torch.fx
前言
最近在学习一些AI编译器,推理框架的知识,恰好看到了torch.fx这个部分。这个其实在1.10就已经出来了,但是一直不知道,所以花了一点时间学习了这部分的内容。
以下所有的代码基于Mac M1 pytorch 1.13,其他的os/版本没有进行测试
1.什么是torch.fx
首先去查看官网docTORCH.FX
FX is a toolkit for developers to use to transform nn.Module instances. 这句话很好的定义了FX的本质:用来改变module实例的一种工具。包括了三个主要的组件:symbolic tracer intermediate representation python code generation
符号追踪可以捕获模块的语义进行解析;中间表示也就是IR记录了中间的操作,比如输入输出和调用的函数等;代码生成这个比较有意思,因为这是一个python-to-python的转换工具,这就从本质上区别了FX与一些AI编译器,推理库的区别。从流程上看,FX与推理库都是解析模型生成IR,然后融合算子呀优化等等,但是FX只是为了优化改变模型的功能,最终落脚点还是在python上;而其他的库都是经过一系列优化后可以脱离python依赖部署到c++等边缘环境上。
2. torch.fx有什么用
既然使用fx可以改变module,那么具体可以有哪些应用场景呢?我总结了下面几个主要的
- 追踪模型图,改变模型部分结构,替换某些算子
- 在python代码的层面对模型进行优化
- 根据trace得到的结果更好的可视化模型
- 对模型进行量化
2.1 模型算子替换
首先来看看官网给出的例子
import torch
from torch import nn
from torch import fx
from torch.fx import symbolic_trace
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.param=nn.Parameter(torch.Tensor([1,2,3,4]))
def forward(self,x):
return (x+self.param).clamp(min=0.0,max=1.0)
model=MyModel()
symbolic_traced=symbolic_trace(model)
print(symbolic_traced.graph)
print(symbolic_traced.code)
symbolic_traced.graph.print_tabular()
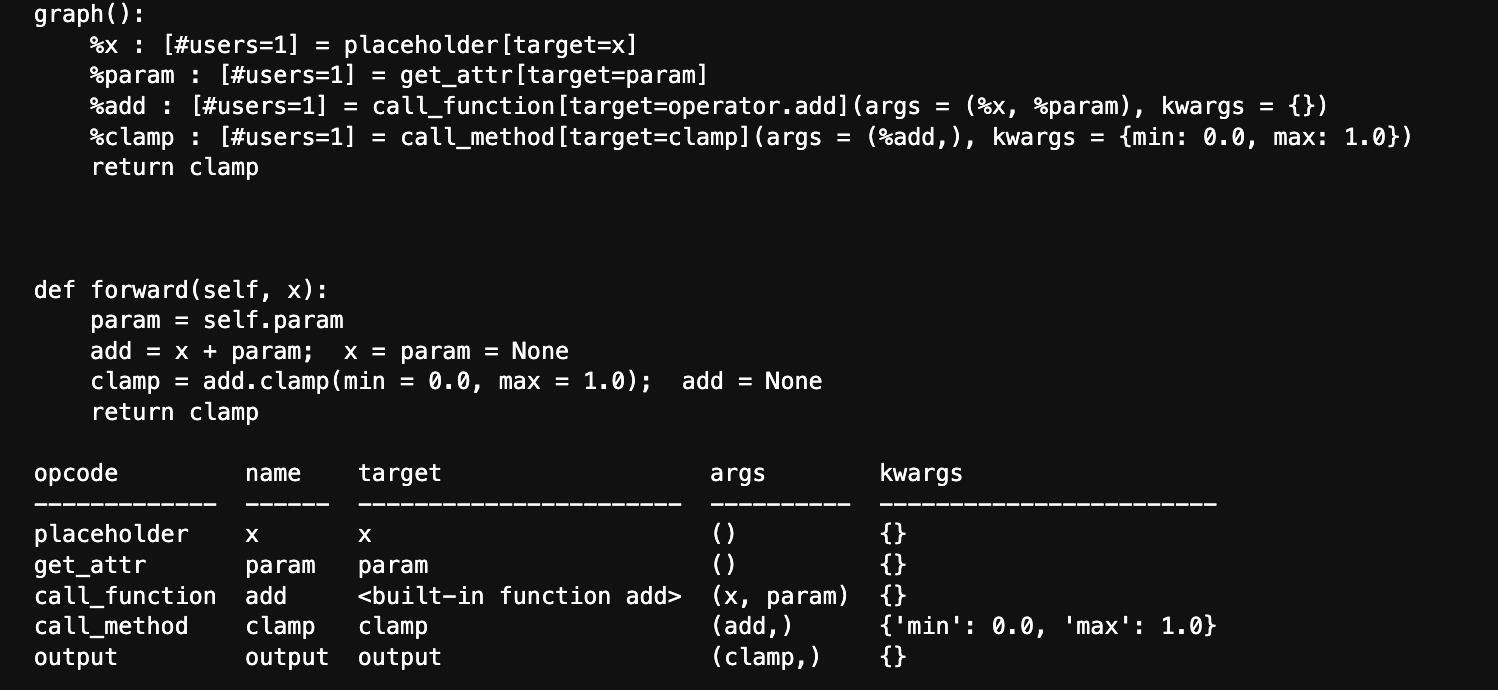
从图里我们可以清楚地看到模型进行的操作以及IR,它也很好的定义了算子的分类(这个对下面部分内容很有用)。然后我们如果想用sigmoid替换clamp,如果按照官网以及大多数已有文章的例子是有错误的
# 将clamp转为sigmoid
def transform(m):
gm=fx.Tracer().trace(m)
for node in gm.nodes:
if node.op=='call_method':
if node.target=="clamp":
print(node.target)
node.target=torch.sigmoid
gm.lint()
return fx.GraphModule(m,gm)
trans_model=transform(model)
print(trans_model.graph)
print(trans_model.code)
trans_model.graph.print_tabular()

很明显可以看到node.target必须是字符串,所以这样替换是不对的。而原示例给出的是torch.mul替换torch.add,如果测试那个代码,node.target==torch.add这个根本不会成立(target是str),所以这里我才将target条件更正。
那怎么替换clamp呢,而且还要验证替换后模型的结果无误差
# 将clamp转为sigmoid
def transform(m):
gm=fx.Tracer().trace(m)
for node in gm.nodes:
if node.op=='call_method':
if node.name=="clamp":
print(node.target)
node.target="sigmoid"
node.name="sigmoid"
node.kwargs={}
gm.lint()
return fx.GraphModule(m,gm)
trans_model=transform(model)
print(trans_model.graph)
print(trans_model.code)
trans_model.graph.print_tabular()
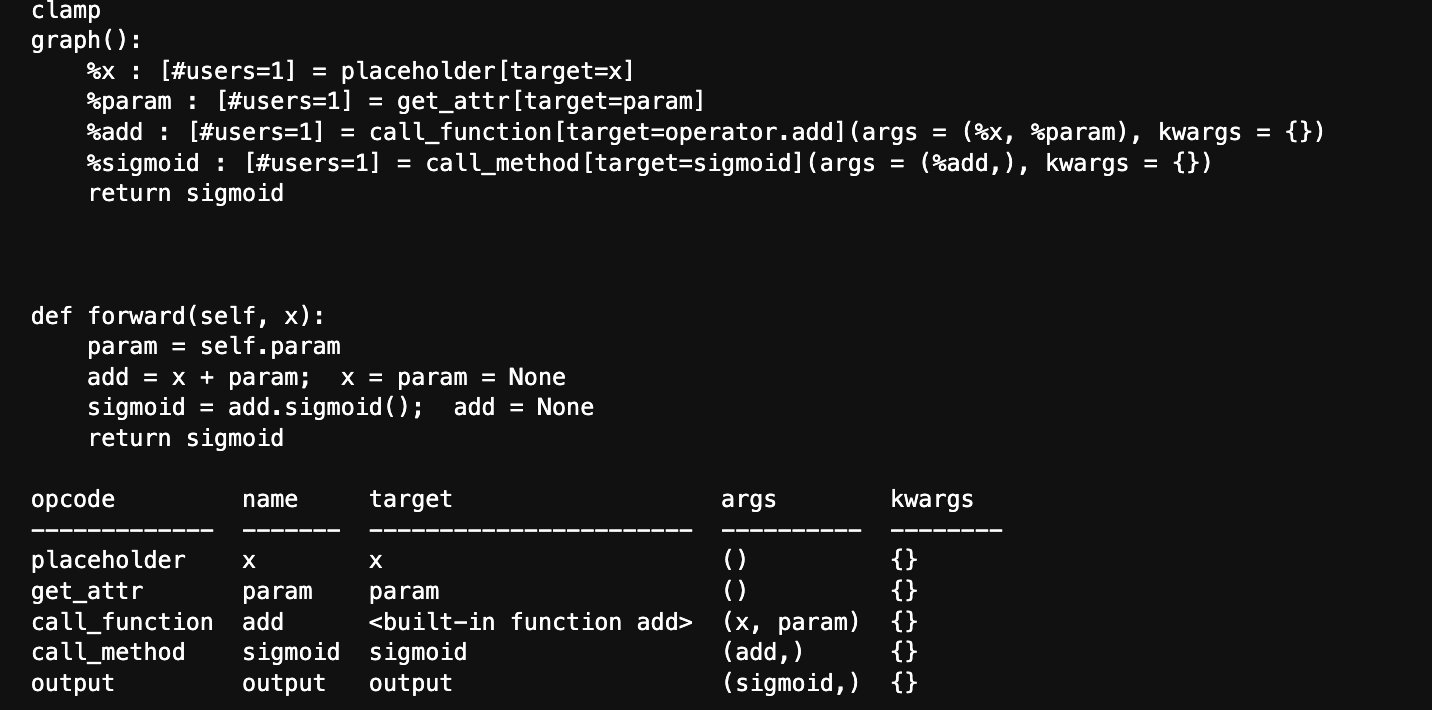
从模型打印结果来看替换是成功的,但是还要经过输出检验
class MyModel1(nn.Module):
def __init__(self):
super().__init__()
self.param=nn.Parameter(torch.Tensor([1,2,3,4]))
#self.linear=torch.nn.Linear(4,5)
def forward(self,x):
return (x+self.param).sigmoid()
test=MyModel1()
inputs = torch.randn(1,4)
torch.testing.assert_close(test(inputs),trans_model(inputs))
这里没有任何输出,证明输出与gt一致。当然不止一种实现,下面给出其他两种
# 将clamp转为sigmoid
def transform(m):
gm=symbolic_trace(m)
for node in gm.graph.nodes:
if node.op=='call_method':
if node.name=="clamp":
print(node.target)
node.target="sigmoid"
node.name="sigmoid"
node.kwargs={}
gm.recompile()
return gm
trans_model=transform(model)
print(trans_model.graph)
