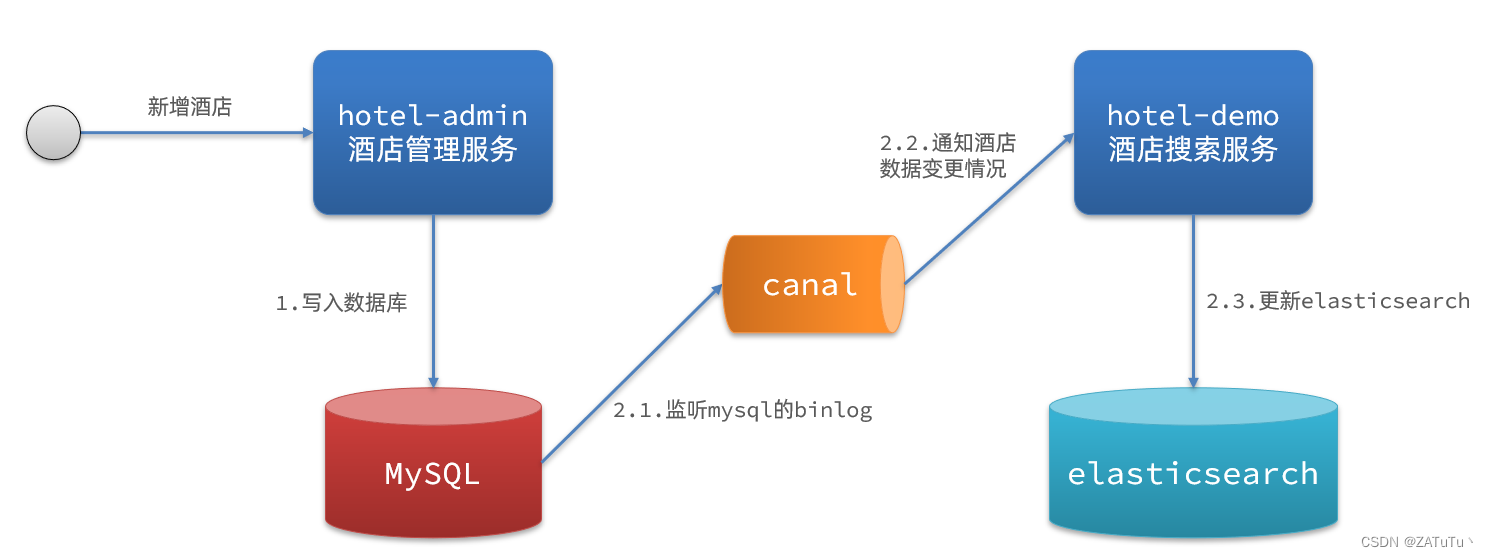
什么是最小生成树
连通图:
在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1和顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
生成树:
一个连通图的最小连通子图称作为图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
最小生成树:
最小生活树是生成树的一个特殊情况,它的边权之和最小。其特点如下:
- 只能使用图中权值最小的边来构造最小生成树
- 只能使用恰好n-1条边来连接图中的n个顶点
- 选用的n-1条边不能构成回路(构成回路会导致有顶点为连通或权值过大)
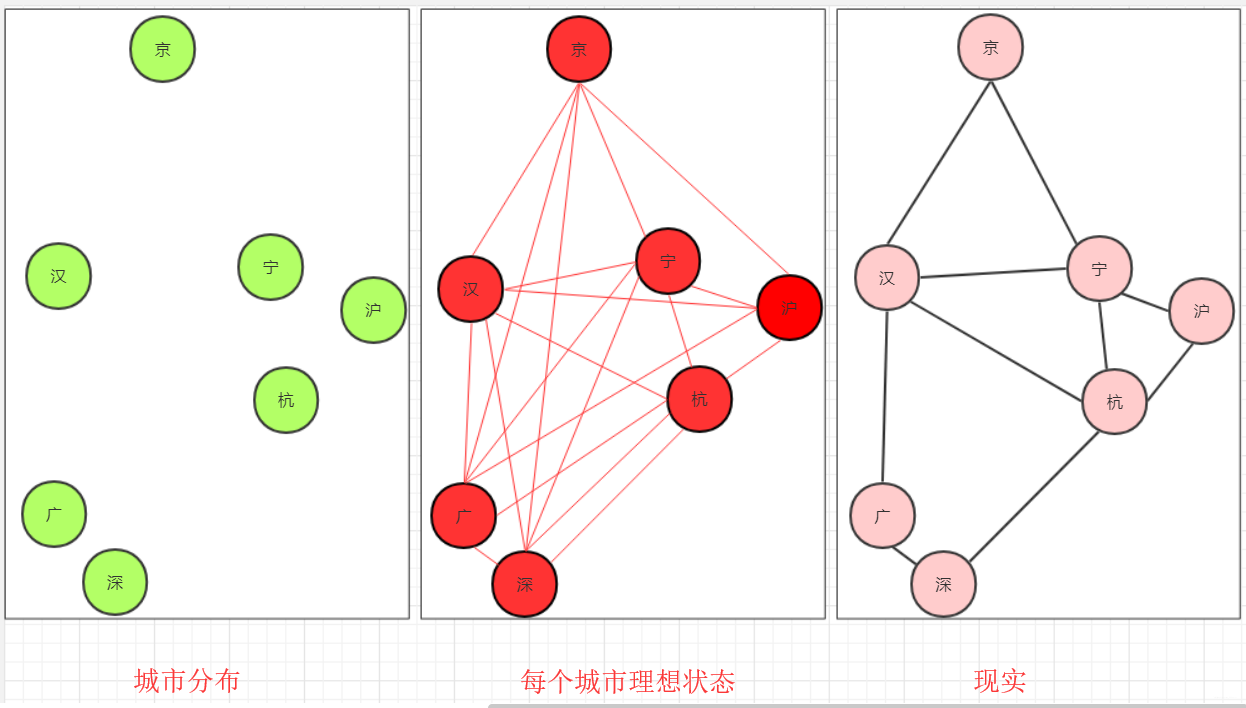
最小生成树的实际应用
例如城市道路铺设中,如果我们直接使用连通结构,这样两点间的交通必然是最便捷的。可是修路的成本的巨大的,但是又要连通所有城市,这便会想到使用最小生成树。
考虑到经济发达城市人口多、车辆多,我们还需要为其多修建一些道路,则实际中的道路修建与最小生成树的结果不同,但是最小生成树在这些实际场景发挥了很大作用。
Kruskal算法
任给一个有n个顶点的连通网络N = {V,E}。
首先构造一个由这n个顶点组成、不含任何边的图G={V,null},其中每个顶点自成一个连通分量,其次不断从E中取出权值最小的一条边(若有多条任取其中之一),若该边的两个顶点来自不同的连通分量,则将此边加入到G中。如此重复,知道所有顶点在同一个连通分量上为止。
