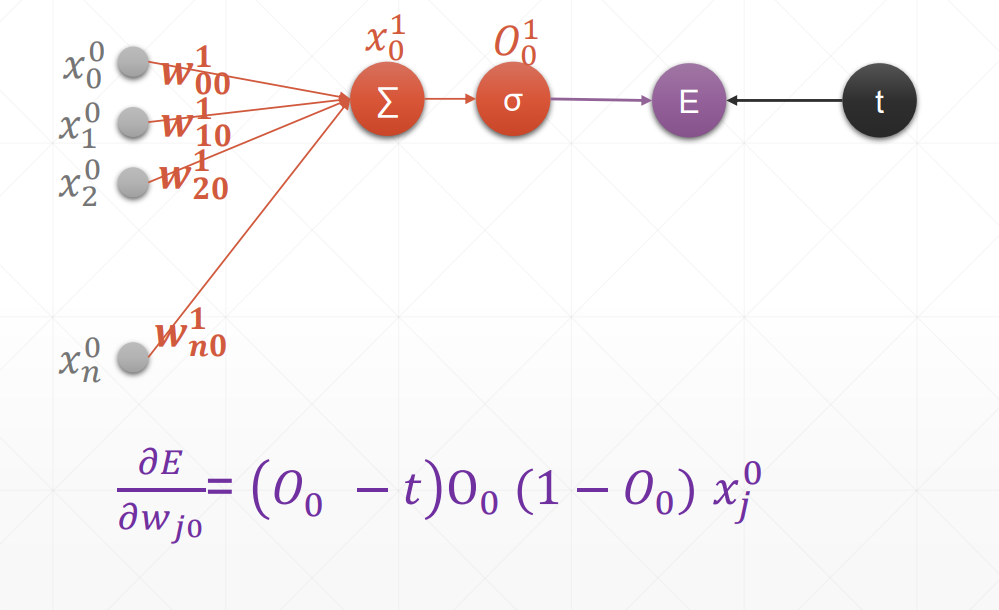
其中 x 上标 0 表示输入,下标 n 表示索引;w 上标 1 表示输出,下标 ij,i 与输入下标对应,j 表示输出索引
O 表示经过激活函数变换后的结果
PyTorch简单实现
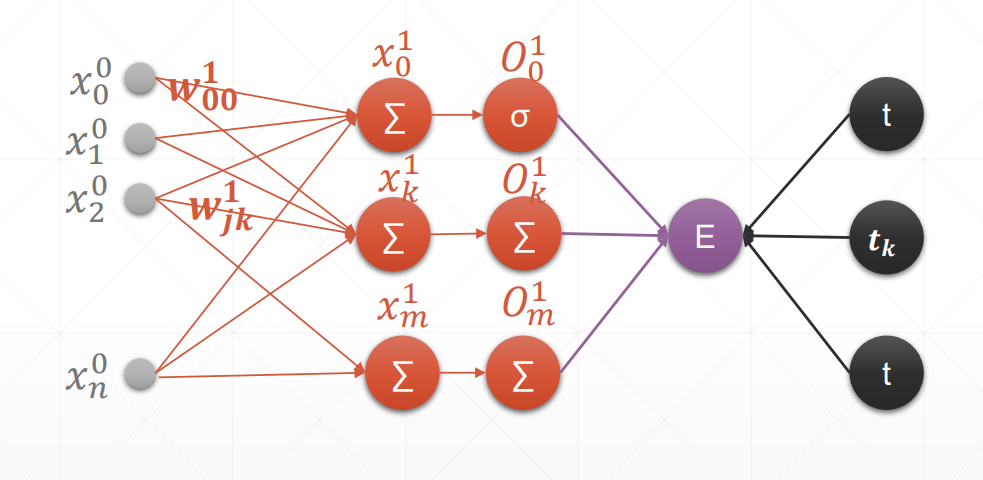
多输出感知机模型
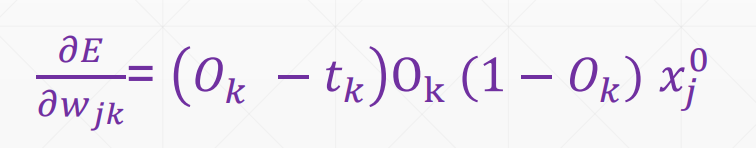
PyTorch简单实现
每一个 O 对每一个输入 x 都有一一对应的关系,即对所有 w 求导
MLP反向传播
链式求导法则
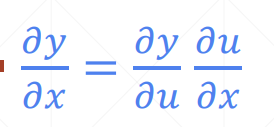
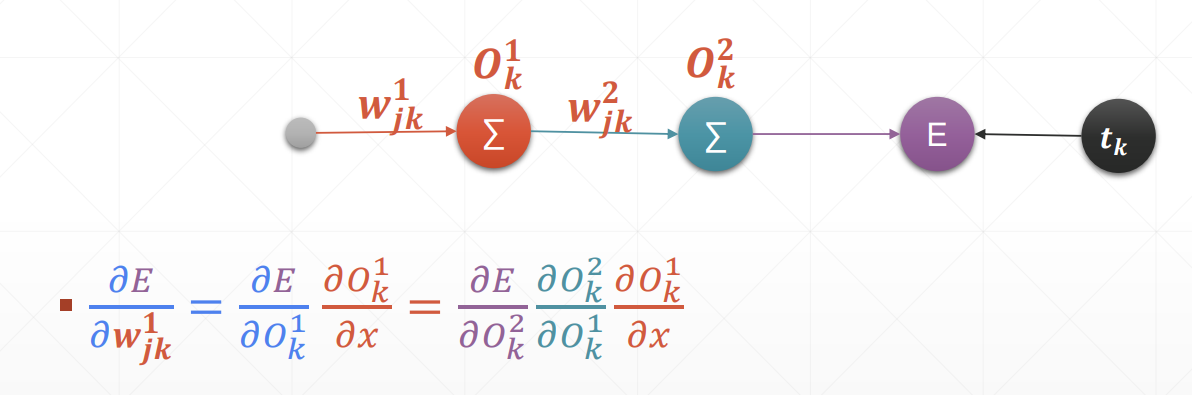
反向传播
对于一个多层的网络来说
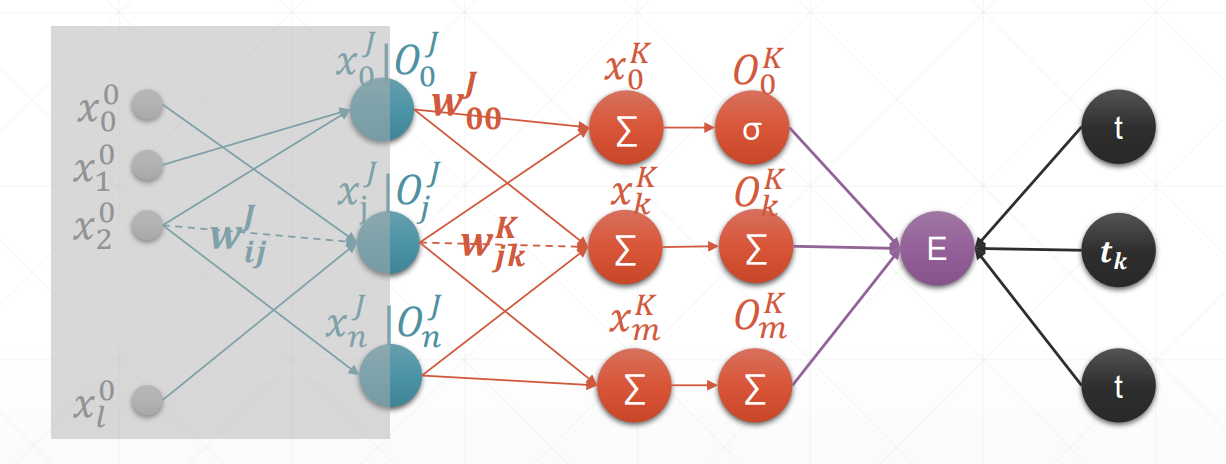
先推导最后一层的梯度算法(感知机部分已推过,原来的输入 x 变成了上一层的输出 O)
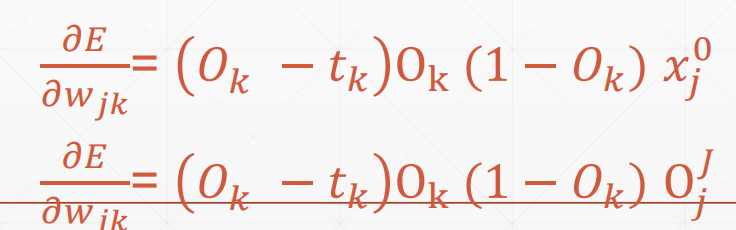
令 =
=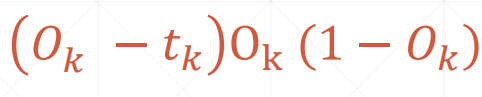 ,其关键不在于形式而是其代表了该层往后的已知信息
,其关键不在于形式而是其代表了该层往后的已知信息
再由最后一层推倒数第二层的梯度
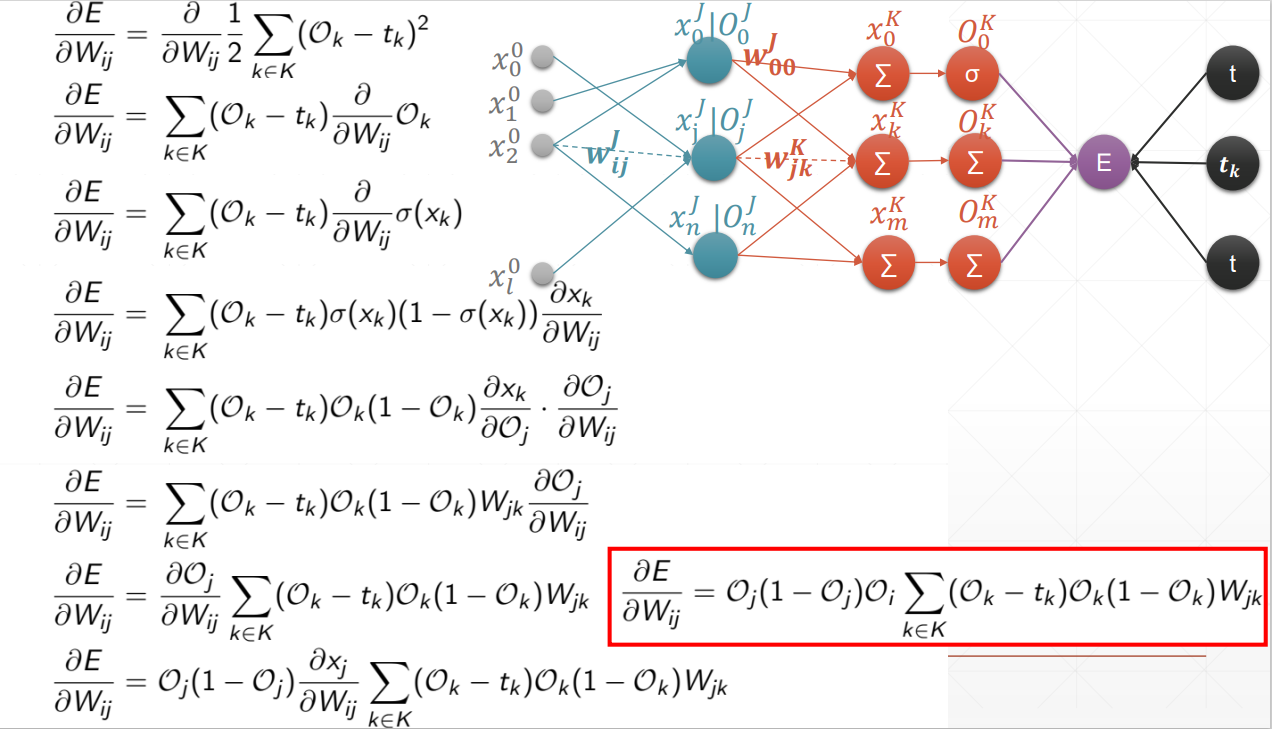
可以看到对 Wij 求导的结果除了 Oi 外其余都是该层往后已知的东西(包括Wjk),这就是从后往前推的反向传播算法
简单函数优化实例
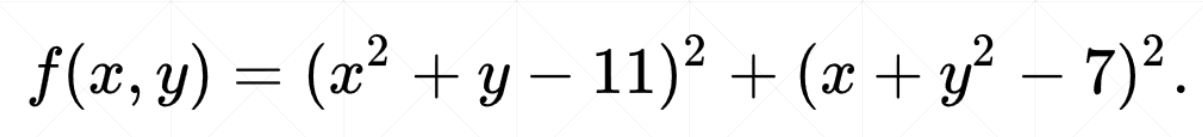
四个极小值点
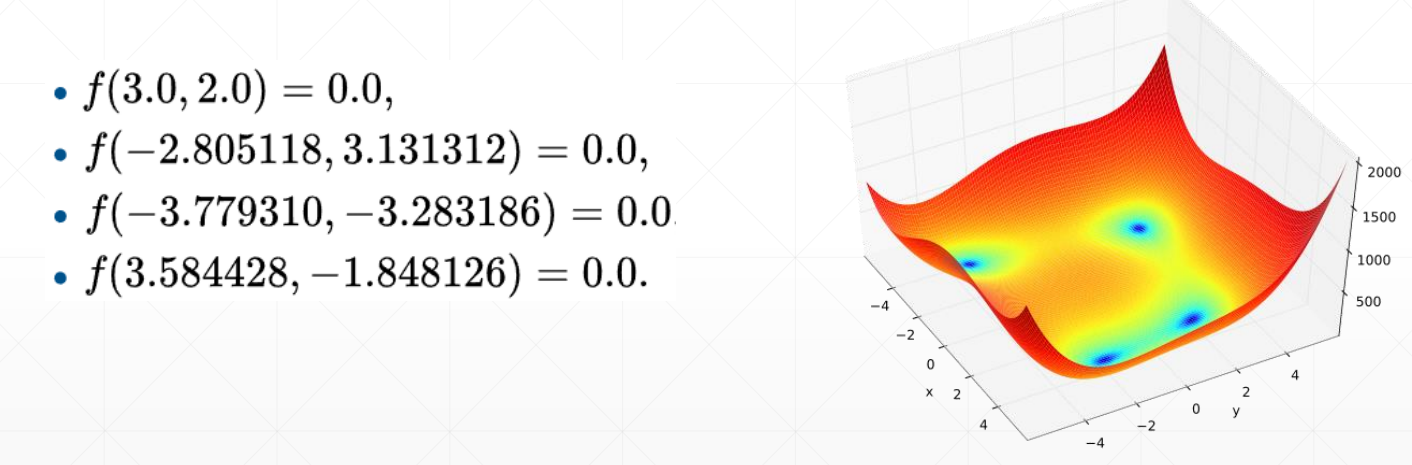
在pycharm中画出图像
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import pyplot as plt
import torch
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
x = np.arange(-6, 6, 0.1)
y = np.arange(-6, 6, 0.1)
print('x,y range:', x.shape, y.shape)
X, Y = np.meshgrid(x, y)
print('X,Y maps:', X.shape, Y.shape)
Z = himmelblau([X, Y])
fig = plt.figure('himmelblau')
ax = fig.gca(projection='3d')
ax.plot_surface(X, Y, Z)
ax.view_init(60, -30)
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
np.meshgrid(x, y) 把 xy 组合起来,然后再传给 ax.plot_surface(X, Y, Z)
# [1., 0.], [-4, 0.], [4, 0.]
x = torch.tensor([1., 0.], requires_grad=True)
optimizer = torch.optim.Adam([x], lr=1e-3)
for step in range(20000):
pred = himmelblau(x)
optimizer.zero_grad()
pred.backward()
optimizer.step()
if step % 2000 == 0:
print ('step {}: x = {}, f(x) = {}'
.format(step, x.tolist(), pred.item()))
梯度下降法求局部最小值,x 就是一个点,每次 optimizer.step() 调用都会进行一次梯度下降
交叉熵
Cross Entropy Loss
熵的概念
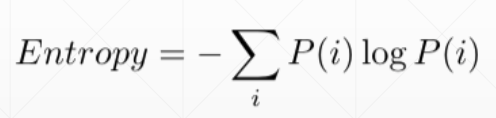
概率分布差异越大熵值越小,如下所示

交叉熵
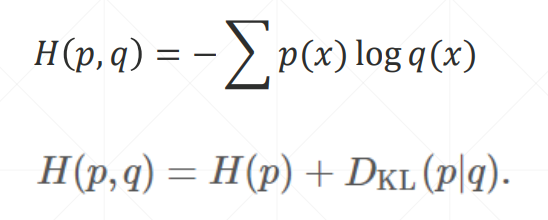
DKL 代表p、q的近似程度,当p、q一样时,其值为0
而对于 one-hot 规则产生的熵始终为 0,所以其交叉熵就可以代表预测值与真实值的 loss
对于二分类问题其形式如下
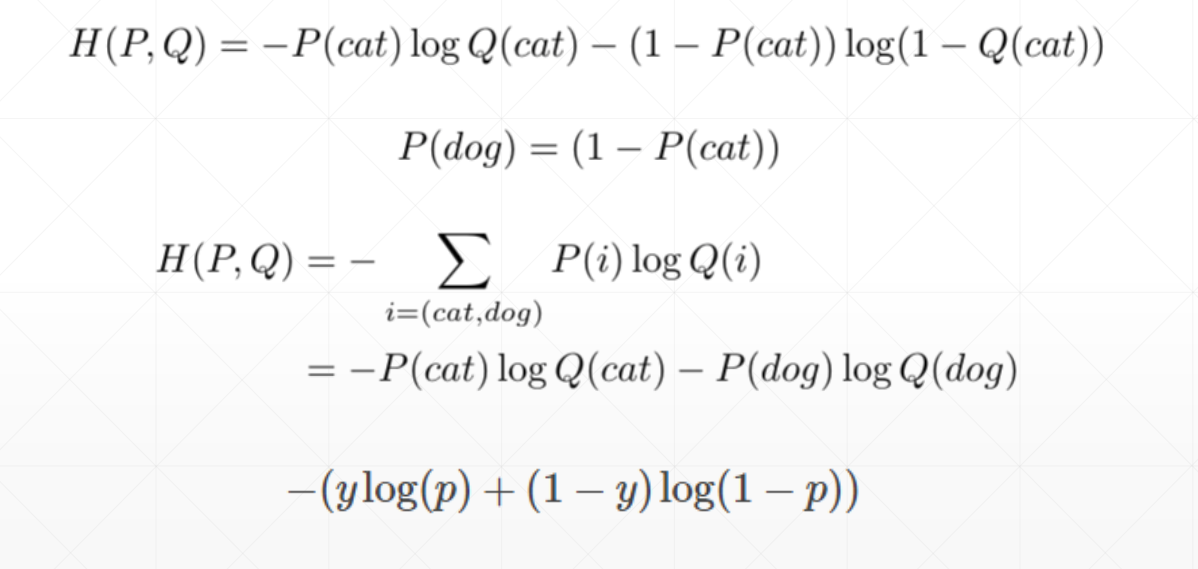
多分类问题演示
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
# 导入数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 创建参数
w1, b1 = torch.randn(200, 784, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w2, b2 = torch.randn(200, 200, requires_grad=True),\
torch.zeros(200, requires_grad=True)
w3, b3 = torch.randn(10, 200, requires_grad=True),\
torch.zeros(10, requires_grad=True)
# 初始化参数
torch.nn.init.kaiming_normal_(w1)
torch.nn.init.kaiming_normal_(w2)
torch.nn.init.kaiming_normal_(w3)
# 构造网络结构,三层线性
def forward(x):
x = x@w1.t() + b1
x = F.relu(x)
x = x@w2.t() + b2
x = F.relu(x)
x = x@w3.t() + b3
x = F.relu(x)
return x
# 定义优化器
optimizer = optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate)
# 计算交叉熵
criteon = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
logits = forward(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
logits = forward(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
GPU加速

