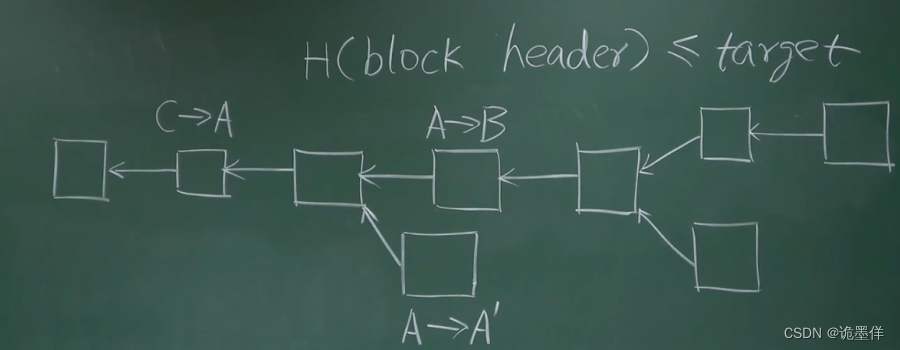
背景
之前在知乎上看到一个问题:作为一个KV数据库,levelDB为什么使用LSM树实现,而不是hash索引?当时就想作答一番。不过看到问题下方已经有大佬作答了,而我也说不出什么新东西来。于是选择作罢。
但是最近有nutsdb用户提了一个issue。大致描述的场景是,他们每天大概有1亿的数据写入,用badgerdb是可以cover住的,但是用nutsdb每次都会因为内存耗尽而提前终止。这个问题正好也涉及到LSM和Hash索引这两种存储架构。也让我联想起在那个知乎上的问题,觉得可以写一篇文章分析这种情况。**为什么同样是一亿数据,nutsdb内存会不够用,而badgerdb却能cover得住呢?**顺便我们也可以从内存的角度来看,在大规模数据的背景下这两种架构的对应实现的表现如何。
我们知道,论文和实际落地有时候是有比较大的出入的,所以这篇文章主要会关注LSM和Bitcask(Hash索引的典型代表)的对应实现,也就是leveldb和nutsdb,为什么是leveldb呢,因为badgerdb是在leveldb的基础上实现了kv分离以达到减少读写放大,这个feature并不会对这篇文章的讨论结果有多少影响,所以为了降低文章的复杂度,本文决定选取leveldb作为观察对象。分析现实世界中这两者的异同。本人水平有限,分析过程中有不当之处还请批评指正。
前置知识
这篇文章不会深入到源码级别,重点是理论分析。很多地方不会讲述技术细节,而是一笔带过。所以需要朋友们对一些前置的知识有一定的了解。我找了一些个人认为讲的比较好的文章,让大家对LSM,Bitcask,leveldb,nutsdb有整体的了解。大家如果对以上的知识没有太多的了解的话,可以翻到文章最下方看延伸阅读上的材料哦~
1. nutsdb
-
