原文链接:https://www.techbeat.net/article-info?id=4394
作者:seven_
要让AI模型真正具备智能感知和认知的功能,我们就不得不把视觉分析和自然语言理解二者结合起来进行研究。AI大模型社区的成长为我们带来了很多极具想象力和创造力的新应用,例如CLIP加持下的文本图像合成模型,以及GPT-3加持下的智能问答机器人等等。这些模型无疑都是通过大规模的文本图像数据对训练得到的,如果我们深究这些模型的训练结果,我们会发现,在这种训练设置下,模型会构建出一个相比以往单模态模型更加丰富、鲁棒的视觉语言联合嵌入空间。如果能够将该嵌入空间独立提取出来,我们是否能够在其基础上开发出具有更多功能的AI模型呢。
基于这种灵感,本文作者提出了一种名为CLOSE(Cross modaL transfer On Semantic Embeddings)的跨模态大模型,需要注意的是,CLOSE仅需要语言数据训练,而抛弃对图像的特征提取就可以完成大多数视觉任务,这在其他传统视觉任务框架中是不敢想象的。这都得益于其加载了利用对比学习范式训练的视觉语言编码器联合嵌入空间,CLOSE可以在图像字幕生成(Image Captioning)、视觉蕴含推理(Visual Entailment)和视觉问答(Visual Question Answering)三个高层次视觉任务上得到非常好的推理性能。此外作者还考虑到在实际应用时,不同模态的嵌入空间在对比模型中可能存在一些系统性的差异,本文分析了这些差异对模型的影响,并研究了各种策略来缓解这一问题。

论文链接:
https://arxiv.org/abs/2211.09778
代码链接:
https://github.com/allenai/close
一、引言
虽然视觉分析和自然语言处理通常被认为是两种截然不同的任务,但模型完成这些任务所需的推理能力往往有很大程度的重合。例如
- 视觉问答(visual question answering)和阅读理解问答(reading comprehension question
answering)都需要模型能够解析和理解问题。 - 视觉蕴涵(visual entailment)和文本蕴涵(textual entailment)都需要模型能够对不同的语义进行比较。
- 字幕生成(captioning)和摘要生成(summarization)都需要模型能够编写总结性的文本。