测试
Accuracy的计算
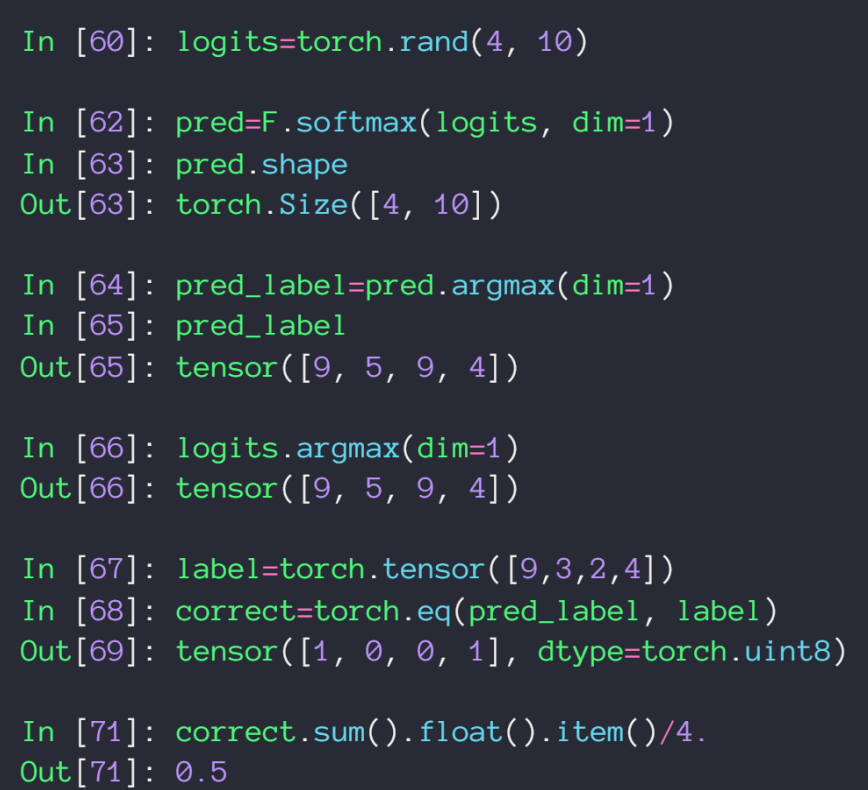
先通过 eq() 来获得一个 01 tensor,再对该tensor求和除以数量即可
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
可视化Visdom
下载地址:GitHub - fossasia/visdom: A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy.
解压后,cmd窗口进入 visdom-master 目录,命令 pip install -e . 完成安装
启动服务:python -m visdom.server
用法:
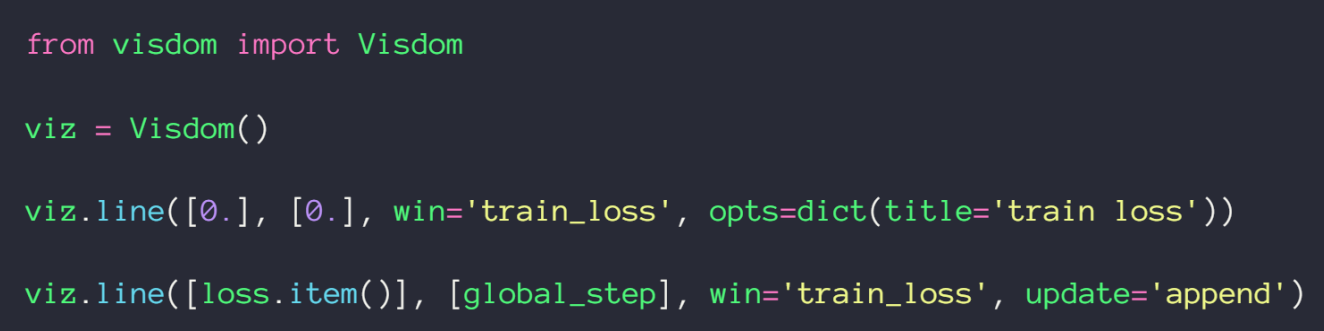
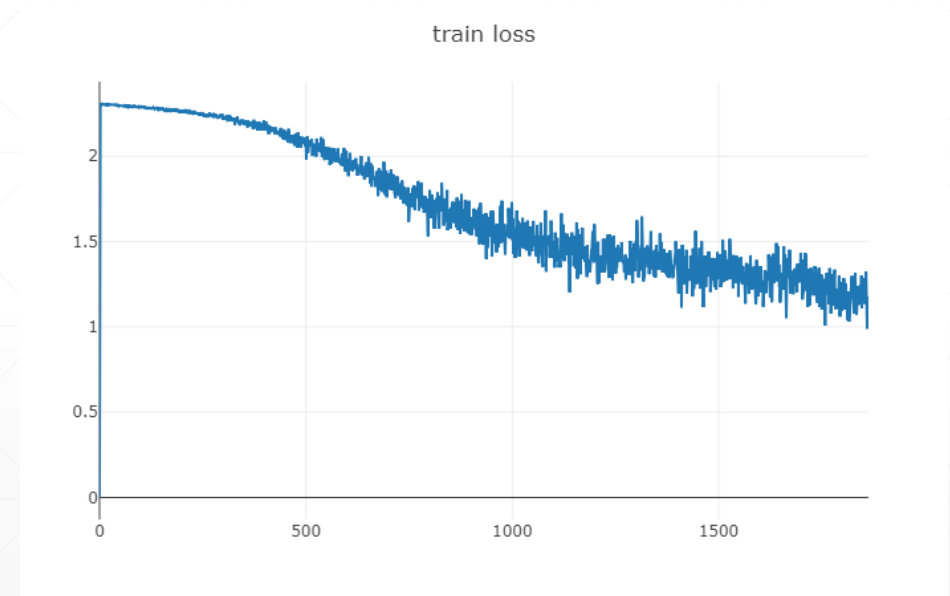
单条曲线
先初始化,win 代表 id, opts 包含一系列名称等参数,然后再传入数据画图
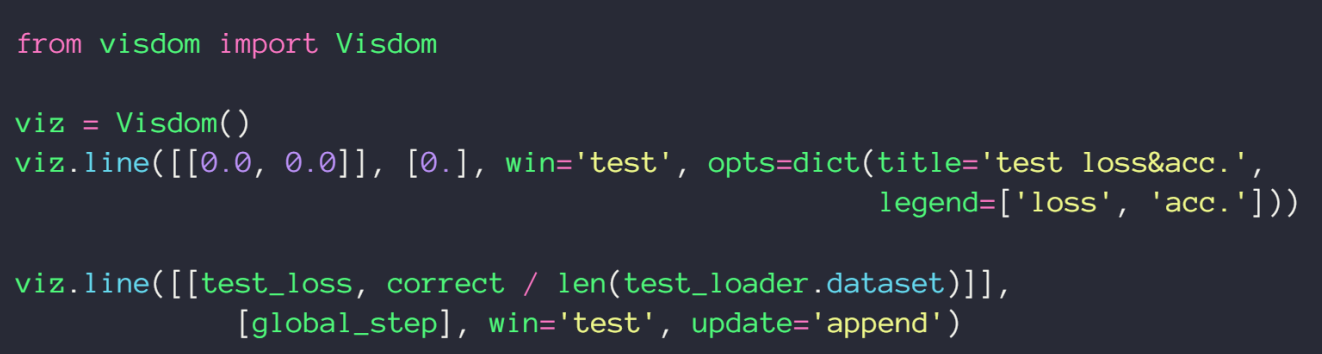
双线模型
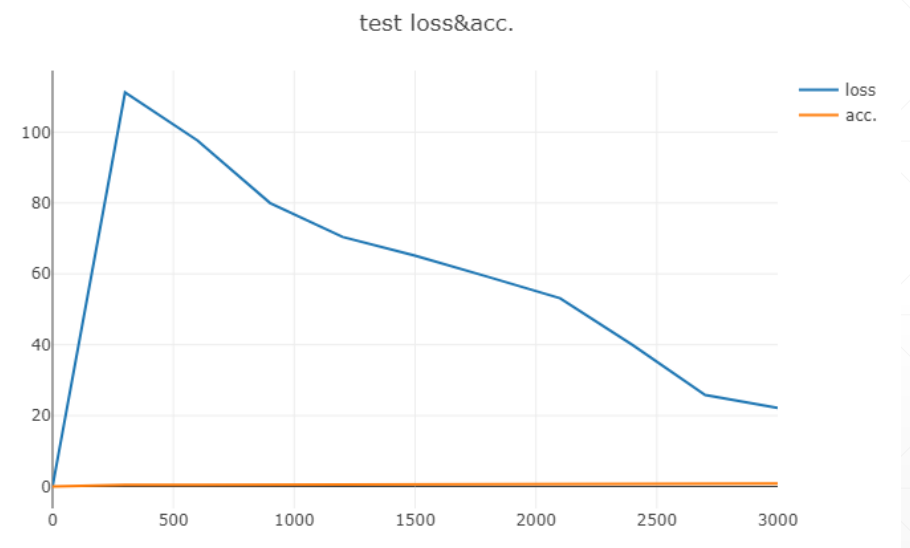
显示图片

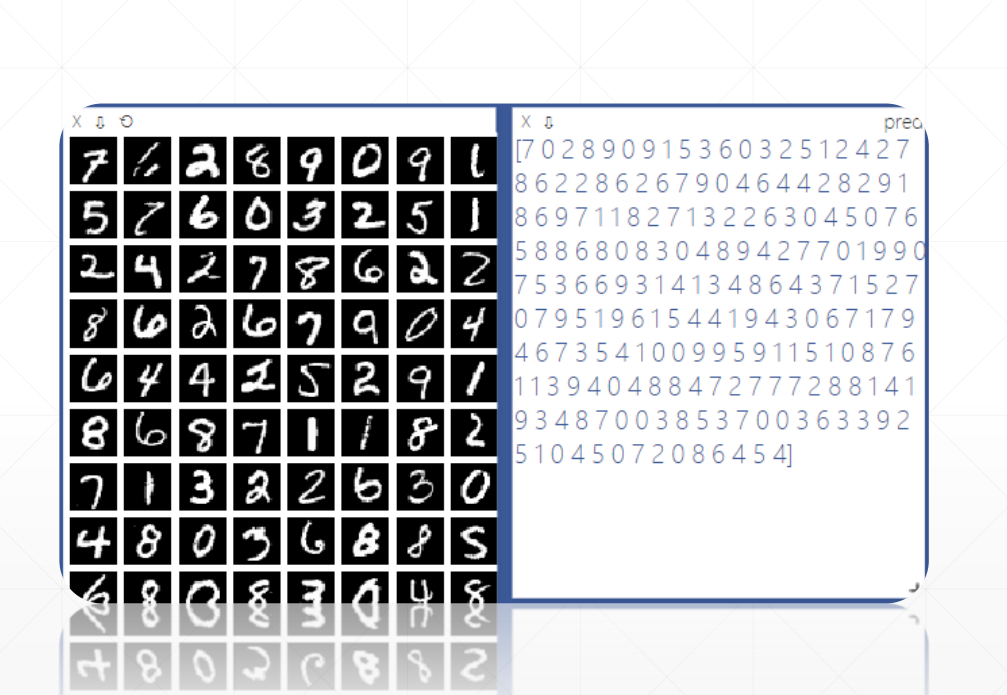
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
过拟合与欠拟合
过拟合:模型的复杂度大于实际需求
欠拟合:模型的复杂度小于实际需求
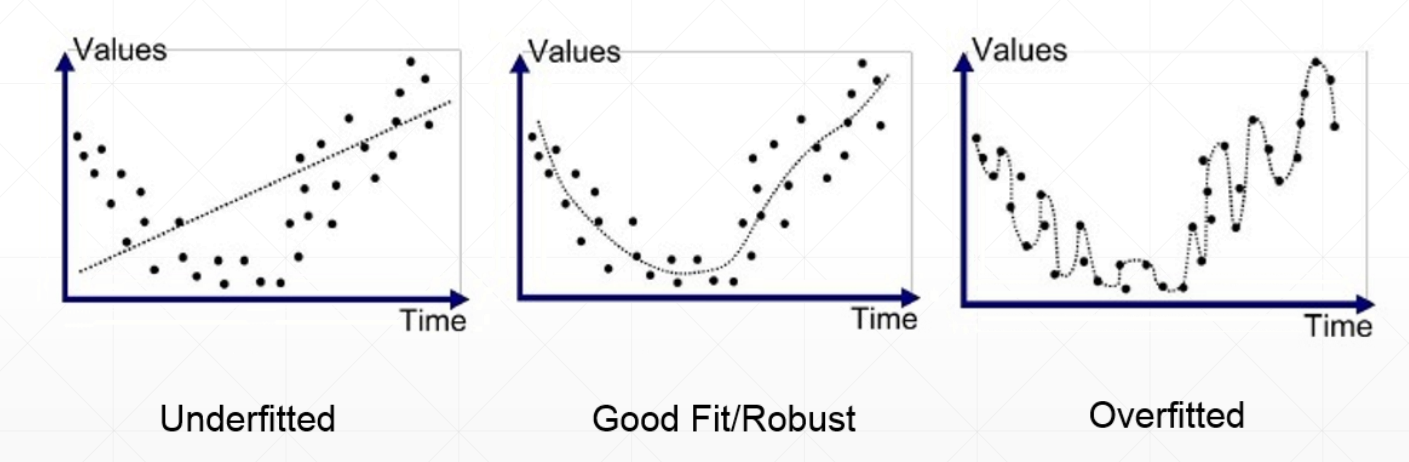
交叉验证
Train-Val-Test划分,目的是减小过拟合的可能
将数据集划分为三个部分,Train部分进行训练,在训练的过程中用 Val 部分进行测试,记录 Accuracy,最后回头取Accuracy最高时的训练数据;Test 部分完全隔离于前两部分,作为第三方验证模型训练的效果
实现数据分类
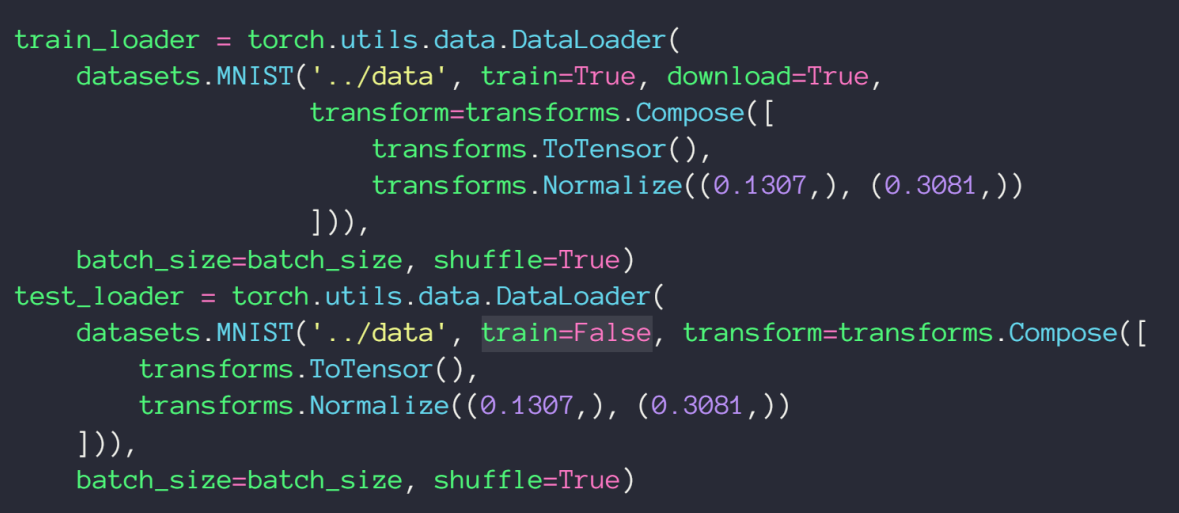
torch.utils.data.DataLoader主要是对数据进行batch的划分,train参数为 True 时就是划分出 Train + Val 部分的数据,为 False 则时 Test 部分,然后再划分 Train 和 Val

torch.utils.data.random_split 划分数据
对于 Train + Val 部分的数据还可以有 K-fold cross-validation 操作,即每次训练都随机再重新划分两部分数据
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_db = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
test_db = datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(test_db,
batch_size=batch_size, shuffle=True)
print('train:', len(train_db), 'test:', len(test_db))
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in val_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(val_loader.dataset)
print('\nVAL set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
Regularization
对于 Loss 函数再加上参数的范数作为新的 Loss 去求最小值,这样在原 Loss 极小的同时,参数(W,b)也会很小
就像是对于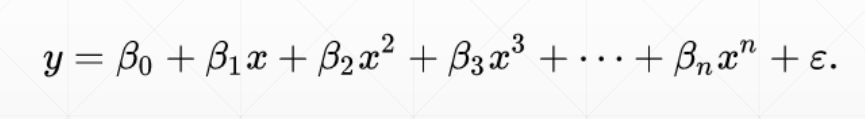 ,显然 β 越小,曲线 y 越平稳,正好抵消过拟合曲线上上下下的形状
,显然 β 越小,曲线 y 越平稳,正好抵消过拟合曲线上上下下的形状
不是直接加上,还要乘以一个系数用以抵消前后的量级的不同

