io 模块提供了 Python 用于处理各种 I/O 类型的主要工具。三种主要的 I/O类型分别为: 文本 I/O, 二进制 I/O 和 原始 I/O。
io.open()
是内置的 open() 函数的别名.
语法:
open(
file,
mode='r',
buffering=-1,
encoding=None,
errors=None,
newline=None,
closefd=True,
opener=None,
)参数:
- file:file 是一个类路径对象(path-like object),表示将要打开的文件的路径
- mode:默认为 'r',用于指定打开文件的模式,可见下文介绍。
- buffering:设置缓冲策略
- encoding:是用于解码或编码文件的编码的名称,这只能在文本模式下使用,默认编码依赖于平台,但 Python 支持的任何编码都可以传递。
- errors:指定如何处理编码和解码错误,不能在二进制模式下使用。
- newline:控制如何换行
- closefd:如果 closefd 为 False 且给出的不是文件名而是文件描述符,那么当文件关闭时,底层文件描述符将保持打开状态。如果给出的是文件名,则 closefd 必须为 True (默认值),否则将触发错误。
- opener: 可以通过传递可调用的 opener 来使用自定义开启器。然后通过使用参数( file,flags )调用 opener 获得文件对象的基础文件描述符。 opener 必须返回一个打开的文件描述符(使用 os.open as opener 时与传递 None 的效果相同)。
file参数
file 是一个类路径对象(path-like object),表示将要打开的文件的路径(绝对路径或者相对当前工作目录的路径),也可以是要封装文件对应的整数类型文件描述符。(如果给出的是文件描述符,则当返回的 I/O 对象关闭时它也会关闭,除非将 closefd 设为 False 。)
路径类对象(path-like object)代表一个文件系统路径的对象。类路径对象可以是一个表示路径的 str 或者 bytes 对象,还可以是一个实现了 os.PathLike 协议的对象。一个支持 os.PathLike 协议的对象可通过调用 os.fspath() 函数转换为 str 或者 bytes 类型的文件系统路径;os.fsdecode() 和 os.fsencode() 可被分别用来确保获得 str 或 bytes 类型的结果。此对象是由 PEP 519 引入的。
mode参数
mode 是可选的字符串,用于指定打开文件的模式。默认值是 'r' ,表示以文本模式打开并读取文件。其他常见模式有:写入模式 'w' (已存在文件会被清空)、独占创建模式 'x' 、追加写入模式 'a' (在 某些 Unix 系统中,无论当前文件指针在什么位置,所有 的写入操作都会追加到文件末尾)。在文本模式,如果未指定 encoding ,则会根据当前平台决定编码格式:调用 locale.getpreferredencoding(False) 获取当前地区的编码。若要读写原生字节格式,请使用二进制模式且不要指定 encoding。
可用的模式有:
- 'r':读文件 (默认)
- 'w':打开以进行写入,首先截断文件
- 'x':创建一个新文件并打开它进行写入,如果存在则失败
- 'a':打开进行写入,如果文件存在,则追加到文件末尾
- 'b':二进制模式
- 't':文本模式 (默认)
- '+':打开文件进行更新(读写)
- 'U':通用换行模式(已弃用)
一些规则:
- 默认模式为 'r' (打开文件用于读取文本,与 'rt' 同义)。
- 'w+' 和 'w+b' 模式将打开文件并清空内容。
- 而 'r+' 和 'r+b' 模式将打开文件但不清空内容。
Python 区分二进制和文本I/O。以二进制模式打开的文件(包括 mode 参数中的 'b' )返回的内容为 bytes 对象,不进行任何解码。在文本模式下(默认情况下,或者在 mode 参数中包含 't' )时,文件内容返回为 str ,首先使用指定的 encoding (如果给定)或者使用平台默认的的字节编码解码。
另外还有一种模式字符 'U' 可用,不过它已失效,并视作弃用。以前它会在文本模式中启用 universal newlines,这在 Python 3.0 已成为默认行为。详情请参阅 newline 形参的文档。
Python不依赖于底层操作系统的文本文件概念,所有处理都由Python本身完成,因此与平台无关。
缓冲策略
buffering 是用于设置缓冲策略的可选整数。规则有:
缓冲是用于设置缓冲策略的可选整数。规则有:
- 传递 0 以关闭缓冲(仅在二进制模式下允许)
- 传递 1 以选择行缓冲(仅在文本模式下可用)
- 传递大于1的整数以指示固定大小块缓冲区的字节大小
