1. 写在前面
今天开始,想开启大数据框架学习的一个新系列,之前在学校的时候就会大数据相关技术很是好奇,但苦于没有实践场景,对这些东西并没有什么体会,到公司之后,我越发觉得大数据的相关知识很重要,不管是搞开发还是做算法,每天都会和海量的数据打交道,而如果想真正的了解我们手中的数据,必须要知道它的整个生命周期,而这里面,就涉及到了海量数据的读取,存储,计算和应用等,所以,我想利用工作之余的闲暇时间, 慢慢去接触点大数据相关的知识,有关这一块,现在有很成熟的框架体系,尚大都总结的完整的,所以这一块跟着尚大好好去学就好,由于是业余时间学习,现在是打算按照组件学,每学完一个组件,记录一篇博客对笔记总结和复盘,然后开启下一个组件,so,又开始一段新的学习之旅,开始吧。
今天这一篇文章是有关Hadoop入门的相关笔记,如果想真正的系统学习大数据框架, Hadoop是无法绕开的一道门, 虽然现在Hadoop可能流行度在下降,可它毕竟是大数据存储和处理的开端,作为入门大数据, 了解清楚它的运作原理,有哪些组件,怎么解决大数据的存储和计算等知识,是非常利于后面的学习的。 Hadoop框架这里, 其实体系很清晰,也可能是尚大总结的好,首先是概述, Hadoop是啥,有哪些组件,怎么配合运作处理大数据问题,然后就是为啥有它,也就是why? 这俩完事之后,那就是要有一个大数据的环境,然后去学每个组件的细节了(hdfs, yarn, mapduce), 这一圈完事之后,Hadoop就能走一遍了。 这篇文章,主要先入个门,学习下概述,以及搭建一个集群环境,为后面学习每个组件做准备。内容如下:

ok, let’s, go!
2. Hadoop概述
2.1 What
2.1.1 基本概念和发展历史
Hadoop是一个Apache基金会开发的分布式系统基础架构, 主要解决: 海量数据的存储和海量数据的分析计算问题。
广义上, Hadoop一般指Hadoop生态圈
了解一个新概念,有必要了解他的发展历史:
-
Hadoop创始人Doug Cutting, 为实现和Google类似的全文搜索功能, 再Lucene框架(和ES有关)基础上优化升级, 查询引擎和索引引擎
-
2001 Lucene成为Apache基金会子项目
-
对于海量数据场景, Lucene框架和Google遇到了同样的困难, 海量数据存储困难, 检索数据慢
-
2003年, Google在大数据方面发表了三篇论文(三驾马车GFS, Map-Reduce, BigTable),解决了上面的问题, 但Google此时只有3篇论文,没有开源代码
-
2003-2004, Hadoop创始人团队开始学习和模仿Google解决这些问题的办法,在此基础上对DFS和MapReduce机制作出了实现,把Lucene框架进行了又一层封装,名曰微型版Nutch,解决了上面的难题。 对应关系:
- GFS → HDFS
- Map-Reduce → Map-Reduce
- BigTable → HBase
所以,Google是Hadoop思想的源泉
-
2005年, Hadoop作为Lucene的子项目Nutch的一部分正式引入Apache基金会
-
2006年,MapReduce和Nutch Distributed File System(NDFS)分别纳入Hadoop项目, Hadoop正式诞生, 标志大数据时代的来临
Hadoop三大发行版本: Apache(免费,最基础), Cloudera(服务收费,封装,功能完善, 产品CDH), Hortonworks(服务收费,也封装, 产品HDP)
2.1.2 Hadoop组成(面试重点)

这里的计算, 指的的程序方面的运行计算,而资源调度,是执行计算的时候, 确定在哪台机器运行,完成计算,需要分配多少内存等,这个是资源的调度。 核心:1.x计算和调度,都由MapReduce完成,耦合性太高, 所以2.x版本,增加了Yarn来分担MapReduce的责任,MapReduce只负责计算, Yarn负责资源调度
所以Hadoop的三大关键组件: HDFS管着数据存储, YARN管着资源调度, MapReduce管着计算。
2.1.3 HDFS架构概述
HDFS主管海量数据的存储,也就是海量的数据,在多台机器上如何存储的问题,这里面有几个概念需要先了解下, 后面会专门写一篇文章整理细节。