作者在此基础上提出了一个假设:如果一个模型学会了使用输入文本的高级语义表征来完成其中的一项任务,那么从理论上讲,只要输入的图像被编码为相同的语义表征,它就可以无需训练而完成其他相应的视觉任务。因此作者仅使用自然语言数据来训练模型,然后使用视觉输入得到语义表征进而完成推理任务。作者称之为零样本跨模态迁移(zero-shot cross-modal transfer),因为它需要将从一种模态学到的知识应用到另一种模态中。
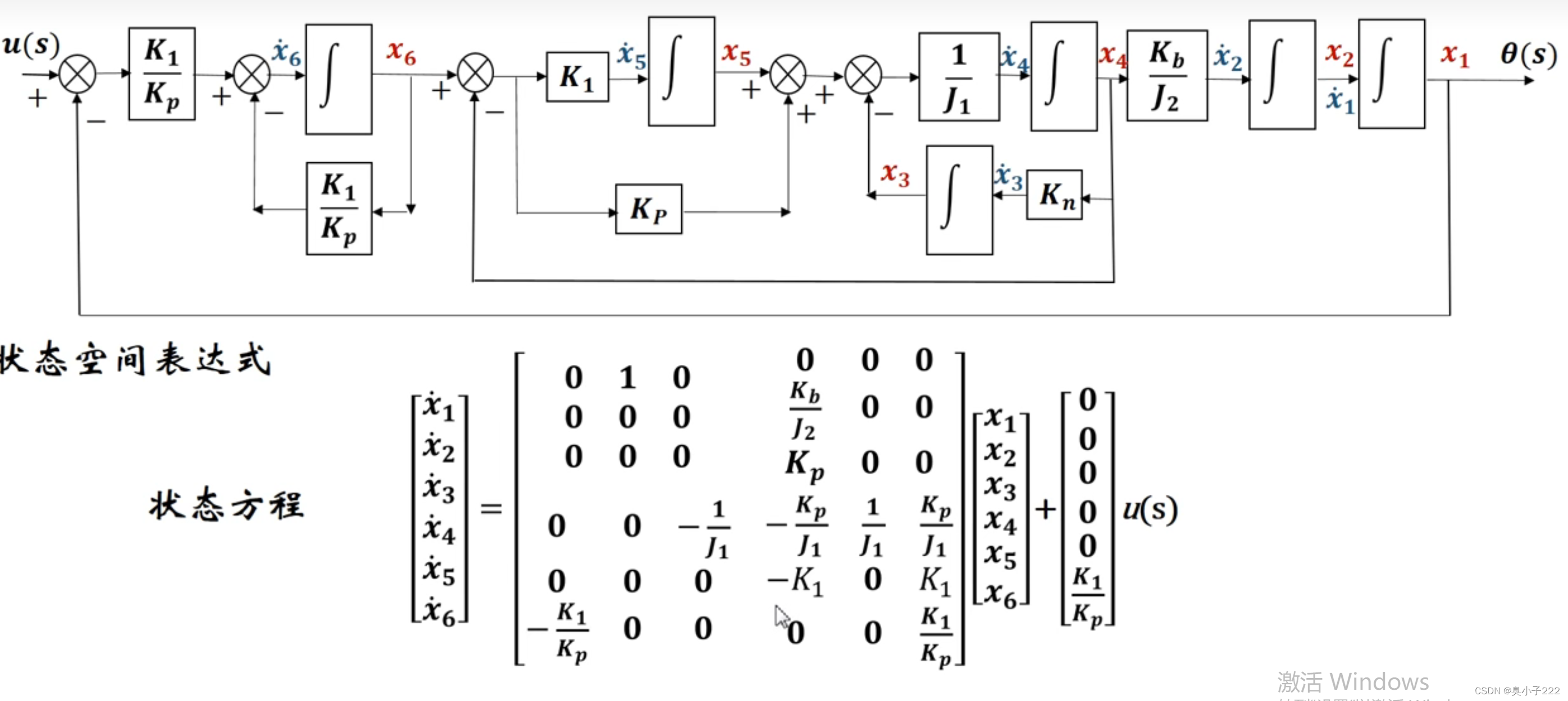
为了实现上述的零样本跨模态迁移,首先需要将图像和文本编码到一个共享的语义空间中,作者使用了CLIP模型[1]作为基础backbone,CLIP编码器可以将语义匹配的图像和文本向量在嵌入空间中拉近,而将不相关的对象拉远。在此基础上作者提出了跨模态迁移CLOSE模型,下图展示了CLOSE的整体框架,在训练阶段,使用冻结的文本编码器将文本输入编码为一个向量,然后将其作为模型的输入。在测试阶段中,通过一个图像编码器来对输入图像进行编码,用来代替之前的文本嵌入。由于这些编码器可以产生较为接近的语义向量,这使得在下游任务中实现跨模态迁移成为可能。
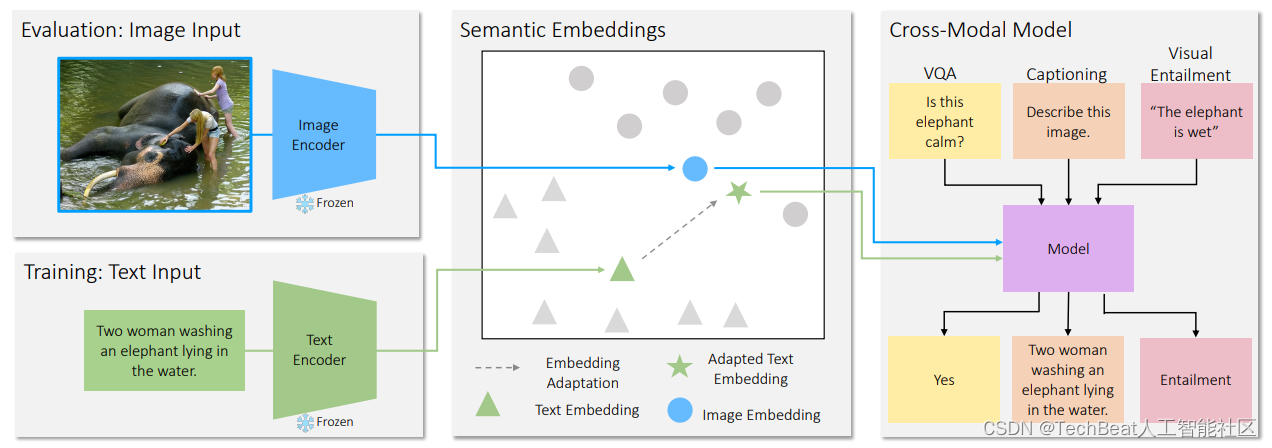
但是这种方式的一个潜在风险是,不同模态的嵌入向量或多或少都存在一些差异,为了解决这一问题,作者提出了一个适应模块(adapter)在训练阶段对文本向量和视觉向量进行修正,作者通过实验发现,对其添加一些高斯噪声会对最终模型的性能有所提升。作者发现仅通过上述方式训练得到的CLOSE模型已经可以与在图像数据上训练的方法性能保持持平,这也证明了两种模态的高度可迁移性。
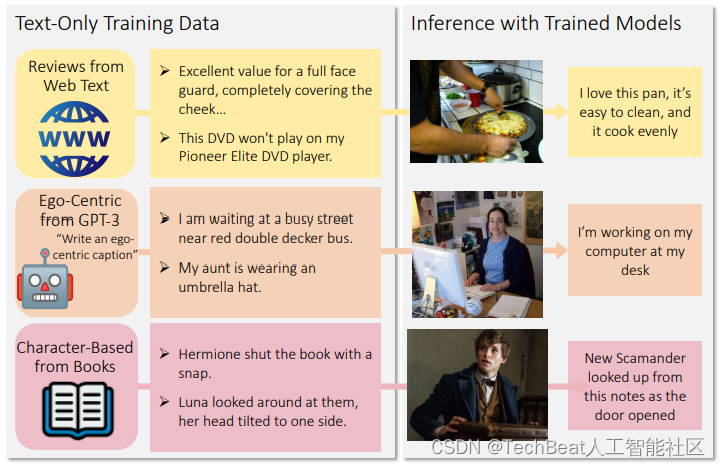
此外,作者还表明CLOSE模型也可以通过机器生成数据进行训练,而无需费时费力的人工标注,要知道目前机器生成文本相比生成图像的成本小得多。作者选用GPT-3[2]来生成图像字幕,并结合一些真实数据,例如来自互联网上的评论数据、书籍等等训练模型,CLOSE在这些文本上训练得到的结果可以为任意给定的真实图像生成准确逼真的字幕描述,生成效果如下图所示。
二、本文方法