- 如果取负值,寄存区的缓冲大小则为系统默认
如果未给出缓冲参数(使用默认的或者负值),默认缓冲策略的工作方式如下:
- 二进制文件缓冲在固定大小的块中; 缓冲区的大小使用启发式选择,试图确定底层设备的默认缓冲区块大小(block size)和 回溯到
io.DEFAULT_BUFFER_SIZE和回溯到io。默认缓冲区大小。在许多系统上,缓冲区的长度通常为4096或8192字节。 - “交互式”文本文件( satty() 返回 True的文件)使用行缓冲。其他文本文件使用上述策略用于二进制文件。
错误处理
errors 是一个可选的字符串参数,用于指定如何处理编码和解码错误 - 这不能在二进制模式下使用。可以使用各种标准错误处理程序(列在 错误处理方案 ),但是使用 codecs.register_error() 注册的任何错误处理名称也是有效的。标准名称包括:
- 如果存在编码错误,'strict' 会引发 ValueError 异常。 默认值 None 具有相同的效果。
- 'ignore' 忽略错误。请注意,忽略编码错误可能会导致数据丢失。
- 'replace' 会将替换标记(例如 '?' )插入有错误数据的地方。
- 'surrogateescape' 将把任何不正确的字节表示为
U+DC80至U+DCFF范围内的下方替代码位。 当在写入数据时使用 - surrogateescape 错误处理句柄时这些替代码位会被转回到相同的字节。 这适用于处理具有未知编码格式的文件。
- 只有在写入文件时才支持 'xmlcharrefreplace'。编码不支持的字符将替换为相应的XML字符引用
&#nnn;。 - 'backslashreplace' 用Python的反向转义序列替换格式错误的数据。
- 'namereplace' (也只在编写时支持)用
\N{...}转义序列替换不支持的字符。
换行控制
newline 控制 universal newlines 模式如何生效(它仅适用于文本模式)。它可以是 None,'','\n','\r' 和 '\r\n'。它的工作原理:
- 从流中读取输入时,如果 newline 为 None,则启用通用换行模式。输入中的行可以以 '\n','\r' 或 '\r\n' 结尾,这些行被翻译成 '\n' 在返回呼叫者之前。如果它是 '',则启用通用换行模式,但行结尾将返回给调用者未翻译。如果它具有任何其他合法值,则输入行仅由给定字符串终止,并且行结尾将返回给未调用的调用者。
- 将输出写入流时,如果 newline 为 None,则写入的任何 '\n' 字符都将转换为系统默认行分隔符 os.linesep。如果 newline 是 '' 或 '\n',则不进行翻译。如果 newline 是任何其他合法值,则写入的任何 '\n' 字符将被转换为给定的字符串。
文件对象
open() 函数所返回的 file object 类型取决于所用模式。 当使用 open() 以文本模式 ('w', 'r', 'wt', 'rt' 等) 打开文件时,它将返回 io.TextIOBase (特别是 io.TextIOWrapper) 的一个子类。 当使用缓冲以二进制模式打开文件时,返回的类是 io.BufferedIOBase 的一个子类。 具体的类会有多种:在只读的二进制模式下,它将返回 io.BufferedReader;在写入二进制和追加二进制模式下,它将返回 io.BufferedWriter,而在读/写模式下,它将返回 io.BufferedRandom。 当禁用缓冲时,则会返回原始流,即 io.RawIOBase 的一个子类 io.FileIO。
以下是一些常见的 file 对象常用方法:
f.read([size]):size 未指定则返回整个文件,如果文件大小 >2 倍内存则有问题,f.read()读到文件尾时返回""(空字串)。f.readline():返回一行。f.readlines([size]):返回包含size行的列表, size 未指定则返回全部行。for line in f: print line:通过迭代器访问。f.write("hello\n"):如果要写入字符串以外的数据,先将他转换为字符串。f.tell():返回一个整数,表示当前文件指针的位置(就是到文件头的字节数)。f.seek(偏移量,[起始位置]):用来移动文件指针。- 偏移量: 单位为字节,可正可负
- 起始位置: 0 - 文件头, 默认值; 1 - 当前位置; 2 - 文件尾
f.close()关闭文件
>>> import os
>>> dir_fd = os.open('somedir', os.O_RDONLY)
>>> def opener(path, flags):
... return os.open(path, flags, dir_fd=dir_fd)
...