算法思路
核心:每次迭代时,选出一条具有最小权值,且两端点不在同一连通分量上的边,加入生成树。
将权值小的边放入到优先级队列中。依次类推
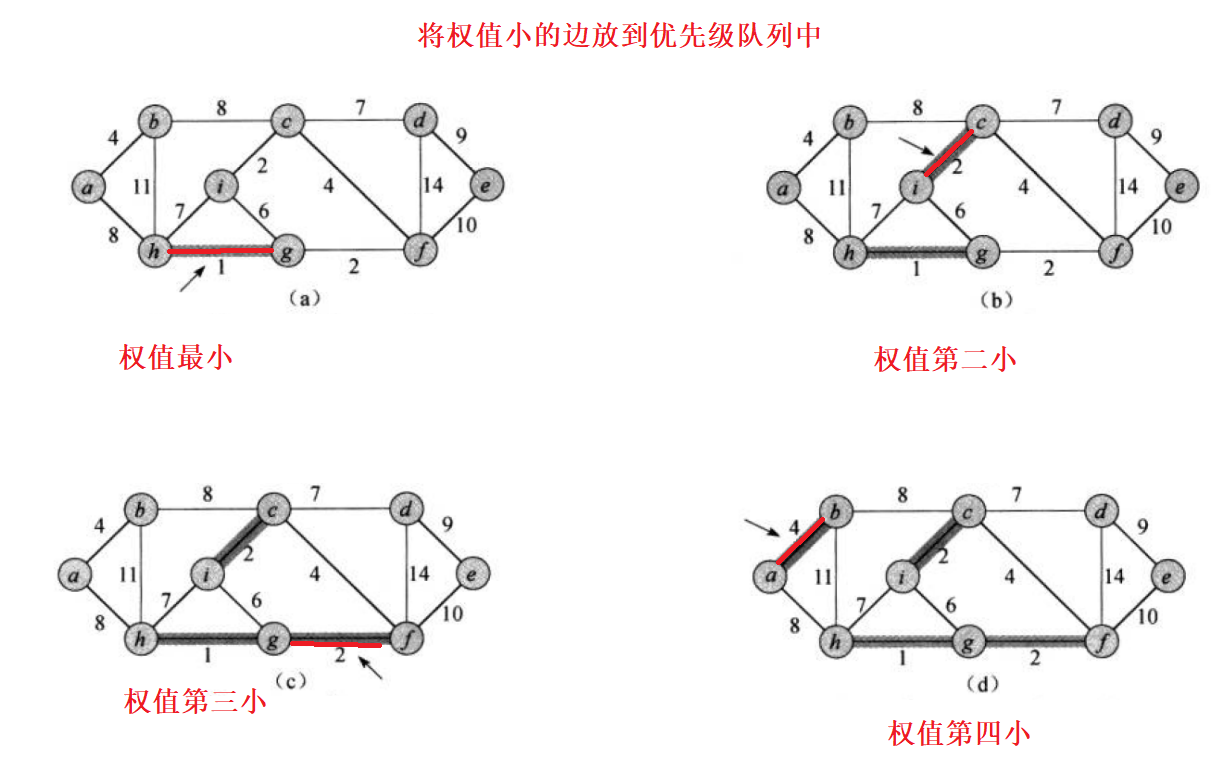
接下来有一个问题,因为生成树不能构成回路,所以在添加边的时候要处理成环问题。
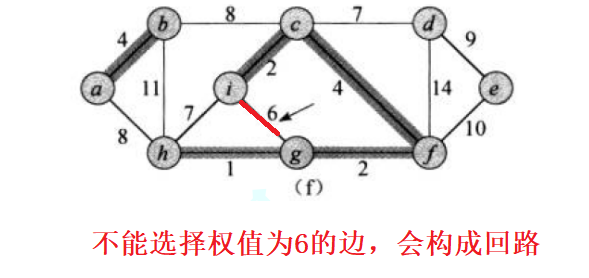
这个问题的解决就要使用并查集;如果该边已经出现过了,则不选择该边,如果该边不在集合中,则可以选择该边
以下是选边的全部过程:
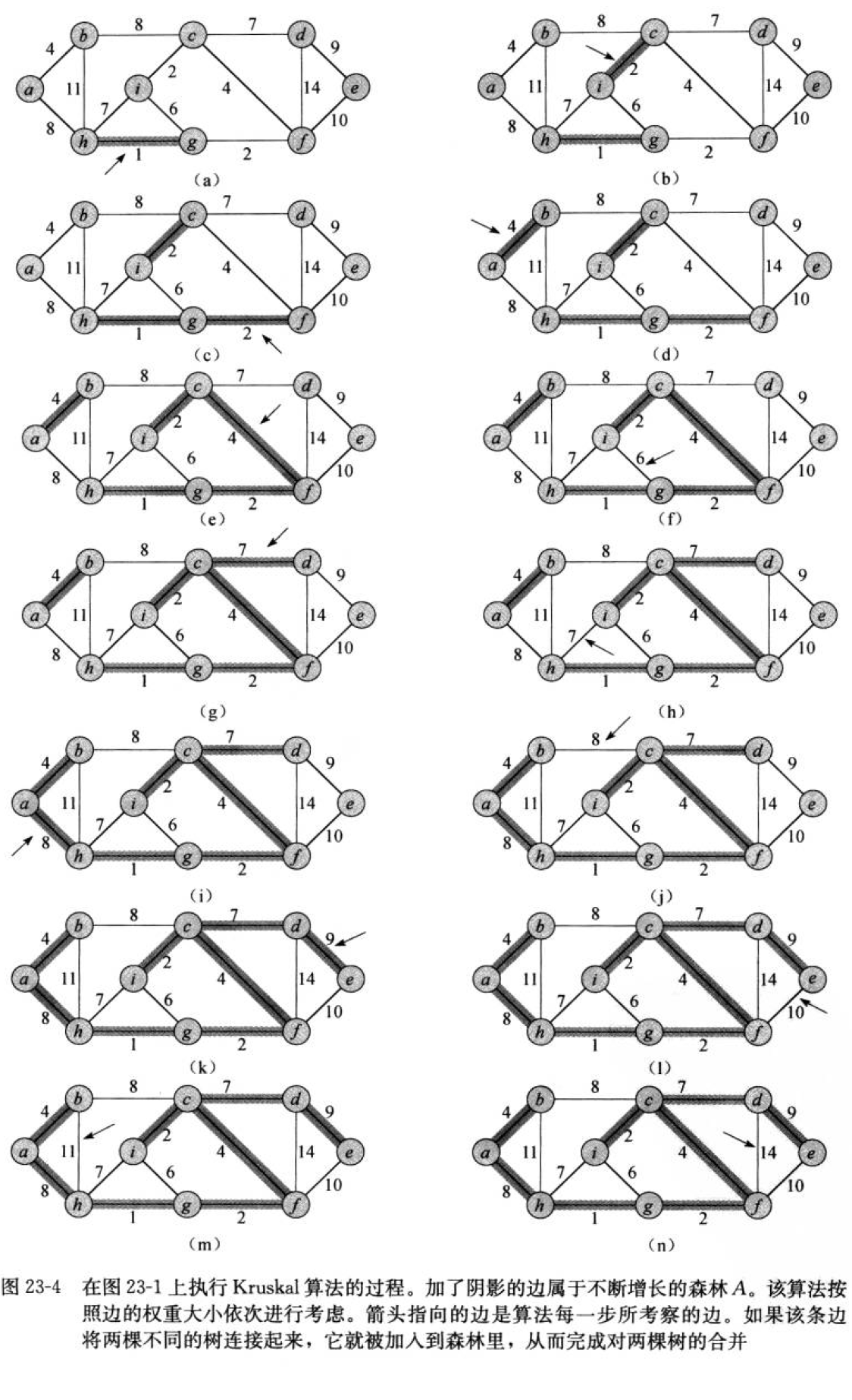
代码实现
首先我们要创建一个边的数据结构Edge,用于将边存放到优先级队列中。
struct Edge
{
size_t _srci;
size_t _dsti;
W _w;
Edge(size_t srci, size_t dsti, W w)
:_srci(srci), _dsti(dsti), _w(w)
{
}
//还要提供一个比较函数,因为优先级队列中使用到了greater,greater会调用>函数
bool operator > (const Edge& ed) const
{
return _w > ed._w;
}
};实现思路:
1. 将所有的边统计到优先级队列中,(注意临界矩阵只遍历一半)
2. 从优先级队列中选出n-1条边,n为顶点数量
3. 依次取出队列中的元素,判断该元素是否出现过(使用并查集)
4. 如果没有出现过,则添加该边到最小生成树中,并将该边添加到并查集中,再统计权值。
