推荐:使用 NSDT场景编辑器快速搭建3D应用场景
世界被人工智能 (AI) 所吸引,尤其是自然语言处理 (NLP) 和生成 AI 的最新进展,这是有充分理由的。这些突破性技术有可能提高各种任务的日常生产力。例如,GitHub Copilot帮助开发人员快速编写整个算法,OtterPilot自动生成高管会议记录,Mixo允许企业家快速启动网站。
本文将简要概述生成式 AI,包括相关的 AI 技术示例,然后通过生成式 AI 教程将理论付诸实践,我们将使用 GPT 和扩散模型创建艺术渲染。

作者的六张 AI 生成的图像,使用本教程中的技术创建。
生成式 AI 的简要概述
注意:熟悉生成式 AI 背后的技术概念的人可以跳过本节并继续学习本教程。
2022 年,许多基础模型实现进入市场,加速了许多领域的人工智能进步。在了解了几个关键概念之后,我们可以更好地定义基础模型:
- 人工智能是一个通用术语,描述任何可以智能地完成特定任务的软件。
- 机器学习是人工智能的一个子集,它使用从数据中学习的算法。
- 神经网络是机器学习的一个子集,它使用以人脑为模型的分层节点。
- 深度神经网络是具有许多层和学习参数的神经网络。
基础模型是在大量原始数据上训练的深度神经网络。在更实际的术语中,基础模型是一种非常成功的人工智能类型,可以轻松适应和完成各种任务。基础模型是生成式 AI 的核心:文本生成语言模型(如 GPT)和图像生成扩散模型都是基础模型。
文本:自然语言处理模型
在生成式 AI 中,自然语言处理 (NLP) 模型经过训练,可以生成读起来好像由人类撰写的文本。特别是,大型语言模型(LLM)与当今的AI系统特别相关。LLM根据其对大量数据的使用进行分类,可以识别和生成文本和其他内容。
在实践中,这些模型可以用作写作甚至编码助手。自然语言处理应用程序包括简单地重述复杂概念,翻译文本,起草法律文件,甚至创建锻炼计划(尽管此类用途有一定的局限性)。
Lex 是具有许多功能的 NLP 写作工具的一个例子:提出标题、完成句子以及就给定主题撰写整个段落。目前最容易识别的LLM是GPT。GPT 由 OpenAI 开发,可以在几秒钟内以高精度响应几乎任何问题或命令。OpenAI的各种模型都可以通过单个API获得。与 Lex 不同,GPT 可以处理代码、根据功能需求对解决方案进行编程以及识别代码内问题,从而使开发人员的生活更加轻松。
图像:AI 扩散模型
扩散模型是一种深度神经网络,它包含潜在变量,能够通过消除模糊(即噪声)来学习给定图像的结构。在训练模型的网络以“知道”图像背后的概念抽象后,它可以创建该图像的新变体。例如,通过消除猫图像中的噪声,扩散模型“看到”猫的干净图像,了解猫的外观,并应用这些知识来创建新的猫图像变体。
扩散模型可用于去噪或锐化图像(增强和完善它们),操纵面部表情或生成面部老化图像,以暗示一个人随着时间的推移可能会如何看待。您可以浏览 Lexica 搜索引擎,见证这些 AI 模型在生成新图像方面的强大功能。