>>> with open('spamspam.txt', 'w', opener=opener) as f:
... print('This will be written to somedir/spamspam.txt', file=f)
...
>>> os.close(dir_fd) # 不要泄露文件描述符IO的类关系图
I/O 流被安排为按类的层次结构实现,继承关系如下图:
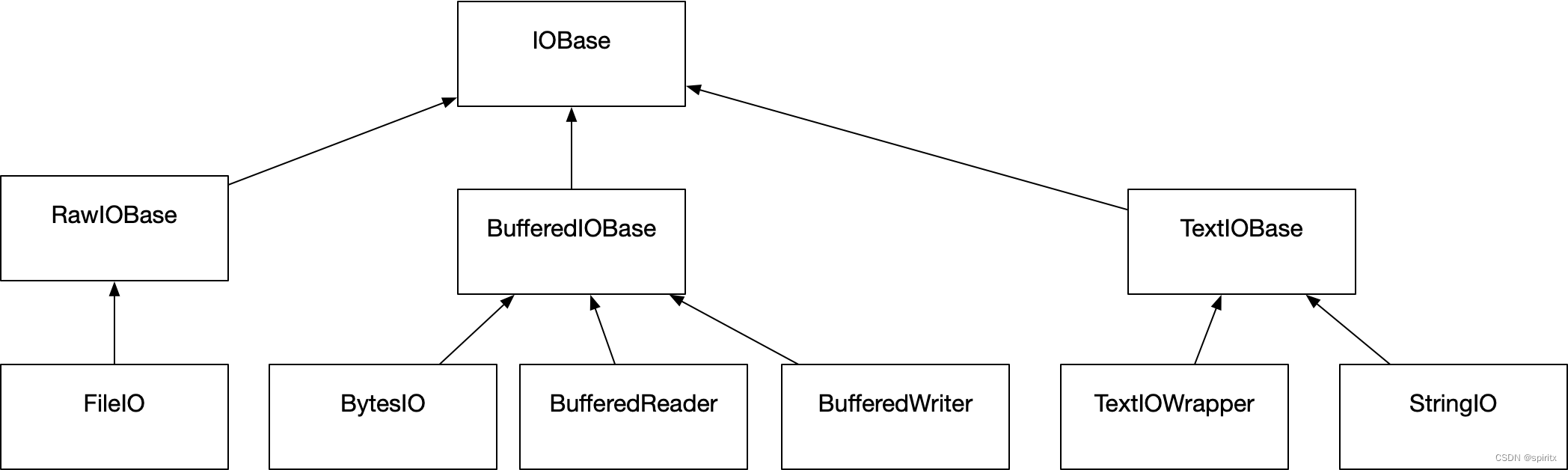
IO的基类
class io.IOBase
所有 I/O 类的抽象基类。
此类为许多方法提供了空的抽象实现,派生类提供了具体的实现。
IOBase.close()
刷新并关闭此流。如果文件已经关闭,则此方法无效。文件关闭后,对文件的任何操作(例如读取或写入)都会引发 ValueError 。
IOBase.closed
如果流已关闭,则返回 True。
IOBase.fileno()
返回流的底层文件描述符(整数)---如果存在。如果 IO 对象不使用文件描述符,则会引发 OSError 。
IOBase.flush()
刷新流的写入缓冲区(如果适用)。这对只读和非阻塞流不起作用。
IOBase.isatty()
如果流是交互式的(即连接到终端/tty设备),则返回 True 。
IOBase.readable()
如果可以读取流则返回 True。 如果返回 False,则 read() 将引发 OSError。
IOBase.readline(size=- 1, /)
从流中读取并返回一行。如果指定了 size,将至多读取 size 个字节。
对于二进制文件行结束符总是 b'\n';对于文本文件,可以用将 newline 参数传给 open() 的方式来选择要识别的行结束符。
IOBase.readlines(hint=- 1, /)
从流中读取并返回包含多行的列表。可以指定 hint 来控制要读取的行数:如果(以字节/字符数表示的)所有行的总大小超出了 hint 则将不会读取更多的行。
0 或更小的 hint 值以及 None,会被视为没有 hint。
请注意,在不调用 file.readlines() 的情况下使用 for line in file: ... 来遍历文件对象已经成为可能。
IOBase.seek(offset, whence=os.SEEK_SET, /)
重新定位流的当前位置的偏移量,whence指定偏移量的起始位置
- os.SEEK_SET or 0 -- 流的开始位置 (默认值); 偏移量offset必须是非负整数(0,或正整数)
- os.SEEK_CUR or 1 -- 流的当前位置;偏移量 offset可以是负整数
- os.SEEK_END or 2 -- 流结尾位置;偏移量offset通常是负整数
IOBase.seekable()
如果流支持随机访问(重新定位当前位置)则返回 True。 如为 False,则 seek(), tell() 和 truncate() 将引发 OSError。
IOBase.tell()
返回当前流的位置。
IOBase.truncate(size=None, /)
将流的大小调整为给定的 size 个字节(如果未指定 size 则调整至当前位置)。 当前的流位置不变。 这个调整操作可扩展或减小当前文件大小。 在扩展的情况下,新文件区域的内容取决于具体平台(在大多数系统上,额外的字节会填充为零)。 返回新的文件大小。
在 3.5 版更改: 现在Windows在扩展时将文件填充为零。
IOBase.writable()
如果流支持写入则返回 True。 如为 False,则 write() 和 truncate() 将引发 OSError。
