路漫漫其修远兮,吾将上下而求索
这次写一个最简单的python爬虫代码,也是大多教程第一次爬取的,代码里面有个别的简单介绍,希望能加深您对python爬虫的理解。
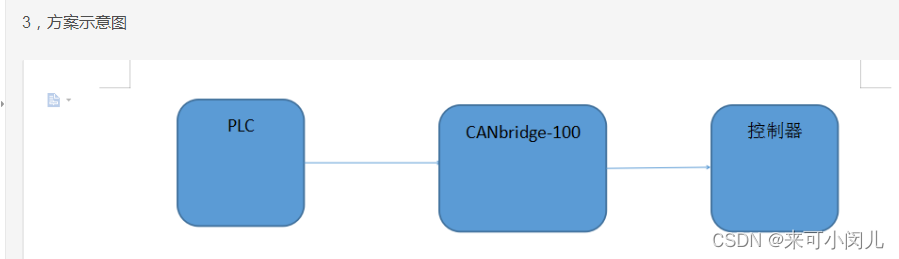
本次爬取两个网页数据
一 爬取的网站 豆瓣电影
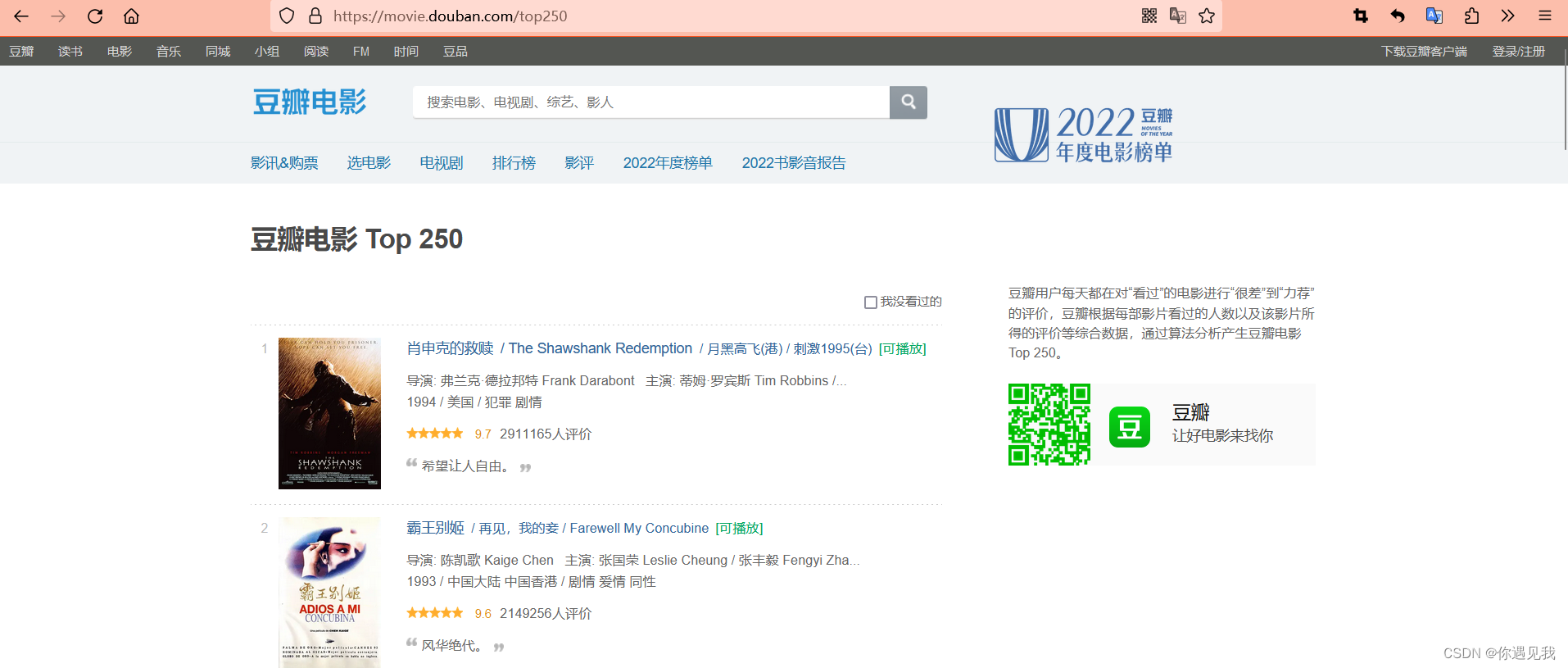
爬取网页中的(肖申克的救赎 1994 评分是: 9.7 共 911165人评价)
(电影名, 年份, 评分,评价人数)
代码
import csv
import re,requests
#拿到源代码 requests,通过re获取想要的数据,csv写入操作
url='https://movie.douban.com/top250'
h={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'
}
r=requests.get(url,headers=h);r.encoding='utf-8'
yuanma=r.text# 拿到网页源代码
#解析数据
obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="".*?<br>(?P<year>.*?) .*?property="v:average".(?P<pf>.*?)</span>'
r'.*?<span>.(?P<pl>.*?)</span>',re.S)
#开始匹配
r=obj.finditer(yuanma)
