不爱生姜不吃醋⭐️⭐️⭐️
声明:
🌻本文写的是关于计算机的存储规则 ❗️
🌻看完之后觉得不错的话麻烦动动小手点个赞赞吧👍
🌻如果本文有什么错误的话欢迎在评论区中指正哦💗
🌻与其明天开始,不如现在行动!💪
🌻大家的支持就是我最大的动力!冲啊!🌹🌹🌹
文章目录
- 🌴计算机存储规则
- 🌴字符集
- 1.ASCII字符集
- 2.GBK字符集
- 3.Unicode字符集
- 🌴总结
🌴计算机存储规则
在计算机中,任意数据都是以二进制形式来存储。一个0或1叫做一个bit(比特位),把八个bit分为一组叫做字节,字节是计算机最小的存储单元。存储英文只需要一个字节。
🌴字符集
1.ASCII字符集
存储:一个字符‘a’,经过ASCII查询后得到其十进制位为97,二进制位为110 0001,此时不足八位,计算机就会进行编码:对其二进制进行补零变为0110 0001存入硬盘。
读取:计算机把存储在硬盘中的数据转化成十进制后查询ASCII变为字符。

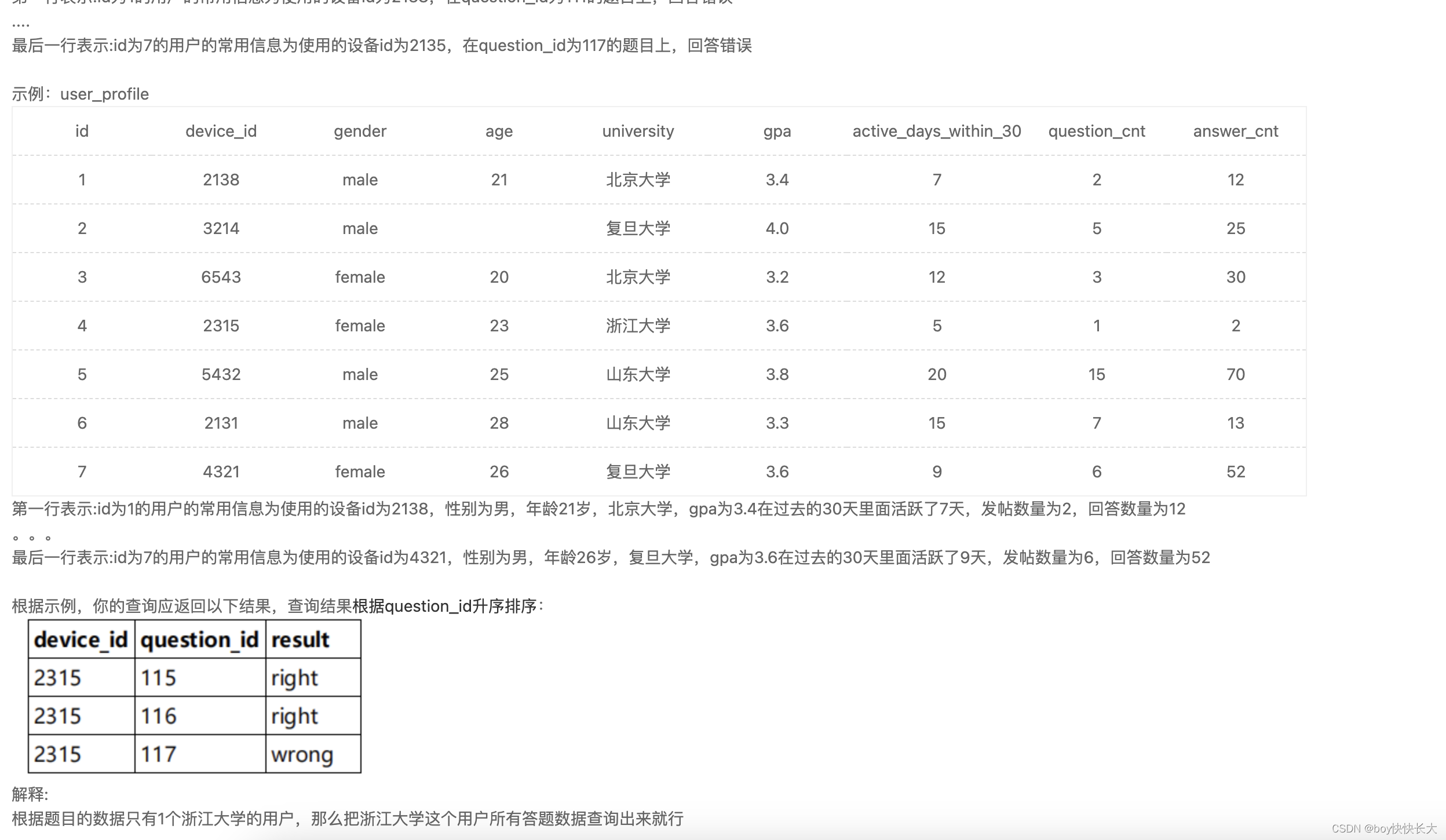
通过上述图片我们可以了解到英文字母的存储规则,但是如果是汉字的话,就不能使用ASCII表。
2.GBK字符集
为了解决不能使用汉字这个问题,国家在1980年的时候发布了GB 2312(中华人民共和国国家标准信息交换用汉字编码字符集)。1984年台湾省实施BIG5字符集(台湾省繁体中文标准字符集)。后面国家为了统一使用,在2000年的时候发布GBK字符集,其中包含国家标准GB13000-1的全部中日韩汉字还有BIG5编码中的所有汉字。
Windows系统简体中文的默认字符集就是GBK(显示的是ANSI)。
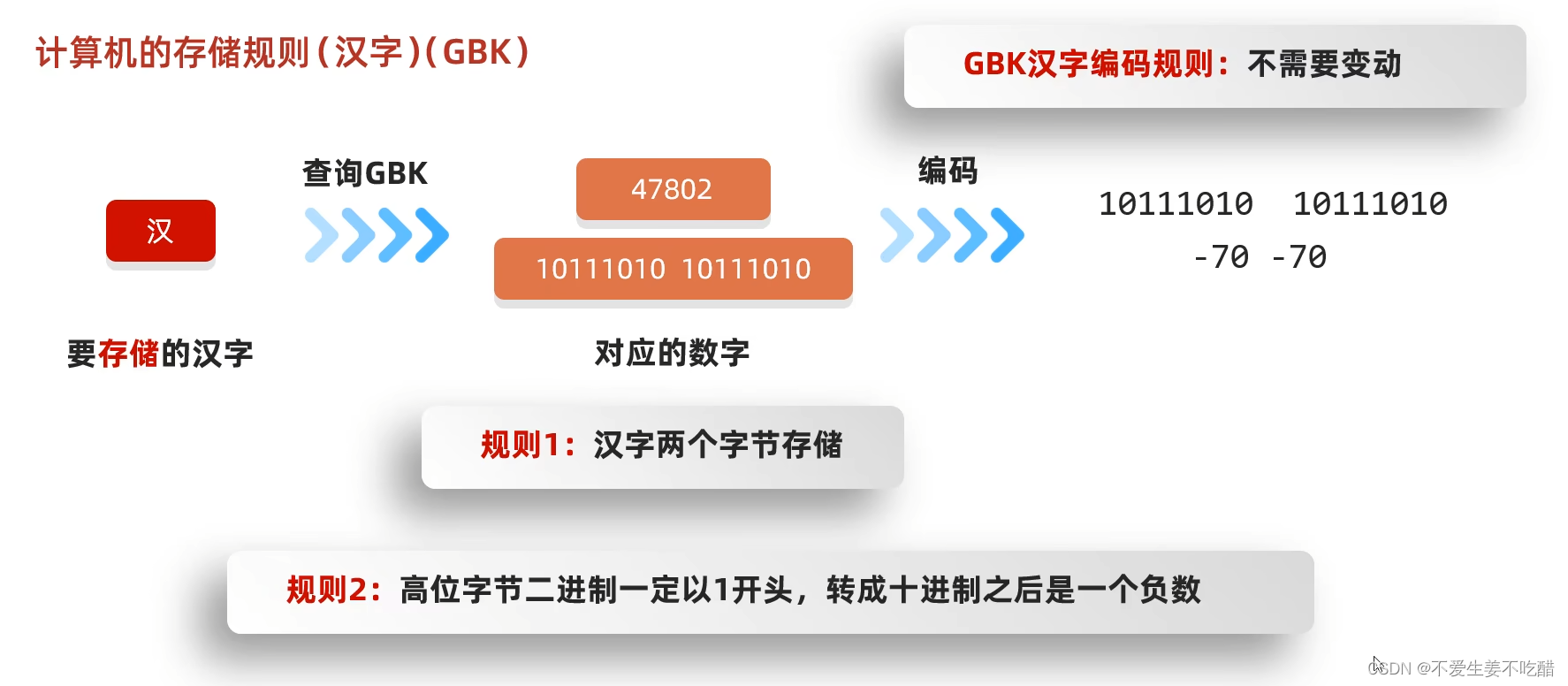
GBK的存储规则分为两个方面:
GBK对于英文的存储规则:
- 英文是一个字节存储,兼容ASCII,二进制前面补0

GBK对于中文的存储规则:
- 汉字用两个字节存储(分为高字节位和低字节位)