组件:
NameNode(NN): 存储文件的元数据, 如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限), 以及每个文件的块列表和块所在的DataNode等, 这个东西,就类似于一个索引,它不存储具体数据。DataNode: 在本地文件系统存储文件块数据,以及块数据的校验和Secondary NameNode(2NN): 每隔一段时间对NameNode元数据备份
2.1.4 YARN架构概述
Yet Another Resource Negotiator(YARN), 是Hadoop的资源管理器

这个图就是YARN的精华, 首先,知道YARN里面的一些概念:
- ResourceManager(RM): 整个集群资源(内存,cpu)的老大
- NodeManager(NM): 单个节点服务器资源的老大
- AplicationMaster(AM): 单个任务运行的老大
- Container: 容器,相当于一台独立的服务器, 里面封装了任务运行所需要的资源
一个任务来了之后,就会在服务器的某个节点上,先产生一个ApplicationMaster, 单个任务的老大,会根据运行任务所需的资源,去跟RM申请资源, 此时RM会分配对应的节点运行任务,这个节点可以是AM所在的服务器,也可以把任务节点放到其他服务器,并给他分配好资源,有了资源,就会开出container,具体运行任务。
2.1.5 MapReduce架构概述
MapReduce的话,这里就不过多整理了,既然他是解决数据计算的问题, 那么怎么高效利用多台机器计算呢? 这里知道它会有两个阶段:
- Map: 把任务分发到每台机器上去做运算, 并行处理输入数据
- Reduce: 对各个机器上Map的结果汇总返回
2.1.6 HDFS、YARN、MapReduce三者关系
这里需要先初步了解,在Hadoop的整体框架下面,这个组件时如何配合工作,去完成大数据的存储计算的。 大致内容如下:

客户提交一批任务, 首先会先到ResourceManager, 说想跑一个任务, 此时RM会找一个节点, 在上面先开一个AM, 把这个任务交给他, AM拿到任务之后,看下运行这个任务需要多少资源(内存,cpu), 此时AM向RM提出申请所需要的资源, RM拿到申请之后哦,就去整个集群里面看看哪些节点能有资源跑这个任务, 找到之后,再节点上开启container跑任务,这时候,每个container就各自独立的进行计算等,这个就是map阶段,等各个container计算完了,会把结果汇总到某个container,这个时reduce节点,汇总完之后,写入到磁盘,此时HDFS开始工作,DataNode负责存储数据,NameNode负责记录这份数据的元信息,而2NN负责间隔备份NN。
2.2 Why
Hadoop的优势(4高):
- 高可靠:底层维护多个数据副本,即使Hadoop某个计算元素或者存储出现故障, 也不会导致数据丢失, 也就是一份数据,会存储到多台机器

- 高扩展性: 集群间分配任务数据, 可方便扩展数以千计的节点(动态增加, 动态删除)

- 高效性:在MapReduce的思想下,Hadoop并行工作,加快任务处理速度

- 高容错性:能够自动将失败任务重新分配

3. 环境准备与安装
大数据环境的安装在学校的时候,其实也搞过一遍,3台虚拟机, 把多个组件的安装走了一个遍,这里就不记录这么细了,只记录点新的东西。
3.1 环境变量配置新知识
之前配置环境变量的时候, 一般是在/etc/profile中直接配置, export a = …:$PATH, 但到公司之后,我发现一般不会在这里面直接配置了,而是通过里面的几行代码:

这个是会遍历/etc/profile.d下面的所有.sh结尾的文件,然后让里面的变量全局生效。 所以,配置环境遍历的时候,可以在这个profile.d下面新建一个.sh脚本,然后在这里面创建环境变量
cd /etc/profile.d
vim bigdata_env.sh
# 在这里面输入
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0
export PATAH=$PATH:JAVE_HOME
....
# 环境变量生效
source /etc/profile
这样,可以分类整理变量。
3.2 Hadoop目录
这里了解下Hadoop目录下面的每个目录文件的作用