PyTorch有 L2范数 的api

其中weight_decay 参数就是上文的范数的系数
手动实现 L1范数

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.01)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
动量
Momentum
在原来按梯度下降的基础上增加一个前量,相当于前一步的梯度仍存在“惯性”,使得参数变化的方向和量不完全取绝于当前梯度,还与上一个点的梯度有关
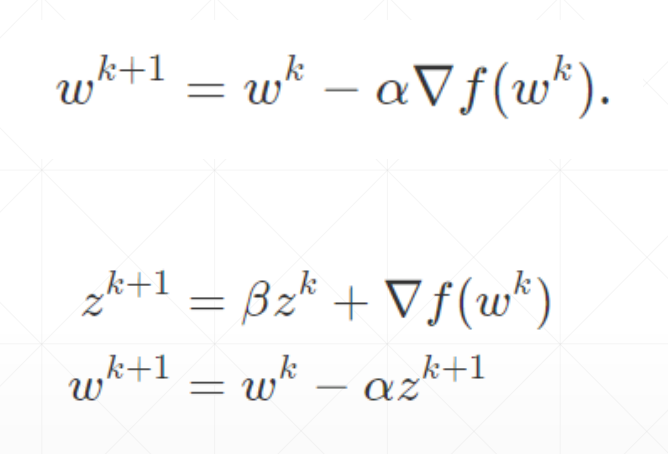
直观效果如下
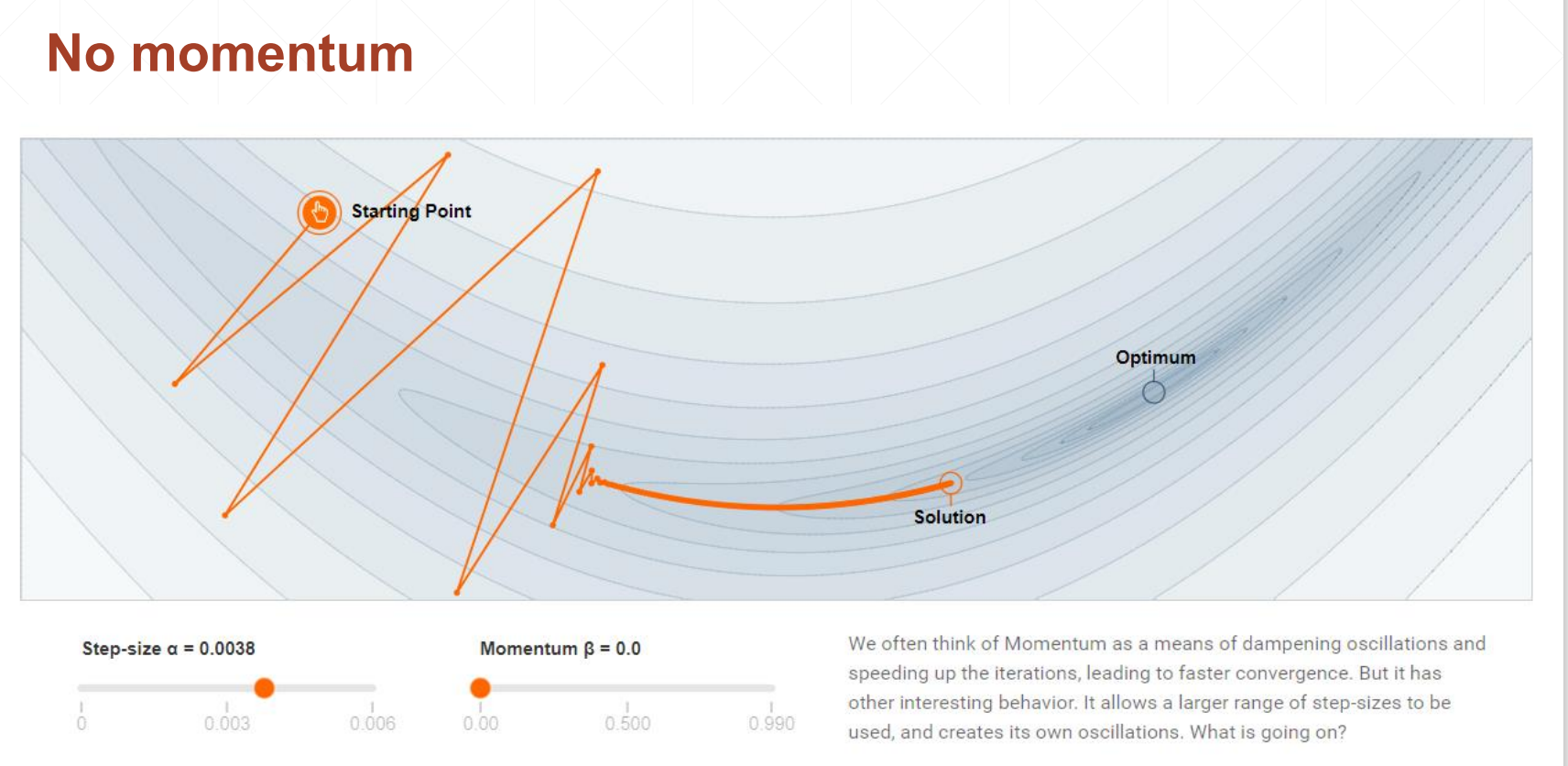
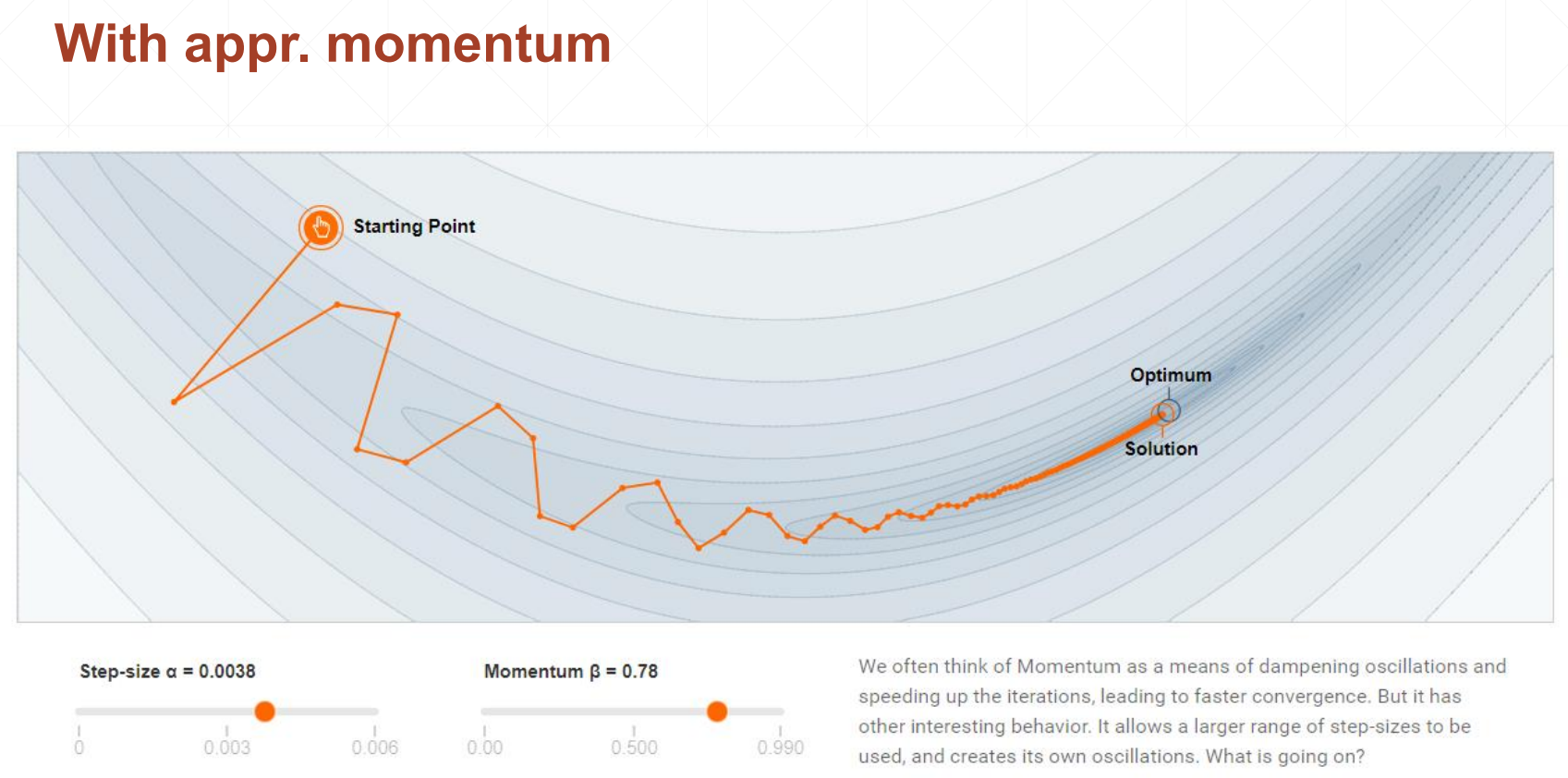
学习率衰减
顾名思义,当下降到接近极小值位置时比原来更小的学习率可以使得下降速度变慢,更容易取到极小值
代码实现

在 SGD 中添加参数即可,包含了动量计算时β的参数 momentum,和学习率衰减阈值的参数 weight_decay,当loss低于该值时,学习率减半
下面是,当以训练一定量的数据后学习率减半的设置
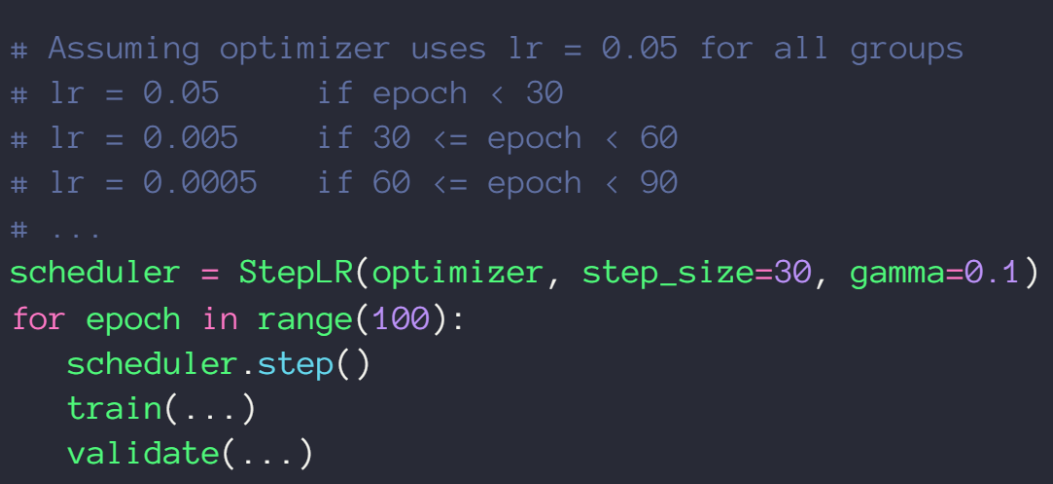
Early Stopping
就是交叉验证时获得较好的结果时提前结束训练
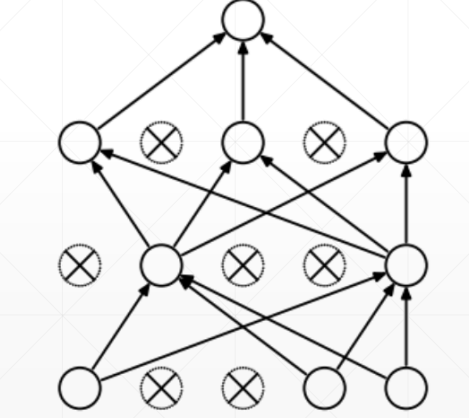
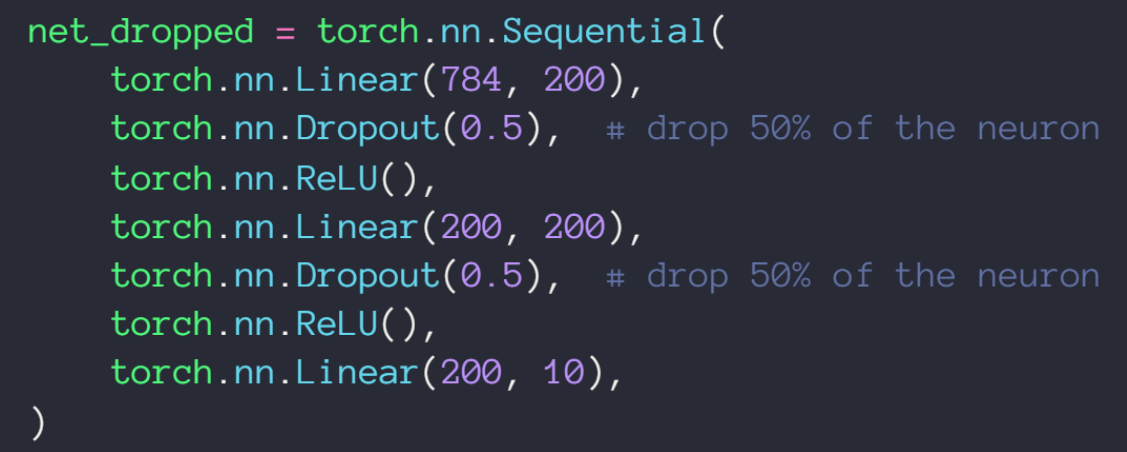
Dropout
每次训练时对于每层神经元,随机的选择部分参与训练,其余闲置,通过多次训练达到 Learning less to learn better 的效果
代码实现
使用 eval() 使得测试时不遵循 dropout 方式

卷积神经网络
Convolutional Neural Network 主要是用于对于图片的处理
卷积
线性模型的弊端,当深度与节点数增加时,总的变量的数量将变得很大,计算机内存无法一次性读入这么多的数据
感受野,模仿人类视觉,以扫描的方式遍历整张图片
卷积操作
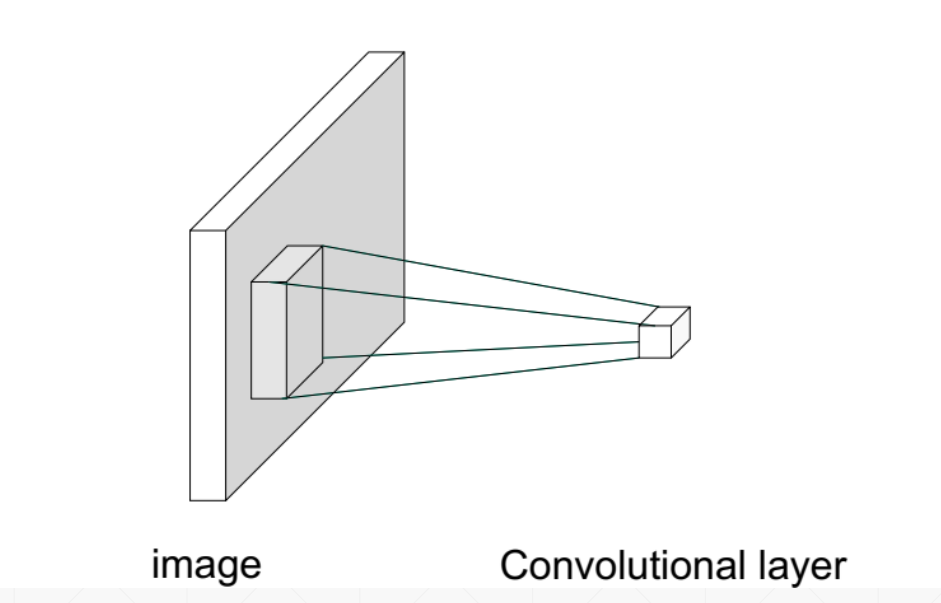
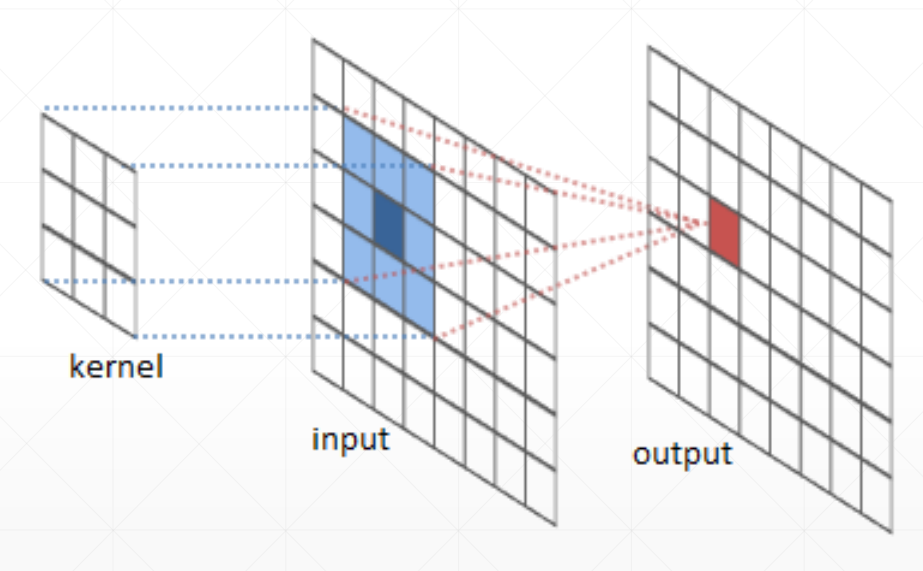
用一个小矩阵盖住图片矩阵,计算重叠部分的卷积和(两矩阵对应相乘后求和),以一定步长遍历整个大矩阵后就可以得到一个新的矩阵
其中小矩阵称为卷积核kernel
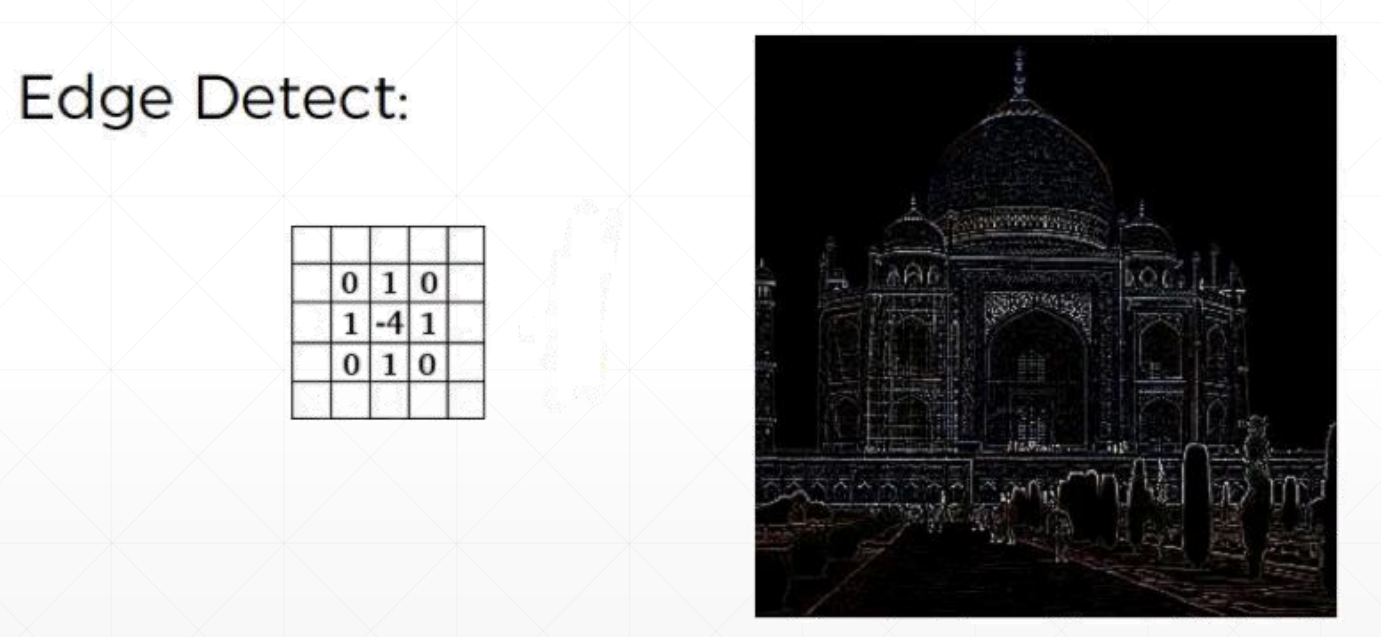
kernel的组成不同会导致对于图片的处理有不同的效果,例如


卷积过程中有如下参数:
- Input_channels,输入通道数,例对于彩色图片,每张图片有三层,单个通道
- Kernel_channels,kernel的数量,选择对每一个输入使用的kernel的数量,上面就列举了三种不同的kernel,其数量决定了输出的数量
- Kernel_size,小矩阵的大小
- Stride,步长
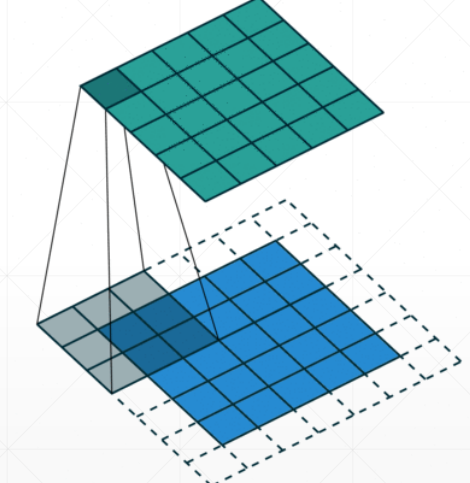
- Padding,边缘填充的数量,看下图就理解了
对于每一个 kernel 其包含的小矩阵的数量与 Input_channels 相同,不止一个

