本篇文章围绕执行引擎,深入浅出的解析执行引擎中解释器与编译器的解释执行和编译执行、执行引擎的执行方式、逃逸分析带来的栈上分配、锁消除、标量替换等优化以及即时编译器编译对热点代码的探测
执行引擎
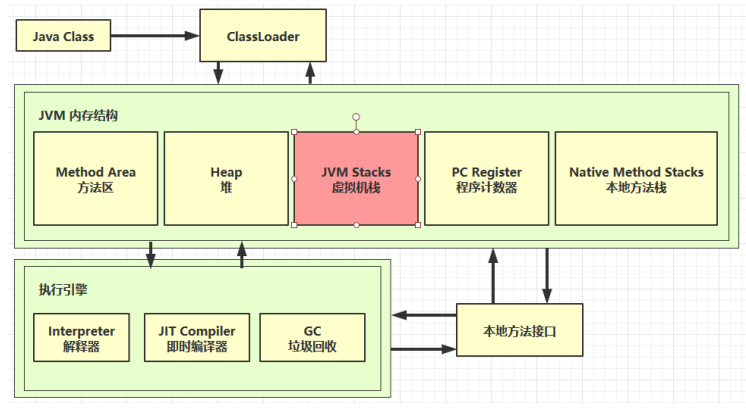
hotspot执行引擎结构图
执行引擎分为解释器、JIT即时编译器以及垃圾收集器
执行引擎通过解释器/即时编译器将字节码指令解释/编译为对应OS上的的机器指令

本篇文章主要围绕解释器与即时编译器,垃圾收集器将在后续文章解析
解释执行与编译执行
Java虚拟机执行引擎在执行Java代码时,会有两种选择:解释执行和编译执行
解释执行:通过字节码解释器把字节码解析为机器语言执行
编译执行:通过即时编译器产生本地代码执行
Class文件中的代码到底是解释执行还是编译执行只有Java虚拟机自己才能判断准确
编译过程

经典编译原理: 1.对源码进行词法,语法分析处理 2.把源码转换为抽象语法树
javac编译器完成了对源码进行词法,语法分析处理为抽象语法树,再遍历抽象语法树生成线性字节码指令流的过程
剩下的指令流有两种方式执行
- 由虚拟机内部的字节码解释器去将字节码指令进行逐行解释 (解释执行)
- 或优化器(即时编译器)优化代码最后生成目标代码 (编译执行)
执行引擎流程图

解释器与编译器
解释器
作用: 对字节码指令逐行解释
优点: 程序启动,解释器立即解释执行
缺点: 低效
即时编译器 (just in time compiler)
Java中的"编译期"不确定
- 可能说的是执行javac指令时的前端编译器 (.java->.class)
- 也可能是后端编译器JIT (字节指令->机器指令)
- 还可能是AOT编译器(静态提前编译器) (.java->机器指令)
作用: 将方法编译成机器码缓存到方法区,每次调用该方法执行编译后的机器码
优点: 即时编译器把代码编译成本地机器码,执行效率高,高效
缺点: 程序启动时,需要先编译再执行
执行引擎执行方式
执行引擎执行方式大致分为3种
-Xint: 完全采用解释器执行
-Xcomp: 优先采用即时编译器执行,解释器是后备选择
-Xmixed: 采用解释器 + 即时编译器

hotspot中有两种JIT即时编译器
Client模式下的C1编译器:简单优化,耗时短(C1优化策略:方法内联,去虚拟化,冗余消除)
Server模式下的C2编译器:深度优化,耗时长 (C2主要是逃逸分析的优化:标量替换,锁消除,栈上分配)
分层编译策略:程序解释执行(不开启逃逸分析)可以触发C1编译,开启逃逸分析可以触发C2编译
解释器,C1,C2编译器同时工作,热点代码可能被编译多次
解释器在程序刚刚开始的时候解释执行,不需要承担监控的开销
C1有着更快的编译速度,能为C2编译优化争取更多时间
C2用高复杂度算法,编译优化程度很高的代码
逃逸分析带来的优化
当对象作用域只在某个方法时,不会被外界调用到,那么这个对象就不会发生逃逸
开启逃逸分析后,会分析对象是否发生逃逸,当不能发生逃逸时会进行栈上分配、锁消除、标量替换等优化
栈上分配内存
//-Xms1G -Xmx1G -XX:+PrintGCDetails
public class StackMemory {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
memory();
}
System.out.println("花费时间:"+(System.currentTimeMillis()-start)+"ms");
try {
TimeUnit.SECONDS.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private static void memory(){
StackMemory memory = new StackMemory();
}
}
复制代码-XX:-DoEscapeAnalysis 花费时间:63ms (未开启逃逸分析)
-XX:+DoEscapeAnalysis 花费时间:4ms (开启逃逸分析)
默认开启逃逸分析
锁消除
同步加锁会带来开销
锁消除:当加锁对象只作用某个方法时,JIT编译器借助逃逸分析判断使用的锁对象是不是只能被一个线程访问,如果是这种情况下就不需要同步,可以取消这部分代码的同步,提高并发性能
标量替换
标量: 无法再分解的数据 (基本数据类型)
聚合量: 还可以再分解的数据 (对象)
标量替换: JIT借助逃逸分析,该对象不发生逃逸,只作用于某个方法会把该对象(聚合量)拆成若干个成员变量(标量)来代替
默认开启标量替换
public class ScalarSubstitution {
static class Man{
int age;
int id;
public Man() {
}
}
public static void createInstance(){
Man man = new Man();
man.id = 123;
man.age = 321;
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
createInstance();
}
System.out.println("花费时间:"+(System.currentTimeMillis()-start)+"ms");
try {
TimeUnit.SECONDS.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
复制代码 //-Xmx200m -Xms200m -XX:+PrintGCDetails
//-XX:+DoEscapeAnalysis 设置开启逃逸分析
//-XX:-EliminateAllocations 设置不开启标量替换
//开启逃逸分析 + 关闭标量替换 : 花费时间:93ms
//开启逃逸分析 + 开启标量替换 : 花费时间:6ms
复制代码热点代码与热点探测
JIT编译器并不是编译所有的字节码,JIT编译器只编译热点代码
热点代码: 被多次调用的方法 或 方法中多次循环的循环体
栈上替换(OSR): JIT将方法中的热点代码编译为本地机器指令(被多次执行的循环体)
编译对象都是方法,如果是栈上替换则"入口"在方法的循环体开始那里
热点探测功能决定了被调用多少次的方法能成为热点代码
hotspot采用基于计数器的热点探测
- 方法调用计数器 : 统计方法调用次数
- 回边计数器 : 统计循环体执行循环次数
方法调用时先判断是否有执行编译后的机器码,有则直接使用方法区的Code cache中的机器码;没有机器码则判断计数器次数是否超过阈值,超过则触发编译,编译后机器码存储在方法区Code cache中使用;最后都没有就使用解释执行
总结
本篇文章将围绕执行引擎,深入浅出的解析执行引擎中的解释器、即时编译器各自执行的优缺点以及原理
执行引擎由解释器、即时编译器、垃圾收集器构成,默认情况下使用解释器与编译器的混合方式执行
即时编译器分为C1、C2编译器,其中C1编译快但优化小,C2开启逃逸分析使用栈上分配、锁消除、标量替换进行优化,编译耗时但是优化大
即时编译器并不是所有代码都编译,而是使用方法技术和循环计数来将热点代码编译成机器码存放在方法区的Code Cache中
在混合执行的模式下,解释器、C1、C2编译器同时工作,分层编译