5. 当队列元素取空时,最小生成树中边的数量小于n-1,则表示该图没有连通,则没有最小生成树,直接返回权值的默认值即可。
6. 如果size等于n-1,则表示最小生成树创建成功,返回权值总和即可
//最小生成树
//如果有最小生成树,则返回该树的权值,如果没有最小生成树,则返回默认值
W Kruskal(Self& minTree)
{
//初始化minTree
size_t n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix = vector<vector<W>>(n, vector<W>(n, MAX_W));
//1. 将边统计起来,使用优先级队列或排序的方式都可以
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
for (size_t i = 0; i < n; i++)
{
//矩阵中走一半即可 要不然会重复入队列
for (size_t j = 0; j < i; j++)
{
if (_matrix[i][j] != MAX_W)
{
minque.push(Edge(i, j, _matrix[i][j]));
}
}
}
//2.选出n-1条边
size_t size = 0;
UnionFindSet ufs(n); //n个顶点
W total_W{}; //总的权值
while (!minque.empty() && size < n)
{
Edge min = minque.top();
minque.pop();
//3.选出一条边之后看该边在不在当前集合,
//在就不选择该边,不在就选择该边,并标记
if (!ufs.IsInset(min._srci, min._dsti))
{
cout << _vertexs[min._srci] << "-" << _vertexs[min._dsti] <<
":" << _matrix[min._srci][min._dsti] << endl;
minTree._AddEdge(min._srci, min._dsti, min._w);
ufs.Union(min._srci, min._dsti);
size++;
total_W += min._w;
}
}
//如果该图不是连通图,则没有最小生成树
if (size < n - 1)
{
return W();
}
return total_W;
}接下来是一些要注意的点:
1. 要将最小生成树进行初始化,否则添加边时会出现越界问题。
2. 最小生成树其实就是该图的子图,typedef Graph<V, W, MAX_W, Direction> Self;
3. 注意将顶点放入到并查集中,防止边的重复。
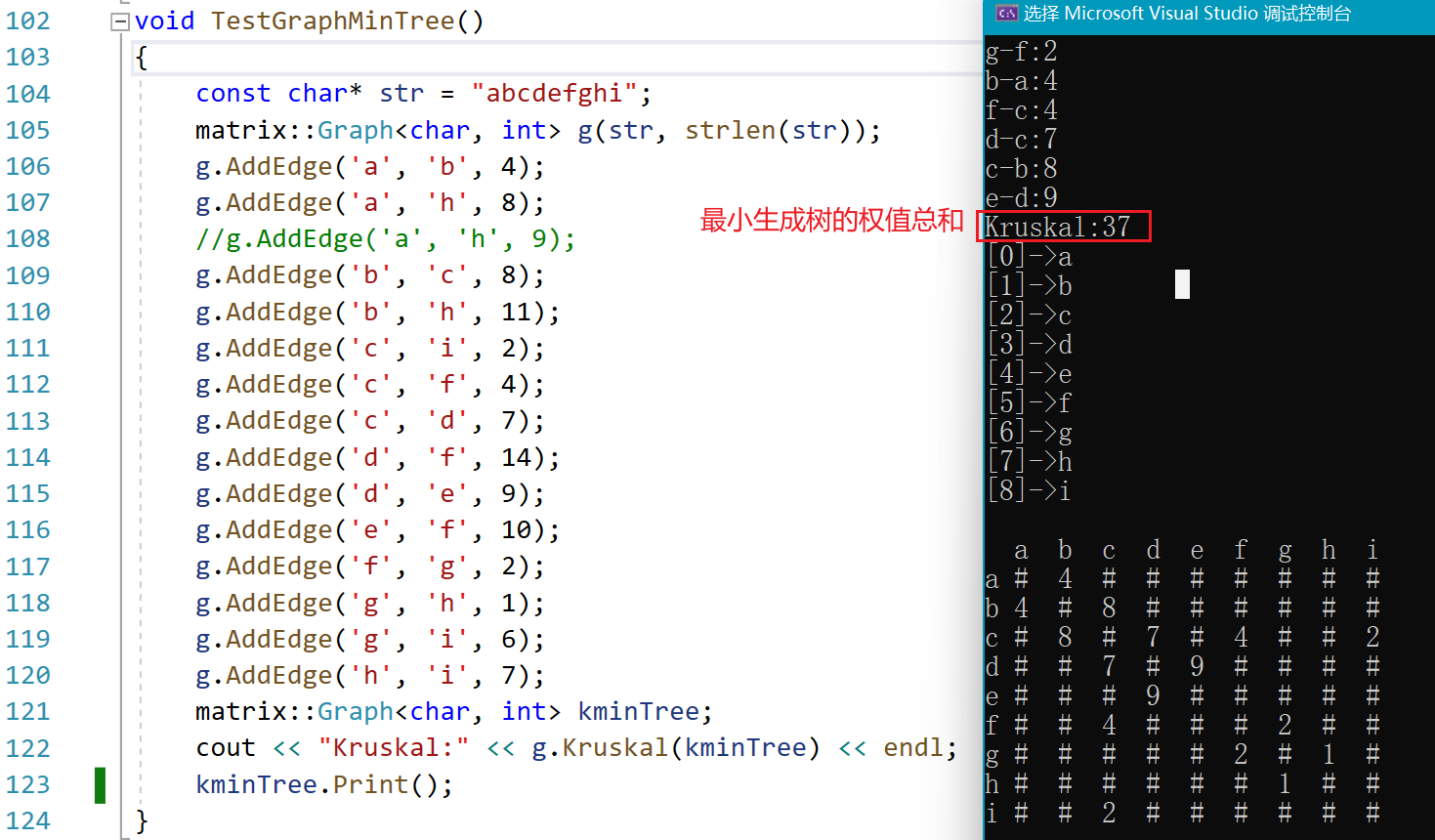
测试用例
void TestGraphMinTree()
{
const char* str = "abcdefghi";
matrix::Graph<char, int> g(str, strlen(str));
g.AddEdge('a', 'b', 4);
g.AddEdge('a', 'h', 8);
//g.AddEdge('a', 'h', 9);