上图,展示了输入有 3 个 channel,对应每个 kernel 也有三个map,总共有 2 个 kernel,输出 2 个矩阵
对于输出的元素是每个 kernel 的三个小矩阵卷积后再求和的结果
代码实现
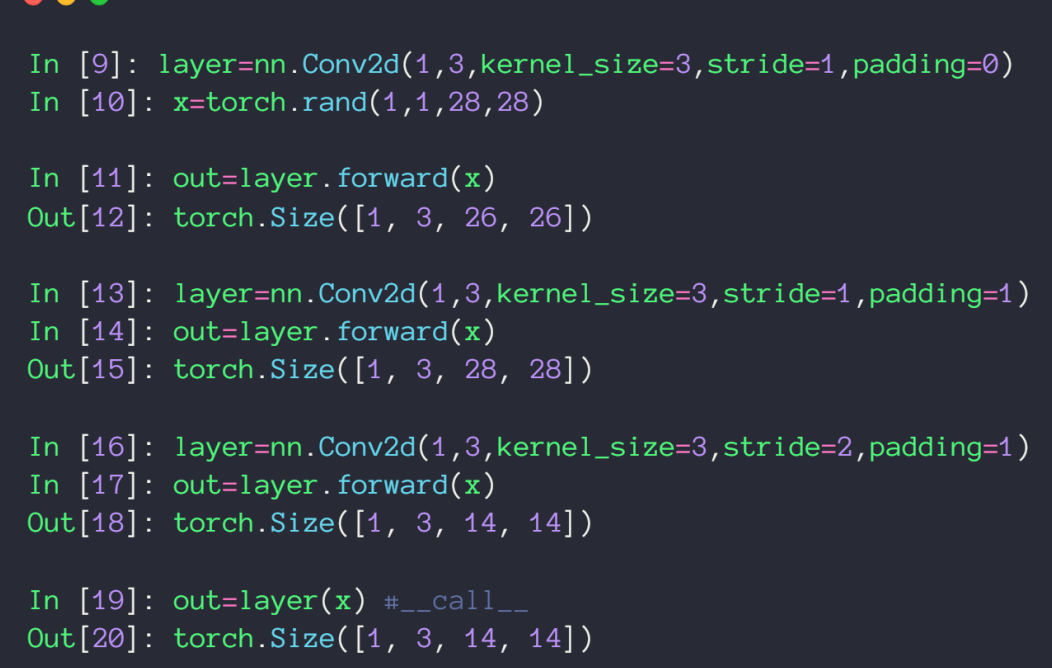
nn.Conv2d(),第一个参数为输入通道数,第二个参数为 kernel 数量
建议使用 later(x) 的方式之间实现卷积操作
kernel的一些参数
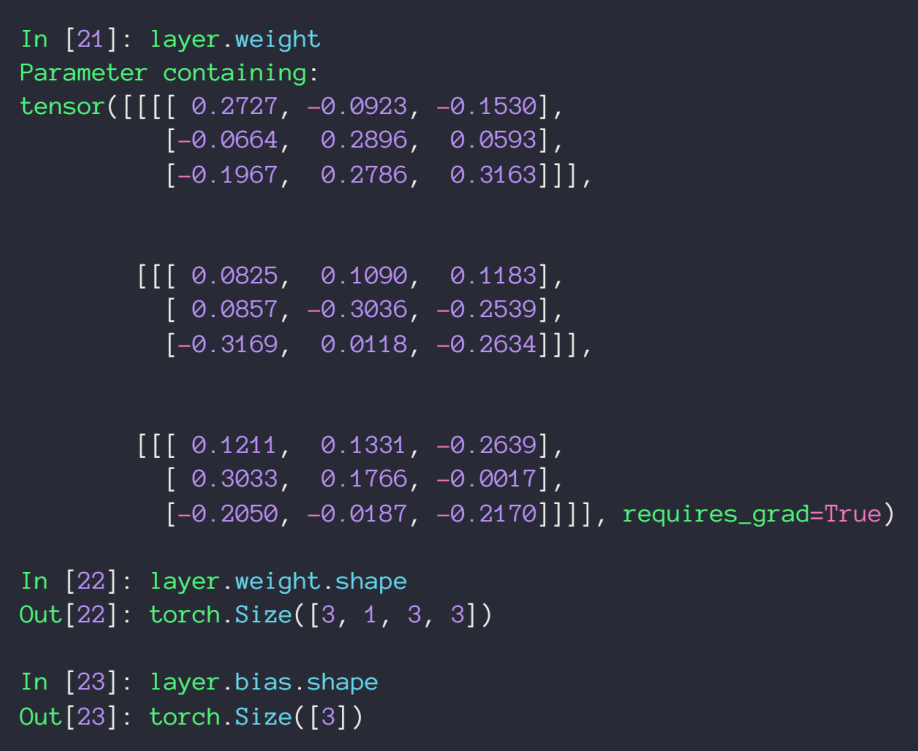
函数式的卷积计算
池化技术
Max pooling
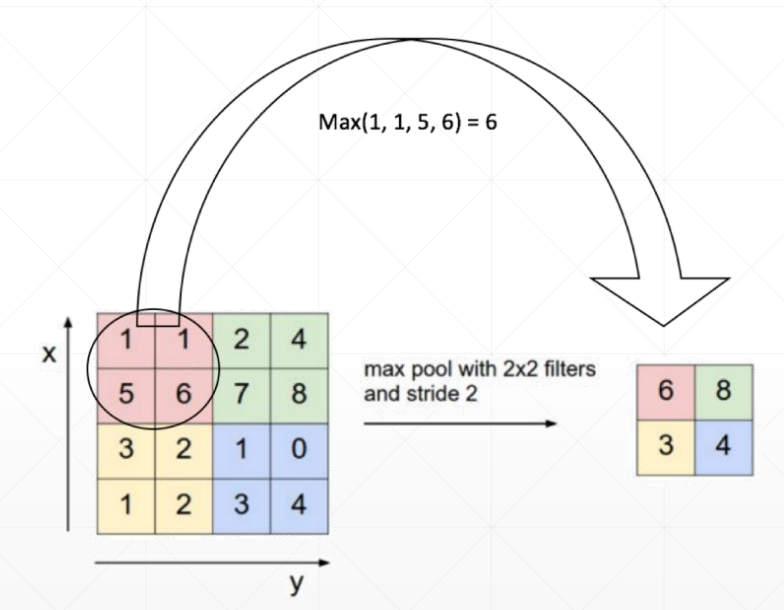
显而易见最大池化取一定区域的最大值作为特征值提出,实现原数据规模减小(reduce size)的目的
Avg pooling
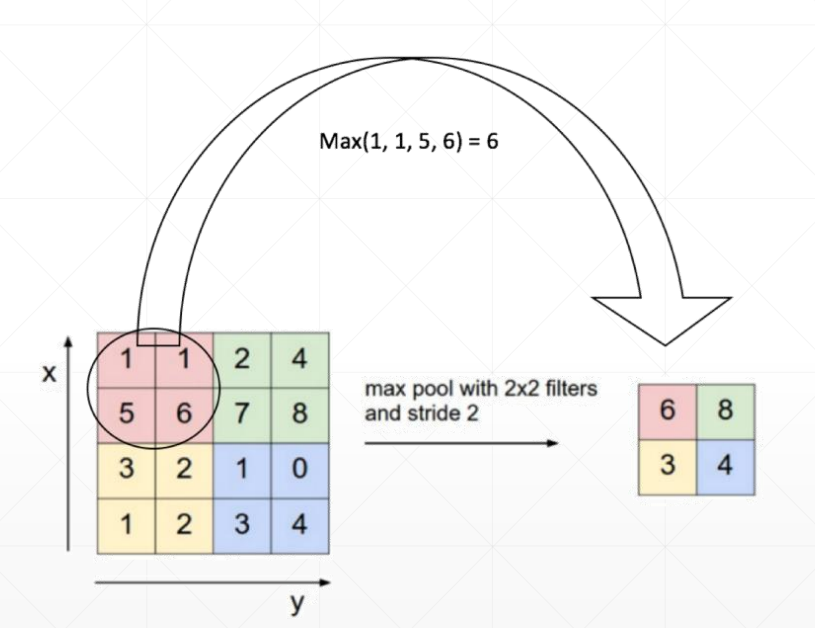
平均池化
代码实现方式

upsample
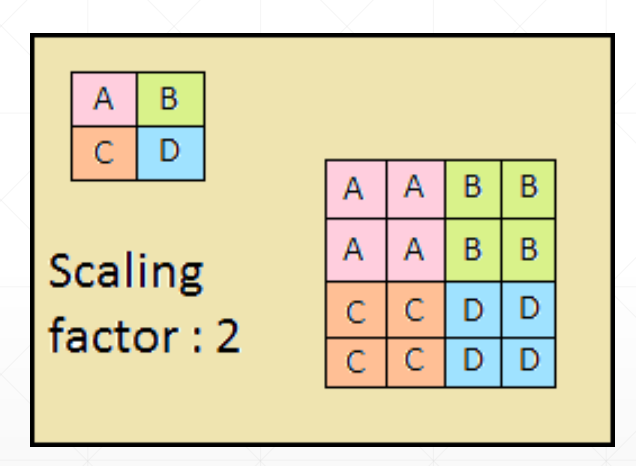
向上采样,作为增加数据大小的一种方式
代码实现

ReLU
ReLU采样


Batch Norm
其目的是为了将原来没有取值限制的数据缩拢到一定范围内,相当于归一化操作
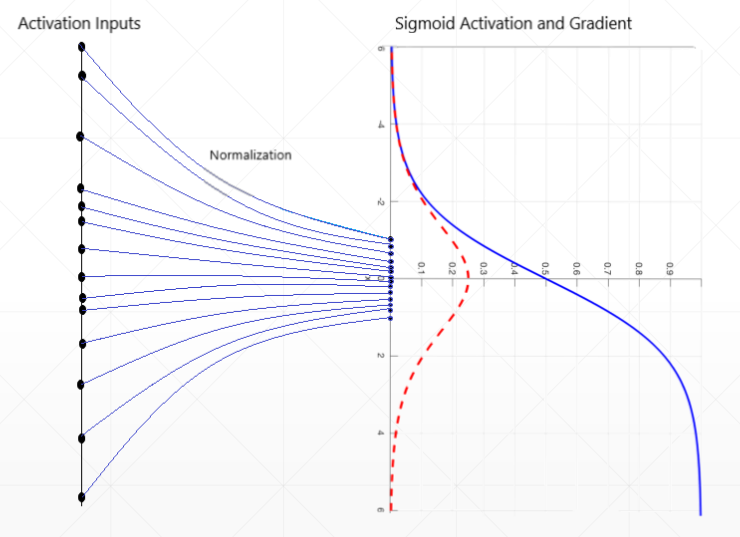
有很多种 Norm,Batch Norm 指的是将一个通道(对于彩色图片的三个通道就分成三个batch)的所有数据标准化

其中 C 为通道数,N 为图片数,HW 为压缩成一维的图片像素
计算过程如下
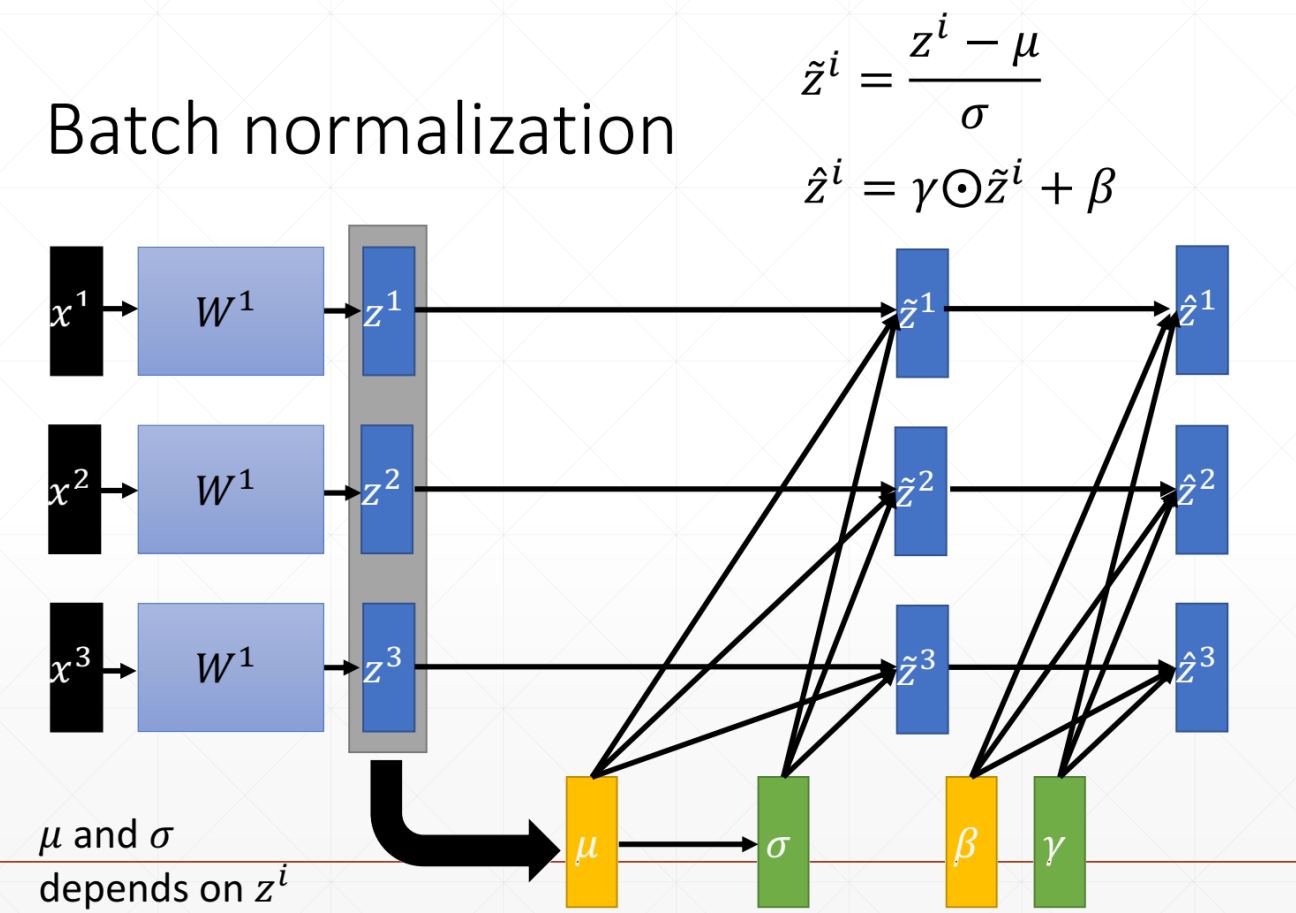
先计算均值和方差,用它们标准化原数据,使其变成标准正态分布,再添加想要的参数使其变成N(γ,β)
代码实现

nn.Module
nn.Module是所有神经网络模块的父类,例如 nn.Linear,nn.BatchNorm2d 等等
-
拥有 Linear,ReLU,Conv2d 等多个模块
-
拥有 Sequential 容器可以快速构建网络而不用写传递参数的代码

-
统一管理变量,拥有参数 parameters 可以获得网络中所有的参数变量, named_parameters 可以额外获得变量名称
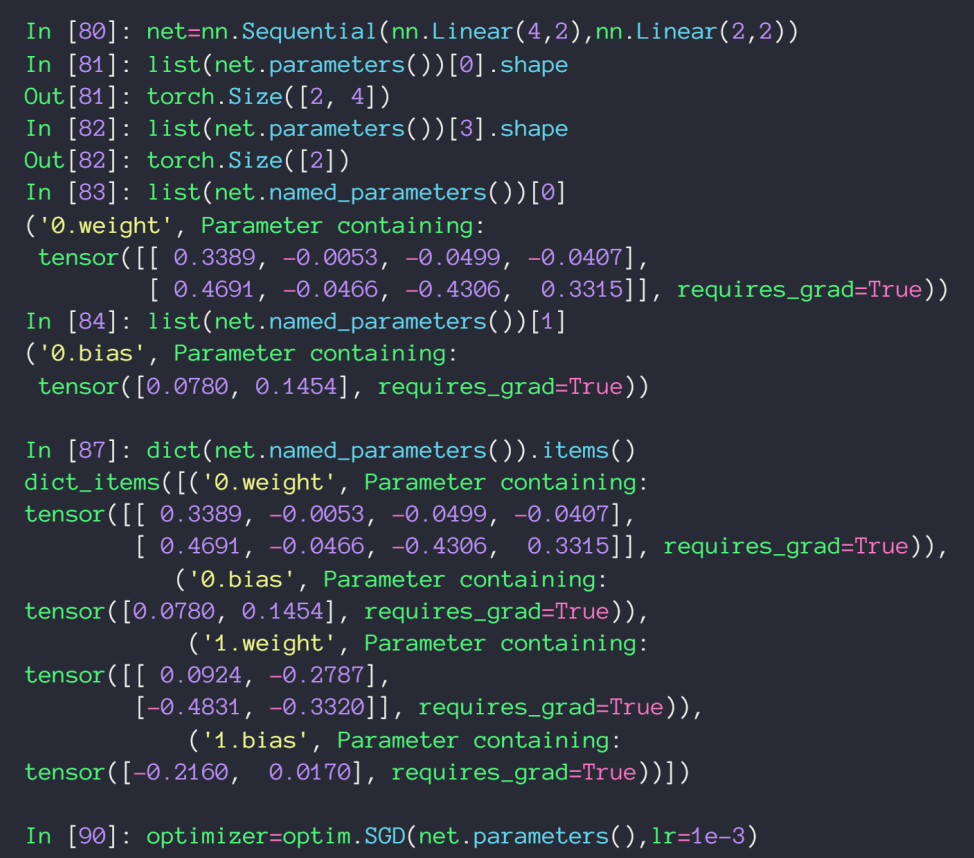
-
所有的网络层都是在以 nn.Module 为根节点的树上建立的

-
快速地将所有参数转化成 GPU 的模式

-
保存训练状态,避免一些意外情况导致训练被迫中止

-
train 和 test 模式快速转换

-
实现自己的层,下面就实现了一个 tensor 数据横向铺开的功能
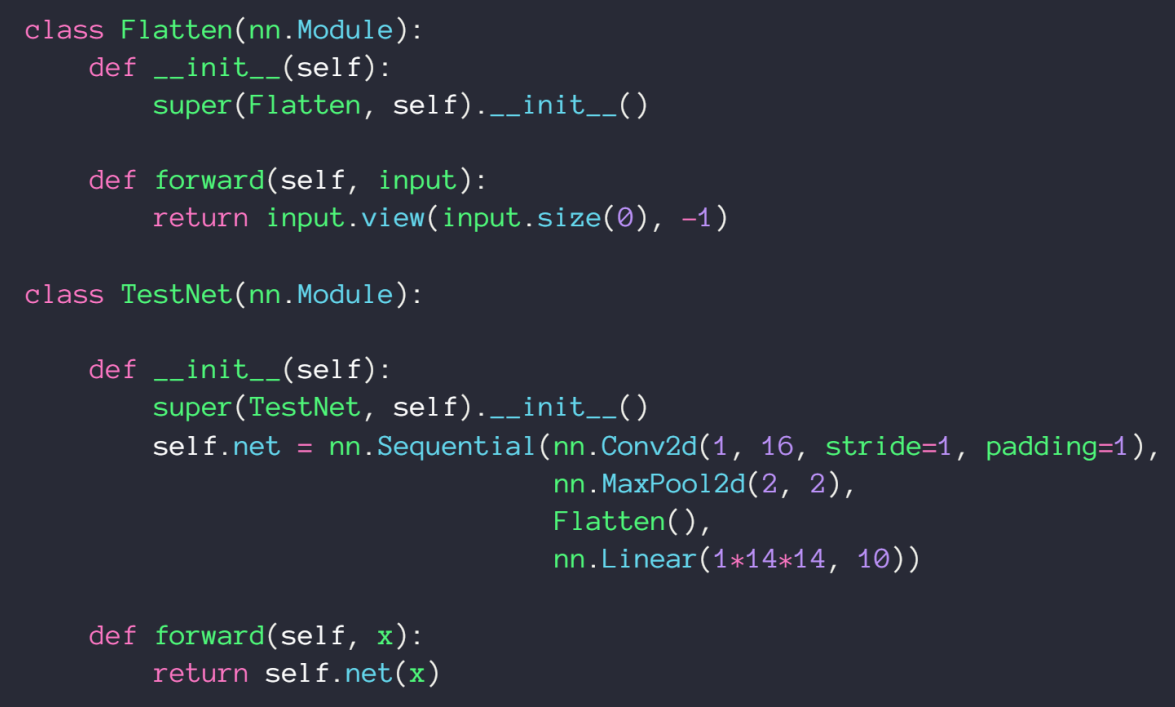
-
实现一个Linear层,nn.Parameter 会把 tensor 加入 parameter 中统一管理,并且 requires_grad 参数设为 True,注意大写 P ,小写 p 是获得所有参数的方法