教程:扩散模型和 GPT 实现
为了演示如何实现和使用这些技术,让我们练习使用 HuggingFace 扩散模型和 GPT 生成动漫风格的图像,这两者都不需要任何复杂的基础设施或软件。我们将从一个现成的模型(即已经创建和预先训练的模型)开始,我们只需要对其进行微调。
注意:本文介绍了如何使用生成式 AI 图像和语言模型以有趣的风格创建自己的高质量图像。本文中的信息不应(误)用于违反 Google Colab 使用条款创建深度伪造。
设置和照片要求
要准备本教程,请在以下位置注册:
| 谷歌 | 使用云端硬盘和 Colab。 |
| 开放人工智能 | 进行 GPT API 调用。 |
您还需要将 20 张自己的照片(甚至更多照片)保存在您计划用于本教程的设备上,以提高性能。为获得最佳效果,照片应:
- 不小于 512 x 512 像素。
- 属于你,也只属于你。
- 具有相同的扩展格式。
- 从各种角度拍摄。
- 至少包括三到五次全身镜头和两到三次中身镜头;其余的应该是面部照片。
也就是说,照片不需要完美——看看偏离这些要求如何影响输出甚至会很有启发性。
使用拥抱人脸扩散模型生成 AI 图像
要开始使用,请打开本教程的配套 Google Colab 笔记本,其中包含所需的代码。
- 运行单元格 1 将 Colab 与您的 Google 云端硬盘连接,以存储模型并在以后保存其生成的图像。
- 运行单元 2 以安装所需的依赖项。
- 运行单元格 3 以下载拥抱面模型。
- 在单元格 4 中,在字段中键入“我的外观”,然后运行该单元格。会话名称通常标识模型将学习的概念。
Session_Name - 运行单元格 5 并上传您的照片。
- 转到单元格 6 以训练模型。通过在运行单元之前选中该选项,可以多次重新训练它。(此步骤可能需要大约一个小时才能完成。
Resume_Training - 最后,运行单元格 7 以测试模型并查看其运行情况。系统将输出一个URL,您可以在其中找到生成图像的界面。输入提示后,按“生成”按钮以渲染图像。
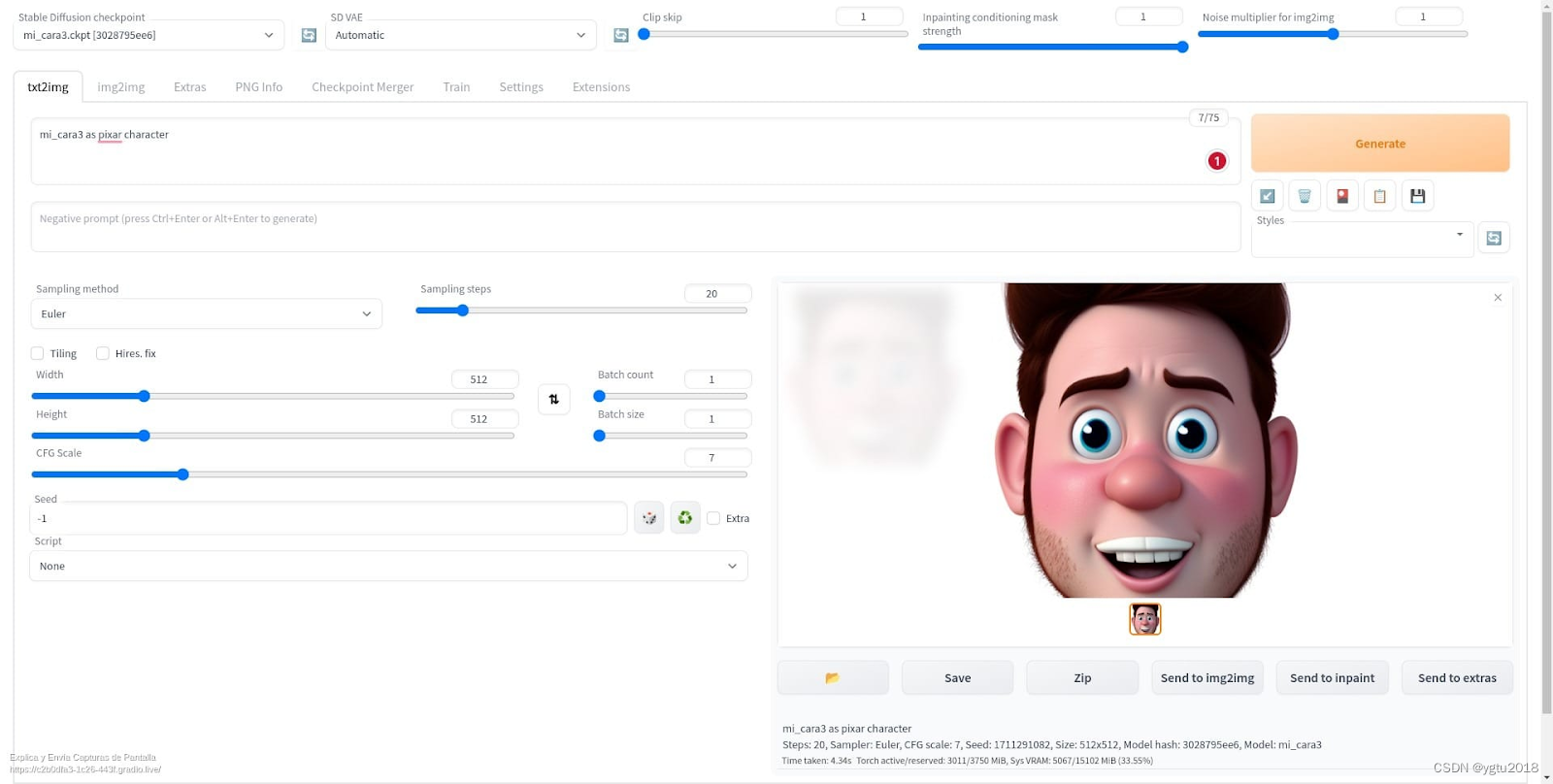
用于生成图像的用户界面
有了工作模型,我们现在可以尝试各种提示,产生不同的视觉风格(例如,“我作为一个动画角色”或“我作为一个印象派绘画”)。但是,将 GPT 用于字符提示是最佳的,因为与用户生成的提示相比,它可以产生更多细节,并最大限度地发挥模型的潜力。
使用 GPT 进行有效扩散模型提示
我们将通过 OpenAI 将 GPT 添加到我们的管道中,尽管 Cohere 和其他选项为我们的目的提供了类似的功能。首先,在 OpenAI 平台上注册并创建您的 API 密钥。现在,在 Colab 笔记本的“生成良好的提示”部分,安装 OpenAI 库:
pip install openai
接下来,加载库并设置 API 密钥:
import openai