nutsdb写入和读取数据的流程相对比较简单,写入数据的时候会直接将数据encode成二进制数据,直接写入到磁盘中。通过构建一个索引对象插入到内存索引数据结构(Bitcask中使用的是hashmap,而nutsdb实现是使用B+Tree)的方式记录数据在磁盘的位置(文件名+数据在文件中的偏移)。
-
转过来看,读取数据的时候可以在内存的索引结构中得到数据的的位置,然后用一次系统调用将数据取出。
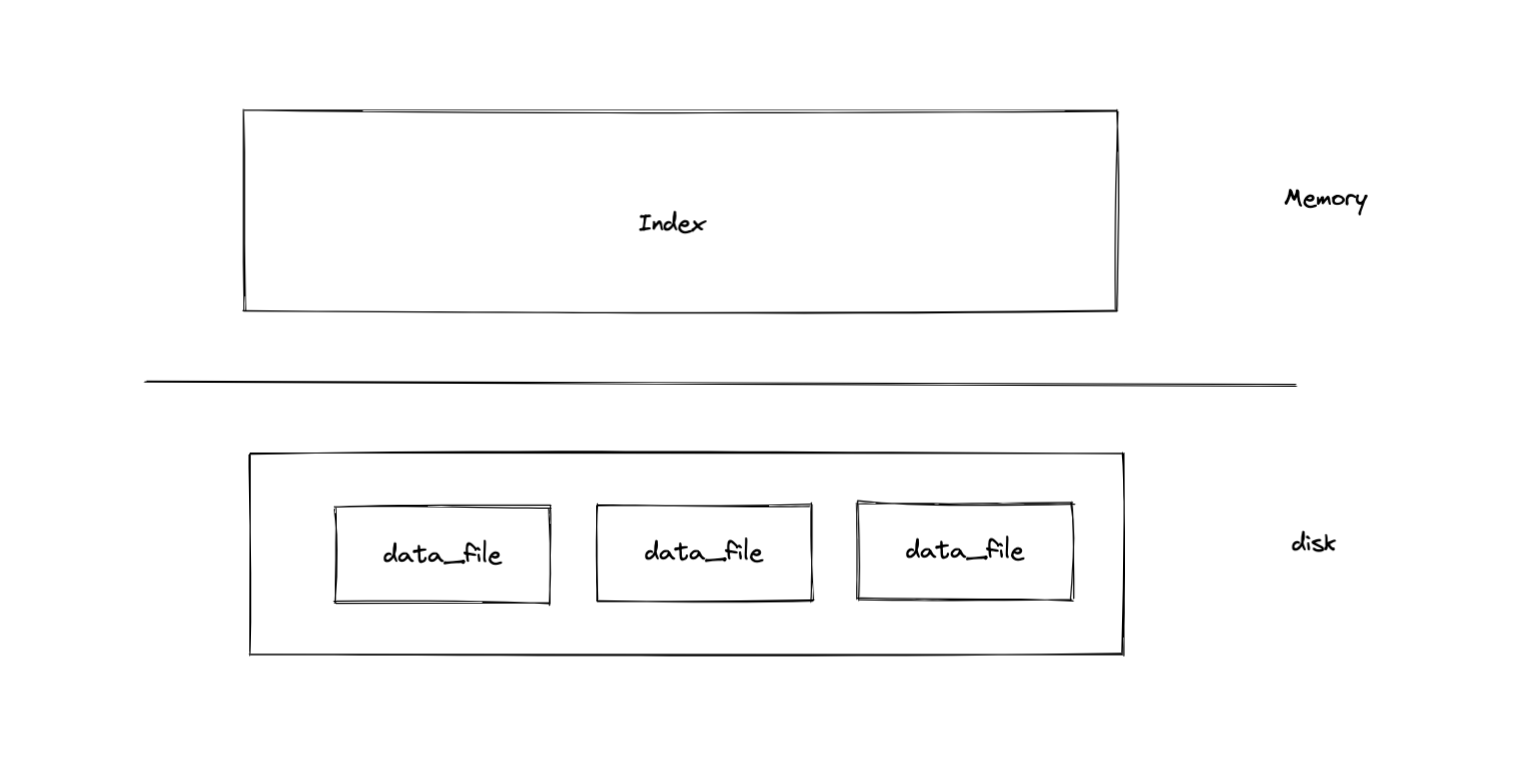
所以我们可以知道的是,nutsdb每新增一条数据,都要在内存中构建一个索引对象去标识数据的位置,以方便我们可以根据这个位置读取出来。所以当数据量很大的时候,索引对象会持续增多,内存迟早是会扛不住的。当然我们可以使用一些压缩算法,比如在论文《Optimistically Compressed Hash Tables & Strings in the USSR》中提到的对hash的压缩,将内存中的索引数据进行一定程度的压缩。不过这样是治标不治本的,只能延缓内存爆满的发生,随着数据的增长内存该炸还是会炸的。
2. goleveldb
相比而言leveldb的情况就复杂很多。Leveldb存储的数据分为两部分,一是存储在WAL和与之对应的MemTable的数据,另外是以SST形式组织起来数据,也就是经过Minor Compaction和Major Compaction之后形成的一层层数据文件。

所以归结起来在leveldb中,内存里会有一下三样东西。1. Memtable 2. LRU缓存(用来缓存在SST中读取出来的block,其中有索引内容,也有数据内容) 3. SST的内存索引。
Memtable和LRU缓存大小是配置可控的,所以在这一块上,可谓穷有穷的玩法,富有富的玩法。也就说如果内存充足可以在Memtable和LRU放置更多更多,内存预算不是很多的话就可以分配少一点,memtable放的东西少会频繁触发minor compaction, LRU少会频繁发生IO系统调用读取磁盘数据,不过无论内存情况怎么样,memTable和LRU缓存始终是能玩的。还有剩下的一个,SST的索引,是什么呢?
