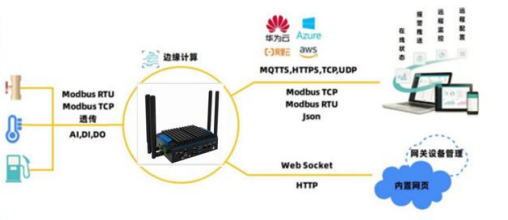
一、实现CenterNet图像分割算法模型的转换和量化(SDK0301-转ONNX编译)
1、模型转换
(1)下载CenterNet算法移植代码:
$ git clone https://github.com/sophon-ai-algo/examples.git
# CenterNet示例项目代码位置 /examples/simple/centernet
$ cd examples/simple/centernet
获取主干网的预训练模型,运行如下命令下载 dlav0 作为主干网的预训练模型:
$ cd data
# 下载 ctdet_coco_dlav0_1x.pth 模型文件到路径 centernet/data/bulid 目录下
$ ./scripts/download_pt.sh
(2)将pth文件转换为ONNX格式模型
【SDK 230501版本后支持Torch模型权重直接转换】
$ cd /bulid
$ vi export_onnx.py
#将以下信息写入py文件中
from model import create_model, load_model
import torch
if __name__ == '__main__':
num_classes = 80
head_conv = 256
heads = {'hm': num_classes,
'wh': 2 ,
'reg': 2}
device = 'cpu'
load_model_path = 'ctdet_coco_dlav0_1x.pth'
#save_script_pt = 'ctdet_coco_dlav0_1x.torchscript.pt'
model = create_model('dlav0_34', heads, head_conv)
model = load_model(model, load_model_path)
model = model.to(device)
model.eval()
#input_var = torch.zeros([1, 3, 512, 512], dtype=torch.float32)
#traced_script_module = torch.jit.trace(model, input_var)
#traced_script_module.save(save_script_pt)
#traced_script_module = torch.jit.load(save_script_pt)
#print('{} exported'.format(save_script_pt))
# Prepare input tensor
input = torch.randn(1, 3, 512, 512, requires_grad=True)
# Export the torch model as onnx
torch.onnx.export(model,
input,
'centernet.onnx', # name of the exported onnx model
opset_version=13,
export_params=True,
do_constant_folding=True)
#将保存的py文件运行
$ python3 export_onnx.py
# 输出信息:
[DEBUG]arch is: dlav0
loaded ctdet_coco_dlav0_1x.pth, epoch 140
#centernet.onnx文件生成在路径 ${centernet}/data/models 下


(3)ONNX转换MLIR模型
如果模型是图片输入, 在转模型之前我们需要了解模型的预处理。如果模型用预处理后的npz文件做输入, 则不需要考虑预处理。参考yolov5s的rgb图片,mean和scale对应为 0.0,0.0,0.0 和 0.0039216,0.0039216,0.0039216 。
模型转换命令如下:
$ mkdir workspace && cd workspace
$ vi onnx2mlir.sh
#将下面的运行指令写入sh文件,方便复现和整理代码
$ model_transform.py \
--model_name centernet \
--model_def ../centernet.onnx \
--input_shapes [[1,3,512,512]] \
--mean 0.0,0.0,0.0 \
--scale 0.0039216,0.0039216,0.0039216 \
--keep_aspect_ratio \
--pixel_format rgb \
--test_input ../../images/000000000139.jpg \
--test_result centernet_top_outputs.npz \
--mlir centernet.mlir \
#--post_handle_type yolo 此参数可以不加,不进行后处理,防止后边的npz文件compare时报错
$ sh onnx2mlir.sh


最终生成文件如下:

(4)MLIR转换F32模型
将mlir文件转换成f32的bmodel, 操作方法如下:
$ vi mlir2f32.sh
#将下列命令写入到mlir2f32.sh文件中,这样方便日后代码复现
model_deploy.py \
--mlir centernet.mlir \
--quantize F32 \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \ #这一步的test_reference要和上一步的test_result保持一致
--tolerance 0.99,0.99 \
--model centernet_1684x_f32.bmodel
$ sh mlir2f32.sh


最终生成文件如下:

(5)MLIR转INT8模型
生成校准表
转INT8模型前需要跑calibration, 得到校准表; 输入数据的数量根据情况准备100~1000张左右。
然后用校准表, 生成对称或非对称bmodel。如果对称符合需求, 一般不建议用非对称, 因为 非对称的性能会略差于对称模型。
这里用现有的200张coco的val2017的图片举例, 执行calibration:
$ vi cali_table.sh
# 将下列命令写入sh文件中,这样做方便日后命令复现
run_calibration.py centernet.mlir \
--dataset ../../images \
--input_num 200 \
-o centernet_cali_table
$ sh cali_table.sh


编译为INT8对称量化模型
转成INT8对称量化模型, 执行如下命令:
$ vi mlir2int8.sh
model_deploy.py \
--mlir centernet.mlir \
--quantize INT8 \
--calibration_table centernet_cali_table \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \
--tolerance 0.85,0.45 \
--model centernet_1684x_int8_sym.bmodel
$ sh mlir2int8.sh
转换过程输出内容如下:

最终生成文件如下:

编译为INT8非对称量化模型
转成INT8非对称量化模型, 执行如下命令:
$ model_deploy.py \
--mlir centernet.mlir \
--quantize INT8 \
--asymmetric \
--calibration_table centernet_cali_table \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \
--tolerance 0.90,0.55 \
--model centernet_1684x_int8_asym.bmodel
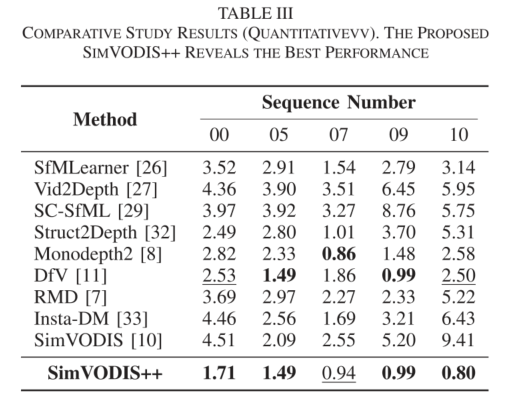
2、效果对比与性能测试-1684X PCIE
进入centernet模型仓库中py文件所在位置,运行测试bmodel检测结果
#进入centernet模型python文件位置
$ cd /Release_230301-public/examples/simple/centernet/py_bmcv_sail
#效果测试
$ python det_centernet_bmcv_sail_1b_4b.py --input ../data/ctdet_test.jpg --bmodel ../data/build/workspace/centernet_1684x_f32.bmodel


预测图片结果并查看:


bmodel性能测试
安装好 libsophon 后, 可以使用 bmrt_test 来测试编译出的 bmodel 的正确 性及性能。可以根据 bmrt_test 输出的性能结果, 来估算模型最大的fps, 来选择合适的模型。
#进入到bmodel所在文件夹位置
$ cd /Release_230301-public/examples/simple/centernet/data/build/workspace
bmrt_test --bmodel centernet_1684x_f32.bmodel #以f32的bmodel为例,也可以测试int8等
#输出信息
[BMRT][deal_with_options:1446] INFO:Loop num: 1
[BMRT][bmrt_test:723] WARNING:setpriority failed, cpu time might flutuate.
[BMRT][bmcpu_setup:349] INFO:cpu_lib 'libcpuop.so' is loaded.
bmcpu init: skip cpu_user_defined
open usercpu.so, init user_cpu_init
[BMRT][load_bmodel:1079] INFO:Loading bmodel from [centernet_1684x_f32.bmodel]. Thanks for your patience...
[BMRT][load_bmodel:1023] INFO:pre net num: 0, load net num: 1
[BMRT][show_net_info:1463] INFO: ########################
[BMRT][show_net_info:1464] INFO: NetName: centernet, Index=0
[BMRT][show_net_info:1466] INFO: ---- stage 0 ----
[BMRT][show_net_info:1475] INFO: Input 0) 'input.1' shape=[ 1 3 512 512 ] dtype=FLOAT32 scale=1 zero_point=0
[BMRT][show_net_info:1485] INFO: Output 0) '515_Concat' shape=[ 1 84 128 128 ] dtype=FLOAT32 scale=1 zero_point=0
[BMRT][show_net_info:1488] INFO: ########################
[BMRT][bmrt_test:782] INFO:==> running network #0, name: centernet, loop: 0
[BMRT][bmrt_test:868] INFO:reading input #0, bytesize=3145728
[BMRT][print_array:706] INFO: --> input_data: < 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... > len=786432
[BMRT][bmrt_test:1005] INFO:reading output #0, bytesize=5505024
[BMRT][print_array:706] INFO: --> output ref_data: < 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... > len=1376256
[BMRT][bmrt_test:1039] INFO:net[centernet] stage[0], launch total time is 55216 us (npu 55135 us, cpu 81 us)
[BMRT][bmrt_test:1042] INFO:+++ The network[centernet] stage[0] output_data +++
[BMRT][print_array:706] INFO:output data #0 shape: [1 84 128 128 ] < -5.44699 -6.73102 -8.15043 -8.61082 -9.36364 -9.72045 -10.5258 -10.805 -11.3242 -11.2517 -11.8261 -11.7891 -12.2917 -12.0212 -11.8811 -11.14 ... > len=1376256
[BMRT][bmrt_test:1083] INFO:load input time(s): 0.002188
[BMRT][bmrt_test:1084] INFO:calculate time(s): 0.055219
[BMRT][bmrt_test:1085] INFO:get output time(s): 0.002644
[BMRT][bmrt_test:1086] INFO:compare time(s): 0.001170

