最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。
更多相关内容可见Fastchat实战部署vicuna-7b-v1.3(小羊驼)_Spielberg_1的博客-CSDN博客
一、配置环境
conda create -n fastchat python=3.9 # fastchat官方建议Python版本要>= 3.8
切换到fastchat
conda activate fastchat安装torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1
pip install torch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1
二、安装fastchat和transformers
安装fschat==0.1.10,官方建议vicuna-7b-delta-v0对应的fastchat版本低于0.1.10
pip install fschat==0.1.10安装transformers
pip install transformers三、合并权重,生成vicuna-7b-v0模型
python -m fastchat.model.apply_delta \
--base /root/LLaMA-7B-hf/llama-7b-hf \
--target /root/vicuna-7b-v0 \
--delta /root/vicuna-7b-delta-v0| base | hf格式的llama-7b模型的路径 |
| target | 合并权重后生成的vicuna-7b-v0模型路径,稍后启动FastChat要用 |
| delta | 从huggingface下载的vicuna-7b-delta-v0路径 |
vicuna-7b模型合并需要30G的RAM,请合理评估
生成目标模型保存在/root/vicuna-7b-v0

命令行输出
(fastchat) root@dl-230904040428gxb-pod-jupyter-7599dcdb54-qjppf:~# python -m fastchat.model.apply_delta --base /root/LLaMA-7B-hf/llama-7b-hf --target /root/vicuna-7b-v0 --delta /root/vicuna-7b-delta-v0
Loading the base model from /root/LLaMA-7B-hf/llama-7b-hf
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [02:12<00:00, 4.03s/it]
Loading the delta from /root/vicuna-7b-delta-v0
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [02:56<00:00, 88.21s/it]
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embeding dimension will be 32001. This might induce some performance reduction as *Tensor Cores* will not be available. For more details about this, or help on choosing the correct value for resizing, refer to this guide: https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
Applying the delta
Applying delta: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 291/291 [00:24<00:00, 11.96it/s]
Saving the target model to /root/vicuna-7b-v0
四、推理
python3 -m fastchat.serve.cli --model-path /root/vicuna-7b-v0| model-path | 上一步合并生成的target路径 |