g.AddEdge('b', 'c', 8);
g.AddEdge('b', 'h', 11);
g.AddEdge('c', 'i', 2);
g.AddEdge('c', 'f', 4);
g.AddEdge('c', 'd', 7);
g.AddEdge('d', 'f', 14);
g.AddEdge('d', 'e', 9);
g.AddEdge('e', 'f', 10);
g.AddEdge('f', 'g', 2);
g.AddEdge('g', 'h', 1);
g.AddEdge('g', 'i', 6);
g.AddEdge('h', 'i', 7);
matrix::Graph<char, int> kminTree;
cout << "Kruskal:" << g.Kruskal(kminTree) << endl;
kminTree.Print();
}
Prim算法
算法思路
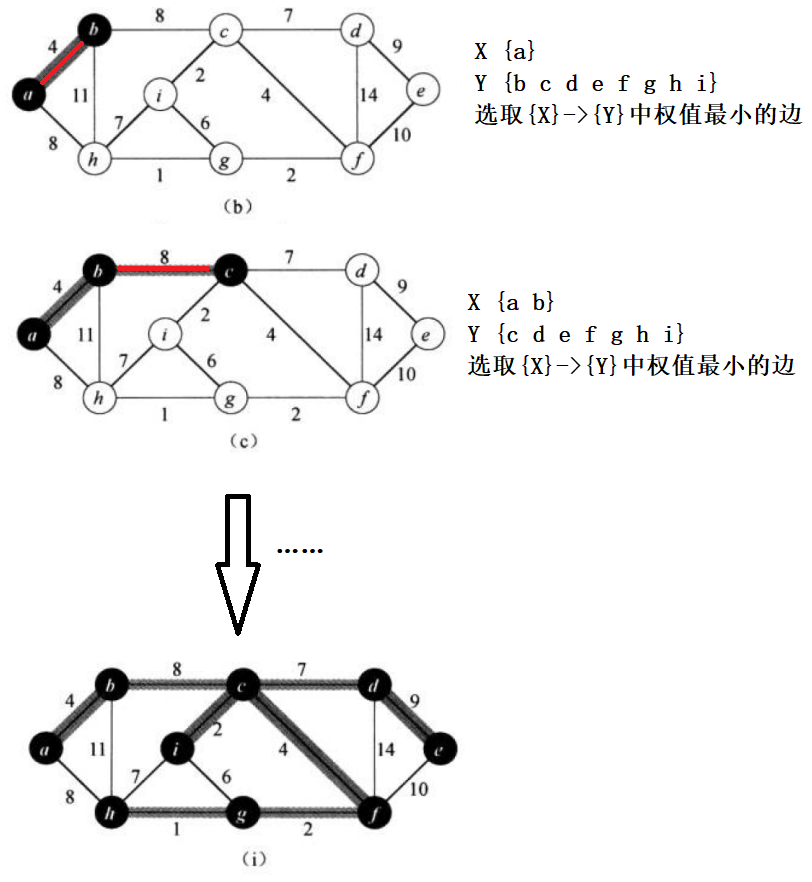
Prim算法所具有的一个性质是集合A中的边总是构成一棵树。这棵树从一个任意的根节点r开始,一直扩大到图中的所有顶点为止。在每一步连接集合A和A之外的顶点的所有边中,选择一条权值最小的边加入到A中。当算法结束时,A中的边形成一棵最小生成树。
因为添加边只会在当前集合中没有的顶点中进行,所以Prim算法天然避免环的生成,不需要使用并查集来避免环的产生。
代码实现
实现思路:
1. 使用两个数组表示X、Y集合,用于表示当前顶点是否被访问。
2. 从X集合中的顶点选出所有的边,可以使用优先级队列来存放边。
3. 依次从优先级队列中选出权值最小的边
