一、概述搜索引擎
1.1 什么是搜索引擎
概念:用户输入想要的关键词,返回含有该关键词的所有信息。
场景:
1、互联网搜索:谷歌、百度、各种新闻首页
2、 站内搜索(垂直搜索):企业OA查询订单、人员、部门,电商网站内部搜索商品(淘宝、京东)场景。
1.2 数据库做搜索弊端
数据量小,简单搜索,可以使用数据库。
站内搜索的问题: 如果数据量很大。
存储的问题: 电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库。
性能问题: 解决上面问题后,查询“笔记本电脑”等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上。
分词搜索问题: 如搜索“笔记本电脑”,只能搜索完全和关键词一样的数据,那么数据量小时,搜索“笔记电脑”,“电脑”数据要不要给用户。
互联网搜索: ---数据量pb级别的数据【byte字节 kb m G t p】
存储引擎来解决上面数据库作为搜索的弊端。
1.3 常用的搜索引擎软件
Solr 和 Elasticsearch 理解为数据库-->搜索性能非常块而且存储量也比较大
1.4 Solr 和 Elasticsearch
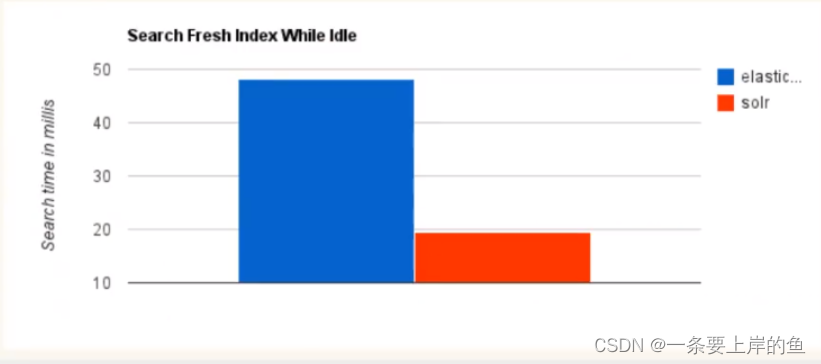
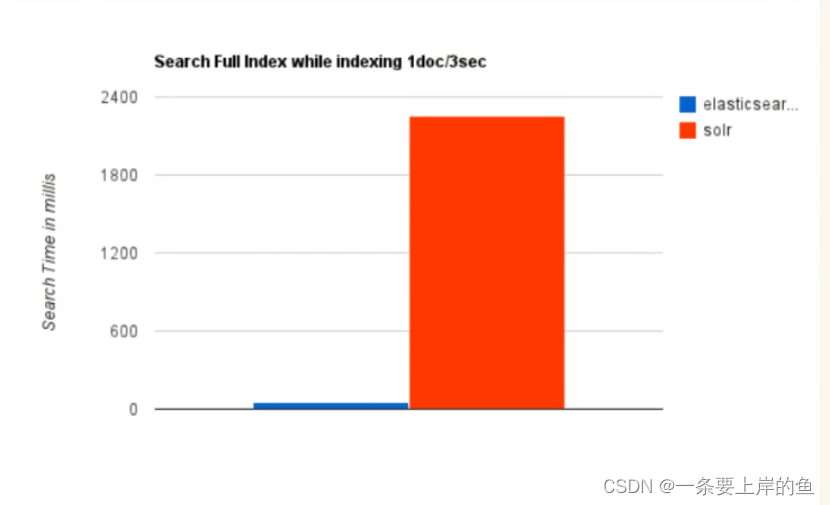
1.当单纯的对已有数据进行搜索时,Solr更快
2.当实时建立索引时,Solr会产生io阻塞,查询性能较差,ElasticSearch具有明显的优势
3.随着数据量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
总结
1、es基本是开箱即用(解压就可以用!)【南京】 ,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用Zookeeper进行分布式管理,而Elasticsearch<mark>自身带有分布式协调管理功能</mark>。
3、Solr 支持更多格式的数据,比如JSON、XML、 CSV ,而Elasticsearch仅支持json文件格式。
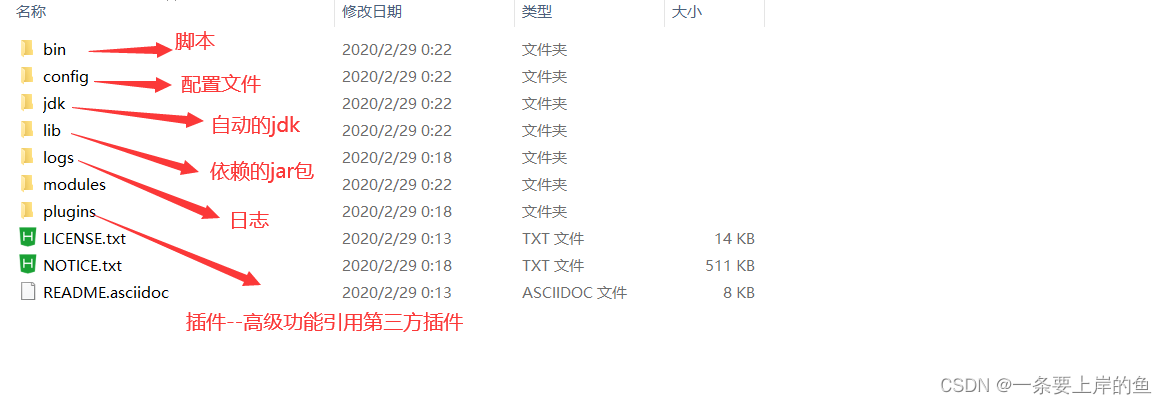
4、Solr 官方提供的功能更多,而Elasticsearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5.Solr 查询快,但更新索引时慢(即插入删除慢) ,用于电商等查询多的应用;ES建立索引快(即查询慢) ,即实时性查询快,用于facebook新浪等搜索。
Solr是传统搜索应用的有力解决方案,但Elasticsearch更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。> 大多数企业使用的是ES.