IOBase.writelines(lines, /)
将行列表写入到流。 不会添加行分隔符,因此通常所提供的每一行都带有末尾行分隔符。
IOBase.__del__()
为对象销毁进行准备。 IOBase 提供了此方法的默认实现,该实现会调用实例的 close() 方法。
class io.RawIOBase
原始二进制流的基类。 它继承自 IOBase 。
原始二进制流通常会提供对下层 OS 设备或 API 的低层级访问,而不是尝试将其封装到高层级的类中。
RawIOBase 在 IOBase 的现有成员以外还提供了下列方法:
RawIOBase.read(size=- 1, /)
从对象中读取 size 个字节并将其返回。 作为一个便捷选项,如果 size 未指定或为 -1,则返回所有字节直到 EOF。 在其他情况下,仅会执行一次系统调用。 如果操作系统调用返回字节数少于 size 则此方法也可能返回少于 size 个字节。
如果返回 0 个字节而 size 不为零 0,这表明到达文件末尾。 如果处于非阻塞模式并且没有更多字节可用,则返回 None。
默认实现会转至 readall() 和 readinto()。
RawIOBase.readall()
从流中读取并返回所有字节直到 EOF,如有必要将对流执行多次调用。
RawIOBase.readinto(b, /)
将字节数据读入预先分配的可写 bytes-like object b,并返回所读取的字节数。 例如,b 可以是一个 bytearray。 如果对象处理非阻塞模式并且没有更多字节可用,则返回 None。
RawIOBase.write(b, /)
将给定的 bytes-like object b 写入到下层的原始流,并返回所写入的字节数。 这可以少于 b 的总字节数,具体取决于下层原始流的设定,特别是如果它处于非阻塞模式的话。 如果原始流设为非阻塞并且不能真正向其写入单个字节时则返回 None。 调用者可以在此方法返回后释放或改变 b,因此该实现应该仅在方法调用期间访问 b。
class io.BufferedIOBase
支持某种缓冲的二进制流的基类。 它继承自 IOBase。
与 RawIOBase 的主要差别在于 read(), readinto() 和 write() 等方法将(分别)尝试按照要求读取尽可能多的输入或是耗尽所有给定的输出,其代价是可能会执行一次以上的系统调用。
除此之外,那些方法还可能引发 BlockingIOError,如果下层的原始数据流处于非阻塞模式并且无法接受或给出足够数据的话;不同于对应的 RawIOBase 方法,它们将永远不会返回 None。
并且,read() 方法也没有转向 readinto() 的默认实现。
典型的 BufferedIOBase 实现不应当继承自 RawIOBase 实现,而要包装一个该实现,正如 BufferedWriter 和 BufferedReader 所做的那样。
BufferedIOBase 在 IOBase 的现有成员以外还提供或重载了下列数据属性和方法:
BufferedIOBase.raw
由 BufferedIOBase 处理的下层原始流 (RawIOBase 的实例)。 它不是 BufferedIOBase API 的组成部分并且不存在于某些实现中。
BufferedIOBase.detach()
从缓冲区分离出下层原始流并将其返回。
在原始流被分离之后,缓冲区将处于不可用的状态。
某些缓冲区例如 BytesIO 并无可从此方法返回的单独原始流的概念。 它们将会引发 UnsupportedOperation。
3.1 新版功能.