4. 判断该边是否成环---即dest顶点必须在Y集合中
5. 在Y集合中则将该边添加到最小生成树中,然后进行顶点的标记
6. 再将dest顶点连通的边再放入队列中,同时也要判断dest连接的顶点归属Y集合。
7. 如果选出n-1条边,返回生成树的总权值,否则返回默认值
W Prim(Self& minTree, const W& src) //src表示从哪个起点开始
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
//初始化minTree
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix = vector<vector<W>>(n, vector<W>(n, MAX_W));
//两个数组表示X、Y集合,用于表示当前顶点是否被访问
vector<bool> X(n, false);
vector<bool> Y(n, true);
//初始化X,Y集合
X[srci] = true;
Y[srci] = false;
//从X-Y集合连接中的边选出权值最小的边
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
//先把srci连接的边添加到队列中
for (size_t i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
{
minque.push(Edge(srci, i, _matrix[srci][i]));
}
}
size_t size = 0;
W total_W = W();
while (!minque.empty())
{
Edge min = minque.top();
minque.pop();
if (Y[min._dsti]) //该顶点必须还在Y集合中 注意!!
{
cout << _vertexs[min._srci] << "-" << _vertexs[min._dsti] <<
":" << _matrix[min._srci][min._dsti] << endl;
minTree._AddEdge(min._srci, min._dsti, min._w);
total_W += min._w;
size++;
if (size == n - 1)
break;
X[min._dsti] = true;
Y[min._dsti] = false;
//将dsti的边进行遍历
for (size_t i = 0; i < n; i++)
{
if (_matrix[min._dsti][i] != MAX_W && Y[i]) //有连通,并且是Y集合中的顶点
{
minque.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
//如果该图不是连通图,则没有最小生成树
if (size < n - 1)
{
return W();
}
return total_W;
}测试用例
void TestGraphMinTree()
{
const char str[] = "abcdefghi";
matrix::Graph<char, int> g(str, strlen(str));