1.5 Elasticsearch是什么
The Elastic Stack, 包括 Elasticsearch【搜索,分析】、 Kibana【可视化】、 Beats 和 Logstash【数据的搜集】(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elaticsearch,简称为 ES, ES 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ElasticStack 技术栈的核心。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
总结: 核心实时存储 和 实时数据分析 实时数据检索 而且可以处理数据量PB级别,以及扩展
1.6 哪些公司正在使用ES
国外:
维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐
Stack Overflow(国外的程序讨论论坛),相当于程序员的贴吧。遇到it问题去上面发帖,热心网友下面回帖解答。
GitHub(开源代码管理),搜索上千亿行代码。
电商网站,检索商品
日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《java编程思想》的监控,如果价格低于27块钱,就通知我,我就去买。
BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
国内:
百度搜索,第一次查询,使用es。
OA、ERP系统站内搜索。
知网
1.7 安装ES
保证JDK 1.8.0_73以上的版本。---安装在window 不要安装在中文目录下
下载和解压缩Elasticsearch安装包,查看目录结构。
Download Elasticsearch | ElasticDownload Elasticsearch | ElasticDownload Elasticsearch | ElasticDownload Elasticsearch | ElasticDownload Elasticsearch | Elastic
下载地址:https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
注意: 9300 端口为 Elasticsearch 集群间组件的通信端口, 9200 端口为浏览器访问的 http协议 RESTful 端口。
打开浏览器,输入地址: http://localhost:9200,测试返回结果,返回结果如下:

1.8 安装kibana
kibana是es数据的前端展现,数据分析时,可以方便地看到数据。作为开发人员,可以方便访问es----可以理解为navcate
下载 Elastic 产品 | Elastic
历史版本下载:Past Releases of Elastic Stack Software | Elastic