BufferedIOBase.read(size=- 1, /)
读取并返回最多 size 个字节。 如果此参数被省略、为 None 或为负值,则读取并返回所有数据直到 EOF。 如果流已经到达 EOF 则返回一个空的 bytes 对象。
如果此参数为正值,并且下层原始流不可交互,则可能发起多个原始读取以满足字节计数(直至先遇到 EOF)。 但对于可交互原始流,则将至多发起一个原始读取,并且简短的结果并不意味着已到达 EOF。
BlockingIOError 会在下层原始流不处于阻塞模式,并且当前没有可用数据时被引发。
BufferedIOBase.read1(size=- 1, /)
通过至多一次对下层流的 read() (或 readinto()) 方法的调用读取并返回至多 size 个字节。 这适用于在 BufferedIOBase 对象之上实现你自己的缓冲区的情况。
如果 size 为 -1 (默认值),则返回任意数量的字节(多于零字节,除非已到达 EOF)。
BufferedIOBase.readinto(b, /)
将字节数据读入预先分配的可写 bytes-like object b 并返回所读取的字节数。 例如,b 可以是一个 bytearray。
类似于 read(),可能对下层原始流发起多次读取,除非后者为交互式。
BlockingIOError 会在下层原始流不处于阻塞模式,并且当前没有可用数据时被引发。
BufferedIOBase.readinto1(b, /)
将字节数据读入预先分配的可写 bytes-like object b,其中至多使用一次对下层原始流 read() (或 readinto()) 方法的调用。 返回所读取的字节数。
BlockingIOError 会在下层原始流不处于阻塞模式,并且当前没有可用数据时被引发。
3.5 新版功能.
BufferedIOBase.write(b, /)
写入给定的 bytes-like object b,并返回写入的字节数 (总是等于 b 的字节长度,因为如果写入失败则会引发 OSError)。 根据具体实现的不同,这些字节可能被实际写入下层流,或是出于运行效率和冗余等考虑而暂存于缓冲区。
当处于非阻塞模式时,如果需要将数据写入原始流但它无法在不阻塞的情况下接受所有数据则将引发 BlockingIOError。
调用者可能会在此方法返回后释放或改变 b,因此该实现应当仅在方法调用期间访问 b。
class io.FileIO
完整语法定义为:
class io.FileIO(name, mode='r', closefd=True, opener=None)
代表一个包含字节数据的 OS 层级文件的原始二进制流。 它继承自 RawIOBase。
name 可以是以下两项之一:
- 代表将被打开的文件路径的字符串或 bytes 对象。 在此情况下 closefd 必须为 True (默认值) 否则将会引发异常。
- 代表一个现有 OS 层级文件描述符的号码的整数,作为结果的 FileIO 对象将可访问该文件。 当 FileIO 对象被关闭时此 fd 也将被关闭,除非 closefd 设为 False。
mode 可以为 'r', 'w', 'x' 或 'a' 分别表示读取(默认模式)、写入、独占新建或添加。 如果以写入或添加模式打开的文件不存在将自动新建;当以写入模式打开时文件将先清空。 以新建模式打开时如果文件已存在则将引发 FileExistsError。 以新建模式打开文件也意味着要写入,因此该模式的行为与 'w' 类似。 在模式中附带 '+' 将允许同时读取和写入。
该类的 read() (当附带为正值的参数调用时), readinto() 和 write() 方法将只执行一次系统调用。
可以通过传入一个可调用对象作为 opener 来使用自定义文件打开器。 然后通过调用 opener 并传入 (name, flags) 来获取文件对象所对应的下层文件描述符。 opener 必须返回一个打开文件描述符(传入 os.open 作为 opener 的结果在功能上将与传入 None 类似)。
新创建的文件是 不可继承的。
在 3.3 版更改: 增加了 opener 参数。增加了 'x' 模式。
在 3.4 版更改: 文件现在禁止继承。
FileIO 在继承自 RawIOBase 和 IOBase 的现有成员以外还提供了以下数据属性和方法:
mode
构造函数中给定的模式。
name
文件名。当构造函数中没有给定名称时,这是文件的文件描述符。
class io.BytesIO
缓冲流,语法为:
class io.BytesIO(initial_bytes=b'')
相比原始 I/O,缓冲 I/O 流提供了针对 I/O 设备的更高层级接口。
一个使用内在字节缓冲区的二进制流。 它继承自 BufferedIOBase。 在 close() 方法被调用时将会丢弃缓冲区。
可选参数 initial_bytes 是一个包含初始数据的 bytes-like object。