CLOSE模型的构建整体上呈现简洁的特点,其首先通过对比学习范式得到较为理想的视觉文本联合嵌入空间,随后在此基础上构建模型,在模型训练阶段,主要对已加载的预训练语言模型进行微调,微调时遵循生成式任务的训练范式。最后通过高斯噪声干扰的方式缓解不同模态之间的空间差异,提高模型性能。下面我们将详细介绍其中的一些技术细节。
2.1 对比学习基础范式
对比学习模块的主要目的是对语义相近的图像输入和文本输入得到一个联合嵌入,这需要两个独立的视觉和文本编码器,这些编码器通过InfoNCE损失函数进行训练,其中对于N个成对图像文本进行编码以生成一组视觉向量 ⟨ u 1 , u 2 , … u n ⟩ \left\langle u_{1}, u_{2}, \ldots u_{n}\right\rangle ⟨u1,u2,…un⟩ 和文本向量 ⟨ v 1 , v 2 , … v n ⟩ \left\langle v_{1}, v_{2}, \ldots v_{n}\right\rangle ⟨v1,v2,…vn⟩。然后对于其中的每对图像和文本向量,计算logits为 l i j = e t v i ∥ v i ∥ u j ∥ u j ∥ l_{i j}=e^{t} \frac{v_{i}}{\left\|v_{i}\right\|} \frac{u_{j}}{\left\|u_{j}\right\|} lij=et∥vi∥vi∥uj∥uj ,logits代表向量之间的余弦相似度乘上相应的学习比例系数 t t t 。然后,这些logits向量输入到交叉熵损失中进行优化。我们可以将语义匹配图像和文本向量作为正样本,将不匹配的图像和文本向量作为负样本。这就满足了对比学习的基本范式,使配对的图像和文本向量之间的余弦相似度变大,而未配对的图像和文本向量之间的相似度变小,这种方式目前已经被证明可以较为完美的应用在很多大规模数据场景中。
2.2 模型构建
CLOSE的构建过程本质上仍然遵循对比学习模型的微调过程,主要针对输入文本进行微调。具体而言,首先对输入的图像和文本特征向量进行规范化到单位长度,使其在特征维度方面与对比嵌入空间进行匹配。随后该向量会通过一个线性层来转换为若干个向量,向量维度与语言编码器保持一致。接下来,其他类型输入,例如VQA任务中的问题文本被标记化编码到语言模型的嵌入层中,与已编码好的文本图像向量进行拼接,构成一个语言模型可处理的输入序列。为了简单起见,作者对所有的任务都进行生成式的训练,例如分别为图像字幕生成,视觉问答,视觉蕴含推理任务生成一段描述、一个问题的答案和一个类别的名称。在模型训练阶段,文本编码器的参数需要冻结,而只微调语言模型和线性层,以确保在预训练期间模型已学到的文本和图像向量之间的对应关系得到保留。