- bin目录: 和hdfs, yarn, mapred启动的命令, 这个很重要,并且需要配置到环境变量中
- etc目录: 里面大量的配置信息,
hdfs-site.xml, mapred-site.xml, core-site.xml, yarn-site.xml, 这个也很重要 - include目录: 大量头文件, 一般用不到
- lib和libexec: 动态链接库, 扩展包等,一般用不到
- sbin: 这个里面包含启动组件的命令,常用的
start-all.sh, stop-all.sh, 或者单独启动每个组件等,这个也很重要,需要配置到环境变量中 - share目录: 提供学习资料, 说明文档以及案例jar包等
3.3 Hadoop运行模式
Hadoop三种运行模式:
- local模式: 数据存储到Linux本地
- 伪分布式模式: 数据存储到HDFS
- 完全分布式: 数据存储到HDFS, 多台服务器工作
3.4 本地模式:官方wordcount案例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ ./wcoutput
- 必须有输入路径和结果输出路径
- 如果结果输出路径存在,会抛异常
4. Hadoop集群模式搭建(重点)
hadoop集群模式,一般是非常重要的,只有亲自搭几遍集群,才能对整体架构有一定的了解, 虽然我之前已经搭建好一遍,但是这次我又重新走了一遍,因为这里Hadoop是3.x版本,之前那个有些老,另外就是为了再熟悉下整个过程,这里就不详细记录了,但至少得知道搭建hadoop集群一般需要的步骤。我这里简单总结下:
- 首先得有N台机器作为节点,我这里是用了3台虚拟机,每台虚拟机上得需要配置主机名,内网ip地址,这两个是为了能保证内部集群的机器进行通信
- 然后每台机器上得安装jdk, hadoop, 这个实际操作的时候,一般是一台机器里面安装好,然后通过脚本分发到其他机器上,于是乎,又涉及到了脚本分发与ssh免密登录
- 每台机器把jdk和hadoop安装完之后,接下来就是修改hadoop etc下面的相关配置,让这几台机器能协调工作
这个是基本流程, 具体细节的话,下面展开说说。
4.1 文件分发
一般从一台服务器把节点配置好,然后写分发脚本把hadoop和java等分发到其他机器上去。所以这里就涉及到了文件分发命令。常用的两个:
-
scp: 用于集群之间文件或者目录拷贝,常用
scp -r $pdir/$fname(源地址) $user@$host:$pdir/$fname(目标地址) -
rsync: 用于文件同步, 和上面命令的区别就是只更新发生变更的文件,而不是所有的都拷贝了
rsync -av $pdir/$fname(源地址) $user@$host:$pdir/$fname(目标地址)第一次分发可以用scp,以后更改,就可以用rsync, 效率会比较高。
-
xsync集群分发脚本
这里整理一个集群文件同步的一个脚本,执行这个脚本之后,循环复制文件到所有节点的相同目录下(一键同步)。vim ~/bin/xsync#! /bin/bash # 1. 判断参数个数 如果小于1, 直接退出 if [ $# -lt 1 ] then echo Not Enought Argument! exit; fi # 遍历集群所有机器i for host in hadoop102 hadoop103 hadoop104 do echo ==============================$host============================ # 遍历命令里面的所有文件@貌似是接受过来的命令参数,依次发送 for file in $@ do # 如果文件在本机上存在, 分发到别的机器上 if [ -e $file ] then # 获取父目录 -P表示,如果有软连接的文件,得到的还是原先的文件 dirname会得到文件的父目录 pdir=$(cd -P $(dirname $file); pwd) # 获取当前文件的名称basename名称 fname=$(basename $file) # 这里配置了ssh免密连接,所以ssh host到了另一台主机,然后创建父目录,-p是如果存在也不会报错 ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done donechmod 777 xsync, 如果普通用户直接用某个命令,可以在自己的加目录中创建一个bin,然后把命令或者脚本放到那里面,这时候该用户就可以直接使用命令了,但是切换成root之后, 用不了,因为那时候找的是root家目录的bin,显然那里面没有这个命令。# 如果往其他机器分发的时候,报错没有权限,可以用sudo, 但是sudo的时候,需要加脚本命令的绝对路径 # 尤其是分发环境变量 sudo ./bin/xsync /etc/profile.d/my_env.sh # 分发完环境变量之后, 记得在其他机器上source下,否则环境变量还是不生效, 感觉这个也可以写个脚本
4.2 ssh免密登录
之前ssh免密登录不知道原理,这里整理下