import io
stream_str = io.BytesIO(b"JournalDev Python: \x00\x01")
print(stream_str.getvalue())
#b'JournalDev Python: \x00\x01'BytesIO 在继承自 BufferedIOBase 和 IOBase 的成员以外还提供或重载了下列方法:
BytesIO.getbuffer()
返回一个对应于缓冲区内容的可读写视图而不必拷贝其数据。 此外,改变视图将透明地更新缓冲区内容:
>>>b = io.BytesIO(b"abcdef")
>>>view = b.getbuffer()
>>>view[2:4] = b"56"
>>>b.getvalue()
b'ab56ef'class io.BufferedReader
语法为:
class io.BufferedReader(raw, buffer_size=DEFAULT_BUFFER_SIZE)
一个提供对可读、不可查找的 RawIOBase 原始二进制流的高层级访问的缓冲二进制流。 它继承自 BufferedIOBase。
当从此对象读取数据时,可能会从下层原始流请求更大量的数据,并存放到内部缓冲区中。 接下来可以在后续读取时直接返回缓冲数据。
根据给定的可读 raw 流和 buffer_size 创建 BufferedReader 的构造器。 如果省略 buffer_size,则会使用 DEFAULT_BUFFER_SIZE。
BufferedReader 在继承自 BufferedIOBase 和 IOBase 的成员以外还提供或重载了下列方法:
BufferedReader.peek(size=0, /)
从流返回字节数据而不前移位置。 完成此调用将至多读取一次原始流。 返回的字节数量可能少于或多于请求的数量。
BufferedReader.read(size=- 1, /)
读取并返回 size 个字节,如果 size 未给定或为负值,则读取至 EOF 或是在非阻塞模式下读取调用将会阻塞。
BufferedReader.read1(size=- 1, /)
在原始流上通过单次调用读取并返回至多 size 个字节。 如果至少缓冲了一个字节,则只返回缓冲的字节。 在其他情况下,将执行一次原始流读取。
在 3.7 版更改: size 参数现在是可选的。
io.BufferedWriter
语法格式为:
class io.BufferedWriter(raw, buffer_size=DEFAULT_BUFFER_SIZE)
一个提供对可写、不可查找的 RawIOBase 原始二进制流的高层级访问的缓冲二进制流。 它继承自 BufferedIOBase。
当写入到此对象时,数据通常会被放入到内部缓冲区中。 缓冲区将在满足某些条件的情况下被写到下层的 RawIOBase 对象,包括:
- 当缓冲区对于所有挂起数据而言太小时;
- 当 flush() 被调用时;
- 当 seek() 被请求时(针对 BufferedRandom 对象);
- 当 BufferedWriter 对象被关闭或销毁时。
该构造器会为给定的可写 raw 流创建一个 BufferedWriter。 如果未给定 buffer_size,则使用默认的 DEFAULT_BUFFER_SIZE。
BufferedWriter 在继承自 BufferedIOBase 和 IOBase 的成员以外还提供或重载了下列方法:
BufferedWriter.flush()
将缓冲区中保存的字节数据强制放入原始流。 如果原始流发生阻塞则应当引发 BlockingIOError。
BufferedWriter.write(b, /)
写入 bytes-like object b 并返回写入的字节数。 当处于非阻塞模式时,如果缓冲区需要被写入但原始流发生阻塞则将引发 BlockingIOError。
class io.BufferedRandom
语法为:
class io.BufferedRandom(raw, buffer_size=DEFAULT_BUFFER_SIZE)
一个提供对不可查找的 RawIOBase 原始二进制流的高层级访问的缓冲二进制流。 它继承自 BufferedReader 和 BufferedWriter。
该构造器会为在第一个参数中给定的可查找原始流创建一个读取器和写入器。 如果省略 buffer_size 则使用默认的 DEFAULT_BUFFER_SIZE。
BufferedRandom 能做到 BufferedReader 或 BufferedWriter 所能做的任何事。 此外,还会确保实现 seek() 和 tell()。
class io.BufferedRWPair
语法为:
class io.BufferedRWPair(reader, writer, buffer_size=DEFAULT_BUFFER_SIZE, /)