2.3 模态差异和高斯噪声干扰
在跨模态的模型迁移中,来自同一个对比模型的文本和图像向量仍有可能具有很大的差异,这种现象被称为模态差异。例如在COCO captions数据集中,一幅图像与其成对的标题之间的平均余弦相似度只有0.26,而两个不相关的标题之间的平均相似度是0.35,作者在下图(a)中对这种差异进行了可视化。出现这一现象的根本原因是,对比模型使用的交叉熵损失只要求配对的图像和文本向量相对于随机的一组图像和文本对接近即可,这种设定其实是不合理的。
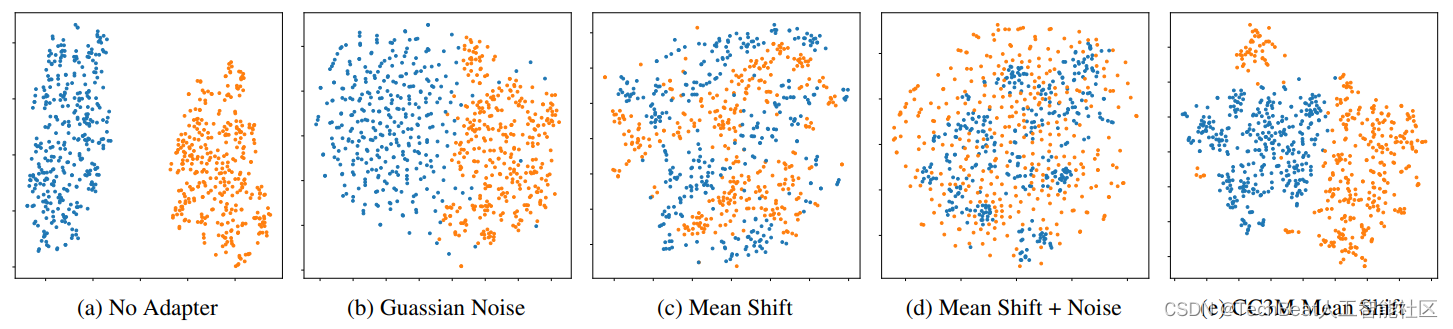
因此作者提出了一种简单有效的解决方案,即在训练阶段为模型加入一个适应模块,将从标准正态分布中提取的高斯噪声添加到文本向量中,然后通过超参数
w
w
w 进行缩放。直观地说,这种噪声要求模型对输入向量的微小变化保持一定的稳定性,从而更好地应对从文本向量切换到图像向量产生的特征波动。上图(b)为加入高斯噪声的结果,我们可以观察到,即使是在
w
=
0.1
w = 0.1
w=0.1 尺度下,加入噪声也会增强嵌入空间的稳定性。当输入的语义略有改变时,添加噪声还可以帮助模型产生具有相似输出的正则化效果,作者还加入了一些其他噪声扰动的对比方法。
三、实验结果
在本文的实验部分,作者重点在三个视觉语言任务上对CLOSE模型进行了性能评估,分别是图像字幕生成、视频问答和视觉蕴含推理。对于图像字幕生成任务,作者在COCO Captioning数据集上进行实验,实验结果如下表所示:
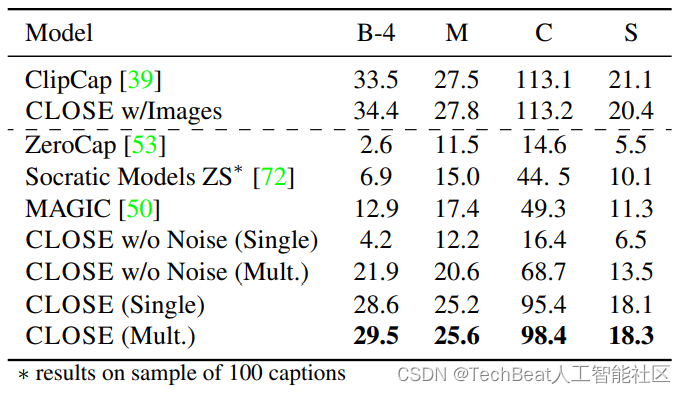
其中(CLOSE Single)表示单字幕生成设置,(Multi CLOSE)表示多字幕生成设置,通过与另一个基于CLIP的字幕模型ClipCap[3]进行比较,可以发现,CLOSE在仅使用文本数据训练的情况下与图像数据训练得到的ClipCap性能基本持平,CLOSE在多字幕和单字幕设置中分别获得了98.4和95.4的分数。此外,CLOSE模型还明显优于零样本方法,这可以是因为零样本方法无法对特定目标的字幕描述进行学习,而CLOSE方法则可以从海量的纯文本数据中获得这些知识。
