部分问题
- 1. count(1)与count(*)的区别
- 2. ROUND函数
- 3. SQL19 分组过滤练习题
- 4. Mysql bigdecimal 与 float的区别
- 5. 隐式内连接与显示内连接 (INNER可省略)
1. count(1)与count(*)的区别
COUNT(*)和COUNT(1)有什么区别?
count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。
count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
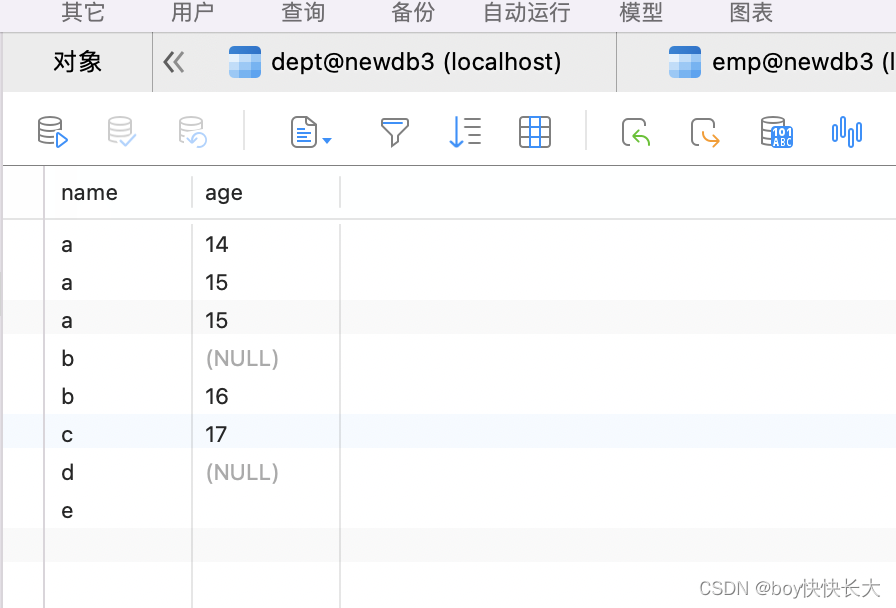
create table counttest(name char(1),age char(2));
insert into counttest values('a', '14'),('a', '15'),('a', '15'),
('b', NULL),('b', '16'),('c', '17'),('d', null),('e','');
SELECT
name,
count( name ),
count( 1 ),
count(*),
count( age ),
count(DISTINCT ( age ))
FROM
counttest group BY name;

2. ROUND函数
MySQL中的ROUND函数是用于将一个数值四舍五入到指定的小数位数的函数。它的语法如下:
ROUND(x, d)
其中,x是要进行四舍五入的数值,d是要保留的小数位数。如果d是正数,则x将四舍五入到小数点后d位;如果d是负数,则x将四舍五入到整数部分的第d位。
以下是一些示例:
- ROUND(3.14159, 2) 返回 3.14。这里将3.14159四舍五入到小数点后2位。
- ROUND(12.345, 0) 返回 12。这里将12.345四舍五入到整数部分。
- ROUND(123.456, -1) 返回 120。这里将123.456四舍五入到整数部分的第一位。
需要注意的是,ROUND函数的舍入规则是标准的四舍五入。如果小数位的下一位是5,将进行向上舍入,否则向下舍入。
另外,还有一个可选的参数mode可以用来指定舍入模式,默认是使用0,表示四舍五入。如果mode是正数,表示向上舍入;如果是负数,表示向下舍入。
总而言之,MySQL中的ROUND函数提供了一种方便的方式来对数值进行四舍五入操作。
SELECT
gender,
university,
COUNT(*) user_num,
ROUND ( AVG( active_days_within_30 ), 1 ) avg_active_days,