一个提供对两个不可查找的 RawIOBase 原始二进制流的高层级访问的缓冲二进制流 --- 一个可读,另一个可写。 它继承自 BufferedIOBase。
reader 和 writer 分别是可读和可写的 RawIOBase 对象。 如果省略 buffer_size 则使用默认的 DEFAULT_BUFFER_SIZE。
BufferedRWPair 实现了 BufferedIOBase 的所有方法,但 detach() 除外,调用该方法将引发 UnsupportedOperation。
文本IO
文本I/O预期并生成 str 对象。这意味着,无论何时后台存储是由字节组成的(例如在文件的情况下),数据的编码和解码都是透明的,并且可以选择转换特定于平台的换行符。
创建文本流的最简单方法是使用 open(),可以选择指定编码:
f = open("myfile.txt", "r", encoding="utf-8")
内存中文本流也可以作为 StringIO 对象使用:
f = io.StringIO("some initial text data")
class io.TextIOBase
文本流的基类。 该类提供了基于字符和行的流 I/O 接口。 它继承自 IOBase。
TextIOBase 在来自 IOBase 的成员以外还提供以下数据属性和方法:
TextIOBase.encoding
用于将流的字节串解码为字符串以及将字符串编码为字节串的编码格式名称。
TextIOBase.errors
解码器或编码器的错误设置。
TextIOBase.newlines
一个字符串、字符串元组或者 None,表示目前已经转写的新行。 根据具体实现和初始构造器旗标的不同,此属性或许会不可用。
TextIOBase.read(size=- 1, /)
从流中读取至多 size 个字符并以单个str的形式返回。 如果 size 为负值或 None,则读取至 EOF。
TextIOBase.readline(size=- 1, /)
读取至换行符或 EOF 并返回单个str。 如果流已经到达 EOF,则将返回一个空字符串。, an empty string is returned.
TextIOBase.write(s, /)
将字符串 s 写入到流并返回写入的字符数。
class io.TextIOWrapper
class io.TextIOWrapper(buffer, encoding=None, errors=None, newline=None, line_buffering=False, write_through=False)
一个提供对 BufferedIOBase 缓冲二进制流的高层级访问的缓冲文本流。 它继承自 TextIOBase。
- encoding 给出流的解码或编码要使用的编码格式的名称。 它默认为 locale.getencoding()。 encoding="locale" 可被用来显式地指定当前语言区域的编码格式。 请参阅 文本编码格式 了解更多信息。
- errors 是一个可选的字符串,它指明编码格式和编码格式错误的处理方式。
- strict:传入 'strict' 将在出现编码格式错误时引发 ValueError (默认值 None 具有相同的效果)
- ignore:传入 'ignore' 将忽略错误。 (请注意忽略编码格式错误会导致数据丢失。)
- replace: 会在出现错误数据时插入一个替换标记 (例如 '?')。
- backslashreplace: 将把错误数据替换为一个反斜杠转义序列。
- xmlcharrefreplace: 替换为适当的 XML 字符引用
- namereplace: (替换为 \N{...} 转义序列)。
- 任何其他通过 codecs.register_error() 注册的错误处理方式名称也可以被接受。
- newline 控制行结束符处理方式。 它可以为 None, '', '\n', '\r' 和 '\r\n'。 其工作原理如下:
- 当从流读取输入时,如果 newline 为 None,则将启用 universal newlines 模式。 输入中的行结束符可以为 '\n', '\r' 或 '\r\n',在返回给调用者之前它们会被统一转写为 '\n'。 如果 newline 为 '',也会启用通用换行模式,但行结束符会不加转写即返回给调用者。 如果 newline 具有任何其他合法的值,则输入行将仅由给定的字符串结束,并且行结束符会不加转写即返回给调用者。
- 将输出写入流时,如果 newline 为 None,则写入的任何 '\n' 字符都将转换为系统默认行分隔符 os.linesep。如果 newline 是 '' 或 '\n',则不进行翻译。如果 newline 是任何其他合法值,则写入的任何 '\n' 字符将被转换为给定的字符串。
- 如果 line_buffering 为 True,则当一个写入调用包含换行或回车符时将会应用 flush()。