不管是在搭建hadoop集群,还是之前在配置git的时候,往往都会设置一个免密登录的操作,之前没有留意到为啥,背后起作用的原因是啥,这次学习偶然了解了下两个服务器之间通信的一个原理。这里以配置git免密登录为例子,把上述过程写一遍。
我们在使用github的时候,一般本地配置好用户名和密码之后, 会配置个ssh免密登录,
- 执行的ssh-key-gen命令,在本地.ssh目录下,此时就会生成一个公钥,一个私钥
- 我们会把这个公钥的内容,复制到github的ssh keys下面
- 这时候, 当我们本地访问github的时候,请求或者数据会用本地的私钥A加密,然后上传到github
- github收到数据之后,就去授权key中找本地上传过去的公钥对数据解密,如果找不到,就报没有权限
- 解密之后,拿到请求,然后发送数据的时候,用公钥A进行加密,传到本地来
- 本地拿到数据,再用私钥A解密,拿到数据
这样,就完成了ssh的加密传输过程
所以,如果是想集群中各个机器之间互相用ssh访问,如果不配置免密登录的话,就得每次传个文件啥的,都需要对方机器的登录密码, 贼麻烦,所以这个东西还是要配置下的。
如果要配置, hadoop102免密访问103和104, 就需要在102上, ssh先生成公钥
ssh-keygen -t rsa
# 这时候.ssh目录下面会多出一个id_rsa和id_rsa.pub来
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
# 这样就实现了102免密登陆其他机器, 此时103和104的.ssh目录下面,会多出一个authorized_keys目录, 记录的就是可以访问此机器的公钥
# 如果想在103和104上也可以免密访问彼此,和102同样的操作也来一遍
如果此时在102切换到root, 就会发现登陆103和104,依然是需要密码。所以这个ssh免密登陆是针对某个具体用户的。
4.3 集群配置
这是此次集群搭建的重头戏,这里学习到的新经验,就是搭建hadoop集群之前,要先进行设计规划,主要是看看NameNode放到哪个节点, DataNode放到哪里,ResourceManager放到哪个节点,NodeManager放到哪, 2NN放到哪里等。之前我搭建的时候,一股脑把3个加粗大哥放到一个机器上了,原来这样做是不好的。

部署规划:
- NameNode和SecondaryNameNode不要安装在同一台服务器,因为两个东西都比较耗内存
- ResourceManager也非常耗内存,不要和NameNode, SecondaryNameNode配置到同一台机器
先有了这样的一个部署,下面修改配置文件的时候,就能相应的进行部署修改了。这里的另外一个点就是: Hadoop配置文件有两类: 默认配置文件和自定义配置文件, 只有用户想修改某一默认配置的时候, 才需要修改自定义配置文件,更改相应属性。
自定义配置文件,主要只得就是hadoop/etc下面的几个关键配置文件:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml, 根据上面的集群规划,这里我们进行配置。 配置的思路,是在hadoop102上配置好,然后用分发脚本分发到103和104即可。
-
配置core-site.xml
在hadoop102上,配置core-site.xml, 这里面可以指定hdfs NameNode的地址,和hdfs的存储目录等<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为icss--> <property> <name>hadoop.http.staticuser.user</name> <value>icss</value> <!-- 有了这个,才能直接在hdfs网页上进行删除文件或者目录操作,否则没权限 --> </property> </configuration>这里指定hdfs NameNode的地址,按照上面那个图来,默认的话是file:///,我们这里设置成hdfs://hadoop102:8020,即把hdfs的namenode放到hadoop102上, hadoop的存储目录设置,默认是/tmp/, 这个文件在linux是有时间限制的,所以需要手动配置目录
-
配置hdfs-site.xml
上面配置namenode的地址相当于一个内部访问的地址(内部模块之间访问),这里还需要配置一个web用户上访问namenode的接口,这样就可以从web页面就可以进行访问,不需要从命令行访问。这个文件主要是配置NameNode和2NN的web页面访问地址。<configuration> <!-- nn web端访问地址 --> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration> -
配置Yarn-site.xml
指定MR, ResourceManager的地址,环境变量继承这里是3.1.x版本的一个bug, 3.2上就没有这个问题了。这里需要额外加上HADOOP_MAPRED_HOME, 默认的里面没有这个环境变量<configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration> -
配置mapred-site.xml
这里指定mapreduce程序走yarn,其实也可以走别的资源调度,默认的话是本地local调度。<configuration> <!-- 指定MapReduce程序走Yarn --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>102上配置好以后, 分发到103和104
xsync hadoop/ -
配置workers节点
这个是3.x和2.x的一个不同点,在2.x里面不是指定workers, 那时候还叫slaves, 为了避免歧视, 这里把所有节点都统称为workers, 这个是hadoop目录下面的workers目录,vim workers, 然后输入,不要有空格和空行hadoop102 hadoop103 hadoop104这里的输入时三台节点的主机名字,然后,分发到每个节点
xsync workers
4.4 集群启动
如果集群是第一次启动,需要在hadoop102节点格式化NameNode
hdfs namenode -format
此时,初始化完成, 在hadoop102的hadoop的总目录下面会多出两个目录: data和logs,进入到/opt/module/hadoop-3.1.3/data/dfs/name/current,里面有个VERSION文件,cat看下,这里面就记录了集群的相关信息,版本号啥的
namespaceID=1937245237
clusterID=CID-b62fd8a6-0686-44b4-8a4e-88dde7336013
cTime=1670748093796
storageType=NAME_NODE
blockpoolID=BP-1316835940-192.168.56.102-1670748093796
layoutVersion=-64
来到sbin目录, 启动hdfs
sbin/start-dfs.sh
来到hadoop102虚拟机,打开浏览器,输入hadoop102:9870,就能查看HDFS上存储的数据信息