数据增强
主要是针对图片数据
对称变换

RandomHorizontalFlip,RandomVerticalFlip 对数据随机作水平或者垂直变换
旋转变换
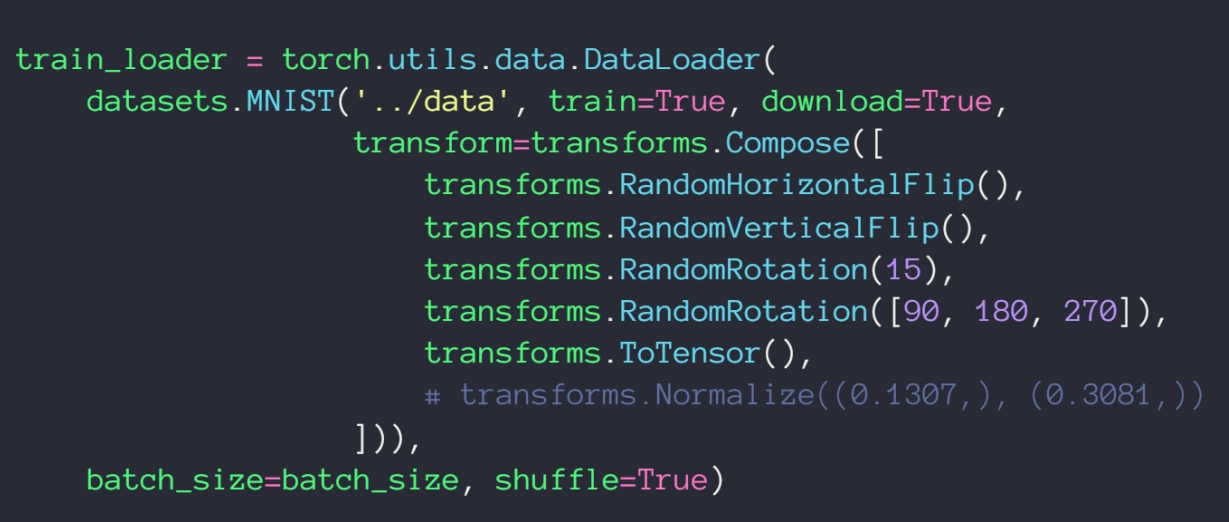
RandomRotation 随机旋转操作,单参数为标量 x 时,随机旋转 -x ~ x 度;单参数为 list 时,随机选择 list 中的数据作为旋转角度
放大缩小

Resize 改变图片大小
随机截图

RandomCrop 随机截取设定大小的图片
卷积神经网络实战
数据集
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
def main():
batchsz = 128
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
if __name__ == '__main__':
main()
pytorch 提供了数据集的下载方式
参数1:下载后的数据保存的文件夹名
参数2:是否为训练集
参数3:需要作哪些数据增强操作
参数4:是否自动下载
上面只是一张张图片加载,下面实现并行加载图片
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
参数1:数据读取设置
参数2:每一个batch的大小
参数3:是否选择随机采样
同样的再建立 test 数据集
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
lenet5
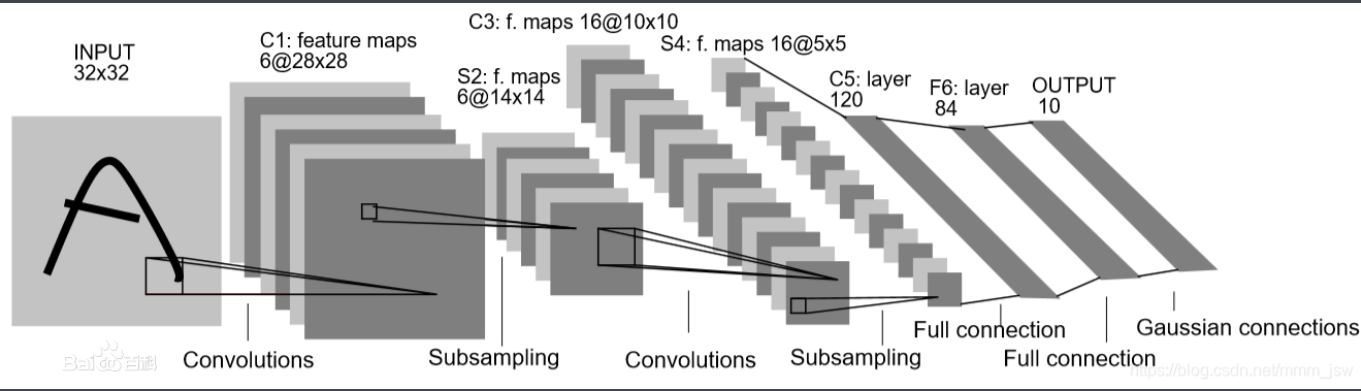
定义类,构造网络
前四层
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
"""
for cifar10 dataset.
"""
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 16, ]
nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#
)
其中 Conv2d 的参数1为输入的通道数,参数2为输出的通道数
然后构造第五层,全连接层,首先要直到经过前四层变换后其通道数为多少
在 init 中添加对前四层的测试,然后编写主函数调用
# [b, 3, 32, 32]
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
# [b, 16, 5, 5]
print('conv out:', out.shape)
def main():
net = Lenet5()
tmp = torch.randn(2, 3, 32, 32)
out = net(tmp)
print('lenet out:', out.shape)
if __name__ == '__main__':
main()

得到通道数后,编写全连接层的代码
self.fc_unit = nn.Sequential(
nn.Linear(32*5*5, 32),
nn.ReLU(),
# nn.Linear(120, 84),
# nn.ReLU(),
nn.Linear(32, 10)
)
编写 forward 方法,来运行构建的网络
def forward(self, x):
"""
:param x: [b, 3, 32, 32]
:return:
"""
batchsz = x.size(0)
# [b, 3, 32, 32] => [b, 16, 5, 5]
x = self.conv_unit(x)
# [b, 16, 5, 5] => [b, 16*5*5]
x = x.view(batchsz, 32*5*5)
# [b, 16*5*5] => [b, 10]
logits = self.fc_unit(x)
return logits
在main中调用定义的网络并完成训练和测试
device = torch.device('cuda')
# 将网络加载到GPU
model = Lenet5().to(device)
# model = ResNet18().to(device)
# 计算交叉熵
criteon = nn.CrossEntropyLoss().to(device)
# 构造参数优化器对象,设置参数和学习率
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
# 转为训练模式
model.train()
# enumerate 在for循环中得到计数
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
# 将数据加载到GPU
x, label = x.to(device), label.to(device)
# 将数据输入模型,得到结果
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
# 计算预测值和实际值的交叉熵
loss = criteon(logits, label)
# backprop 计算梯度,并优化参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
# 转为测试模式
model.eval()
# 声明不需要计算梯度
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
# 作eq运算会得到一个大小和每个batch一样大小的tensor,该tensor中有几个1就是对了几个所以作sum运算
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
完整代码
main
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch import nn, optim
from lenet5 import Lenet5
from resnet import ResNet18
def main():
batchsz = 128
cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_train = DataLoader(cifar_train, batch_size=batchsz, shuffle=True)
cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True)
cifar_test = DataLoader(cifar_test, batch_size=batchsz, shuffle=True)
# x, label = iter(cifar_train).next()
x, label = next(iter(cifar_train))
print('x:', x.shape, 'label:', label.shape)
device = torch.device('cuda')
model = Lenet5().to(device)
# model = ResNet18().to(device)
criteon = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
for epoch in range(1000):
model.train()
for batchidx, (x, label) in enumerate(cifar_train):
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
logits = model(x)
# logits: [b, 10]
# label: [b]
# loss: tensor scalar
loss = criteon(logits, label)
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss:', loss.item())
model.eval()
with torch.no_grad():
# test
total_correct = 0
total_num = 0
for x, label in cifar_test:
# [b, 3, 32, 32]
# [b]
x, label = x.to(device), label.to(device)
# [b, 10]
logits = model(x)
# [b]
pred = logits.argmax(dim=1)
# [b] vs [b] => scalar tensor
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
# print(correct)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
if __name__ == '__main__':
main()
lenet5代码
import torch
from torch import nn
from torch.nn import functional as F
class Lenet5(nn.Module):
"""
for cifar10 dataset.
"""
def __init__(self):
super(Lenet5, self).__init__()
self.conv_unit = nn.Sequential(
# x: [b, 3, 32, 32] => [b, 16, ]
nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=0),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
#
)
# flatten
# fc unit
self.fc_unit = nn.Sequential(
nn.Linear(32*5*5, 32),
nn.ReLU(),
# nn.Linear(120, 84),
# nn.ReLU(),
nn.Linear(32, 10)
)
# [b, 3, 32, 32]
tmp = torch.randn(2, 3, 32, 32)
out = self.conv_unit(tmp)
# [b, 16, 5, 5]
print('conv out:', out.shape)
# # use Cross Entropy Loss
# self.criteon = nn.CrossEntropyLoss()
def forward(self, x):
"""
:param x: [b, 3, 32, 32]
:return:
"""
batchsz = x.size(0)
# [b, 3, 32, 32] => [b, 16, 5, 5]
x = self.conv_unit(x)
# [b, 16, 5, 5] => [b, 16*5*5]
x = x.view(batchsz, 32*5*5)
# [b, 16*5*5] => [b, 10]
logits = self.fc_unit(x)
# # [b, 10]
# pred = F.softmax(logits, dim=1)
# loss = self.criteon(logits, y)
return logits
def main():
net = Lenet5()
tmp = torch.randn(2, 3, 32, 32)
out = net(tmp)
print('lenet out:', out.shape)
if __name__ == '__main__':
main()
ResNet
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
# we add stride support for resbok, which is distinct from tutorials.
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
# followed 4 blocks
# [b, 64, h, w] => [b, 128, h ,w]
self.blk1 = ResBlk(64, 128, stride=2)
# [b, 128, h, w] => [b, 256, h, w]
self.blk2 = ResBlk(128, 256, stride=2)
# # [b, 256, h, w] => [b, 512, h, w]
self.blk3 = ResBlk(256, 512, stride=2)
# # [b, 512, h, w] => [b, 1024, h, w]
self.blk4 = ResBlk(512, 512, stride=2)
self.outlayer = nn.Linear(512*1*1, 10)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print('after conv:', x.shape) #[b, 512, 2, 2]
# [b, 512, h, w] => [b, 512, 1, 1]
x = F.adaptive_avg_pool2d(x, [1, 1])
# print('after pool:', x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128, stride=4)
tmp = torch.randn(2, 64, 32, 32)
out = blk(tmp)
print('block:', out.shape)
x = torch.randn(2, 3, 32, 32)
model = ResNet18()
out = model(x)
print('resnet:', out.shape)
if __name__ == '__main__':
main()
循环神经网络
时间序列表示
对于一张图片,可以用像素化为矩阵变成数据来分析,那么对于一段语音,文本也要提取他的特征来数字化
对于一段文字,最主要的就是将文字编码成数据的过程
-
one-hot 编码方式,有n种文字就以大小为 n 的向量来表示,太占空间了一般不用
-
基于语义相关性编码的 GloVe 方式,现成的

时间序列中的 batch
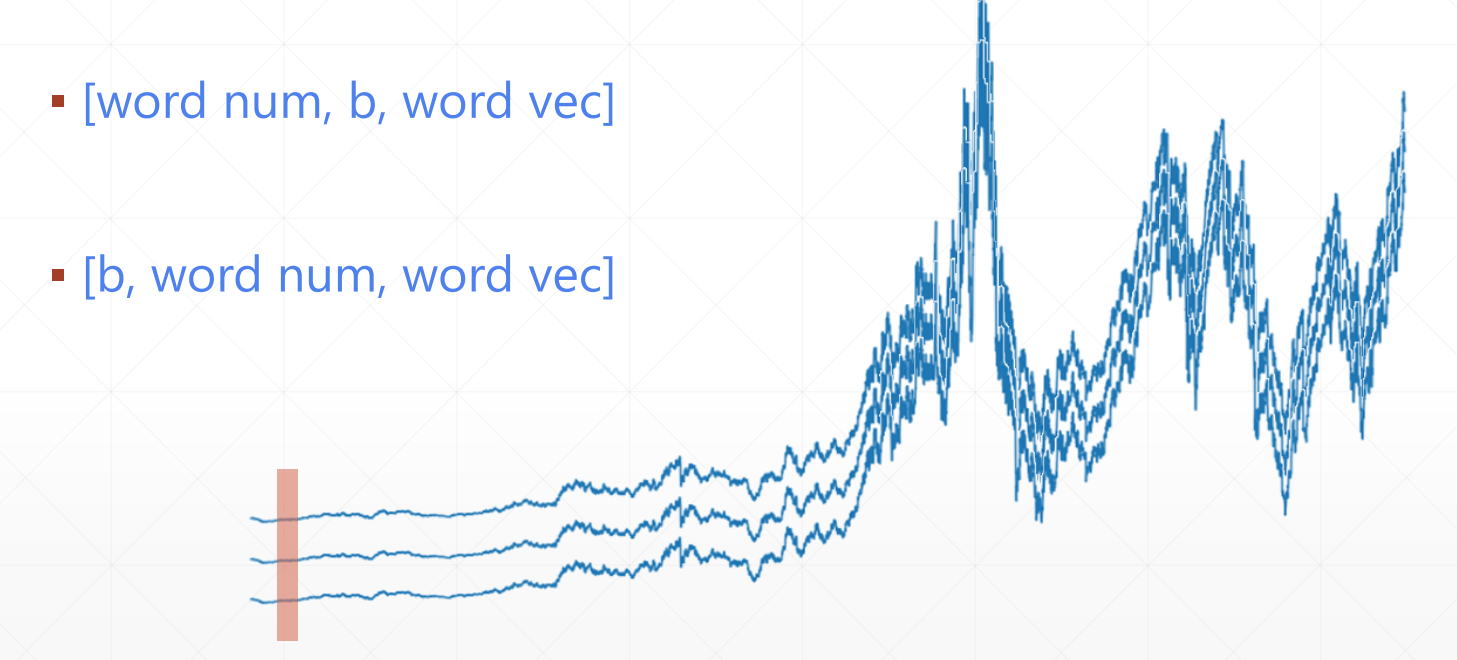
word num 单词数; b 语句数; word vec 编码方式
网络构成
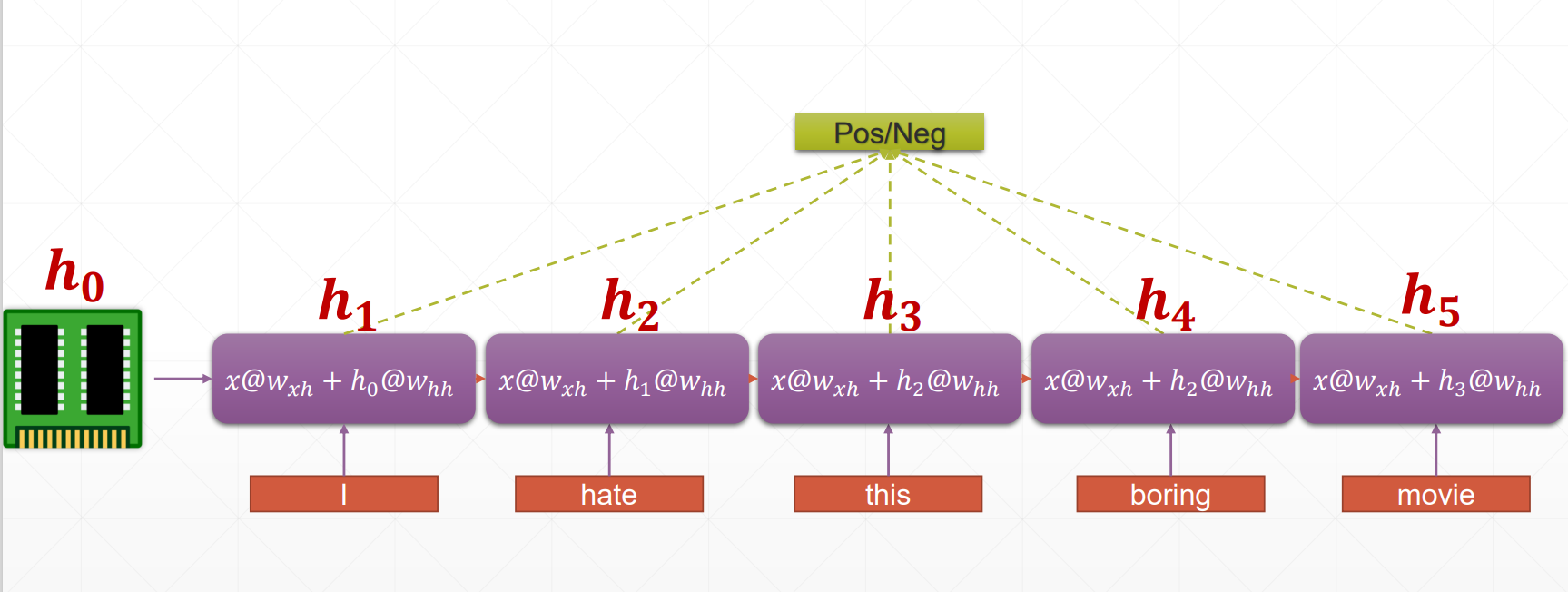
-
通过 @ 运算构成最基础的 x@w 结构
-
对于每一个单词的特征提取的权重应当是相同的,所以 w 为所有节点共享 wxh
-
考虑到它是一个完整的语句含有语境等前后关联的因素,设置 h 来作为一个记忆模块传递前面单词的影响,即前一个的输出是后一个输入的一部分
-
对于每一个点的输出可以再做整合,或者直接输出分析,这取决于训练目的
-
所谓循环就由此而来
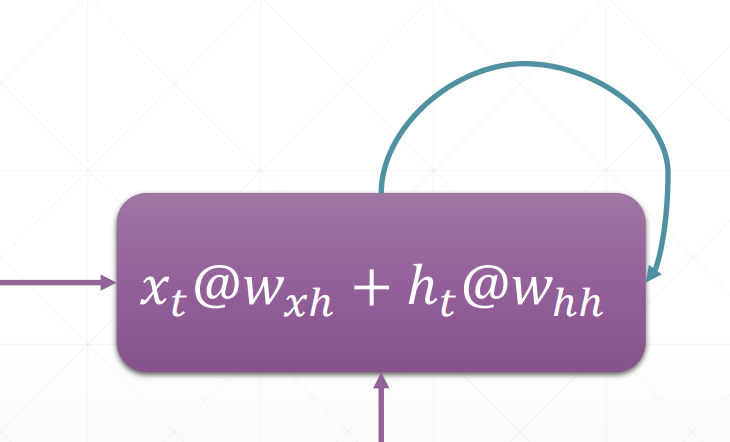
代码实现
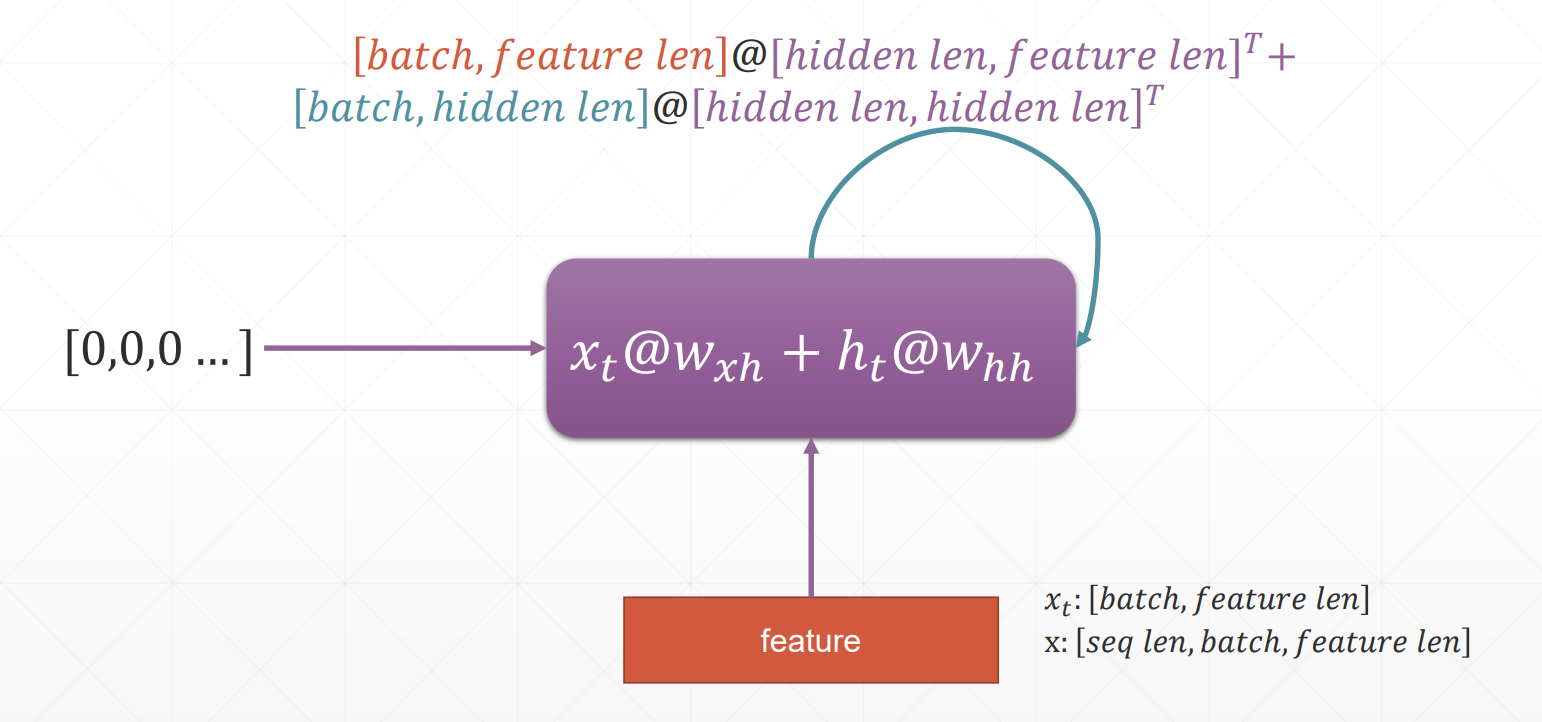
每次运算是两个卷积操作之和,其中 hidden len 是记忆参数 h 所具有的一个维度, feature len 表示表现一个单词所具有的维度size
代码实现