openai.api_key = "YOUR_API_KEY"
我们将从 GPT 生成优化的提示,以动漫角色的风格生成我们的图像,替换为笔记本单元格 4 中设置的会话名称“我的样子”:YOUR_SESSION_NAME
ASKING_TO_GPT = 'Write a prompt to feed a diffusion model to generate beautiful images '\
'of YOUR_SESSION_NAME styled as an anime character.'
response = openai.Completion.create(model="text-davinci-003", prompt=ASKING_TO_GPT,
temperature=0, max_tokens=1000)
print(response["choices"][0].text)
该参数的范围介于 0 和 2 之间,它确定模型是应严格遵守其训练的数据(值接近 0),还是对其输出更具创造性(值接近 2)。该参数设置要返回的文本量,四个标记相当于大约一个英语单词。temperaturemax_tokens
就我而言,GPT 模型输出如下:
"Juan is styled as an anime character, with large, expressive eyes and a small, delicate mouth.
His hair is spiked up and back, and he wears a simple, yet stylish, outfit. He is the perfect
example of a hero, and he always manages to look his best, no matter the situation."
最后,通过将此文本作为输入输入到扩散模型中,我们实现了最终输出:

让 GPT 编写扩散模型提示意味着您不必详细考虑动漫角色外观的细微差别——GPT 将为您生成适当的描述。您可以随时根据口味进一步调整提示。完成本教程后,您可以创建自己的复杂创意图像或您想要的任何概念。
人工智能的优势触手可及
GPT 和扩散模型是两个基本的现代 AI 实现。我们已经看到了如何单独应用它们,并通过配对它们来乘以它们的功率,使用 GPT 输出作为扩散模型输入。在此过程中,我们创建了一个由两个大型语言模型组成的管道,这些模型能够最大限度地提高它们自己的可用性。
原文链接:人工智能的优势:使用 GPT 和扩散模型生成图像 (mvrlink.com)









![[构建 Vue 组件库] 小尾巴 UI 组件库 —— 横向商品卡片(仿淘宝)](https://img-blog.csdnimg.cn/img_convert/c22d71652804b2d0334c083f30f51a93.png)