- 高字节位二进制一定是以1开头,转化成十进制之后是一个负数
3.Unicode字符集
Unicode字符集是国际标准字符集,将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
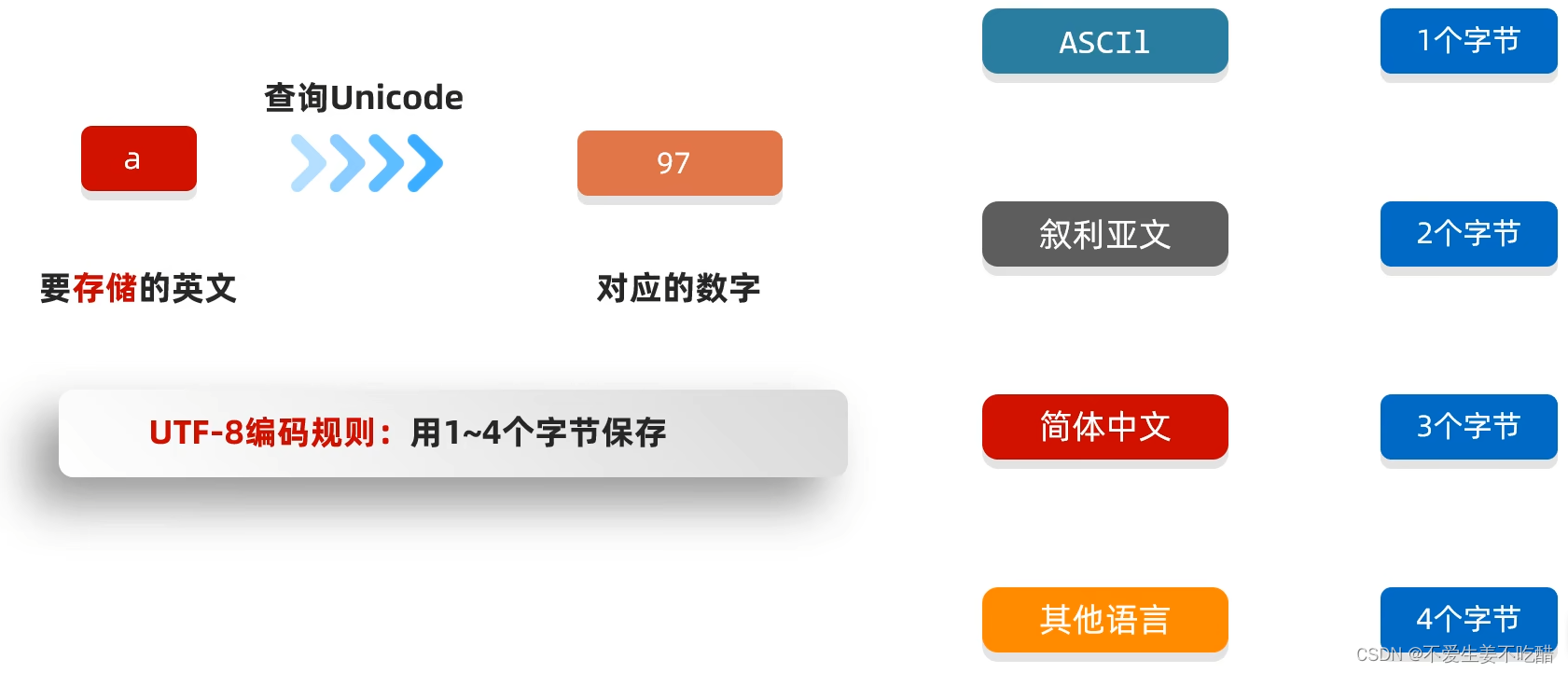
Unicode字符集的UTF-8编码格式中:
- 一个英文占一个字节,二进制第一位是0,转成十进制是正数
- 一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数
Unicode的UFT-8编码格式中对于英文的存储规则:

Unicode的UFT-8编码格式中对于汉字的存储规则:

注意:UTF-8不是一种字符集,它是Unicode字符集的一种编码方式
🌴总结
文章内容是关于计算机的存储规则。
本文中若是有出现的错误请在评论区或者私信指出,我再进行改正优化,如果文章对你有所帮助,请给博主一个宝贵的三连,感谢大家😘!!!