- 如果 write_through 为 True,则对 write() 的调用会确保不被缓冲:在 TextIOWrapper 对象上写入的任何数据会立即交给其下层的 buffer 来处理。
在 3.3 版更改: 已添加 write_through 参数
在 3.3 版更改: 默认的 encoding 现在将为 locale.getpreferredencoding(False) 而非 locale.getpreferredencoding()。 不要使用 locale.setlocale() 来临时改变区域编码格式,要使用当前区域编码格式而不是用户的首选编码格式。
在 3.10 版更改: encoding 参数现在支持 "locale" 作为编码格式名称。
TextIOWrapper 在继承自 TextIOBase 和 IOBase 的现有成员以外还提供了以下数据属性和方法:
TextIOWrapper.line_buffering
是否启用行缓冲。
TextIOWrapper.write_through
写入是否要立即传给下层的二进制缓冲。
3.7 新版功能.
TextIOWrapper.reconfigure()
reconfigure(*, encoding=None, errors=None, newline=None, line_buffering=None, write_through=None)
使用 encoding, errors, newline, line_buffering 和 write_through 的新设置来重新配置此文本流。
未指定的形参将保留当前设定,例外情况是当指定了 encoding 但未指定 errors 时将会使用 errors='strict'。
如果已经有数据从流中被读取则将无法再改变编码格式或行结束符。 另一方面,在写入数据之后再改变编码格式则是可以的。
此方法会在设置新的形参之前执行隐式的流刷新。
3.7 新版功能.
在 3.11 版更改: 此方法支持 encoding="locale" 选项。
class io.StringIO
class io.StringIO(initial_value='', newline='\n')
一个使用内存文本缓冲的文本流。 它继承自 TextIOBase。
当 close() 方法被调用时将会丢弃文本缓冲区。
- 缓冲区的初始值可通过提供 initial_value 来设置。 如果启用了换行符转写,换行符将以与 write() 相同的方式进行编码。 流将被定位到缓冲区的起点,这模拟了以 w+ 模式打开一个现有文件的操作,使其准备好从头开始立即写入或是将要覆盖初始值的写入。 要模拟以 a+ 模式打开一个文件准备好追加内容,请使用 f.seek(0, io.SEEK_END) 来将流重新定位到缓冲区的末尾。
- newline 参数的规则与 TextIOWrapper 所用的一致,不同之处在于当将输出写入到流时,如果 newline 为 None,则在所有平台上换行符都会被写入为 \n。
StringIO 在继承自 TextIOBase 和 IOBase 的现有成员以外还提供了以下方法:
StringIO.getvalue()
返回一个 包含缓冲区全部内容的 str。 换行符会以与 read() 相同的方式被编码,但是流位置不会改变。
用法示例:
import io
output = io.StringIO()
output.write('First line.\n')
print('Second line.', file=output)
# Retrieve file contents -- this will be
# 'First line.\nSecond line.\n'
contents = output.getvalue()
# Close object and discard memory buffer --
# .getvalue() will now raise an exception.
output.close()import io
data = io.StringIO()
data.write('JournalDev: ')
print('Python.', file=data)
print(data.getvalue()) #JournalDev: Python.
data.close()
input = io.StringIO('This goes into the read buffer.')
print(input.read()) #This goes into the read buffer.



![The WebSocket session [x] has been closed and no method (apart from close())](https://img-blog.csdnimg.cn/1f53af5b1f214d7c87b8ffa236d75483.png)