控制台输出,Human是输入,Assistant是模型的回复
(fastchat) root@dl-230904040428gxb-pod-jupyter-7599dcdb54-qjppf:~# python3 -m fastchat.serve.cli --model-path /root/vicuna-7b-v0
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. If you see this, DO NOT PANIC! This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=True`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [02:00<00:00, 60.38s/it]
Human: hello
Assistant: Hello! How can I help you today?
Human: can you tell me a jok
Assistant: Sure, here's a joke for you:
Why was the math book sad?
Because it had too many problems!
I hope you found that joke amusing. Do you have any other questions or topics you'd like to discuss?
Human: a guide to touring in China
Assistant: China is a vast and diverse country with a rich history and culture, and there is no shortage of things to see and do. Here are some tips for touring in China:
1. Plan ahead: Research the destinations you want to visit, the best time to go, and the logistics of getting there. Consider factors such as cost, time, transportation, and accommodation.
2. Get a visa: Depending on your nationality, you may need to obtain a visa before you travel to China. Make sure you have enough time to apply for a visa and that you have all the necessary documents.
3. Pack appropriately: Pack clothes for the season, and bring a mix of casual and formal wear. Also, don't forget to pack any necessary medication and travel accessories like a first aid kit, phone charger, and a portable battery pack.
4. Learn some basic Mandarin: While many people in China speak English, having some basic Mandarin will help you communicate with locals and navigate the country more easily.
5. Be respectful: China is a highly cultured country, and it's important to be respectful of local customs and traditions. Dress modestly, avoid pointing with your chin, and avoid discussing sensitive political or religious topics.
6. Try the local food: Chinese cuisine is diverse and delicious, and there are many local specialties to try. Don't be afraid to try new things, but be aware of food safety concerns and only eat at reputable restaurants.
7. Stay safe: Be aware of your surroundings and take proper safety precautions, such as avoiding unfamiliar or poorly lit areas at night, and keeping valuable items safe.
8. Enjoy the experience: China is a beautiful and fascinating country, and there is no shortage of things to see and do. Enjoy the experience, take it all in, and have a great time!
Human: how to study vicuna
Assistant: Studying vicuñas can be a challenging and rewarding experience, but it requires careful planning and preparation. Here are some tips for studying vicuñas:
1. Research the species: Learn about the biology, behavior, and ecology of vicuñas, including their habitat, diet, and social structure.
2. Identify the best sites: Identify the best sites to study vicuñas, such as national parks, wildlife reserves, or other protected areas. Make sure you have permission to study the vicuñas and that you are familiar with the local regulations and laws.
3. Develop your skills: Develop the necessary skills to study vicuñas, such as knowledge of the local language, tracking and observation skills, and experience in capturing and handling animals.
4. Set up your equipment: Set up your equipment, such as cameras, GPS devices, and other necessary tools, to monitor and study the vicuñas.
5. Observe and collect data: Observe the vicuñas in their natural habitat and collect data on their behavior, such as their movement patterns, feeding habits, and social interactions.
6. Analyze your data: Analyze the data you have collected and draw conclusions about the behavior and ecology of the vicuñas.
7. Communicate your findings: Communicate your findings to other researchers and conservationists, and use your research to inform conservation efforts and protect the vicuñas.
8. Consider the ethics: Remember to consider the ethical implications of your study and to minimize any negative impacts on the vicuñas and their habitat.
总结:vicuna-7b支持英文,回答能力有限。
遇到的问题
ImportError: cannot import name 'is_tokenizers_available' from 'transformers.utils'
原因:transformers版本不匹配
解决方法:安装transformers,
pip install transformers查看版本为4.32.1

ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.