nn.RNN() 参数1:输入的feature len 参数2:hidden len 参数3: 网络的层数,默认1
weight_XX 就是上图的 whh、wxh
RNN的输出如下

其中 out 是每一个时刻的 h 的集合,所以他的数量和输入 x 的数量一样;ht 是每一层网络最后时刻的 h 值,他的数量和层数相同;x 就是输入, h0 是初始 h 的值

nn.RNNCell() 参数的含义和上面一样,但是他不循环,循环要自己来
实现一个两层的RNN

实现对一个函数图像的预测
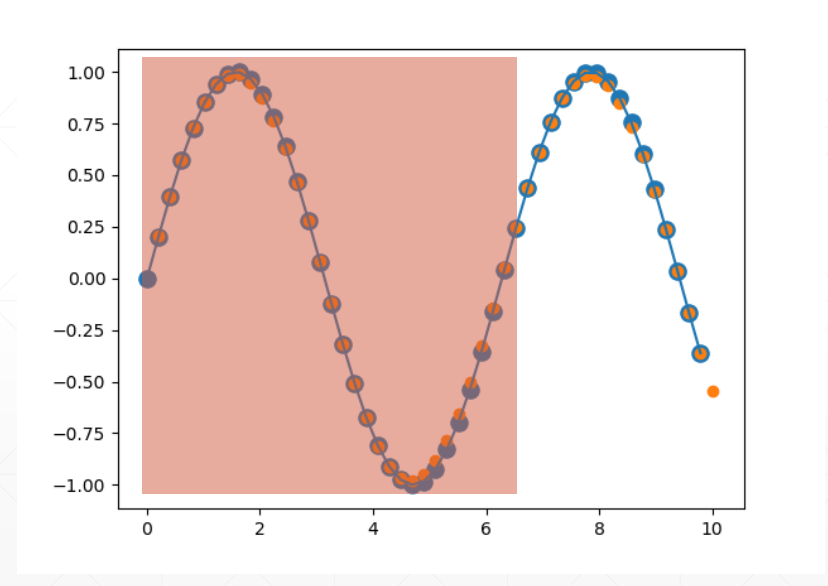
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from matplotlib import pyplot as plt
num_time_steps = 50
input_size = 1
hidden_size = 16
output_size = 1
lr=0.01
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
)
for p in self.rnn.parameters():
nn.init.normal_(p, mean=0.0, std=0.001)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev)
# [b, seq, h]
out = out.view(-1, hidden_size)
out = self.linear(out)
out = out.unsqueeze(dim=0)
return out, hidden_prev
model = Net()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr)
hidden_prev = torch.zeros(1, 1, hidden_size)
for iter in range(6000):
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
output, hidden_prev = model(x, hidden_prev)
hidden_prev = hidden_prev.detach()
loss = criterion(output, y)
model.zero_grad()
loss.backward()
# for p in model.parameters():
# print(p.grad.norm())
# torch.nn.utils.clip_grad_norm_(p, 10)
optimizer.step()
if iter % 100 == 0:
print("Iteration: {} loss {}".format(iter, loss.item()))
start = np.random.randint(3, size=1)[0]
time_steps = np.linspace(start, start + 10, num_time_steps)
data = np.sin(time_steps)
data = data.reshape(num_time_steps, 1)
x = torch.tensor(data[:-1]).float().view(1, num_time_steps - 1, 1)
y = torch.tensor(data[1:]).float().view(1, num_time_steps - 1, 1)
predictions = []
input = x[:, 0, :]
for _ in range(x.shape[1]):
input = input.view(1, 1, 1)
(pred, hidden_prev) = model(input, hidden_prev)
input = pred
predictions.append(pred.detach().numpy().ravel()[0])
x = x.data.numpy().ravel()
y = y.data.numpy()
plt.scatter(time_steps[:-1], x.ravel(), s=90)
plt.plot(time_steps[:-1], x.ravel())
plt.scatter(time_steps[1:], predictions)
plt.show()
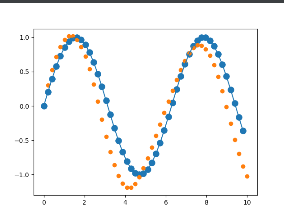
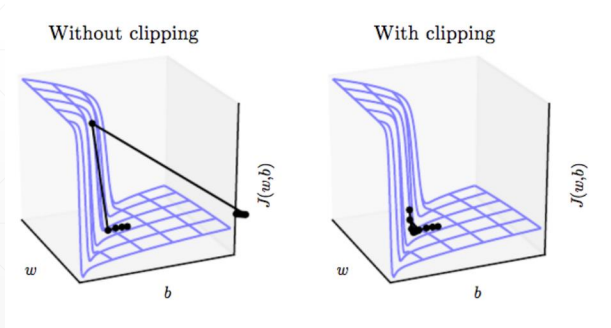
梯度爆炸
在梯度的计算过程中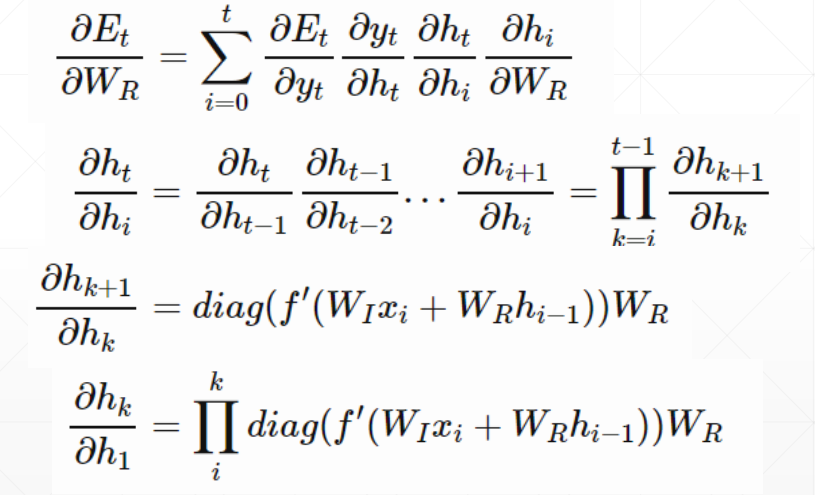
偏导与偏导之间只有乘法,会产生一个 Wn 的因子,当 W > 1时,不断地乘法会导致梯度趋于无穷,如图所示
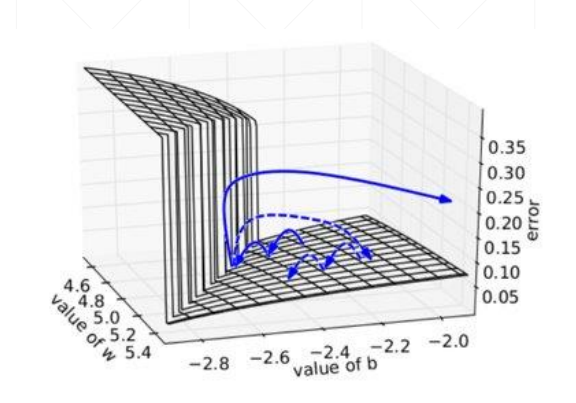
过大地梯度会导致梯度下降算法朝着错误地方向“迈”一大步,训练无法达到目的
解决方式
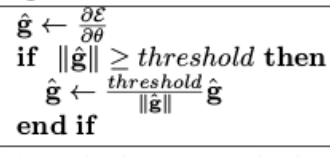
当梯度超过阈值时,保留梯度的方向,将值变为设定的大小,相当于减小其犯错造成的后果
梯度消失
和爆炸类似,当 W < 1 时,梯度信息会趋于零,解决方式 LSTM
LSTM
原理
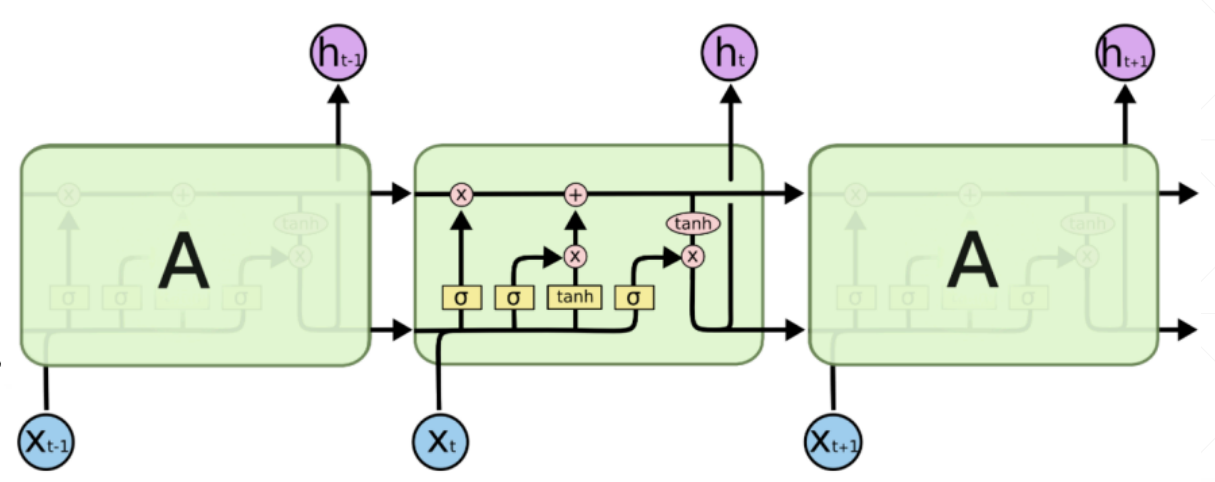
在RNN的基础上加以修改
RNN的记忆参数就是上一个模块的输出,导致后面的模块得不到比较靠前的信息
LSTM 设置参数 C 来专门作为记忆参数,输出是 h,输入为 X
C 的计算过程如下
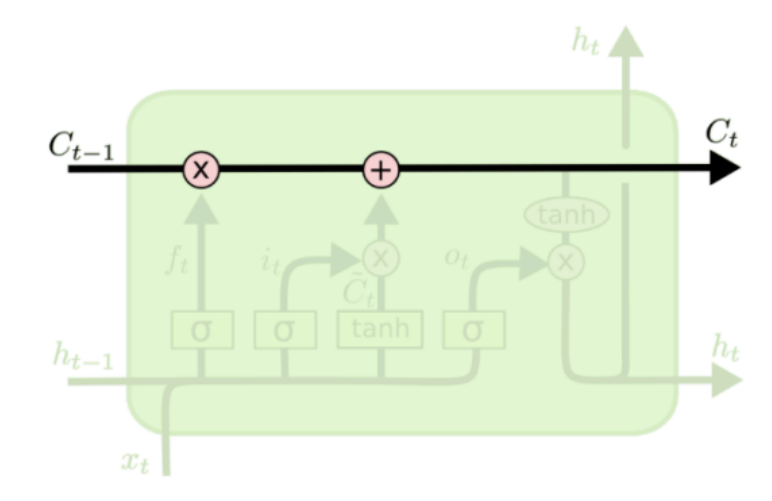
新的 Ct 由 Ct-1 乘以一个参数ft再加上一个参数it * 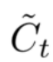 构成,
构成,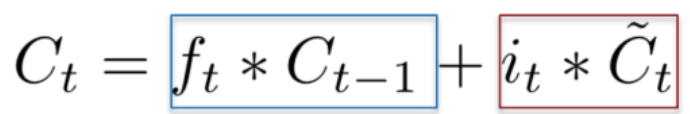
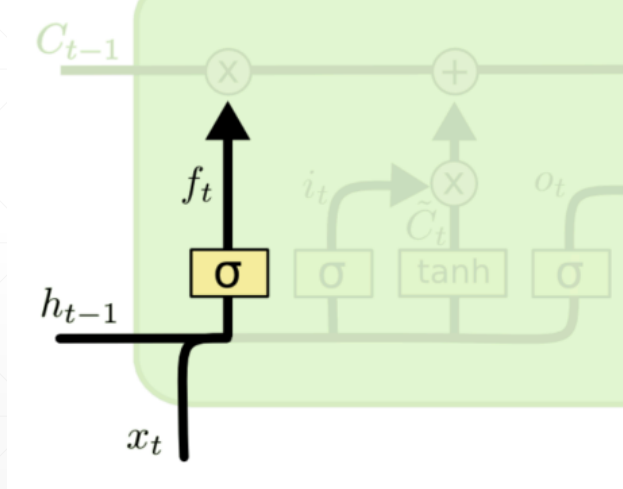
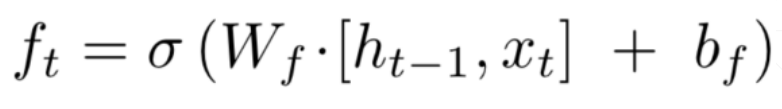
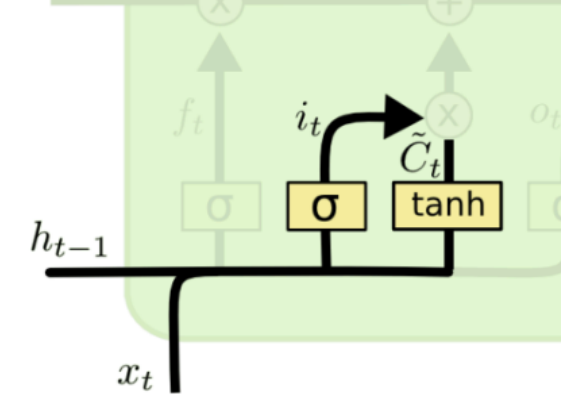
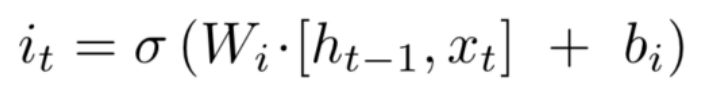
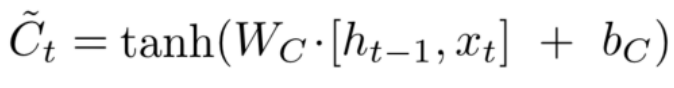
可以看到相当于新旧两个 C 在两个参数的影响下重新相加得到最后的 C
LSTM最后的输出 ht
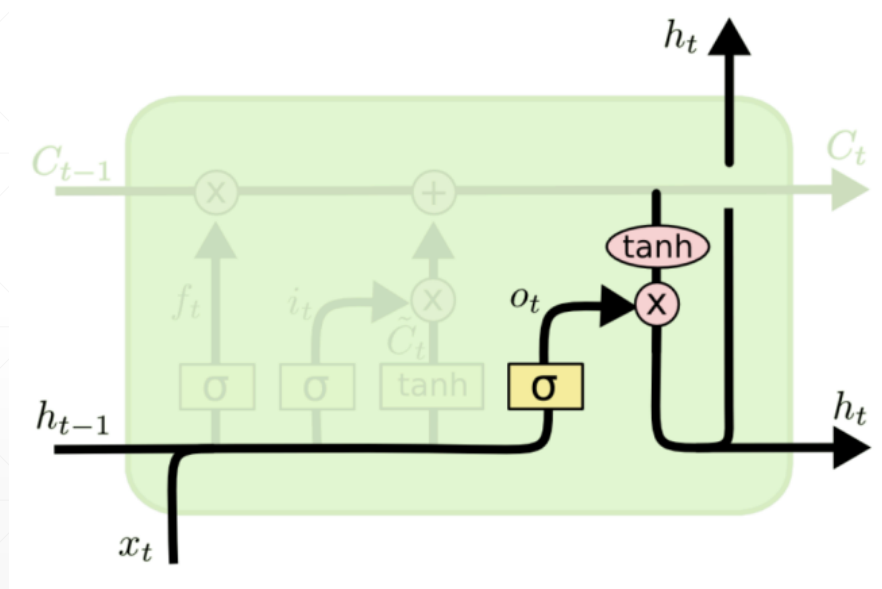
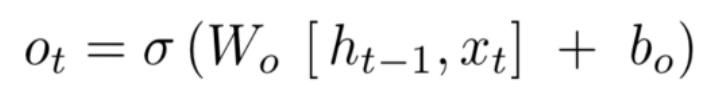
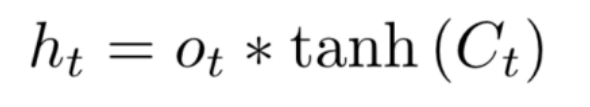
之所以解决了梯度消失的问题,因为计算过程中添加了加法运算,使得 Wn 因子没那么大的“作用”
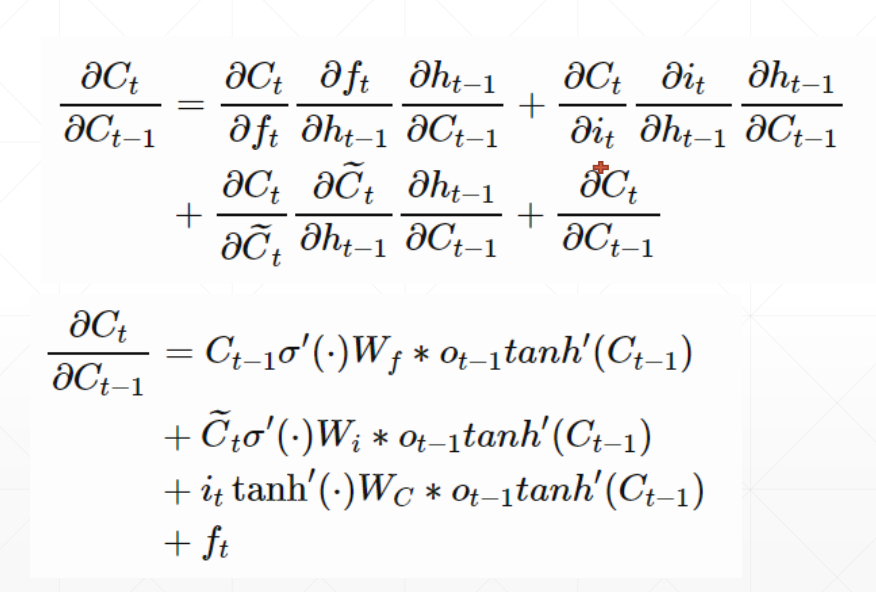
代码实现
和 nn.RNN 差不多