print(trans_model.code)
torch.testing.assert_close(test(inputs),trans_model(inputs))
# 将clamp转为sigmoid
from torch.fx import replace_pattern
def pattern(x):
return x.clamp(min=0.0,max=1.0)
def replacement(x):
return x.sigmoid()
replace_pattern(symbolic_traced,pattern,replacement)
print(symbolic_traced.graph)
print(symbolic_traced.code)
torch.testing.assert_close(test(inputs),symbolic_traced(inputs))
2.2 算子融合
在做推理部署的时候最常用的就是算子融合,也就是将多个算子的计算在数学上进行等效替换,从而减少了算子数量以及整体的计算量,加速了推理时间。torch.fx也给了我们很好的算子融合替换帮助,因为上面说了有了trace我们可以很轻松地对模型算子进行替换,例如最常见的conv+bn融合,丢弃dropout
这部分代码可以参考官方样例/torch/fx/experimental/optimization.py,我这里直接白嫖过来演示一下
from torch.nn.utils.fusion import fuse_conv_bn_eval
from torch.fx.node import Argument, Target
from typing import Type, Dict, Any, Tuple, Iterable, Optional, List, cast
import copy
def _parent_name(target : str) -> Tuple[str, str]:
"""
Splits a qualname into parent path and last atom.
For example, `foo.bar.baz` -> (`foo.bar`, `baz`)
"""
*parent, name = target.rsplit('.', 1)
return parent[0] if parent else '', name
def matches_module_pattern(pattern: Iterable[Type], node: fx.Node, modules: Dict[str, Any]):
if len(node.args) == 0:
return False
nodes: Tuple[Any, fx.Node] = (node.args[0], node)
for expected_type, current_node in zip(pattern, nodes):
if not isinstance(current_node, fx.Node):
return False
if current_node.op != 'call_module':
return False
if not isinstance(current_node.target, str):
return False
if current_node.target not in modules:
return False
if type(modules[current_node.target]) is not expected_type:
return False
return True
def replace_node_module(node: fx.Node, modules: Dict[str, Any], new_module: torch.nn.Module):
assert(isinstance(node.target, str))
parent_name, name = _parent_name(node.target)
modules[node.target] = new_module
setattr(modules[parent_name], name, new_module)
def fuse(model: torch.nn.Module, inplace=False) -> torch.nn.Module:
"""
Fuses convolution/BN layers for inference purposes. Will deepcopy your
model by default, but can modify the model inplace as well.
"""
patterns = [(nn.Conv1d, nn.BatchNorm1d),
(nn.Conv2d, nn.BatchNorm2d),
(nn.Conv3d, nn.BatchNorm3d)]
if not inplace:
model = copy.deepcopy(model)
fx_model = fx.symbolic_trace(model)
modules = dict(fx_model.named_modules())
new_graph = copy.deepcopy(fx_model.graph)
for pattern in patterns:
for node in new_graph.nodes:
if matches_module_pattern(pattern, node, modules):
if len(node.args[0].users) > 1: # Output of conv is used by other nodes
continue
conv = modules[node.args[0].target]
bn = modules[node.target]
fused_conv = fuse_conv_bn_eval(conv, bn)
replace_node_module(node.args[0], modules, fused_conv)
node.replace_all_uses_with(node.args[0])
new_graph.erase_node(node)
return fx.GraphModule(fx_model, new_graph)
def remove_dropout(model: nn.Module) -> nn.Module:
"""
Removes all dropout layers from the module.