视觉蕴含推理任务会给定一幅图像和一段与该图像相关的文本描述,要求模型对该文本描述与图像的相关性进行判断,判断类型有三种:蕴含、矛盾和中性。在本文的实验中,作者先在SNLI(一个只含有语言的数据集)上进行训练,然后再SNLIVE(一个视觉语言数据集)上进行评估。实验结果如下表所示,可以看到,CLOSE在无图像参与训练的情况下仍然能够获得与图像模型相近的性能。
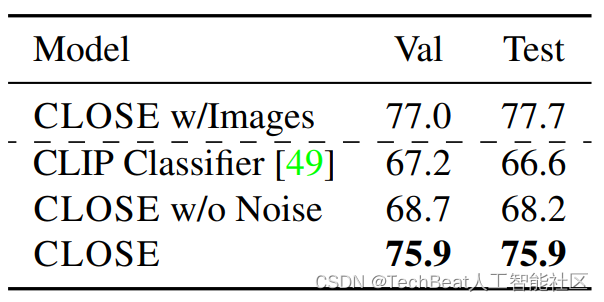
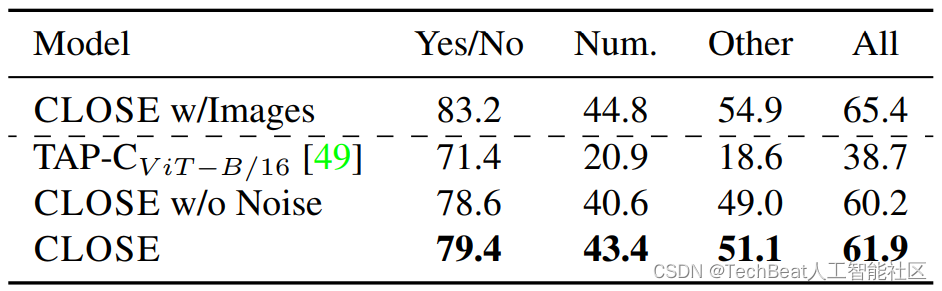
对于视觉问答任务,作者选用VQA 2.0 benchmark进行实验,实验数据包含描述场景的短句(使用文本编码器编码)、问题语句和目标答案。下表展示了CLOSE模型在VQA 2.0数据集上的实验结果。
此外,作者还展示了CLOSE模型的零样本图像字幕生成效果,如下图所示,给定一幅任意图像,CLOSE均能准确的识别当前场景,并为其生成一段风格完善的图像描述。

四、总结
在这项工作中,作者巧妙地利用了目前较为成熟的AI大模型的语义嵌入空间,构建了一个跨模态语义迁移框架CLOSE,并且获得了非常惊人的效果。这也证明了目前基于对比学习范式训练大模型的实用性。此外CLOSE模型仅通过语言数据训练,就可以在图像字幕生成、视觉问答和视觉蕴含等多个任务上达到良好的推理效果,这也向社区指明了一条道路,如果能够合理的利用已有的AI大模型,就可以大大减小对图像数据的人力标注工作。最后作者也期望未来社区能够开发出更多的基于对比范式的跨模态模型。
参考
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
[2] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Rad- ford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. ArXiv, abs/2005.14165, 2020.
[3] Ron Mokady, Amir Hertz, and Amit H Bermano. Clipcap: Clip prefix for image captioning. arXiv preprint arXiv:2111.09734, 2021.
Illustration by Pixel True from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com