翻译;ValueError:Tokenizer类LLaMATokenizer不存在或当前未导入。
原因:transformers版本更新,AutoTokenizer 更新为LlamaTokenizer,AutoModelForCausalLM 更新为LlamaForCausalLM
解决办法:
1、打开fastchat.model.apply_delta.py
将所有的AutoTokenizer 替换为 LlamaTokenizer
AutoModelForCausalLM 替换为 LlamaForCausalLM
2、找到llama-7b的模型,改动tokenizer_config.json文件,
把"tokenizer_class": "LLaMATokenizer" 改为 "tokenizer_class": "LlamaTokenizer".
ImportError: cannot import name ‘LlamaTokenizerFast’ from ‘transformers’
翻译:ImportError:无法从“transformers”导入名称“LlamaTokenizerFast”
原因:transformers中无法导入LlamaTokenizerFast
解决:
确认您已经安装了最新的 Transformers 库:请检查您是否已经安装了最新版本的 Transformers 库,您可以使用pip命令来更新Transformers库:
pip install --upgrade transformers检查LlamaTokenizerFast是否存在于Transformers库中:请确保您在Transformers库中找到了LlamaTokenizerFast类。您可以查看Transformers文档或使用以下命令来检查:
python -c "from transformers import LlamaTokenizerFast"如果该命令未报告任何错误,则表示LlamaTokenizerFast类可用。
UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment
解决办法:
pip install protobufError:AutoTokenizer.from_pretrained,UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment · Issue #25848 · huggingface/transformers · GitHub
RuntimeError: The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0
原因:fastchat版本不匹配,降低到0.1.10版本
查看“FastChat版本兼容性”文档:https://github.com/lm-sys/FastChat/blob/main/docs/vicuna_weights_version.md
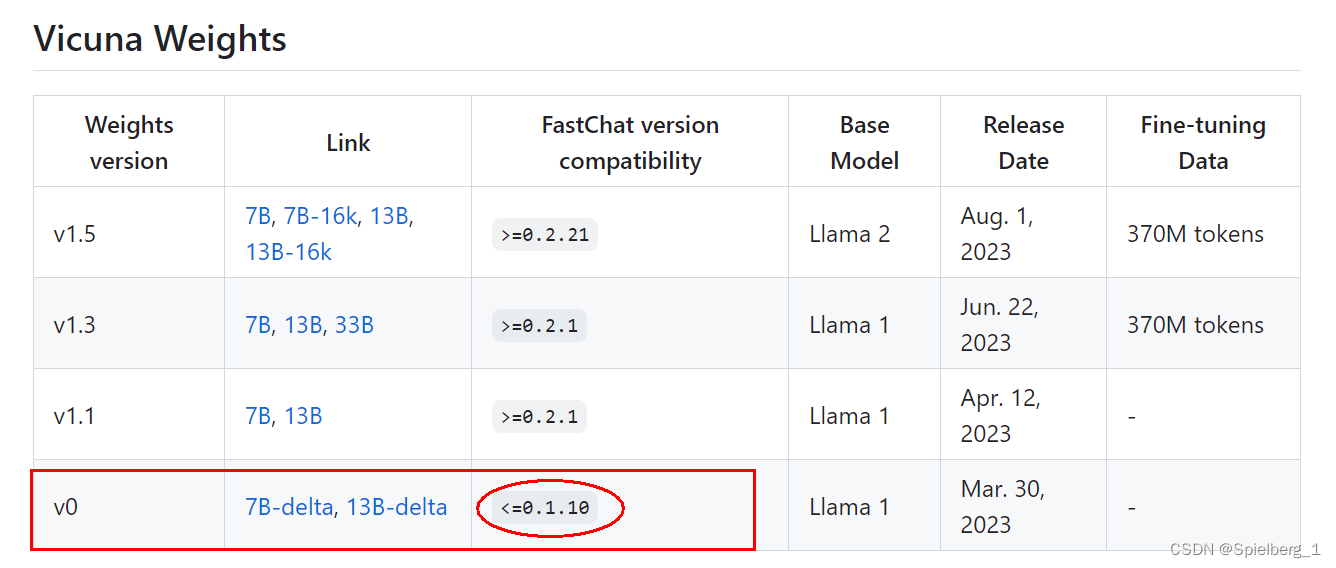
有效的方式:
pip install fschat==0.1.10RuntimeError: The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0 · Issue #132 · Vision-CAIR/MiniGPT-4 · GitHub
用到的ubuntu命令:
chmod +rwx file 给file文件添加读、写、执行权限。r表示可读,w表示可写,x表示执行
chmod -rwx file 删除file文件读、写、执行权限
nvidia-smi -l 5 每隔5秒刷新nvidia-smi,实时查看GPU使用、显存占用情况
参考
Fastchat实战部署vicuna-7b-v1.3(小羊驼)_Spielberg_1的博客-CSDN博客
nvidia-smi命令实时查看GPU使用、显存占用情况_我们是宇宙中最孤独的孩子的博客-CSDN博客
MiniGPT-4 本地部署 RTX 3090 - 知乎
解决ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported_wx6176918821622的技术博客_51CTO博客
http://www.kuazhi.com/post/445223.html
ChatGPT DeepSpeed 部署中bug以及解决方法_博客_夸智网
Error:AutoTokenizer.from_pretrained,UnboundLocalError: local variable 'sentencepiece_model_pb2' referenced before assignment · Issue #25848 · huggingface/transformers · GitHub
ubuntu如何修改读写权限设置 - 小小蚂蚁
小羊驼模型(FastChat-vicuna)运行踩坑记录 - 知乎
win10,win11 下部署Vicuna-7B,Vicuna-13B模型,gpu cpu运行_babytiger的博客-CSDN博客





![数据结构——七大排序[源码+动图+性能测试]](https://img-blog.csdnimg.cn/img_convert/063e2967083621d3c6c701762af9cde6.png)