我们之前讲到,程序是运行在内存中的,对于持久化存储引擎而言,数据是会落到磁盘上保存的,但是磁盘不知道你存了什么进来,所以需要存储引擎设计一些算法精准找到磁盘中的数据。Bitcask模型比较简单,也就是一条数据对应一个索引。这样直接可以读取数据了。但是在leveldb中,他能够以很小的内存管理一大片磁盘中的数据,让我们看看他是怎么做到的。
我们可以在上图中看到leveldb会有因为一次次compaction操作所形成的一层层的SST文件,当然我们要知道的是,这里所谓的一层层,是我们的逻辑概念,磁盘是不会帮你维护这个逻辑的。所以在内存中我们需要维护这个关系。那么他是怎么做的呢,下面我们看看goleveldb代码实现。
var levels []tFiles
// tFiles hold multiple tFile.
type tFiles []*tFile
// tFile holds basic information about a table.
type tFile struct {
fd storage.FileDesc
seekLeft int32
size int64
imin, imax internalKey
}
我们可以看到,levels代表所有层次SST文件的所有索引信息。而tFiles代表一层的SST文件的索引信息。tFile结构维护的是一个SST文件的索引信息,其中最重要的内容其实是imin和imax,标识了这个文件中存储的数据Key的范围。查询数据的时候可以依次遍历每一层,因为上层的数据总是比下层的新,如果在当层找到了就不需要往下找了,找不到就继续往下层找,直到遍历完最后一层。在同层中可以通过比对Key与tFile中的存储的imin和imax看下key是否存在于这个文件中。如果存在的话就可以读取这个文件来找到这条数据。