目录
Table Types
Query types
Copy On Write Table
Merge On Read
Table & Query Types | Apache Hudi
Hudi表类型定义了如何在DFS上对数据进行索引和布局,以及如何在这样的组织之上实现上述原语和时间线活动(即如何写入数据)。反过来,查询类型定义了底层数据如何向查询公开(即如何读取数据)。
| Table Type | Supported Query types |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
Table Types
Hudi支持以下表类型
- 写入时复制:使用列式文件格式(例如parquet)存储数据。通过在写入期间执行同步合并,更新简单地对文件进行版本和重写。
- 读取时合并:使用列式(例如parquet)+基于行的(例如avro)文件格式的组合存储数据。更新被记录到增量文件中,然后被压缩以同步或异步地生成新版本的列式文件。
下表总结了这两种表类型之间的区别
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data Latency | Higher | Lower |
| Query Latency | Lower | Higher |
| Update cost (I/O) | Higher (rewrite entire parquet) | Lower (append to delta log) |
| Parquet File Size | Smaller (high update(I/0) cost) | Larger (low update cost) |
| Write Amplification | Higher | Lower (depending on compaction strategy) |
Query types
Hudi支持以下查询类型
- 快照查询:查询查看给定提交或压缩操作时表的最新快照。在读取表上进行合并的情况下,它通过动态合并最新文件切片的基本文件和增量文件来暴露近乎实时的数据(几分钟)。对于写表复制,它提供了对现有拼花地板表的直接替换,同时提供了追加启动/删除和其他写端功能;