1、下载,解压kibana。
2、启动Kibana:bin\kibana.bat
3、浏览器访问 http://localhost:5601 进入Dev Tools界面。像plsql一样支持代码提示。
4、发送get请求,查看集群状态GET _cluster/health。相当于浏览器访问。
如果出现如下错误
Could not create APM Agent configuration: Request Timeout after 30000ms
重写启动es就可以用了

1.9 ES中常用的概念
集群
集群这一概念已经遍及天下了,在Elasticsearch中也不例外,可以将多台Elasticsearch节点组成集群使用,可以在任意一台节点上进行搜索。
节点
节点是一台Elasticsearch服务器,可以存储、查询、创建索引,也可以与其它节点一共组成一个集群。
索引---数据库
索引是具有某种相似特性的文档集合,熟悉mysql的应该不会对于这个名词陌生,Elasticsearch使用的是倒排索引。
文档---一条记录
一个文档是一个可以被索引的基础信息单元。
分片
单个索引包含数据太大的话,将会降低索引速度。为此,Elasticsearch提供了将索引细分成多个片段的能力,就是分片。
副本
副本是ElasticSearch索引分片的备份,主要应对与节点故障时保存数据的可用性。副本与它的原始分片不会在同一个节点上,以此来保存单节点故障时的高可用。
注意: ES6.0以后Type这个概念模糊了,7.0以后不在使用Type. 默认索引的type都是_doc
索引----数据库
类型---表
文档---一条记录
字段---列
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
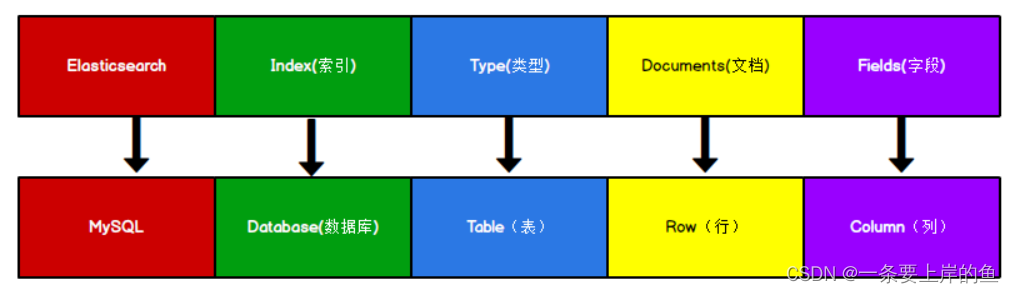
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。_doc

二、ES中常用的API接口
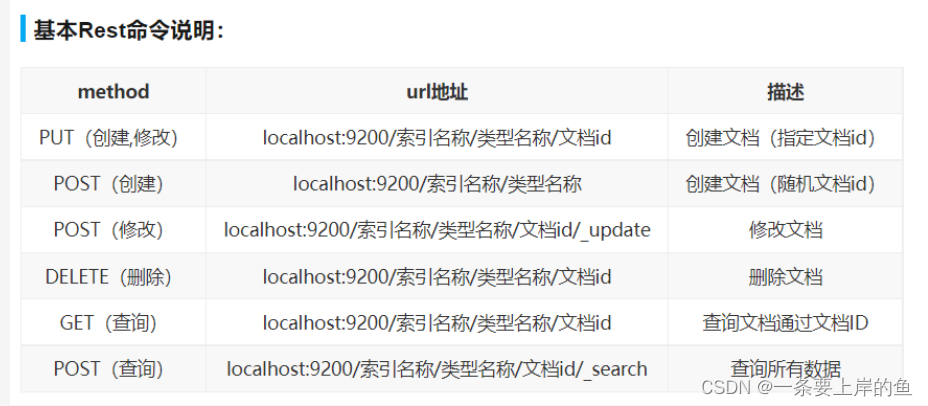
ES中提高了很多API接口,而这些接口是按照Restful风格定义的。
---风格: 根据不同的操作提供不同的提交方式,而且可以在地址上传递参数 /{id}
2.1、创建索引
语法:
PUT /索引名称
{
"mappings": {
"properties":{
"字段名":{"type":数据类型},
"字段名": {"type":数据类型}
}
}
}
数据类型:
字符串类型: text keywords
数字类型: long、Integer、short、byte、double、float、half float、scaled float
日期类型: date
布尔类型: boolean
二进制类型: .........