得益于SST的优秀设计,找寻数据就像开启一个又一个的盲盒,在即有的提示之下不断的迫近数据所在,直到最后豁然开朗找到数据。而这一个个盲盒很大一部分又都在磁盘中。不会像nutsdb那样所有数据都需要一个索引对象存在与内存中。如下图所示的SST文件的组织结构。
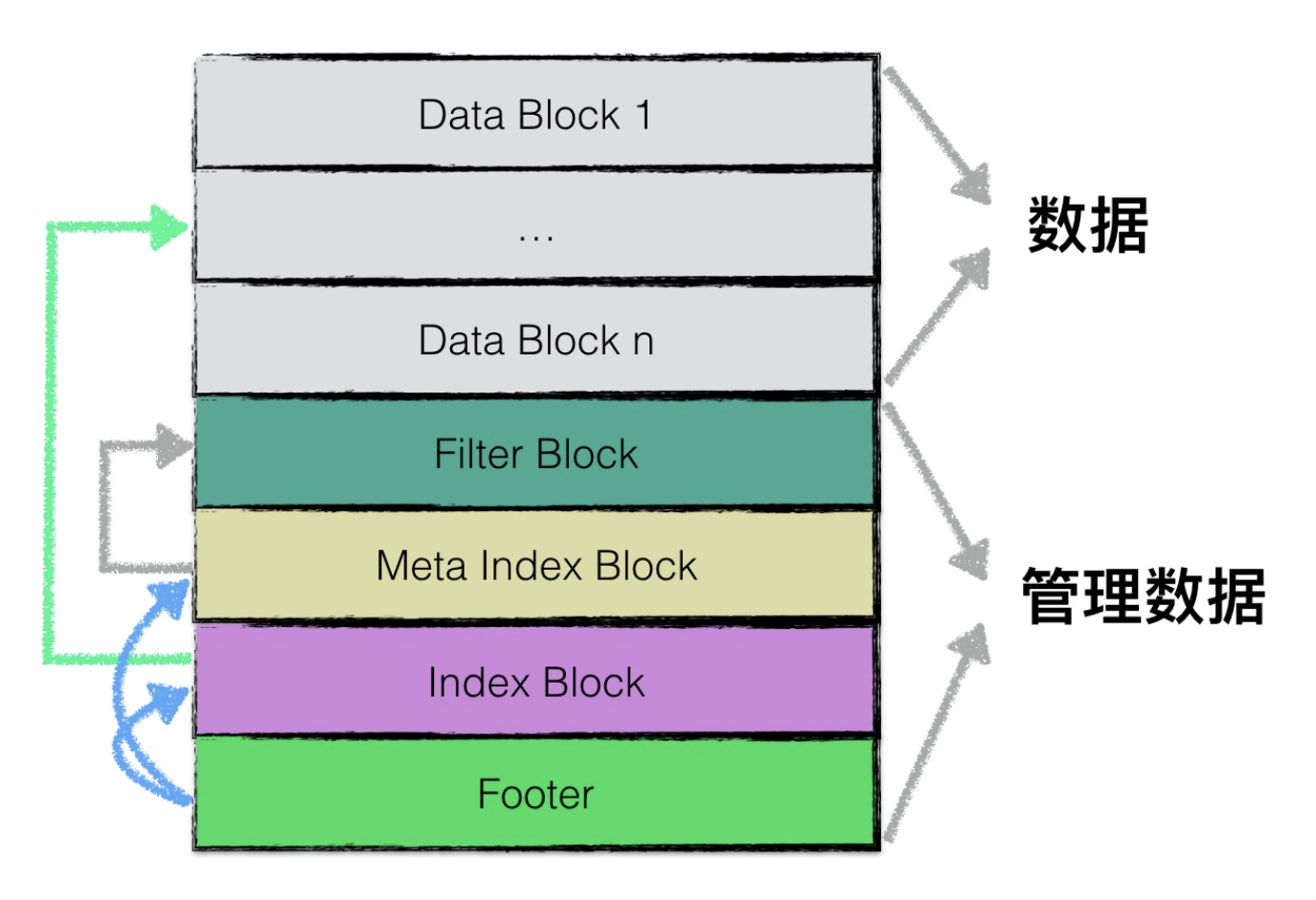
让我们看看要在SST中读取一条数据需要打开几个盲盒。首先我们会在内存中判断这个要读取的key是不是在imin和imax之间,如果是的话,就读SST的Footer,Footer会提示我们找到SST数据模块的索引信息(Index Block)以及索引信息的描述信息(Meta Index Block,布隆过滤器是可选的,所以这个实际上可能不一定有)。根据Index Block我们可以找到数据所在。当然这里不会展开SST中每个Block是怎么设计的,感兴趣的朋友可以看延伸阅读哦。
我们可以看到,通过高效的数据组织形式。只需要很小一部分内存,也就是levels这个对象里面包含的东西,存储少量的索引对象在内存中,也可以管理很大量的磁盘数据,也就是大量的数据。这样虽然会引入多次的系统调用才能最终找到数据,但是这些读取过的block都可以被缓存起来,后面也不需要在重复发生系统调用了。
综上所讲述,leveldb在内存的使用上,无论数据量的多少可以达到一个比较健康的状态。数据量多的时候,可能会出现零散读取数据的情况,会频繁的在缓存中进行换入换出,性能上会变慢,但是不至于不可用,换一个角度来说,数据量如果很大,系统变慢,从感官上来说,应该是属于正常的。但是不可用,很难接受的。
说到这里你可能会问了,nutsdb也可以这样组织数据嘛,这不就解决内存问题了?这个问题问的很好,但是理论上来说,是不太可能的。为什么呢?
3. nutsdb可以换一个数据组织方式吗?