- 增量查询:自从给定的提交/压缩之后,查询只能看到写入到表中的新数据。这有效地提供了更改流,以启用增量数据管道;
- 读取优化查询:查询查看给定提交/压缩操作时表的最新快照。只显示最新文件切片中的基本/列式文件,并保证与非hudi列式表相比具有相同的列式查询性能;
下表总结了不同查询类型之间的权衡。
| Trade-off | Snapshot | Read Optimized |
|---|---|---|
| Data Latency | Lower | Higher |
| Query Latency | Higher (merge base / columnar file + row based delta / log files) | Lower (raw base / columnar file performance) |
Copy On Write Table
“写入时复制”表中的文件切片仅包含基本/列文件,每次提交都会生成新版本的基本文件。换句话说,我们在每次提交时都隐式压缩,这样只存在列数据。因此,写入放大率(为1字节的输入数据写入的字节数)高得多,其中读取放大率为零。这是分析工作负载非常需要的属性,因为分析工作负载主要是重读取的。
下面从概念上说明了当数据写入到写时拷贝表中并在其上运行两个查询时,这是如何工作的。
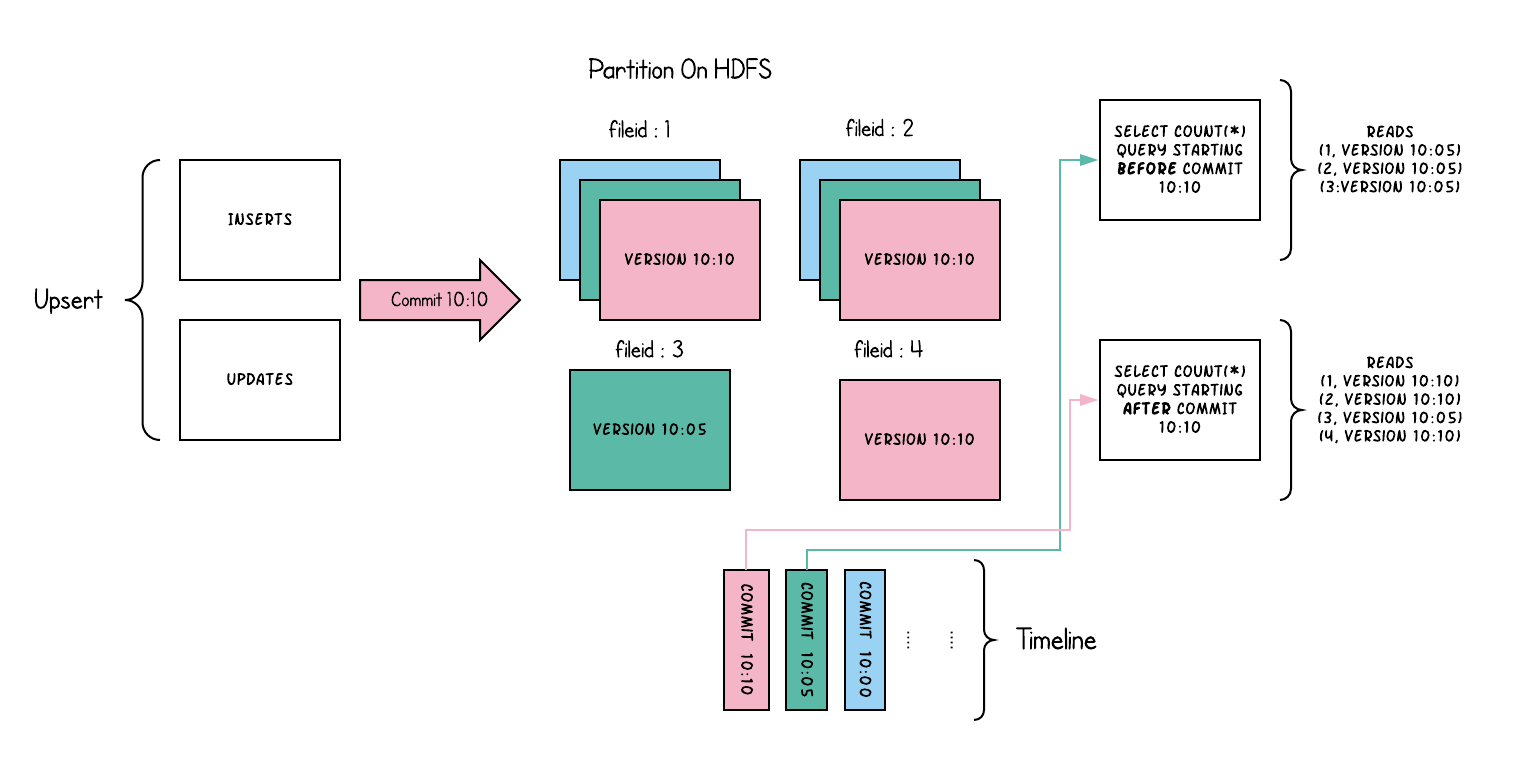
当数据被写入时,对现有文件组的更新会为该文件组生成一个新的切片,该切片标记有提交即时时间,而插入会分配一个新文件组并为该文件群写入其第一个切片。这些文件切片及其提交时间在上面用颜色编码。针对这样一个表运行的SQL查询(例如:select count(*)统计该分区中的总记录),首先检查最新提交的时间线,并过滤每个文件组中除最新文件片段之外的所有文件片段。正如您所看到的,一个旧的查询不会看到当前飞行中提交的文件以粉色编码,而是在提交后开始的一个新的查询会拾取新的数据。因此,查询不受任何写入失败/部分写入的影响,仅在提交的数据上运行。