"""
fx_model = fx.symbolic_trace(model)
class DropoutRemover(torch.fx.Transformer):
def call_module(self, target : Target, args : Tuple[Argument, ...], kwargs : Dict[str, Any]) -> Any:
if isinstance(self.submodules[target], nn.Dropout):
assert len(args) == 1
return args[0]
else:
return super().call_module(target, args, kwargs)
return DropoutRemover(fx_model).transform()
class TestConv2d(nn.Module):
def __init__(self,in_channels,out_channels,**kwargs):
super(TestConv2d,self).__init__()
self.conv=nn.Conv2d(in_channels,out_channels,**kwargs)
self.bn=nn.BatchNorm2d(out_channels)
self.relu=nn.ReLU(True)
def forward(self,x):
x=self.conv(x)
x=self.bn(x)
x=self.relu(x)
return x
class TestModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1=TestConv2d(3,32,kernel_size=3)
self.conv2=TestConv2d(32,64,kernel_size=3)
self.dropout=nn.Dropout(0.3)
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=self.dropout(x)
return x
def show(string,count):
print(f"{'='*count}{string}{'='*count}")
test_model=TestModel()
# 在eval下进行融合,丢弃
test_model.eval()
### origin
origin_model=symbolic_trace(test_model)
show("origin result",20)
print(origin_model.graph)
print(origin_model.code)
### fuse
fuse_model=fuse(test_model)
fuse_model=remove_dropout(fuse_model)
show("fuse result",20)
print(fuse_model.graph)
print(fuse_model.code)
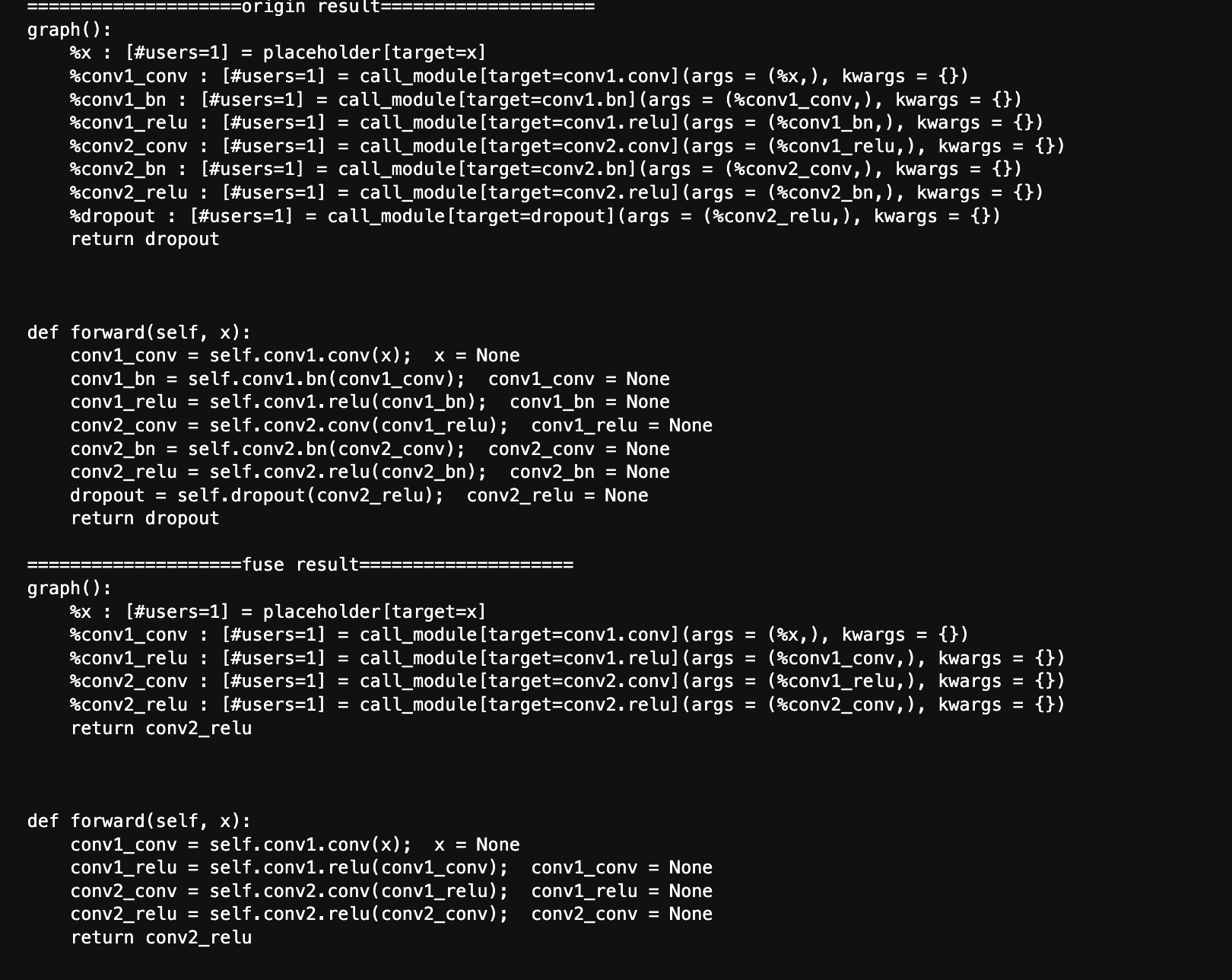
可以看到经过算子融合与丢弃,模型没有了bn dropout十分简洁。有人会说为什么不把relu也融进conv,这在量化中可以实现截断但是如果是全精度也就是FP32下如果scale和zeropoint不一致没法量化回来,所以这里并没有进行融合。
2.3 模型可视化