在配置了ResourceManager的节点(hadoop103)上启动YARN
sbin/start-yarn.sh
在hadoop103机器的浏览器,输入网址hadoop103:8088, 查看YARN上运行的Job信息

4.5 集群测试
4.5.1 测试hdfs
来到hadoop102,使用命令在hdfs上创建一个目录
hadoop fs -mkdir /input
hadoop fs -put input/word.txt /input
此时去hdfs页面就能看到有目录出现,里面就会有work.txt

那么,这里的一个疑问是, web页面的这些数据是怎么来的呢? 或者说hdfs上的数据是存储到本地的哪里了呢? 这里的块大小是当前数据块的大小,允许存储的数据上限128MB.
答: 配置hdfs的时候,我们指定了hadoop数据的一个存储目录,就是hadoop-3.1.3下面的data目录下,hdfs初始化的时候,也初始化好了这个data目录,所以hdfs上的数据就是存储到了这里面,一层层的进入
cd data/dfs/data/current/BP-1316835940-192.168.56.102-1670748093796/current/finalized/subdir0/subdir0
这里面,会看到两个文件

并且在hadoop103和hadoop104这个对应的路径下面,也各自有这两个文件, 即存储了数据的副本,这样即使102的datanode挂了, 数据依然还在。这样, 数据的Replication就是3,存储了3份。
这里记录一个集群崩溃处理方法: 如果误操作把hadoop102下面的data目录误删除掉了,就会删除掉集群的NameNode,此时如果直接执行格式化集群命令,会发现NameNode没了,即这时候会出现NameNode的启动错误。 这是因为,每次初始化一个新集群的时候, NameNode和DataNode都会有一个当前新集群的一个集群ID标识,只有两个匹配起来,两者才能正常工作,这个在data/dfs/name/current/VERSION和data/dfs/data/current/VERSION中能看到
如果假设集群崩溃了,直接格式化格式化NameNode, 就会在NameNode上产生新的集群id,而此时的DataNode的版本还是之前的,就导致NameNode和DataNode的集群id不一致,新集群的NameNode上无法访问老集群上的DataNode的数据,此时新进群的NameNode就会启动失败。
所以如果集群在运行过程中抱错,需要重新格式化NameNode的话,一定要先停止namenode和datanode的进程,并且删除所有机器的data和logs的目录(老机器上的数据),然后再进行格式化。


4.5.2 测试YARN
集群里面有了word.txt,这里用集群模式搞一个wordcount,看看集群中节点的工作情况, hadoop102上
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /wcoutput
这时候,来到hadoop103上的web界面,看执行情况,就发现多了一个任务