f=open('shuju.csv',mode='w')#打开一个文件
csvs=csv.writer(f)
for i in r:
print(i.group("name"),i.group("year").strip(),'评分是:',i.group('pf'),'共',i.group('pl'))#strip()去掉空白
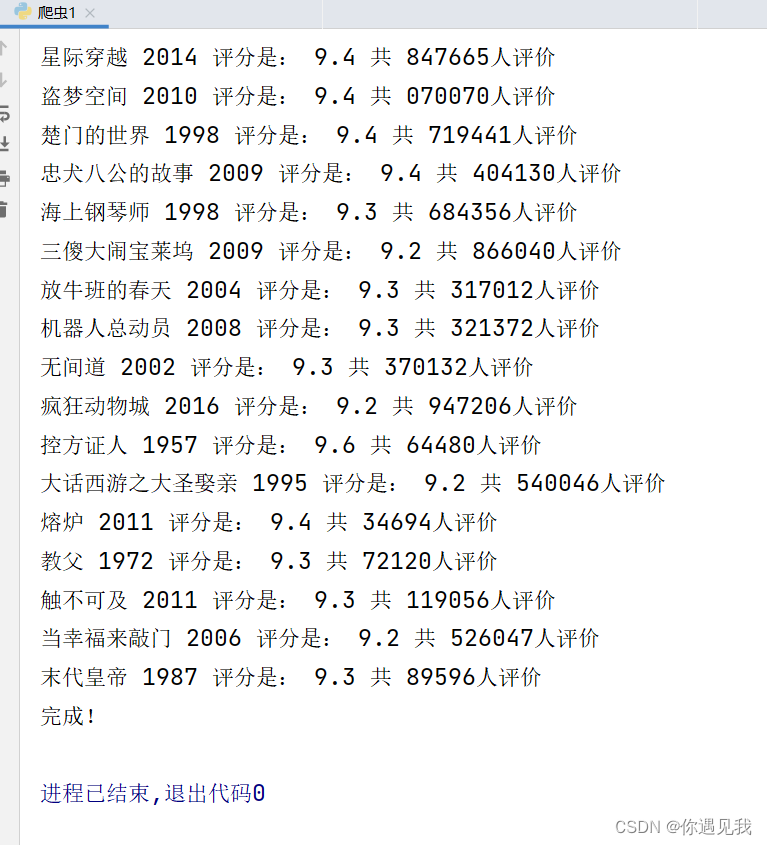
print("完成!")实验效果:
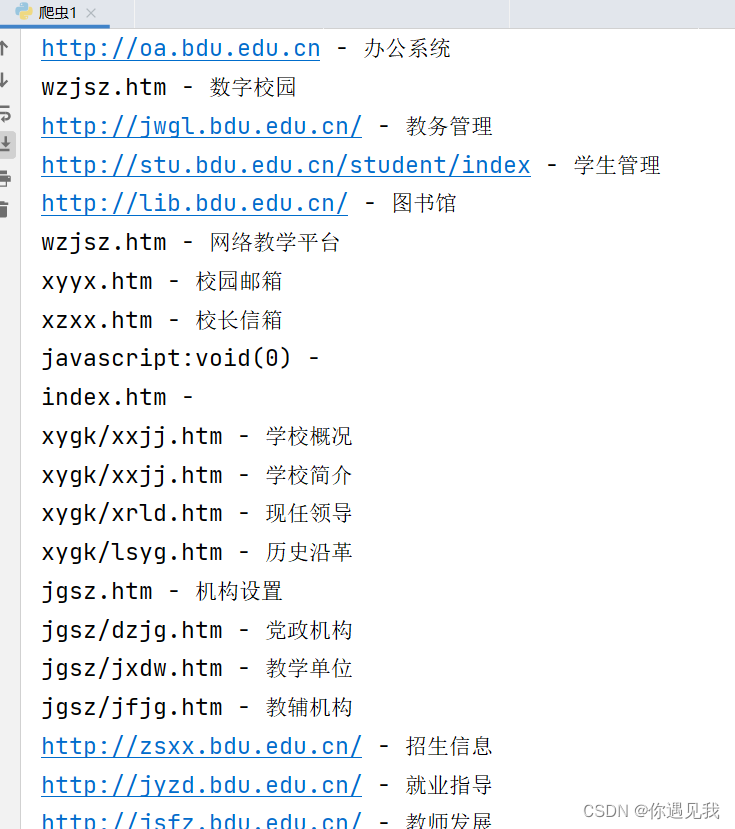
二 爬取保定学院官网网页的href(链接)
代码
#爬取保定学院官网网页的href(链接)
import re,requests
from bs4 import BeautifulSoup
#拿到源代码 requests,通过re获取想要的数据,csv写入操作
url="https://www.bdu.edu.cn/"
r=requests.get(url);r.encoding='utf-8'
yuanma=r.text# 拿到网页源代码
bs=BeautifulSoup(yuanma)
cha=bs.findAll('a')
for i in cha:
if 'href' in i.attrs:
#print(i)
print(i.attrs['href'],'-',i.text)
r.close()实验效果:
本文章只是单纯的从技术角度介绍使用python代码搜索网页数据,读者要正常使用技术。
希望对您有所帮助。
最后,谢谢您的观看