不知道多少人用过torchviz对模型进行过可视化,不能说不好只能说根本不直观。这里我恰好看到了一篇讲利用fx进行模型结构可视化的博客,可惜博主代码没有全部给出来。不过根据他的文章也算是给了我一种很好的思路,既然我们都有模型的DAG,IR,那我们应该可以更加直观的实现模型结构的可视化。所以这部分就算是完成博主没有给出来的代码,模型定义就用博主博客中的模型
利用torch.fx提取PyTorch网络结构信息绘制网络结构图 - wrong.wang,大家可以先去看看博主的这篇文章我不过多讲重复内容。另外如果想实现功能,还得去研究一下fx解释器的源码torch.fx.interpreter — PyTorch 1.13 documentation
from torchviz import make_dot
import graphviz
import torch.nn.functional as F
class TestModel(nn.Module):
def __init__(self):
super(TestModel, self).__init__()
self.bias = nn.Parameter(torch.randn(1))
self.main = nn.Sequential(nn.Conv2d(3, 4, 1), nn.ReLU(True))
self.skip = nn.Conv2d(2, 4, 3, stride=1, padding=1)
def forward(self, x, y):
x = self.main(x)
y = (self.skip(y)+self.bias).clamp(0, 1)
x_size = x.size()[-2:]
y = F.interpolate(y, x_size, mode="bilinear", align_corners=False)
return torch.sigmoid(x) + y
x=torch.randn(1,3,16,16)
y=torch.randn(1,2,8,8)
test_model=TestModel()
z=test_model(x,y)
g=make_dot(z,params=dict(test_model.named_parameters()))
g.render(directory="test",format='svg',view=False)
首先用torchviz绘制一下模型
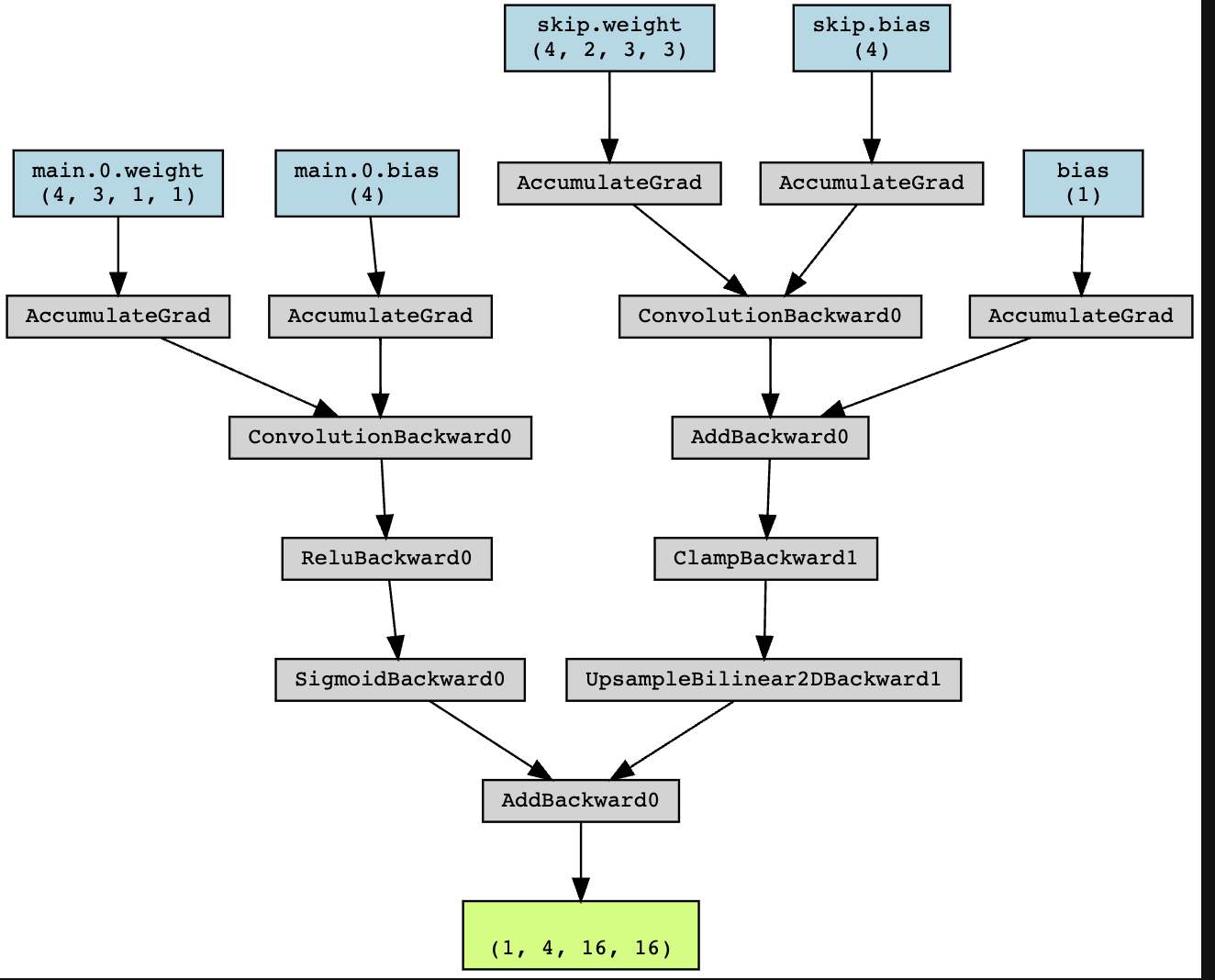
看着这张图,似懂非懂的样子,并不能直观的看到模型的结构。然后开始实现博主的代码
import traceback
class Get_IR(torch.fx.Interpreter):
def run_node(self,n):
try:
result=super().run_node(n)
except Exception:
traceback.print_exc()
raise RuntimeError(f"Error while run node:{n.format_node()}")
is_find=False
def extract_meta(t):
if isinstance(t,torch.Tensor):
nonlocal is_find
is_find=True
return _extra_meta(t)
else:
return t
def _extra_meta(t):
if n.op=="call_module":
submod=self.fetch_attr(n.target)
return {'name':n.name,'op':n.op,'args':n.args,'shape':t.shape,'target':n.target,'kw':n.kwargs,'mod':submod}