写表复制的目的是通过
- 一流的支持在文件级自动更新数据,而不是重写整个表/分区;
- 能够增量使用更改,而不是浪费扫描或摸索启发式;
- 严格控制文件大小以保持出色的查询性能(小文件会严重影响查询性能)。
Merge On Read
“写入时复制”表中的文件切片仅包含基本/列文件,每次提交都会生成新版本的基本文件。换句话说,我们在每次提交时都隐式压缩,这样只存在列数据。因此,写入放大率(为1字节的输入数据写入的字节数)高得多,其中读取放大率为零。这是分析工作负载非常需要的属性,因为分析工作负载主要是重读取的。
下面从概念上说明了当数据写入到写时拷贝表中并在其上运行两个查询时,这是如何工作的。
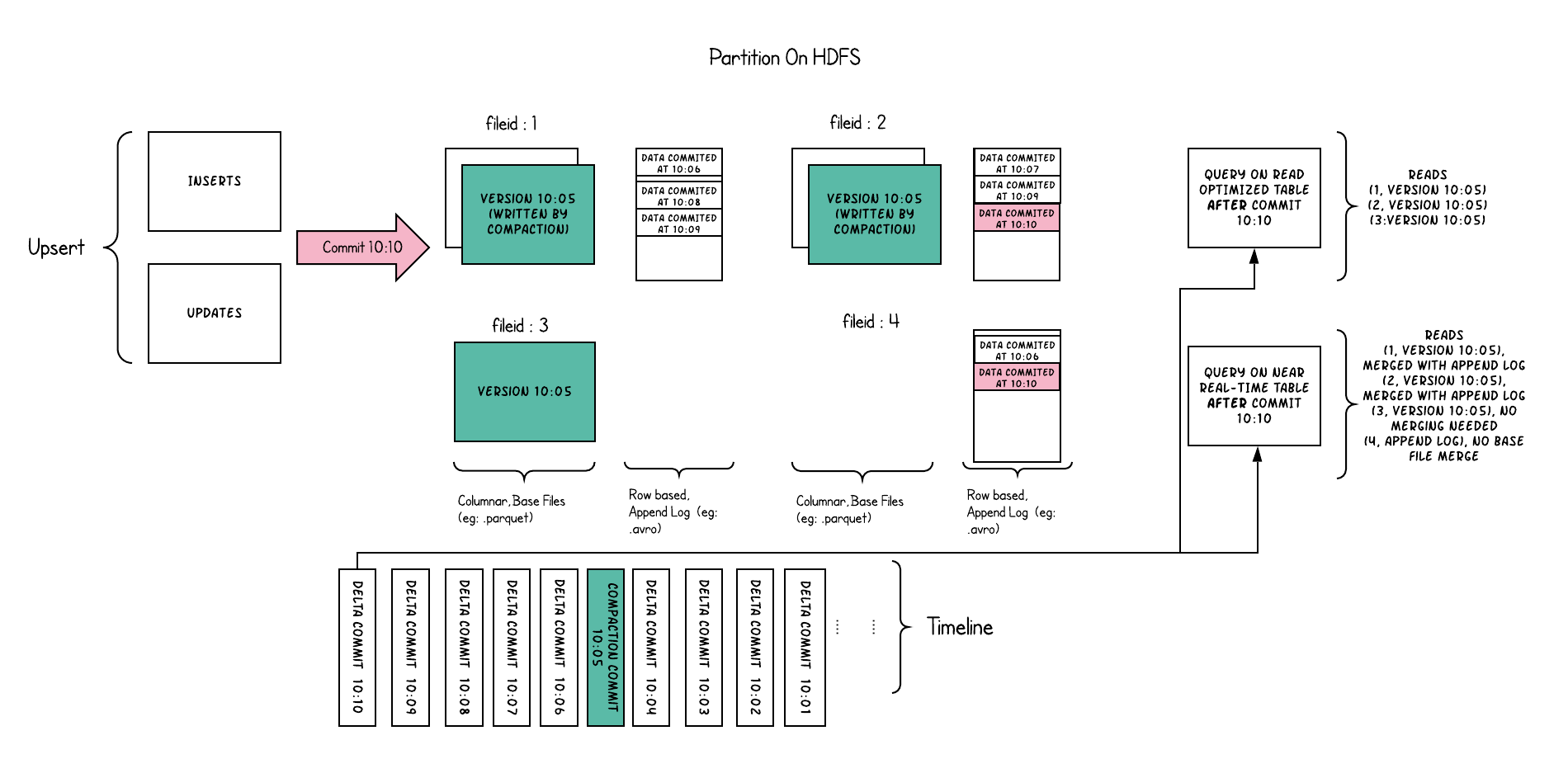
在这个例子中发生了很多有趣的事情,它们揭示了方法中的微妙之处:
- 我们现在每1分钟左右就会提交一次,这是其他表类型无法做到的;
- 在每个文件id组中,现在有一个增量日志文件,它保存对基本列文件中记录的传入更新。在本例中,delta日志文件保存了10:05到10:10之间的所有数据。与之前一样,基本柱状文件仍然使用提交进行版本控制。因此,如果只查看基本文件,那么表布局看起来就像一个写时复制表;
- 定期压缩过程从增量日志中协调这些更改,并生成新版本的基础文件,就像示例中10:05发生的情况一样;
- 查询同一基础表有两种方法:读取优化查询和快照查询,这取决于我们选择的是查询性能还是数据的新鲜度;
- 当来自提交的数据可用于查询时,对于读优化查询,语义会以微妙的方式发生变化。请注意,这样一个在10:10运行的查询在10:05之后不会看到数据,而快照查询总是看到最新的数据;
- 当我们触发压缩时,它决定压缩什么,这是解决这些难题的关键。通过实施压缩策略(与旧分区相比,我们积极压缩最新分区),我们可以确保读取优化的查询在X分钟内以一致的方式查看发布的数据。
合并读表的目的是直接在DFS上实现近乎实时的处理,而不是将数据复制到可能无法处理数据量的专用系统。该表还有一些次要的好处,例如通过避免数据的同步合并来减少写入放大,即一批中每1字节数据写入的数据量。