需要源码和数据集请点赞关注收藏后评论区留言私信~~~
划分聚类、密度聚类和模型聚类是比较有代表性的三种聚类思路
1:划分聚类
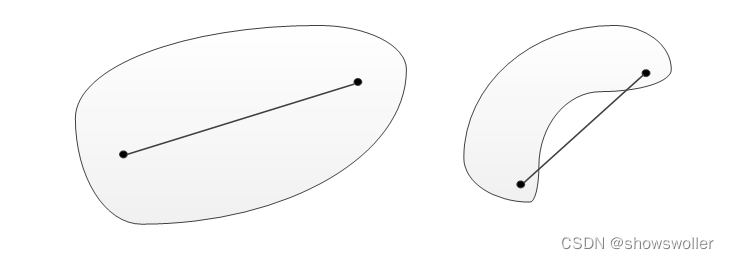
划分(Partitioning)聚类是基于距离的,它的基本思想是使簇内的点距离尽量近、簇间的点距离尽量远。k-means算法就属于划分聚类。划分聚类适合凸样本点集合的分簇。
2:密度聚类
密度(Density)聚类是基于所谓的密度进行分簇
密度聚类的思想是当邻域的密度达到指定阈值时,就将邻域内的样本点合并到本簇内,如果本簇内所有样本点的邻域密度都达不到指定阈值,则本簇划分完毕,进行下一个簇的划分。
DBSCAN
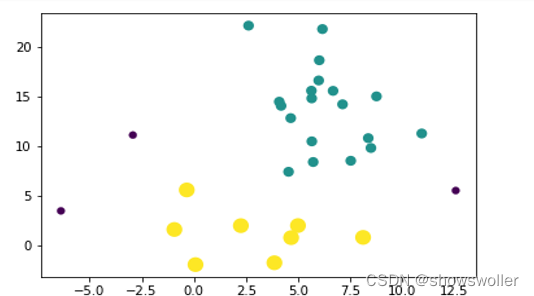
DBSCAN算法将所有样本点分为核心点、边界点和噪声点,如灰色点、白色点和黑色点所示
核心点:在指定大小的邻域内有不少于指定数量的点。指定大小的邻域,一般用邻域半径eps来确定。指定数量用min_samples来表示。
边界点:处于核心点的邻域内的非核心点。
噪声点:邻域内没有核心点的点

DBSCAN算法需要预先指定eps和min_samples两个参数,即它们是超参数。
算法寻找一个簇的过程是先对样本点按顺序排查,如果能找到一个核心点,就从该核心点出发找出所有直接和间接与之相邻的核心点,以及这些核心点的所有边界点,这些核心点和边界点就形成一个簇
接着,从剩下的点中再找另一个簇,直到没有核心点为止。余下的点为噪声点。
效果展示如下 对数据集中三十个坐标应用DBSCAN算法
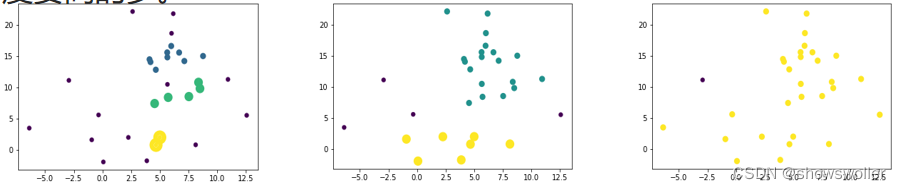
下面三幅图是eps和min_samples取不同值时候的分布情况
代码如下
from sklearn.cluster import DBSCAN
import numpy as np
samples = np.loadtxt("kmeansSamples.txt")
clustering = DBSCAN(eps=5, min_samples=5).fit(samples)
clustering.labels_
>>>array([ 0, 0, 0, 0, -1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, -1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, -1, 0], dtype=int64)
import matplotlib.pyplot as plt
plt.scatter(samples[:,0],samples[:,1],c=clustering.labels_+1.5,linewidths=np.power(clustering.labels_+1.5, 2))
plt.show()
DBSCAN算法善于发现任意形状的稠密分布数据集,但它的结果对邻域参数eps和min_samples敏感。不像k-means算法只需要调整一个参数,DBSCAN算法需要对两个参数进行联合调参,复杂度要高的多。
如果能确定聚类的具体评价指标,如簇数、噪声点数限制和SC、DBI、CH和ZQ等,则可以对参数eps和min_samples的合理取值依次运行DBSCAN算法,取最好的评价结果。如果数据量特别大,则可以将参数空间划分为若干网格,每个网格取一个代表值进行聚类。
OPTICS
OPTICS算法的基本思想是在DBSCAN算法的基础上,将每个点离最近的核心点密集区的可达距离都计算出来,然后根据预先指定的距离阈值把每个点分到与密集区对应的簇中,可达距离超过阈值的点是噪声点。点到核心点密集区的可达距离是它到该区内所有核心点的距离的最小值。
引入可达距离可以直观的看到样本点的聚集情况,OPTICS算法巧妙地解决了确定eps参数值的问题
输出结果如下


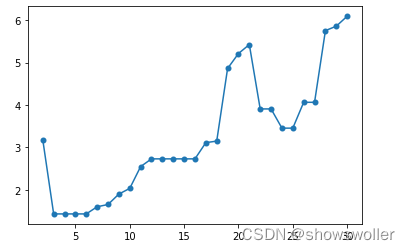
代码如下
from sklearn.cluster import OPTICS, cluster_optics_dbscan
import matplotlib.pyplot as plt
import numpy as np
samples = np.loadtxt("kmeansSamples.txt")
clust = OPTICS(max_eps=np.inf,min_samples=5, cluster_method='dbscan',eps=4.5)
clust.fit(samples)
clust.ordering_
reachability = clust.reachability_[clust.ordering_]
reachability
labels = clust.labels_[clust.ordering_]
labels
plt.plot(list(range(1, 31)),reachability,marker='.',markeredgewidth=3,linestyle='-')
plt.show()
plt.scatter(samples[:,0],samples[:,1],c=clust.labels_+1.5,linewidths=np.power(clust.labels_+1.5, 2))
plt.show()创作不易 觉得有帮助请点赞关注收藏~~~





![[附源码]计算机毕业设计PythonQ宝商城(程序+源码+LW文档)](https://img-blog.csdnimg.cn/019551ff143f4c4888c8476a1a6355eb.png)


![[附源码]Node.js计算机毕业设计黑河市劳务人员管理系统Express](https://img-blog.csdnimg.cn/b3eee7cb0d82457f9742ee98e2bd46e1.png)