g.AddEdge('a', 'b', 4);
g.AddEdge('a', 'h', 8);
g.AddEdge('b', 'c', 8);
g.AddEdge('b', 'h', 11);
g.AddEdge('c', 'i', 2);
g.AddEdge('c', 'f', 4);
g.AddEdge('c', 'd', 7);
g.AddEdge('d', 'f', 14);
g.AddEdge('d', 'e', 9);
g.AddEdge('e', 'f', 10);
g.AddEdge('f', 'g', 2);
g.AddEdge('g', 'h', 1);
g.AddEdge('g', 'i', 6);
g.AddEdge('h', 'i', 7);
/*matrix::Graph<char, int> kminTree;
cout << "Kruskal:" << g.Kruskal(kminTree) << endl;
kminTree.Print();*/
cout << "prim算法的实现" << endl;
matrix::Graph<char, int> pminTree;
cout << "Prim:" << g.Prim(pminTree, 'a') << endl;
pminTree.Print();
}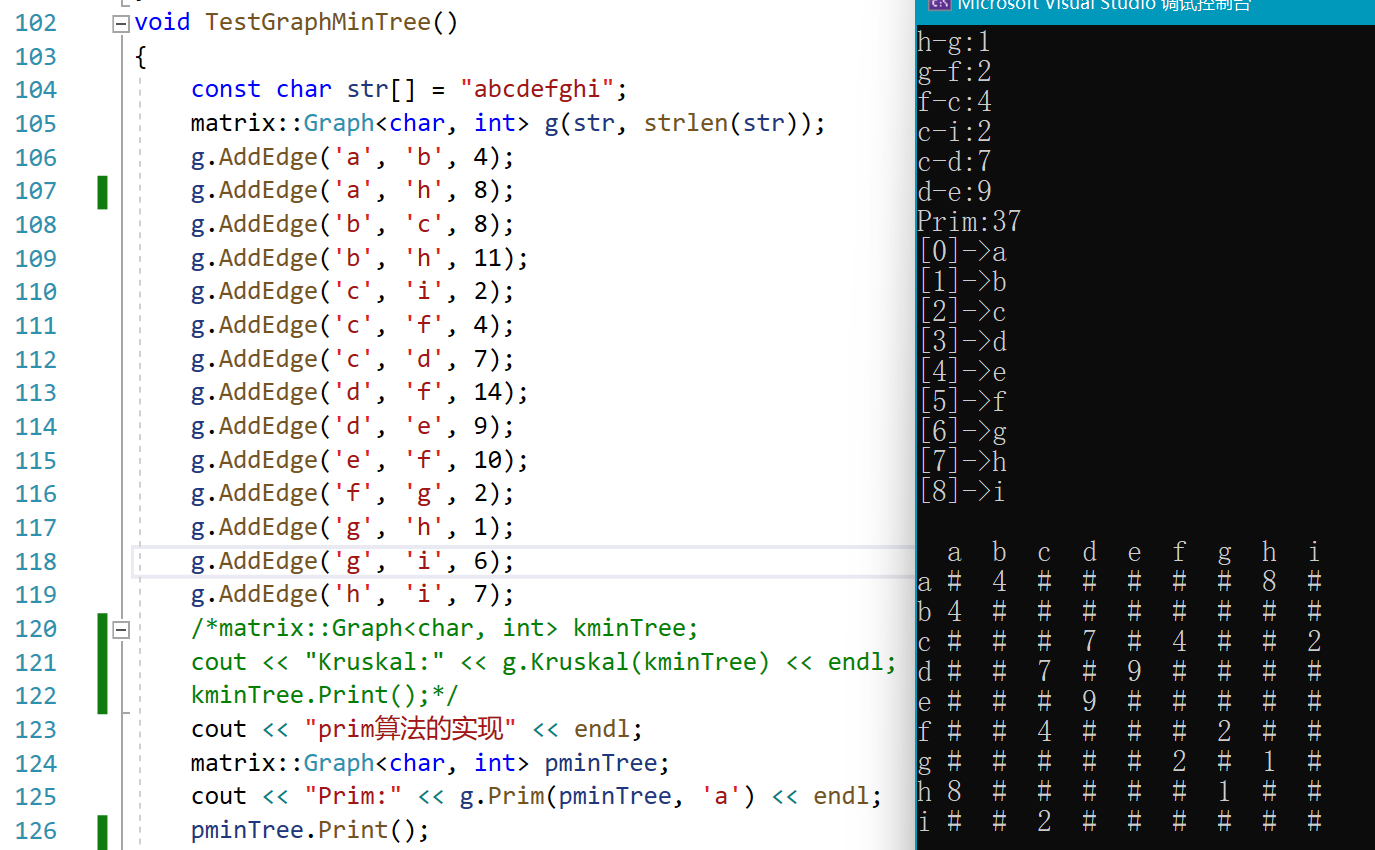
最后细心的你可以会发现,两种算法的结果权值都是37,但是其生成的最小生成树是不同的,这就好比一个正三角形,三个顶点所在的位置,无论连接哪条线,其都是最小生成树,所以不唯一。