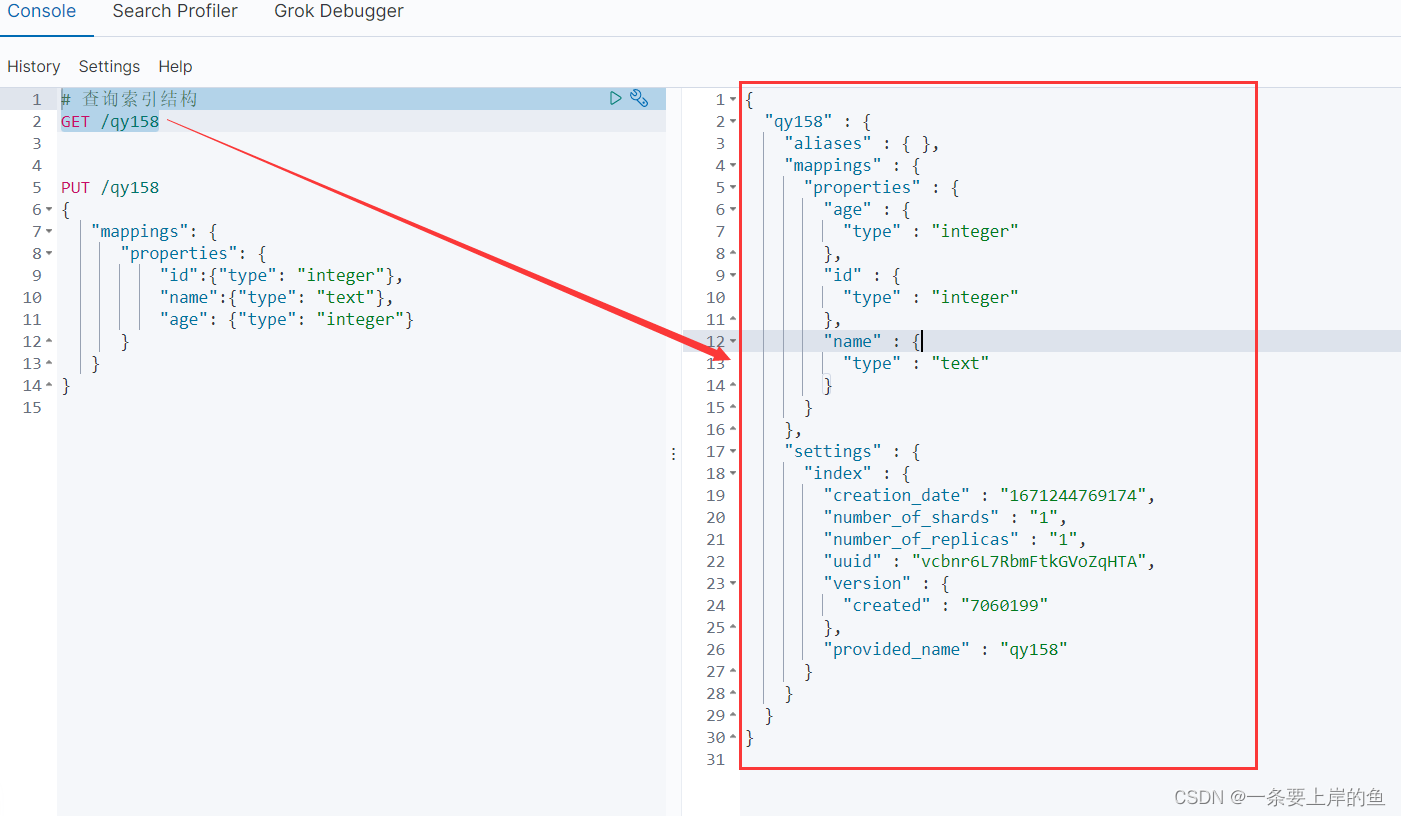
2.2、获取索引的结构
语法:
GET /索引名称
2.3、查询ES中所有的索引
语法:
GET /_cat/indices?v

2.4、删除索引
语法:
DELETE /索引名称

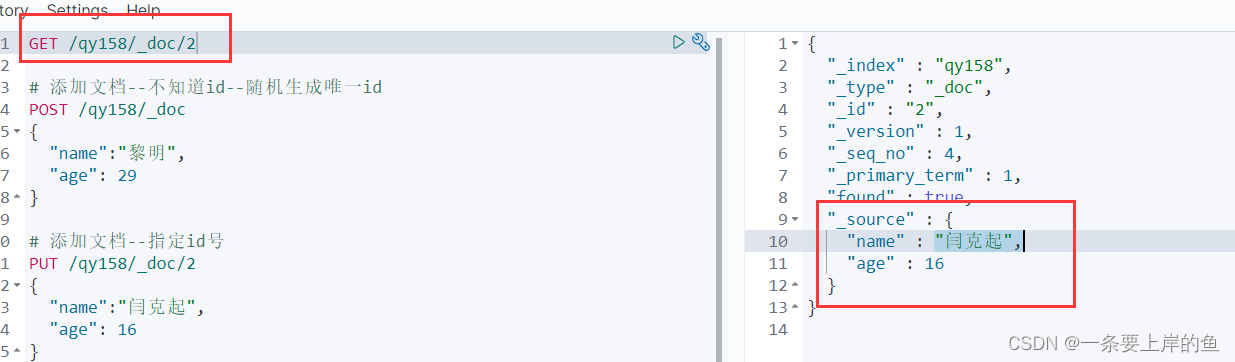