二、实现CenterNet图像分割算法模型的转换和量化(SDK0501-Torch直接编译转换)
1、模型转换
(1)下载CenterNet算法移植代码:
$ git clone https://github.com/sophon-ai-algo/examples.git
# CenterNet示例项目代码位置 /examples/simple/centernet
$ cd examples/simple/centernet
获取主干网的预训练模型,运行如下命令下载 dlav0 作为主干网的预训练模型和数据:
$ cd data/scripts/scripts
# 下载 ctdet_coco_dlav0_1x.pth 模型文件到路径 centernet/data/bulid 目录下
$ ./download_pt.sh
$ ./00_prepare.sh


将pth文件转换为pt文件
$ cd build
$ python export.py

(2)Torch转换MLIR模型
如果模型是图片输入, 在转模型之前我们需要了解模型的预处理。如果模型用预处理后的npz文件做输入, 则不需要考虑预处理。参考yolov5s的rgb图片,mean和scale对应为 0.0,0.0,0.0 和 0.0039216,0.0039216,0.0039216 。
模型转换命令如下:
$ mkdir workspace && cd workspace
$ vi torch2mlir.sh
#将下面的运行指令写入sh文件,方便复现和整理代码
$ model_transform.py \
--model_name centernet \
--model_def ../build/ctdet_coco_dlav0_1x.torchscript.pt \
--input_shapes [[1,3,512,512]] \
--mean 0.0,0.0,0.0 \
--scale 0.0039216,0.0039216,0.0039216 \
--keep_aspect_ratio \
--pixel_format rgb \
--test_input ../images/000000000139.jpg \
--test_result centernet_top_outputs.npz \
--mlir centernet.mlir \
#--post_handle_type yolo 此参数可以不加,不进行后处理,防止后边的npz文件compare时报错
$ sh torch2mlir.sh


最终生成文件如下:

(4)MLIR转换F32模型
将mlir文件转换成f32的bmodel, 操作方法如下:
$ vi mlir2f32.sh
#将下列命令写入到mlir2f32.sh文件中,这样方便日后代码复现
model_deploy.py \
--mlir centernet.mlir \
--quantize F32 \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \ #这一步的test_reference要和上一步的test_result保持一致
--tolerance 0.99,0.99 \
--model centernet_1684x_f32.bmodel
$ sh mlir2f32.sh

最终生成文件如下:

(5)MLIR转INT8模型
生成校准表
转INT8模型前需要跑calibration, 得到校准表; 输入数据的数量根据情况准备100~1000张左右。
然后用校准表, 生成对称或非对称bmodel。如果对称符合需求, 一般不建议用非对称, 因为 非对称的性能会略差于对称模型。
这里用现有的200张coco的val2017的图片举例, 执行calibration:
$ vi cali_table.sh
# 将下列命令写入sh文件中,这样做方便日后命令复现
run_calibration.py centernet.mlir \
--dataset ../images \
--input_num 200 \
-o centernet_cali_table
$ sh cali_table.sh


编译为INT8对称量化模型
转成INT8对称量化模型, 执行如下命令:
$ vi mlir2int8.sh
model_deploy.py \
--mlir centernet.mlir \
--quantize INT8 \
--calibration_table centernet_cali_table \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \
--tolerance 0.85,0.45 \
--model centernet_1684x_int8_sym.bmodel
$ sh mlir2int8.sh
转换过程输出内容如下:


最终生成文件如下:

编译为INT8非对称量化模型
转成INT8非对称量化模型, 执行如下命令:
$ vi mlir2int8a.sh
model_deploy.py \
--mlir centernet.mlir \
--quantize INT8 \
--asymmetric \
--calibration_table centernet_cali_table \
--chip bm1684x \
--test_input centernet_in_f32.npz \
--test_reference centernet_top_outputs.npz \
--tolerance 0.90,0.55 \
--model centernet_1684x_int8_asym.bmodel
$ sh mlir2int8a.sh
2、效果对比与性能测试-1684X PCIE
进入centernet模型仓库中py文件所在位置,运行测试bmodel检测结果
#进入centernet模型python文件位置
$ cd /Release_230301-public/examples/simple/centernet/py_bmcv_sail
#效果测试
$ python det_centernet_bmcv_sail_1b_4b.py --input ../data/ctdet_test.jpg --bmodel ../data/build/workspace/centernet_1684x_f32.bmodel


预测图片结果并查看:


bmodel性能测试
bmodel性能测试
安装好 libsophon 后, 可以使用 bmrt_test 来测试编译出的 bmodel 的正确 性及性能。可以根据 bmrt_test 输出的性能结果, 来估算模型最大的fps, 来选择合适的模型。
#进入到bmodel所在文件夹位置
$ cd /Release_230301-public/examples/simple/centernet/data/build/workspace
bmrt_test --bmodel centernet_1684x_f32.bmodel #以f32的bmodel为例,也可以测试int8等
#输出信息
[BMRT][deal_with_options:1446] INFO:Loop num: 1
[BMRT][bmrt_test:723] WARNING:setpriority failed, cpu time might flutuate.
[BMRT][bmcpu_setup:349] INFO:cpu_lib 'libcpuop.so' is loaded.
bmcpu init: skip cpu_user_defined
open usercpu.so, init user_cpu_init
[BMRT][load_bmodel:1079] INFO:Loading bmodel from [centernet_1684x_f32.bmodel]. Thanks for your patience...
[BMRT][load_bmodel:1023] INFO:pre net num: 0, load net num: 1
[BMRT][show_net_info:1463] INFO: ########################
[BMRT][show_net_info:1464] INFO: NetName: centernet, Index=0
[BMRT][show_net_info:1466] INFO: ---- stage 0 ----
[BMRT][show_net_info:1475] INFO: Input 0) 'input.1' shape=[ 1 3 512 512 ] dtype=FLOAT32 scale=1 zero_point=0
[BMRT][show_net_info:1485] INFO: Output 0) '515_Concat' shape=[ 1 84 128 128 ] dtype=FLOAT32 scale=1 zero_point=0
[BMRT][show_net_info:1488] INFO: ########################
[BMRT][bmrt_test:782] INFO:==> running network #0, name: centernet, loop: 0
[BMRT][bmrt_test:868] INFO:reading input #0, bytesize=3145728
[BMRT][print_array:706] INFO: --> input_data: < 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... > len=786432
[BMRT][bmrt_test:1005] INFO:reading output #0, bytesize=5505024
[BMRT][print_array:706] INFO: --> output ref_data: < 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ... > len=1376256
[BMRT][bmrt_test:1039] INFO:net[centernet] stage[0], launch total time is 55216 us (npu 55135 us, cpu 81 us)
[BMRT][bmrt_test:1042] INFO:+++ The network[centernet] stage[0] output_data +++
[BMRT][print_array:706] INFO:output data #0 shape: [1 84 128 128 ] < -5.44699 -6.73102 -8.15043 -8.61082 -9.36364 -9.72045 -10.5258 -10.805 -11.3242 -11.2517 -11.8261 -11.7891 -12.2917 -12.0212 -11.8811 -11.14 ... > len=1376256
[BMRT][bmrt_test:1083] INFO:load input time(s): 0.002188
[BMRT][bmrt_test:1084] INFO:calculate time(s): 0.055219
[BMRT][bmrt_test:1085] INFO:get output time(s): 0.002644
[BMRT][bmrt_test:1086] INFO:compare time(s): 0.001170









![[构建 Vue 组件库] 小尾巴 UI 组件库 —— 横向商品卡片(仿淘宝)](https://img-blog.csdnimg.cn/img_convert/c22d71652804b2d0334c083f30f51a93.png)