elif n.op=="call_method":
return {'name':n.name,'op':n.op,'args':n.args,'shape':t.shape,'target':n.target,'kw':n.kwargs}
elif n.op=="call_function":
return {'name':n.name,'op':n.op,'args':n.args,'shape':t.shape,'target':n.target,'kw':n.kwargs}
else:
return {'name':n.name,'op':n.op,'args':n.args,'shape':t.shape}
n.meta["result"]=torch.fx.node.map_aggregate(result,extract_meta)
n.meta["find"]=is_find
return result
traced=symbolic_trace(test_model)
args=(x,y)
kwargs={}
_=Get_IR(traced).run(*args,**kwargs)
print(traced.graph.print_tabular())
for node in traced.graph.nodes:
print(node.meta)
其实这部分就是利用解释器会遍历图中的每个节点,所以我们只需要自定义一下run_node(),在里面加入解析网络结构,输入输出的功能就可以了。
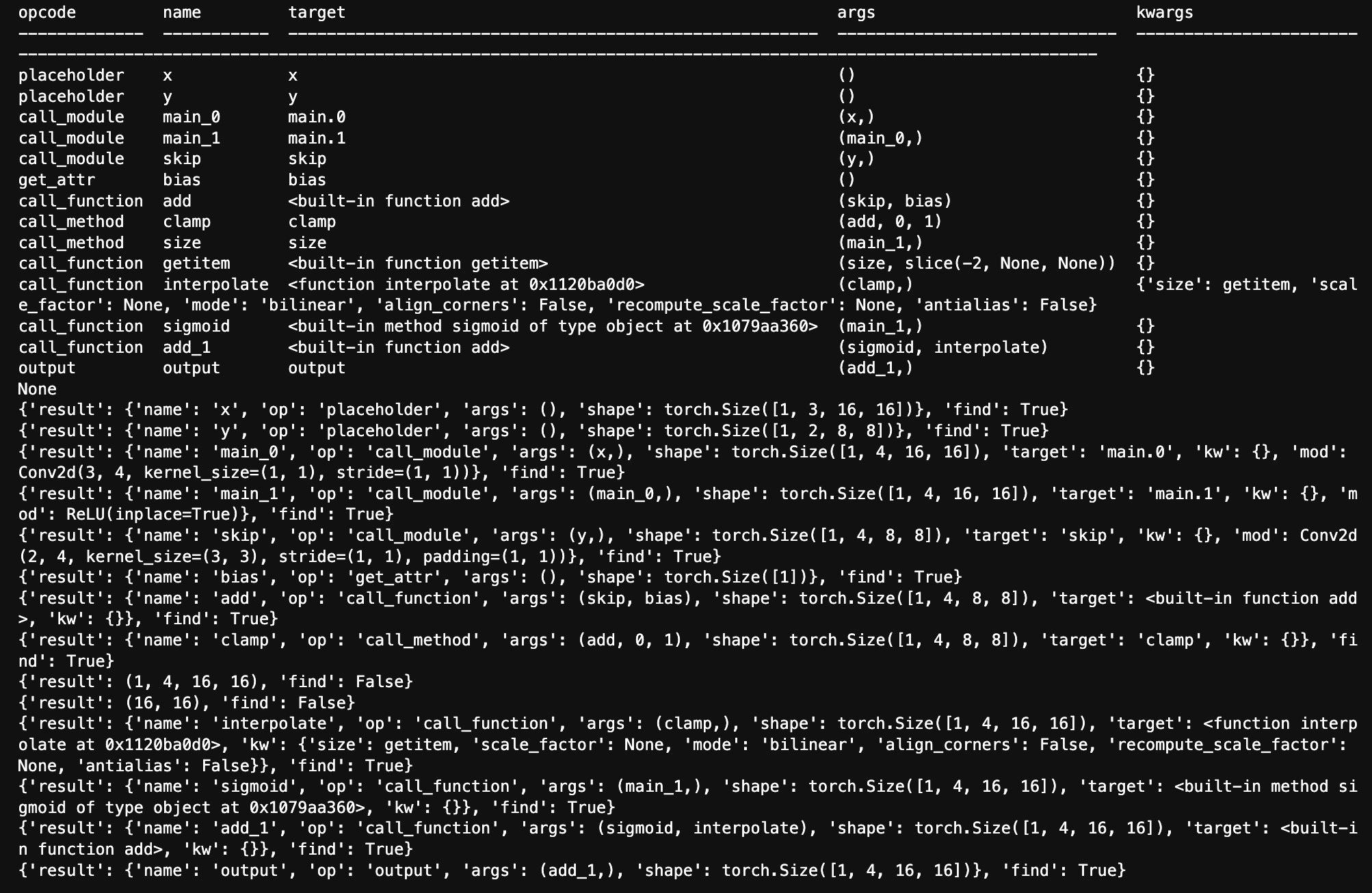
可以看到meta里面已经有了模型结构所需要的一切,但是这里虽然打印出来size和getitem是存在的,但是实际上并没有在条件中解析到,目前还没找到原因。
def create_str(node):
if node.op=="call_module":
return f"<<TABLE><TR><TD COLSPAN='2'>{node.meta['result']['mod']}</TD></TR><TR><TD>{node.meta['result']['name']}</TD><TD>{node.meta['result']['shape']}</TD></TR></TABLE>>"
elif node.meta['find']:
return f"<<TABLE><TR><TD>{node.meta['result']['name']}</TD></TR><TR><TD>{node.meta['result']['shape']}</TD></TR></TABLE>>"
else:
return f"<<TABLE><TR><TD>{node.meta['result']}</TD></TR></TABLE>>"
def single_node(model: torch.nn.Module, graph: graphviz.Digraph, node: torch.fx.Node):
node_label = create_str(node) # 生成当前节点的label
node_kwargs = dict(shape='plaintext',align='center',fontname='monospace')
graph.node(node.name, label=node_label, **node_kwargs) # 在Graphviz图中添加当前节点
# 遍历当前节点的所有输入节点,添加Graphviz图中的边
for in_node in node.all_input_nodes:
edge_kwargs = dict()
if (
not node.meta["find"]
or not in_node.meta["find"]
):
# 如果当前节点的输入和输出中都没有Tensor,就把当前边置为浅灰色虚线,弱化显示
edge_kwargs.update(dict(style="dashed", color="lightgrey"))
# 添加当前边
graph.edge(in_node.name, node.name, **edge_kwargs)
def model_graph(model: torch.nn.Module, *args, **kwargs) -> graphviz.Digraph:
# 将nn.Module转换为torch.fx.GraphModule,获取计算图
symbolic_traced: torch.fx.GraphModule = torch.fx.symbolic_trace(model)
# 执行一下网络,以此获取每个节点输入输出的具体信息
Get_IR(symbolic_traced).run(*args, **kwargs)
# 定义一个Graphviz网络
graph = graphviz.Digraph("model", format="svg", node_attr={"shape": "plaintext"})
for node in symbolic_traced.graph.nodes: # 遍历所有节点
single_node(model, graph, node)
return graph
model = TestModel()
graph = model_graph(model, torch.randn(1, 3, 16, 16), torch.randn(1, 2, 8, 8))
graph.render(directory="test", view=False)
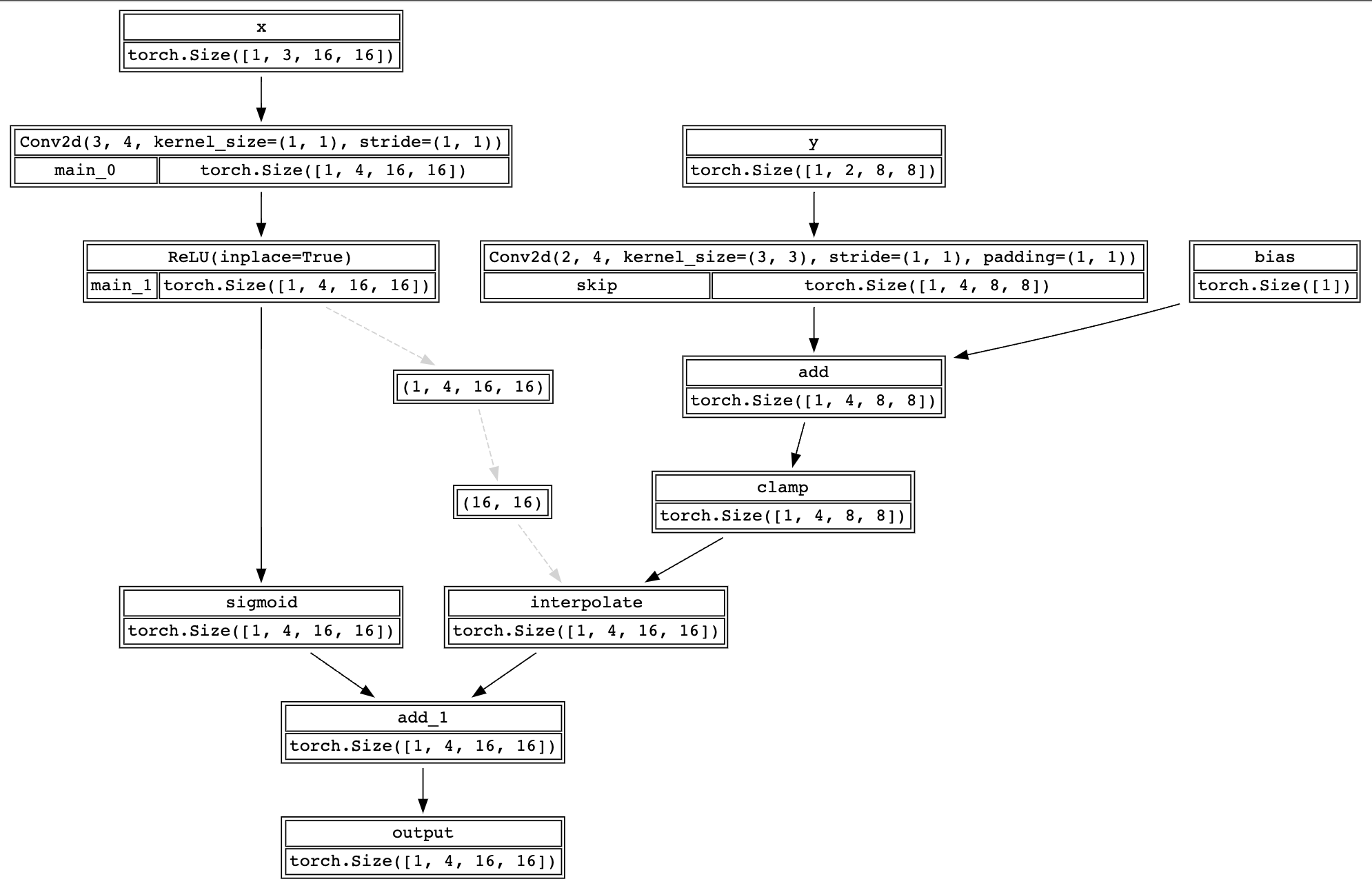
这样来看模型结果就清晰许多,也和博主给出的结果高度还原。当时就是因为看到了这个结构图所以让我好好看了一遍解释器部分的源码来实现这个效果,如果未来自己做推理框架希望也能很清晰直观地给出模型结构图这和简单易用一样都是最基本的。
2.4 量化
在不大幅度减小模型精度的情况下,对已有训练好的模型以低精度执行计算这就是量化。一般对于pytorch就是从FP32(FP16如果有amp)转到INT8
可以参考torch的官方文档https://pytorch.org/docs/master/quantization.html#prototype-fx-graph-mode-quantization
利用fx可以轻松的插入量化节点,并进行校准。不过量化需要已知数据分布,所以下面的步骤就是
- 用某个数据集训一个模型
- 量化
- 校准
- 对比检验
这里我就用resnet18在cifar10上训练得到模型为例,训练部分的代码网上很多这里就不再给出
model=resnet18(pretrained=True)
model.fc=nn.Linear(model.fc.in_features,10)
if not os.path.exists("raw.pth"):
train_model(model,train_loader,test_loader,10,torch.device("mps:0"))
torch.save(model.state_dict(),"raw.pth")