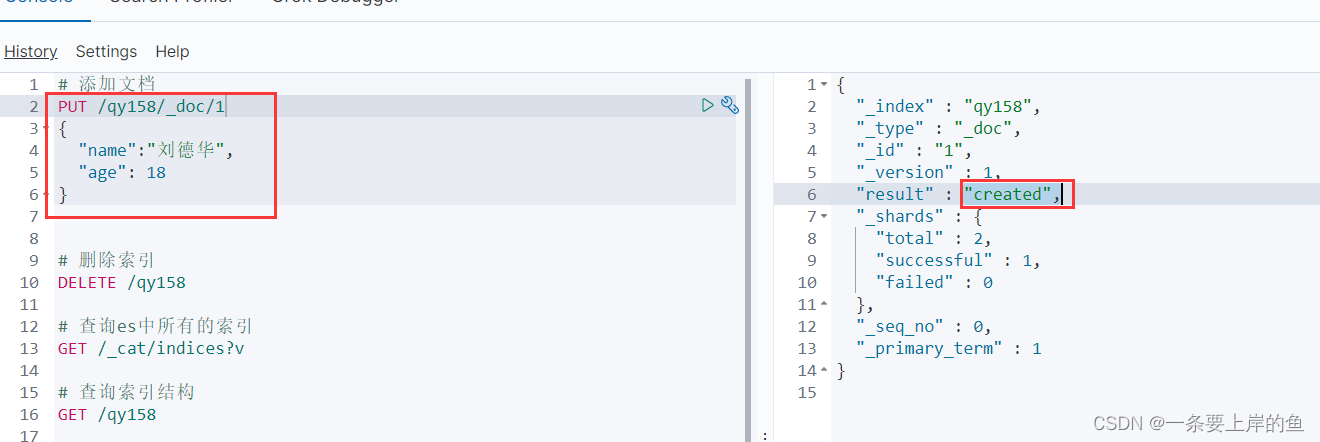
2.5、添加文档
添加记录-----数据库
添加时指定了id
语法:
put /索引名称/_doc/1
{
"name":"张学友",
"age": 18
}
添加时不知道id
POST /索引名称/_doc
{
}

2.6、根据id查询文档
语法:
GET /索引/_doc/id值