为什么说不太可能呢?问题的关键在于,nutsdb的数据是乱序存储的,而leveldb是有序存储的。正是这一字之差造成了这样的情况。为什么这么说呢?
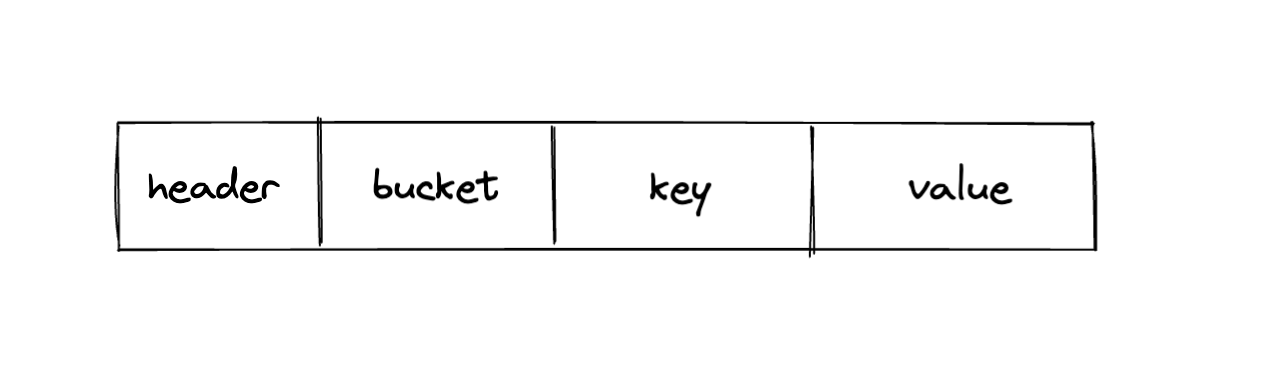
在我们之前的文章中,讲过在nutsdb中一条数据在磁盘里是这样存在的。数据是以下图的形式一条条的追加写入到磁盘之中。可以理解为,在磁盘中相邻数据之间没有任何关系,所以需要在内存中记录每一条数据在什么位置。不然就不知道怎么找数据了。
那么leveldb呢?为什么数据有序就可以做到呢?得益于Memtable这样的内存数据结构,在leveldb中他的实现是跳表。在跳表的最下面一层就是一条有序的链表,可以通过一次遍历就写入这些数据到SST的Data Block中。也就是说在SST中数据之间其实是有序排列的。这样就可以通过不断的缩小范围找到数据啦。
总结
说到这里其实并不是把bitcask就不行了,正所谓架构没有最好和最坏,只有最合适的。bticask设计简单,读写性能都比较稳定,点查场景中速度较快,但是缺点就是内存占用会随着数据的增长而增长。leveldb读会稍微差一点,因为需要多次io才能找到数据,并且有时候会跨越多个层级读取SST。不过我要由衷赞叹的是,SST的设计确实精美绝伦。
延伸阅读
- 知乎上的问题:https://www.zhihu.com/question/27256968/answer/35881582
- nutsdb issue:https://github.com/nutsdb/nutsdb/issues/239
- LSM论文翻译:https://xonlab.com/2021/01/10/%E8%AE%BA%E6%96%87%E7%BF%BB%E8%AF%91The%20Log-Structured%20Merge-Tree%EF%BC%88LSM-Tree%EF%BC%89/
- leveldb架构解析:https://zhuanlan.zhihu.com/p/436037845
- SST组织结构详解:https://leveldb-handbook.readthedocs.io/zh/latest/sstable.html


![[附源码]Node.js计算机毕业设计黑河市劳务人员管理系统Express](https://img-blog.csdnimg.cn/b3eee7cb0d82457f9742ee98e2bd46e1.png)

![[附源码]Python计算机毕业设计冠军体育用品购物网站Django(程序+LW)](https://img-blog.csdnimg.cn/97392b76bfa945d2b322c5274a12bea5.png)
![[LeetCode周赛复盘] 第 324 场周赛20221218](https://img-blog.csdnimg.cn/9ed24260f18e456fa0bf836eaeb41934.png)