输出多了一个参数 C,但 C 的 dim 是和 h 一样的所以输入还原来的参数结构(nn.LSTM的输入参数),对于网络来说,输入多了个初始化的参数 C

同样的有 nn.LSTMCell

双层的
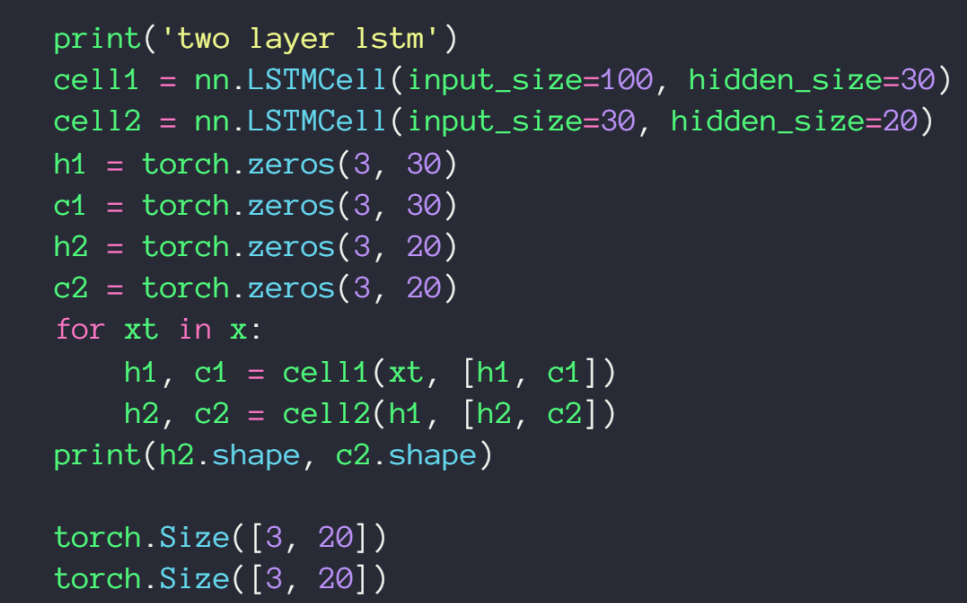
实战
评论分类问题
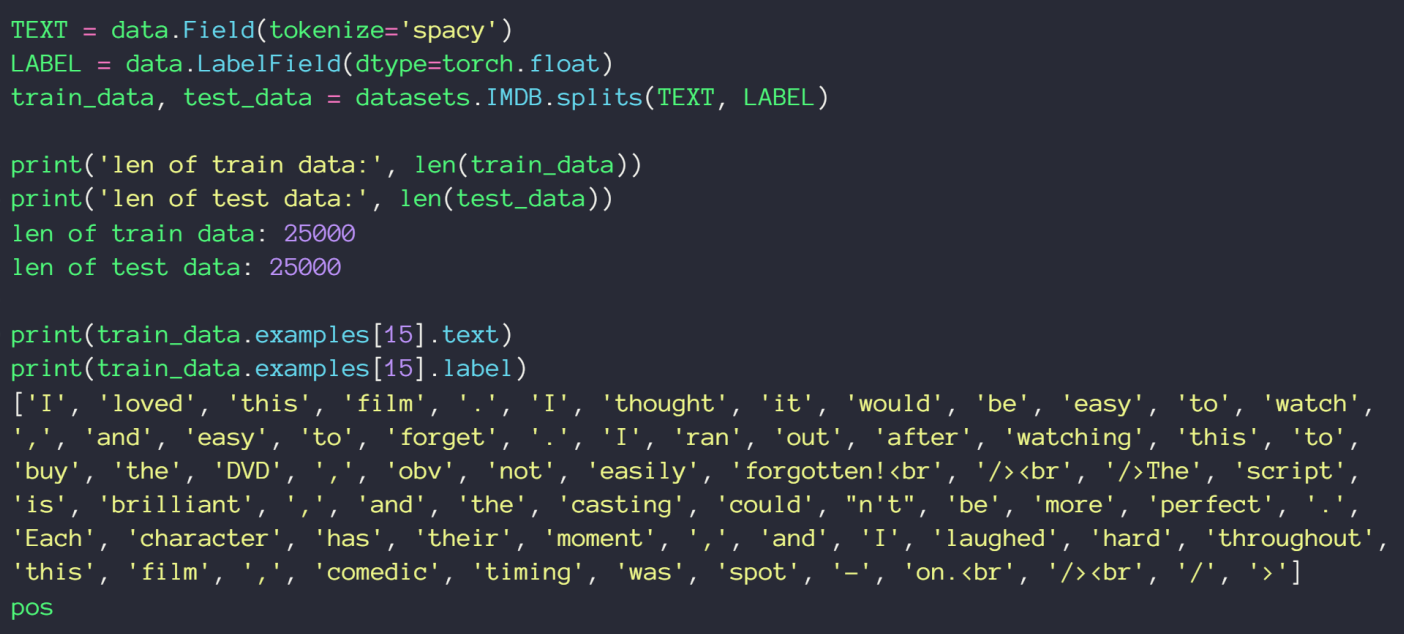
数据集使用 torchtext 中的 IMDB,获取方式如下
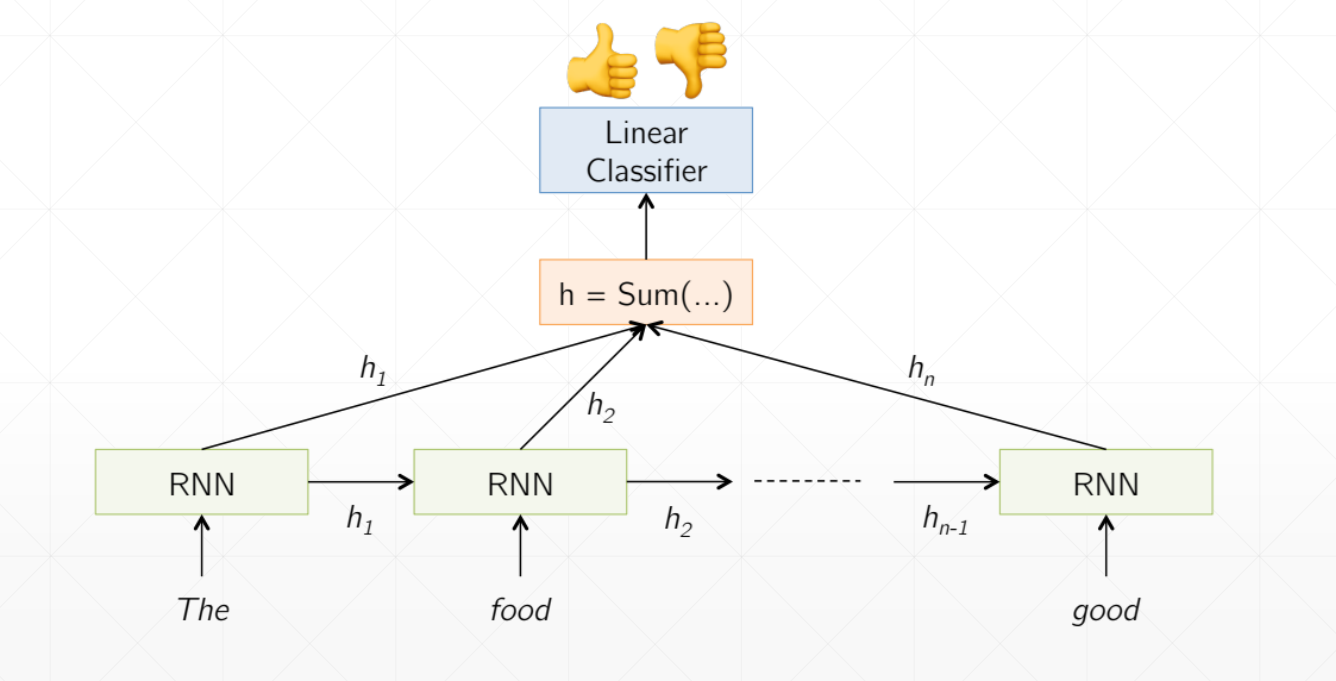
网络结构
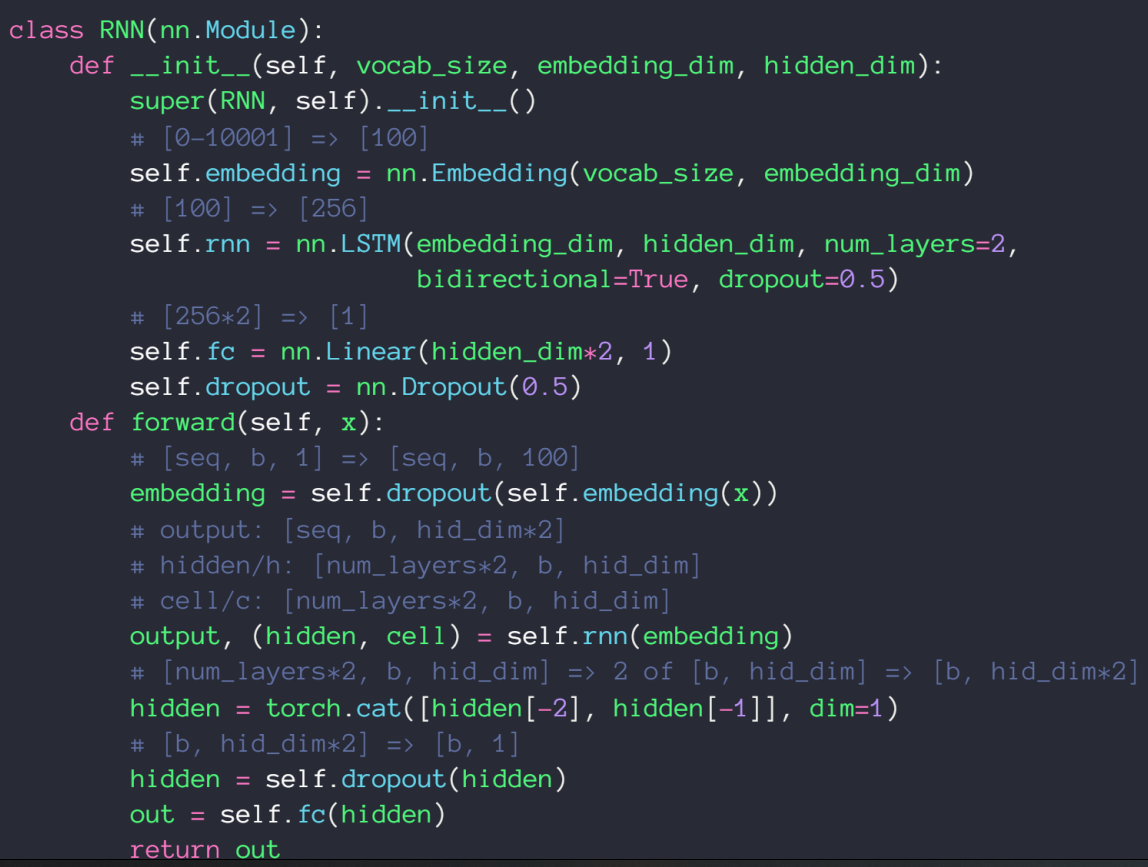
nn.Embedding 是编码器;参数1,被编码的总单词数 参数2,编码每个单词所需要的 dim
Embedding 初始化