这里说个坑哈,千万别用mac训练太慢了。如果用cuda估计几分钟以内就算完了,但是因为用服务器不能多屏还是觉得不好所以忍着在mac上训练(顺便摸摸鱼)
然后开始量化,参考https://pytorch.org/tutorials/prototype/fx_graph_mode_ptq_dynamic.html#post-training-dynamic-quantization进行后训练动态量化
print(torch.backends.quantized.supported_engines)

这个很重要,得知道使用的平台支持的engine
import os
import time
import copy
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
import torchvision
from torchvision import transforms
from torchvision.models.resnet import resnet18
from torch.quantization.quantize_fx import prepare_fx,convert_fx
from torch.ao.quantization import get_default_qconfig_mapping
from torch.ao.quantization.fx.graph_module import ObservedGraphModule
model=resnet18(pretrained=True)
model.fc=nn.Linear(model.fc.in_features,10)
model.load_state_dict(torch.load("raw.pth",map_location='cpu'))
model.to(torch.device("cpu"))
model.eval()
torch.backends.quantized.engine = 'qnnpack'
qconfig_mapping=get_default_qconfig_mapping("qnnpack")
model_to_quantize=copy.deepcopy(model)
prepared_model=prepare_fx(model_to_quantize,qconfig_mapping,example_inputs=torch.randn([1,3,224,224]))
print(f"prepared model {prepared_model.graph.print_tabular()}")
quantized_model=convert_fx(prepared_model)
print(f"{'='*100}")
print(f"quantized model {quantized_model.graph.print_tabular()}")
这里就载入训练好的模型,然后进行量化。根据官网的例子找到核心内容仿照就好
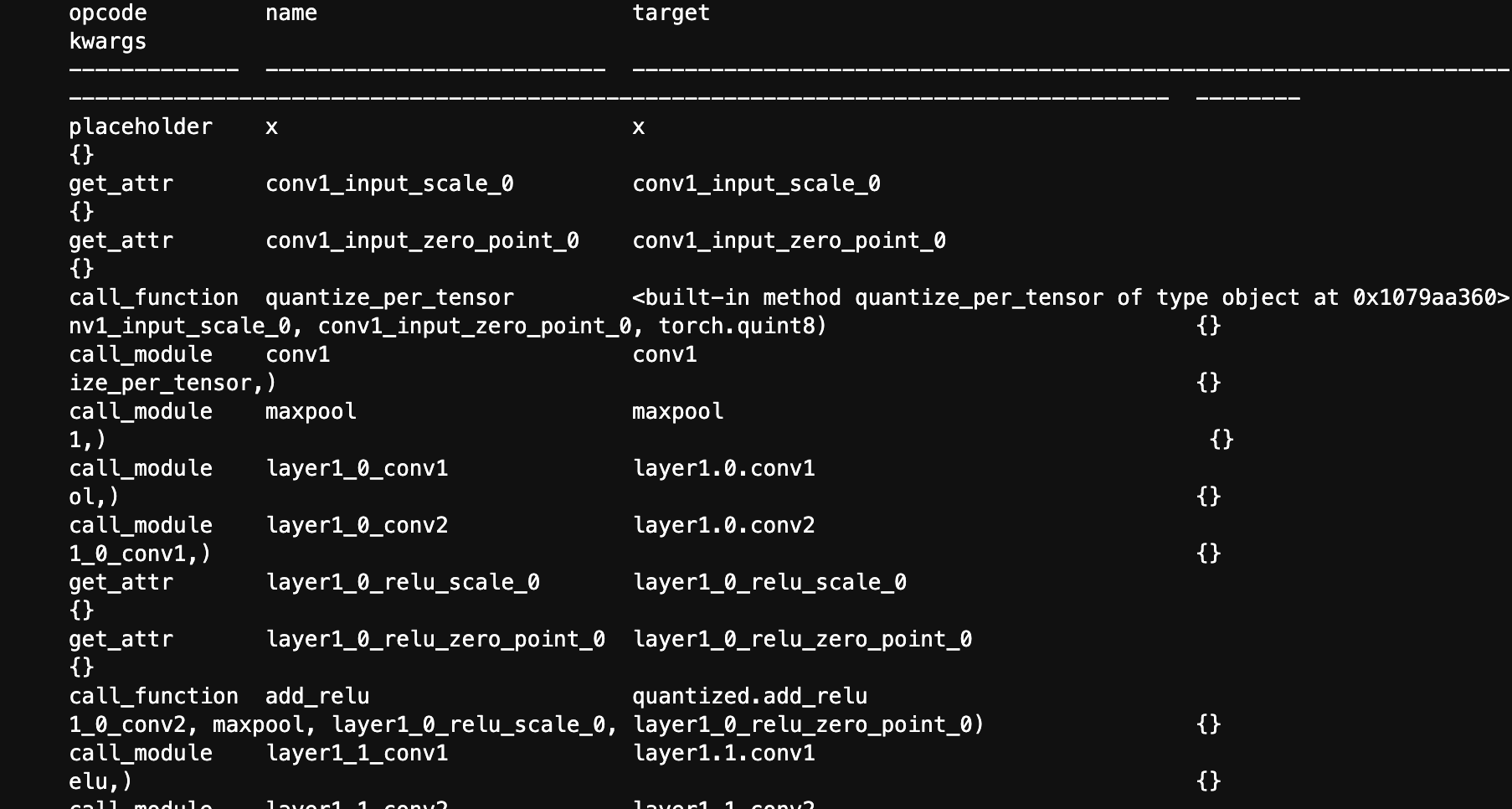
可以看到图中转为了torch.quint8,模型的大小肯定也缩小了很多
def print_size_of_model(model):
torch.save(model.state_dict(),"tmp.pt")
print(f"The model size:{os.path.getsize('tmp.pt')/1e6}MB")
os.remove("tmp.pt")
print_size_of_model(prepared_model)