如果看hdfs的数据,会发现多出来一个wcoutput目录,里面就是统计单词的结果文件。
4.5.3 配置历史服务器
历史服务器是这样,上面运行的这个程序页面,当wordcount程序运行完之后,刷新上面这个界面,就会发现后面Tracking UI那里变成一个history

此时,如果点击History,就会出现链接错误,这是因为历史服务器没有配置,这说明,我们现在是没法看到之前运行完的任务的执行情况的。而如果我们希望查看跑完的任务的一个历史执行情况,就需要历史服务器的配置。
配置历史服务器,hadoop102上来到mapred-site.xml中, 加入下面参数即可。
- 历史服务器端地址: 内部模块与模块通信的一个地址和端口
- 历史服务器web端地址: 用户与模块交互的一个web地址和端口
<configuration>
<!-- 指定MapReduce程序走Yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
分发到其他节点xsync hadoop/, 重启yarn, 然后在hadoop102启动历史服务器
bin/mapred --daemon start historyserver
jps看是否历史服务器启动, 查看JobHistory: 网址输入hadoop102:19888
# 再次运行wordcount程序
# 此时程序运行完点击History的话,就能自动跳到上面这个网址里面去了

但是,这里面如果想看详细具体的聚集日志,也就是点击logs,会出现也给报错:

这个的原因是因为,目前集群还没有配置日志的聚集,这个概念是说: 应用运行完之后,会将程序的运行日志上传到HDFS系统上去。 如果没有配置,就没有上传,此时在页面上就读不到.

日志聚集功能的好处: 可以方便的查看程序运行详情, 方便开发调试。
注意: 开启日志聚集功能,需要重新启动NodeManager, ResourceManager和HistoryServer。
4.5.4 配置日志聚集功能
在hadoop102的yarn-site.xml中加入下面的配置信息:
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能更 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
分发到103和104上去。
关闭yarn以及历史服务器,然后重新开。
mapred --daemon stop historyserver
sbin/stop-yarn.sh
mapred --daemon start historyserver
sbin/start-yarn.sh
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /wcoutput
再执行wordcount程序,此时进入历史服务器点击Logs,就能看到程序的实际运行日志了。
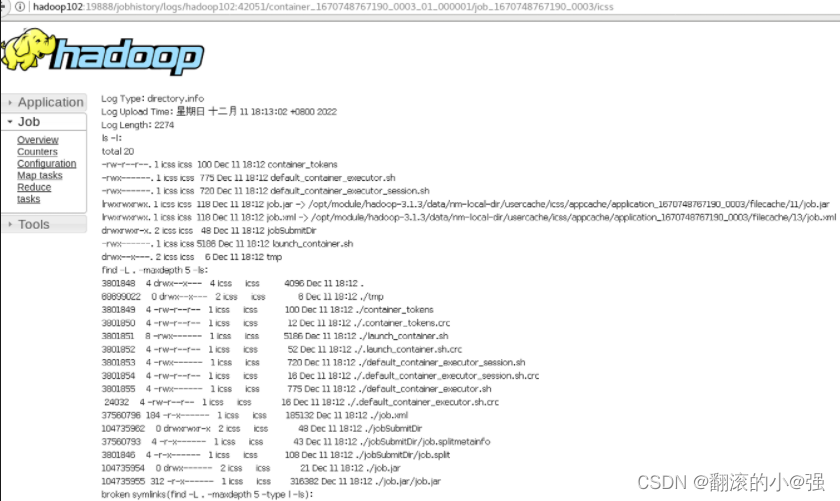
这时候,程序过程中如果抛异常,就能快速定位位置了。
4.5.5 集群启动/停止方式总结
# 整体启动/停止hdfs
start-dfs.sh/stop-dfs.sh
# 整体启动/停止yarn
start-yarn.sh/stop-yarn.sh
# 分别启动/停止hdfs组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
# 启动/停止yarn组件
yarn --daemon start/stop resourcemanager/nodemanager
5. 其他
5.1 集群相关的两个常用脚本
这里记录两个集群相关的脚本,第一个就是一键开启集群和关闭集群, ~/bin目录下面新建my_hadoop,然后编写脚本
#! /bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit;
fi
case $1 in
"start")
echo "======================== start hadoop cluster =========================="
echo "------------------------ start hdfs ------------------------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo "----------------------- start yarn -------------------------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo "---------------------- start historyserver ----------------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo "======================= stop hadoop cluster =========================="
echo "----------------------- stop historyserver---------------------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo "----------------------- stop yarn -------------------------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo "---------------------- stop hdfs ----------------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
chmod a+x给它。
第二个是一键查看每个节点上的节点是否正常开启,~/bin目录新建jpsall,写脚本
#! /bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo ====================== $host =============================
ssh $host jps
done
chmod a+x给它,然后xsync bin目录给到其他节点机器即可。
5.2 两道面试题
这里记录两道面试题