关键在于第四行,将下载的 GloVe 编码方式的权重(vectors) 通过 copy_ 取代网络中的 embedding 的权重
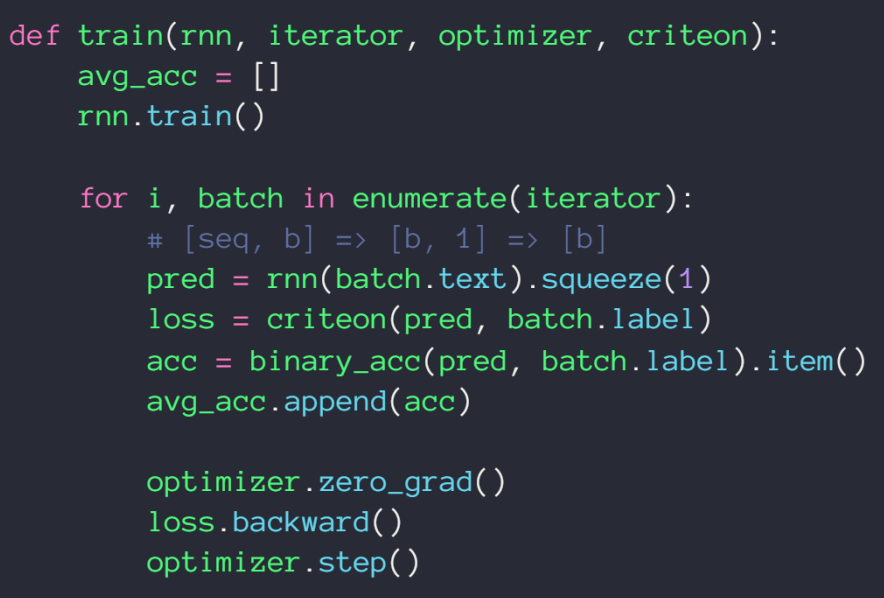
训练
自定义数据集
实例,自定义一个 pokemon 数据集,包括数据加载,训练,测试
原数据:https://pan.baidu.com/s/1V_ZJ7ufjUUFZwD2NHSNMFw 提取码:dsxl
包含一千多张五种宝可梦的图片
加载数据
创建一个自定义的数据集
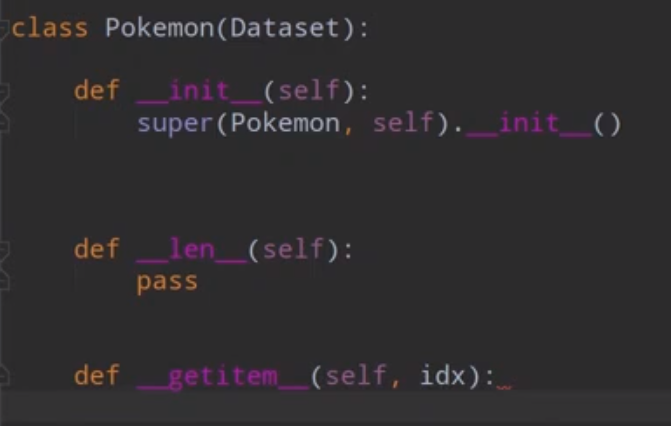
- 继承 torch.utils.data.Dataset
- 实现 _len__(元素数量) 和 _getitem (返回指定idx的元素)两个方法
数据预处理
- Image Resize 调整图片的大小以适应网络
- Data Argumentation 数据增强
- Normalize 标准化数据
- To Tensor 转化为 tensor 数据
import torch
import os, glob
import random, csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
# 定义数据集,并继承Dataset
class Pokemon(Dataset):
# root:文件目录 resize:图片大小 mode:数据模块(train,val,test)
def __init__(self, root, resize, mode):
super(Pokemon, self).__init__()
self.root = root
self.resize = resize
# 图片类别标号
# 以root目录中的文件夹名来确定图片种类并标号
self.name2label = {} # "sq...":0
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
# print(self.name2label)
# image, label
# 将图片的路径作为标识image,并和相对应的类别标号一起保存在csv文件中
self.images, self.labels = self.load_csv('images.csv')
# 区分三种数据
if mode=='train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif mode=='val': # 20% = 60%->80%
self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))]
self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))]
else: # 20% = 80%->100%
self.images = self.images[int(0.8*len(self.images)):]
self.labels = self.labels[int(0.8*len(self.labels)):]
def load_csv(self, filename):
# 如果没有csv文件就创建一个
if not os.path.exists(os.path.join(self.root, filename)):
images = []
# 遍历所有图片,保存其路径到images中
for name in self.name2label.keys():
# 'pokemon\\mewtwo\\00001.png
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
# 1167, 'pokemon\\bulbasaur\\00000000.png'
print(len(images), images)
random.shuffle(images)
# 根据images路径中的分类文件夹名来给每一个图片贴标签
# 格式为'pokemon\\bulbasaur\\00000000.png', 0
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images: # 'pokemon\\bulbasaur\\00000000.png'
name = img.split(os.sep)[-2]
label = self.name2label[name]
# 'pokemon\\bulbasaur\\00000000.png', 0
writer.writerow([img, label])
print('writen into csv file:', filename)
# read from csv file,读取数据返回
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
# 'pokemon\\bulbasaur\\00000000.png', 0
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
return len(self.images)
# 因为下面加载数据时做了标准化处理,导致visdom显示的图片乱码,denormalize 起到反标准化显示图片的功能
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x-mean)/std
# x = x_hat*std = mean
# x: [c, h, w]
# mean: [3] => [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
# print(mean.shape, std.shape)
x = x_hat * std + mean
return x
# 不能一次把所有图片数据读到内存中,getitem起到类似迭代器的效果
def __getitem__(self, idx):
# idx~[0~len(images)]
# self.images, self.labels
# img: 'pokemon\\bulbasaur\\00000000.png'
# label: 0
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
# 根据路径读取图片具体内容
lambda x:Image.open(x).convert('RGB'), # string path= > image data
# 调整图片大小
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
# 随机旋转
transforms.RandomRotation(15),
# 弥补随机旋转导致的黑边
transforms.CenterCrop(self.resize),
# 转为Tensor类型
transforms.ToTensor(),
# 标准化
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
def main():
import visdom
import time
import torchvision
#可视化
viz = visdom.Visdom()
# 以上所有的定义都可以由下面这一小块(torchvision.datasets.ImageFolder)来实现
# 图片目录符合 root/类型/数据 的格式
# tf = transforms.Compose([
# transforms.Resize((64,64)),
# transforms.ToTensor(),
# ])
# db = torchvision.datasets.ImageFolder(root='pokemon', transform=tf)
# loader = DataLoader(db, batch_size=32, shuffle=True)
#
# print(db.class_to_idx)
#
# for x,y in loader:
# viz.images(x, nrow=8, win='batch', opts=dict(title='batch'))
# viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
#
# time.sleep(10)
# 建立数据集
db = Pokemon('pokemon', 64, 'train')
x,y = next(iter(db))
print('sample:', x.shape, y.shape, y)
viz.image(db.denormalize(x), win='sample_x', opts=dict(title='sample_x'))
# 定义数据加载器,num_workers为线程数
loader = DataLoader(db, batch_size=32, shuffle=True, num_workers=8)
for x,y in loader:
viz.images(db.denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
time.sleep(10)
if __name__ == '__main__':
main()
网络结构ResNet
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h ,w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# # [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# # [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
# [b, 256, 7, 7]
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
print('block:', out.shape)
model = ResNet18(5)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if __name__ == '__main__':
main()
训练
import torch
from torch import optim, nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from pokemon import Pokemon
from resnet import ResNet18
batchsz = 32
lr = 1e-3
epochs = 10
device = torch.device('cuda')
torch.manual_seed(1234)
train_db = Pokemon('pokemon', 224, mode='train')
val_db = Pokemon('pokemon', 224, mode='val')
test_db = Pokemon('pokemon', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True,
num_workers=4)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
viz = visdom.Visdom()
def evalute(model, loader):
model.eval()
correct = 0
total = len(loader.dataset)
for x,y in loader:
x,y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(5).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
global_step = 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch in range(epochs):
for step, (x,y) in enumerate(train_loader):
# x: [b, 3, 224, 224], y: [b]
x, y = x.to(device), y.to(device)
model.train()
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if epoch % 1 == 0:
val_acc = evalute(model, val_loader)
if val_acc> best_acc:
best_epoch = epoch
best_acc = val_acc
# 保存最有acc的情况下的参数数据
torch.save(model.state_dict(), 'best.mdl')
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(model, test_loader)
print('test acc:', test_acc)
if __name__ == '__main__':
main()
用到的util
from matplotlib import pyplot as plt
import torch
from torch import nn
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
def plot_image(img, label, name):
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
plt.title("{}: {}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
迁移学习
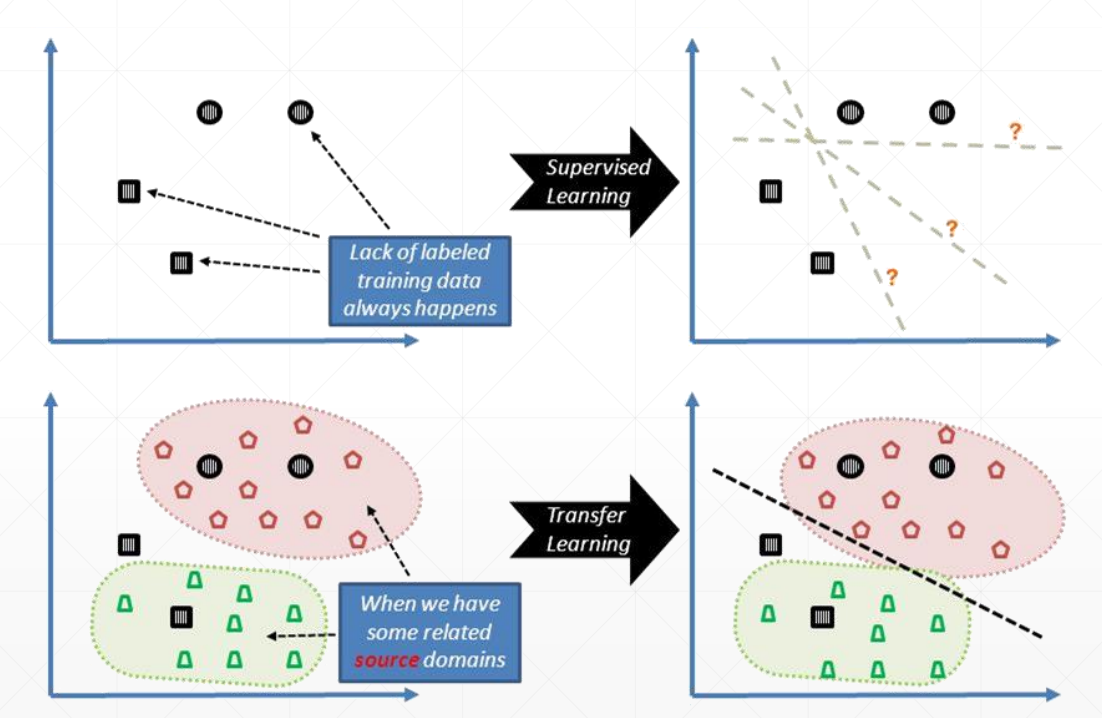
如图(上面两张)所示,在样本较少的情况下,训练的结果的可能性有很多,不一定能够得到最好的效果(中间那条)
所以如下方两张所示,如可有原来训练好的模型的基础上再训练自己的样本,会得到更好的效果,这就是迁移学习
对于本例只需要在训练代码中修改
# from resnet import ResNet18
from torchvision.models import resnet18
from utils import Flatten
...
# model = ResNet18(5).to(device)
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], #[b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
).to(device)
自编码器
基础
Auto-Encoders,用于无监督学习
训练数据集没有标签,自编码器起到降维的作用
无监督学习的过程
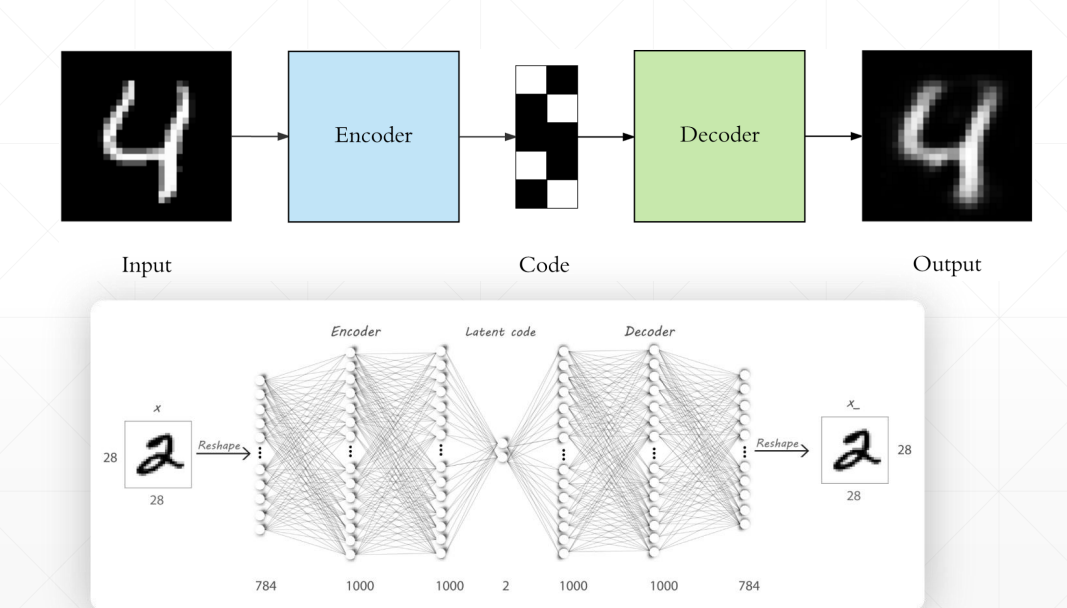
将原数据编码降维后再通过一个网络使得其变回原来的数据,训练目标就是数据前后的差别越小越好
两种loss
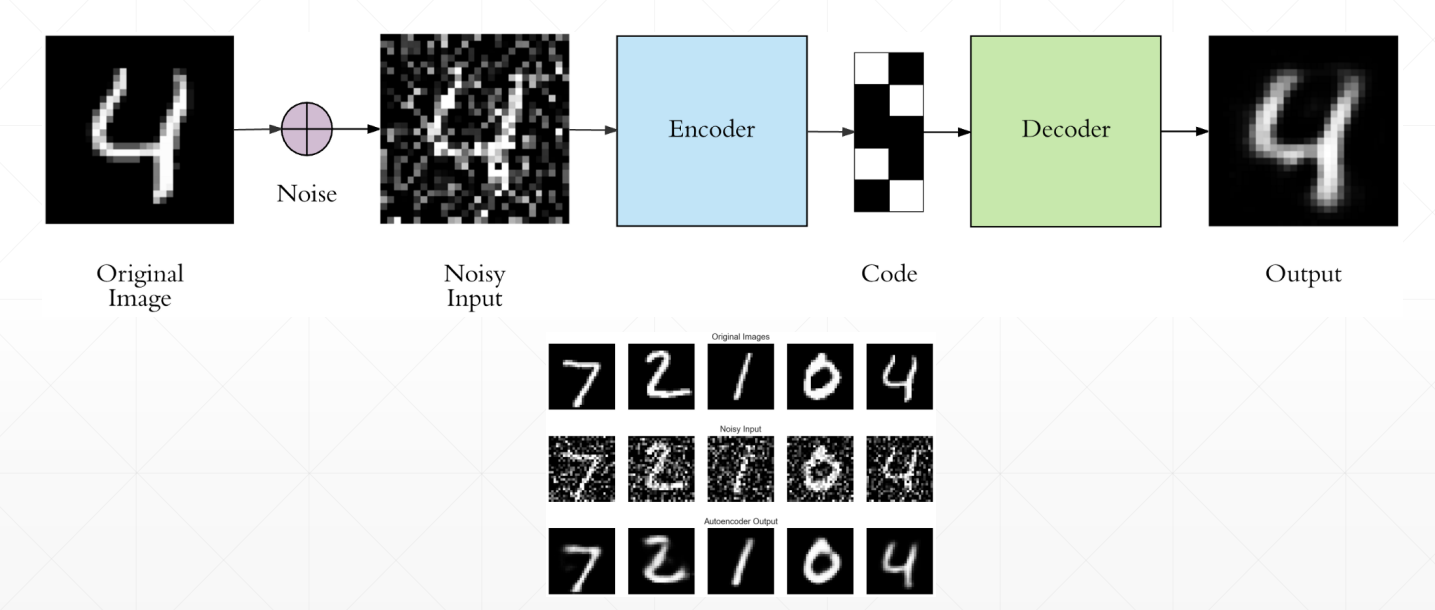
Denoising AutoEncoders
自编码器的变种,在进入Encoder前对数据添加噪声
Dropout AutoEncoders
自编码器的变种,训练时,每次epoch随机选择部分网络节点参与运算
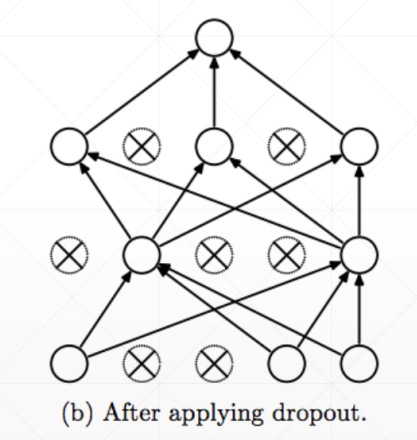
Adversarial AutoEncoders
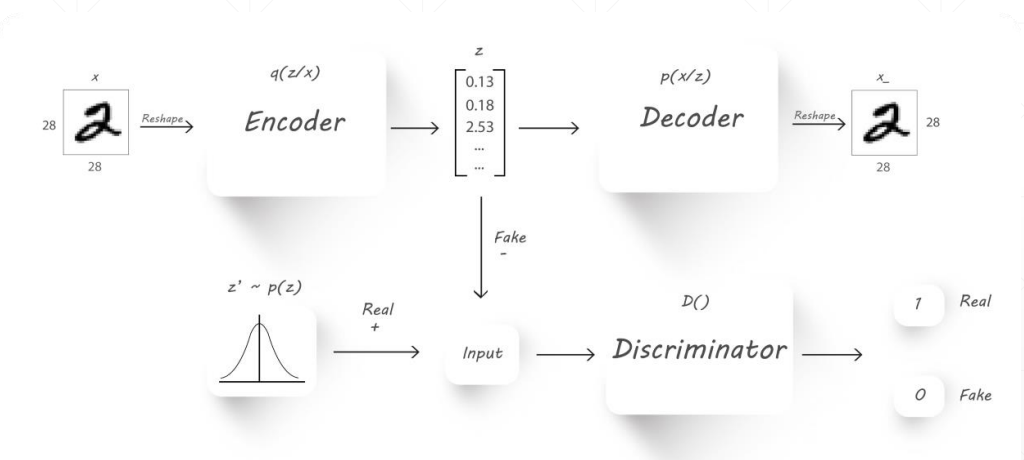
在训练时不仅限制结果与原来的区别,在 loss 中添加对于中间层要满足某分布的要求
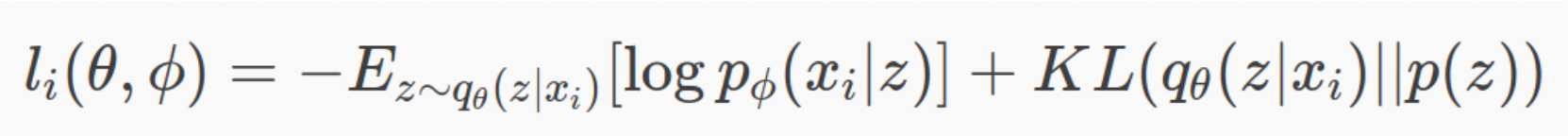
loss 公式由两部分组成
- 由前后数据的差异决定,越相近差距越小
- 由中间层的分布与设定的分布的差异决定,越相近差距越小
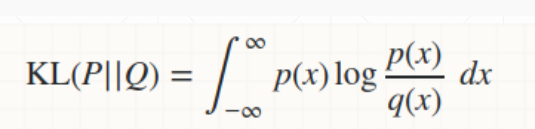
生成对抗网络GAN
GAN是一个由两个模型组成的系统:判别器( D )和生成器( G )。判别器的任务是判断输入图像是源自数据集中还是由机器生成的。判别器一般使用二分类的神经网络来构建,一般将取自数据集的样本视为正样本,而生成的样本标注为负样本。生成器的任务是接收随机噪声,然后使用反卷积网络来创建一个图像。
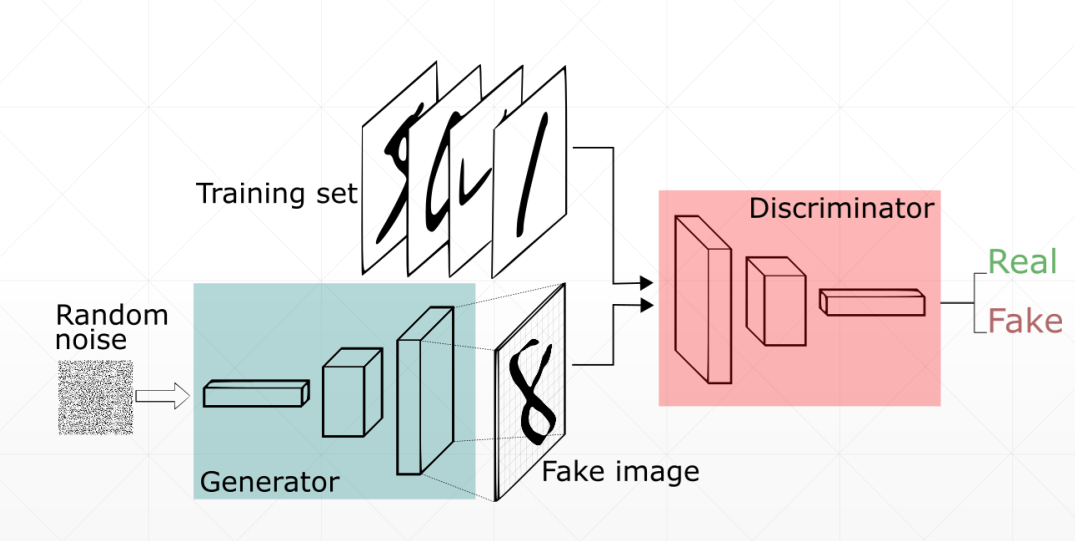
累了,推荐《深入浅出PyTorch》这本书上去看
tplotlib import pyplot as plt
import torch
from torch import nn
class Flatten(nn.Module):
def __init__(self):
super(Flatten, self).__init__()
def forward(self, x):
shape = torch.prod(torch.tensor(x.shape[1:])).item()
return x.view(-1, shape)
def plot_image(img, label, name):
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
plt.title("{}: {}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
## 迁移学习
<img src="https://biji-1310687466.cos.ap-nanjing.myqcloud.com/biji/image-20221216141032184.png" alt="image-20221216141032184" style="zoom:67%;" />
如图(上面两张)所示,在样本较少的情况下,训练的结果的可能性有很多,不一定能够得到最好的效果(中间那条)
所以如下方两张所示,如可有原来训练好的模型的基础上再训练自己的样本,会得到更好的效果,这就是**迁移学习**
对于本例只需要在训练代码中修改
```python
# from resnet import ResNet18
from torchvision.models import resnet18
from utils import Flatten
...
# model = ResNet18(5).to(device)
trained_model = resnet18(pretrained=True)
model = nn.Sequential(*list(trained_model.children())[:-1], #[b, 512, 1, 1]
Flatten(), # [b, 512, 1, 1] => [b, 512]
nn.Linear(512, 5)
).to(device)
自编码器
基础
Auto-Encoders,用于无监督学习
训练数据集没有标签,自编码器起到降维的作用
无监督学习的过程
将原数据编码降维后再通过一个网络使得其变回原来的数据,训练目标就是数据前后的差别越小越好
两种loss
Denoising AutoEncoders
自编码器的变种,在进入Encoder前对数据添加噪声
[外链图片转存中…(img-jJ6v1cWR-1671341836185)]
Dropout AutoEncoders
自编码器的变种,训练时,每次epoch随机选择部分网络节点参与运算
Adversarial AutoEncoders
在训练时不仅限制结果与原来的区别,在 loss 中添加对于中间层要满足某分布的要求
[外链图片转存中…(img-MSG9ZpVe-1671341836186)]
loss 公式由两部分组成
- 由前后数据的差异决定,越相近差距越小
- 由中间层的分布与设定的分布的差异决定,越相近差距越小
生成对抗网络GAN
GAN是一个由两个模型组成的系统:判别器( D )和生成器( G )。判别器的任务是判断输入图像是源自数据集中还是由机器生成的。判别器一般使用二分类的神经网络来构建,一般将取自数据集的样本视为正样本,而生成的样本标注为负样本。生成器的任务是接收随机噪声,然后使用反卷积网络来创建一个图像。
累了,推荐《深入浅出PyTorch》这本书上去看