print_size_of_model(quantized_model)
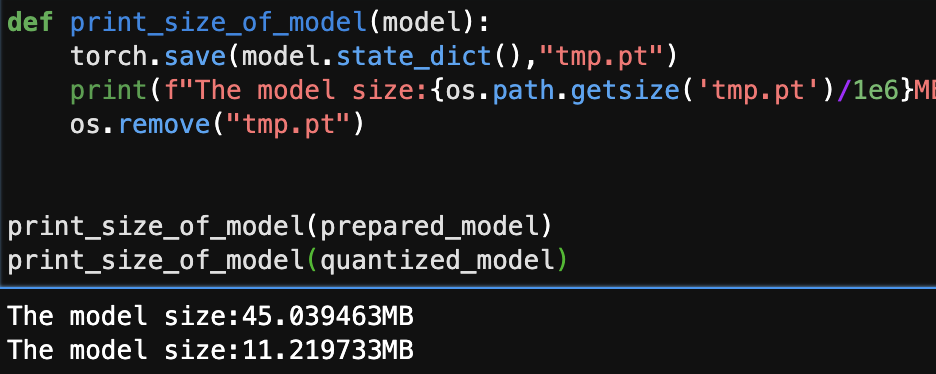
模型大小差不多变成了原来的1/4,但是光变小不行还得看精度
# 测试一下精度
train_loader,test_loader=prepare_dataloader()
example_data=torch.randn([1,3,224,224])
out1=model(example_data)
out2=quantized_model(example_data)
print(torch.allclose(out1,out2,1e-3))
out1
out2
evaluate_model(model,test_loader,device='cpu')
evaluate_model(quantized_model,test_loader,device='cpu')
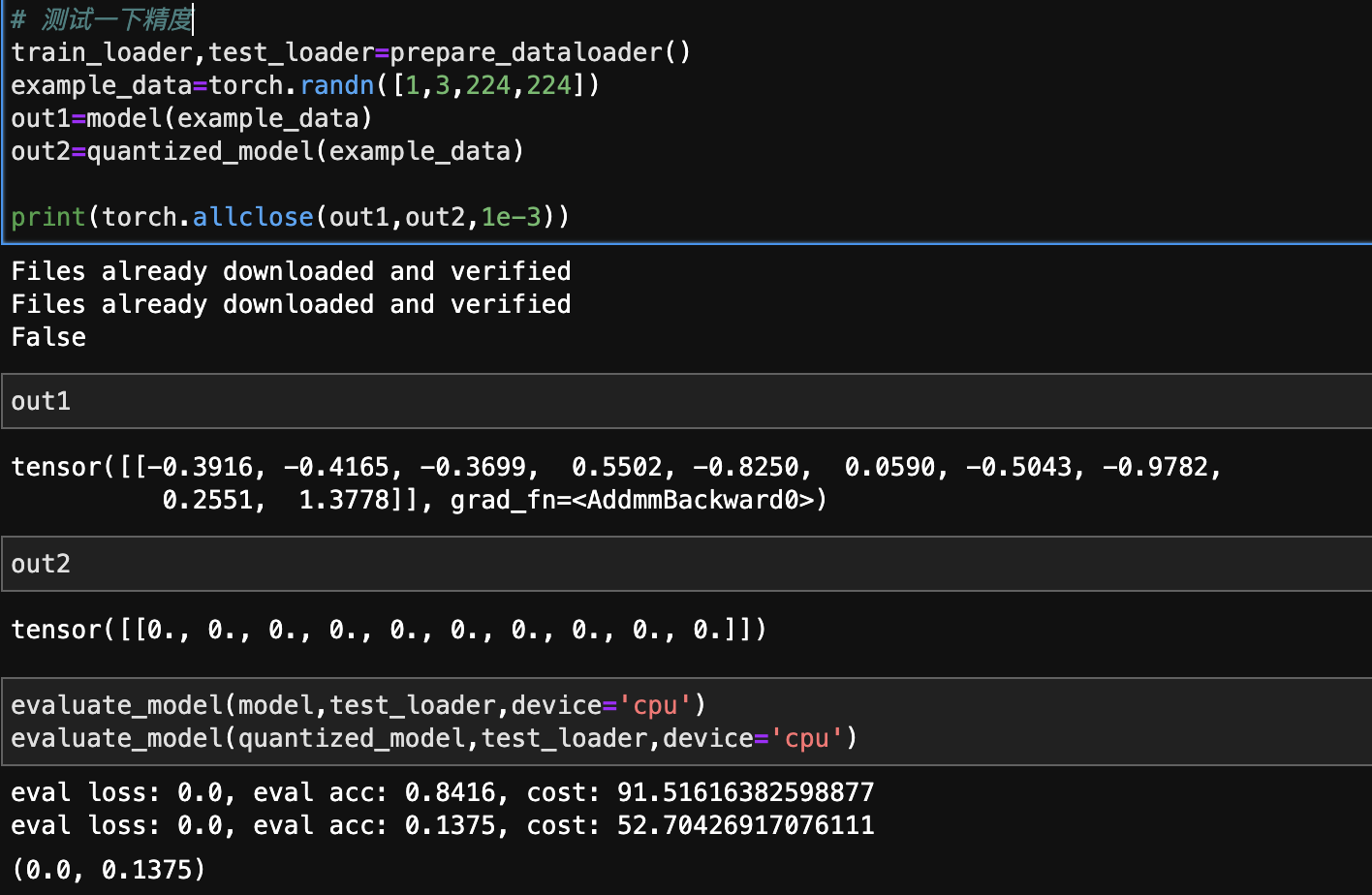
直接G了,这什么鬼呀虽然推理时间差不多少了一半但是这准确率跟瞎猜差不多了,这可不行!!!所以还需要进行量化的重要一步:校准
我们需要已知数据分布的情况下对模型进行量化才能使量化后的模型依然保持准确率,所以下面就进行量化校准
# 校准恢复精度
model_to_quantize=copy.deepcopy(model)
prepared_model=prepare_fx(model_to_quantize,qconfig_mapping,example_inputs=torch.randn([1,3,224,224]))
prepared_model.eval()
with torch.inference_mode():
for inputs,labels in test_loader:
prepared_model(inputs)
quantized_recover_model=convert_fx(prepared_model)
out3=quantized_recover_model(example_data)
print(torch.allclose(out1,out3,1e-3))
out3
evaluate_model(quantized_recover_model,test_loader,device='cpu')
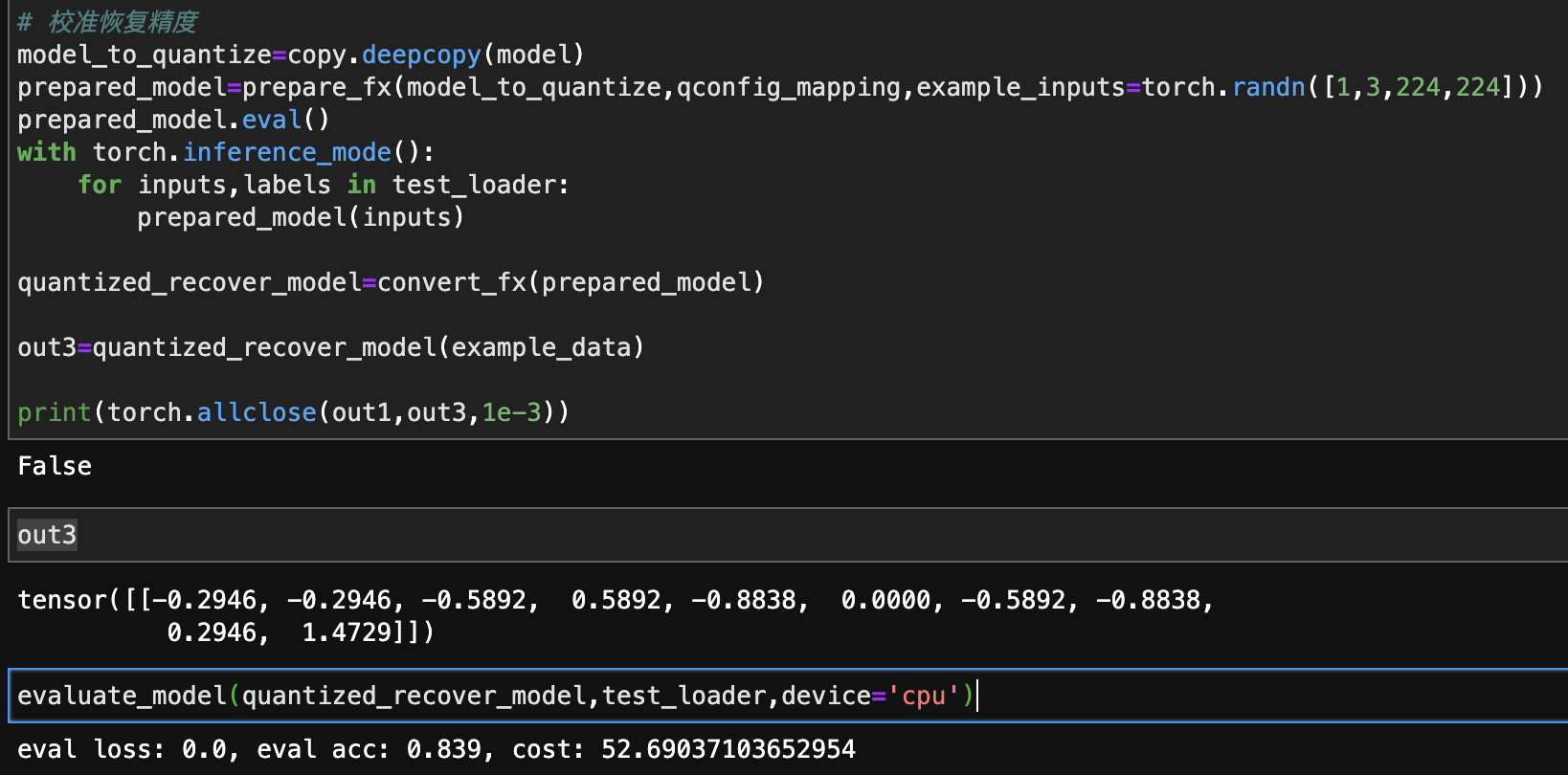

虽然这里精度并没有对齐,但是准确率还是恢复上来了。对于边缘,移动端的部署来说,这么一点点微小的准确率损失可以换来存储占用小75%,推理速度提高一倍,这是谁都能接受的。
最后
看了AI编译器,推理框架后再来看fx,总感觉相似但是又不同。就像之前说的本质上二者就不同,fx只存在于python而不考虑硬件部署上,但是如果我们首先利用fx在python端尽力优化好然后再去推理框架上微调一下结构,那会比反复调整推理框架适应所有可能的算子轻松很多,毕竟python还是比c++写起来坑少很多的,而且这样的话推理框架就可以很自然的附带出python的推理api,希望以后有时间我可以根据这个思路早点写出来。




![[附源码]计算机毕业设计PythonQ宝商城(程序+源码+LW文档)](https://img-blog.csdnimg.cn/019551ff143f4c4888c8476a1a6355eb.png)


![[附源码]Node.js计算机毕业设计黑河市劳务人员管理系统Express](https://img-blog.csdnimg.cn/b3eee7cb0d82457f9742ee98e2bd46e1.png)