5.3 集群时间同步
时间同步的意义在于,如果在集群中起定时任务跑的时候,如果多台机器的时间不一样,就会导致问题。
生产环境: 如果服务器能连接外网,不需要时间同步,此时所有机器会定时和外网的时间保持同步

如果服务器不能连接外网,就需要让所有机器进行时间同步, 这时候,以hadoop102为基准,hadoop103和hadoop104定时的和102的时间同步即可。由于虚拟机都能连接外网,这里就不设置了,简单记录下如果进行时间同步的话,应该怎么做.
首先, hadoop102上做下面操作:时间服务配置(必须是root用户)
# 查看所有节点的ntpd服务状态和开机自启动状态
sudo systemctl status ntpd
sudo systemctl start ntpd
sudo systemctl is-enabled ntpd
配置hadoop102的ntp.conf配置文件
sudo vim /etc/ntp.conf
修改:

在这个文件的末尾添加下面两行代码: 当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
server 127.127.1.0
fudge 127.127.1.0 stratum 10
修改hadoop102的/etc/sysconfig/ntpd文件,增加下面内容,让硬件时间和系统时间一起同步,一般硬件的时间会更准一些
sudo vim /etc/sysconfig/ntpd
# 增加
SYNC_HWCLOCK=yes
# 重启ntpd服务
sudo systemctl start ntpd
# 设置开机启动
sudo systemctl enable ntpd
这样,在102上就设置完了基准时间服务器, 接下来就是103和104上的时间与102定时对齐逻辑。
# 关闭103和104上的ntp服务和自启动,这个是防止与外界互联网进行时间同步,总不能一会和102时间同步,一会和外网时间同步
# 103和104执行下面命令
sudo systemctl stop ntpd
sudo systemctl disable ntpd
# 在103和104上配置1分钟与102的时间服务器同步一次
sudo crontab -e
# 编写定时任务如下
*/1 * * * * /usr/sbin/ntpddate hadoop102
# hadoop103上修改下机器时间
sudo date -s "2022-09-11 11:11:11"
# 103上1分钟后查看机器是否和102的时间服务同步
sudo date
6. 小总
这节课主要整理的与hadoop入门的相关知识,概述部分可以简单对hadoop做一个大致了解,其他的就是偏动手实践居多, 主要是hadoop集群环境搭建这里,需要亲自上手去搭才会有感觉,这里我其实做了简化,再后面,就是一些可以提升日常开发效率的一些脚本啥的了。
我觉得这里面的重点内容:
- hadoop的组件以及怎么协调工作的
- hadoop集群环境搭建的步骤: 这个面试可能会问到,怎么搭的集群? 修改的什么配置文件,每个配置文件都是干啥的?
- hadoop集群崩溃处理的方法, 为什么这么处理?
- hadoop里面用到的端口号
这篇文章作为入门,知识量并不是太多,零零散散,我也花了两三周的时间才看完入门篇, 主要是平时时间配置的不是很合理,每天抽不出空来自我学习,另外一个原因是上周被病毒袭击了一下, 身体不大行,不怎么想学, 后面尽量还是保持最多两周一更的进度吧。
下一篇,走进HDFS,去看看这里面的细节和原理, 海量数据在HDFS的运算下究竟是怎么存的? NameNode和DataNode又是怎么配合, 2NN在这里面到底在干啥?等。










![Jenkins自动部署springboot的Docker镜像,解决Status [1]问题](https://img-blog.csdnimg.cn/0881ab6b311144fbbca40e305edee5d1.png)