1. 入门
from(bucket: "example_query") // 没有筛选条件直接查询会报错
|> range(start: -1h) // |>是管道符,后跟筛选条件2. 序列、表和表流
序列是InfluxDB的概念,一个序列是由measurement、标签集、一个字段名称
表流是FLUX为了兼容关系型数据库和InfluxDB创造的概念

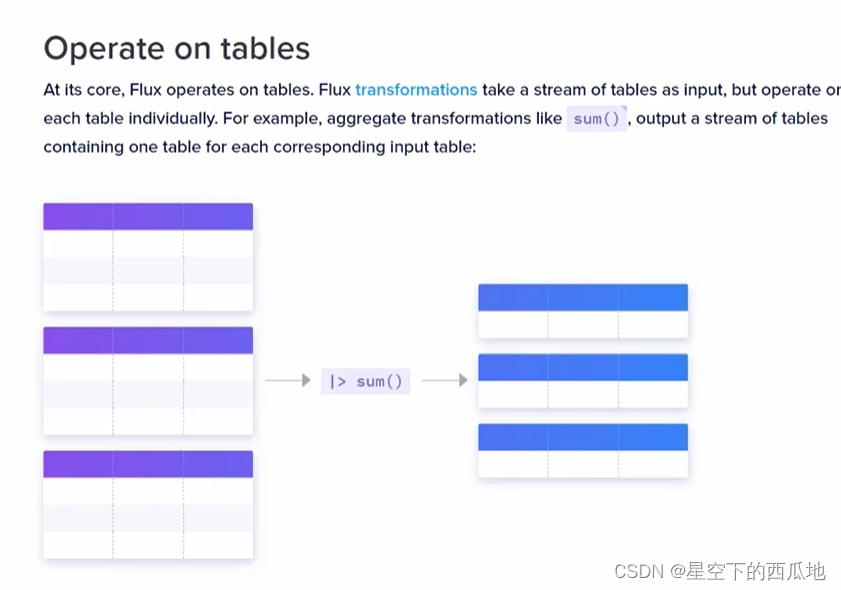
上图整体是表流,table 0、1是FLUX的两张表,对应InfluxDB的两个序列(rate、temp)
图上列名下的GROUP和NO GROUP :通过_measure、_field、code将表分组为多个子表、序列;通过Flux查询时,默认通过这三列分组
max() 最大值
|> max() // 返回结果是每个序列各一行,值为最大值
filter 过筛选滤
from(bucket: "example_query") // 没有筛选条件直接查询会报错
|> range(start: -4h) // |>是管道符,后跟筛选条件,过去4小时
|> filter(fn: (r) => (r:["_measurement"]=="people"))// 筛选测量名称(表名)为people的数据
|> filter(fn: (r) => (r:["code"]=="02"))// 筛选标签code为02的数据
|> filter(fn: (r) => (r:["_measurement"]=="people", onEmpty: "keep"))// onEmpty会让返回的table序号返回未用过的序号,比如数据存储用到0、1、2、3,则会返回4、5
_value类型不同,查询结果会分开,导致数据处理出错。一般加筛选条件过滤,来统一类型

toInt()
将查询结果的_value类型转为Long类型
原始带下划线的字段会与函数有一些约定,像_value/_time,缺失导致一些函数无法使用。
map函数
import "array"
// map函数,遍历表流里面的每一条数据
array.from(rows: [{"name": "tony"}, {"name": "jack"}])
|> map(fn: (r) => {
return if r["name"] == "tony" then {"_name": "tony不是jack"} else {"_name": "jack不是tony"}
})自定义管道函数
// 只能处理流数据,<-是管道函数的标识,table=<-就是流的占位符,调用时无需传入,如toInt()
big100 = (table=<-, x = 100.0) => {
return table
|> map(fn: (r) => ({r with "_value": r["_value"] * x}))
}
from(bucket: "test_init")
|> big100(x: 200.0)开窗 | window和aggregateWindow
// 30s的开窗,改变了原有序列,把整个表流 按照窗口 重新分配(查询结果会出现序号远大于原有序号)
|> window(period: 30s)
// 30s的开窗,不会改变原有序列,必须要指定一个函数
|> aggregateWindow(period: 30s, every: 30s, fn: max)
yield和join
默认返回一个_result,如果想要实现同时返回多个表,需要使用yield来区分,否则会报错
yield主要是为了支持join(.full/.inner/.left/.right/.tables/time),但是不建议使用。建议使用java等语言来处理join的逻辑 (因为InfluxDB不支持缓存,建议使用redis来缓存)
from(bucket: "example_test01")
|> range(start: -4h)
|> yield(name: "tom")
from(bucket: "example_test02")
|> range(start: -4h)
|> yield(name: "jack")