ROUND ( AVG( question_cnt ), 1 ) avg_quesition_cnt
FROM
user_profile
GROUP BY
gender,
university
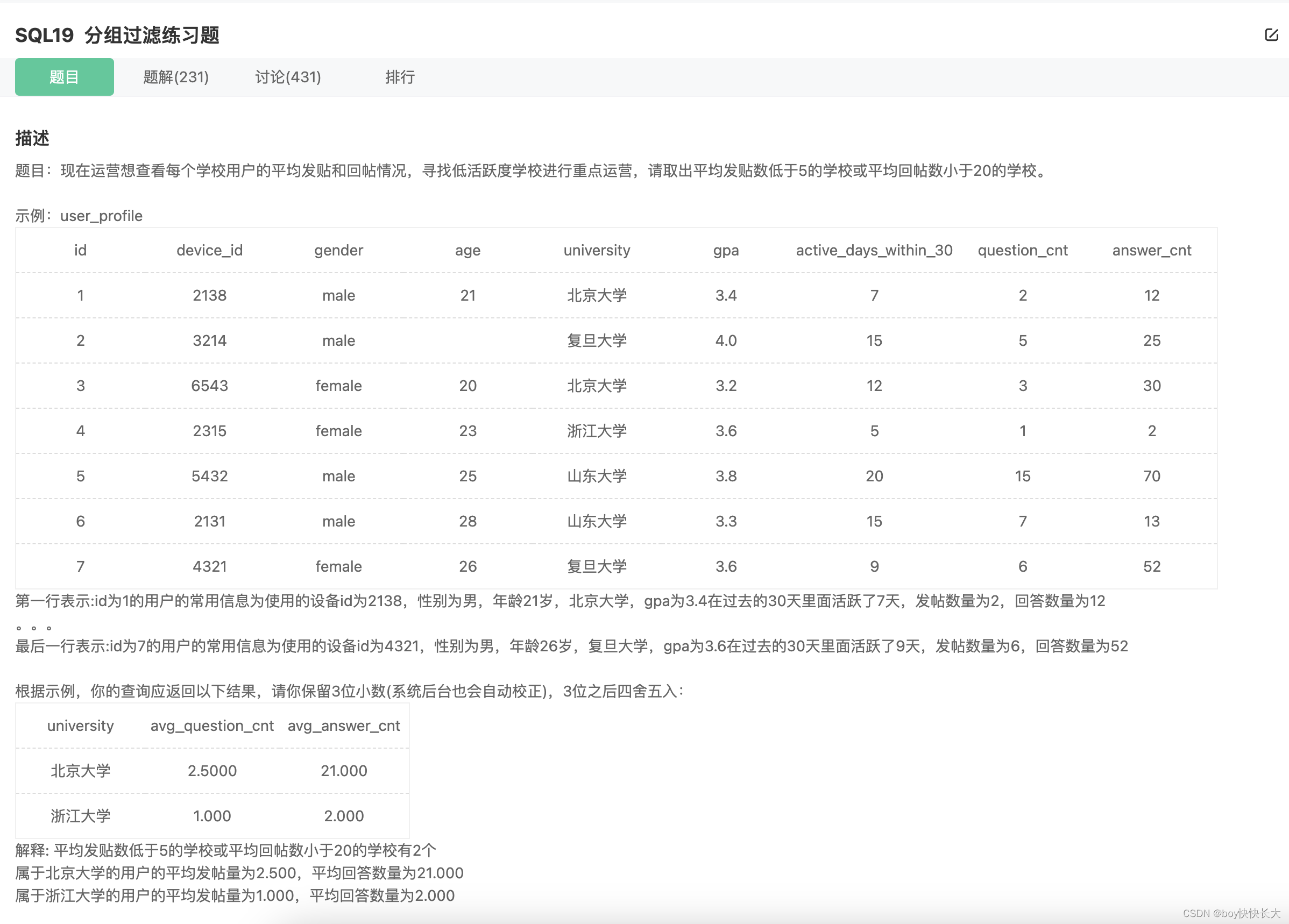
3. SQL19 分组过滤练习题
分组过滤练习题
SELECT
university,
avg( question_cnt ) avg_question_cnt,
avg( answer_cnt ) avg_answer_cnt
FROM
user_profile
GROUP BY
university
HAVING
avg_question_cnt < 5
OR avg_answer_cnt < 20;
DROP TABLE IF EXISTS user_profile;
CREATE TABLE `user_profile` (
`id` INT NOT NULL,
`device_id` INT NOT NULL,
`gender` VARCHAR ( 14 ) NOT NULL,
`age` INT,
`university` VARCHAR ( 32 ) NOT NULL,
`gpa` FLOAT,
`active_days_within_30` INT,
`question_cnt` FLOAT,
`answer_cnt` FLOAT
);
INSERT INTO user_profile VALUES(1,2138,'male',21,'北京大学',3.4,7,2,12);
INSERT INTO user_profile VALUES(2,3214,'male',null,'复旦大学',4.0,15,5,25);
INSERT INTO user_profile VALUES(3,6543,'female',20,'北京大学',3.2,12,3,30);
INSERT INTO user_profile VALUES(4,2315,'female',23,'浙江大学',3.6,5,1,2);
INSERT INTO user_profile VALUES(5,5432,'male',25,'山东大学',3.8,20,15,70);
INSERT INTO user_profile VALUES(6,2131,'male',28,'山东大学',3.3,15,7,13);
INSERT INTO user_profile VALUES(7,4321,'male',28,'复旦大学',3.6,9,6,52);
复制
输出:
university|avg_question_cnt|avg_answer_cnt
北京大学 |2.500 |21.000
浙江大学 |1.000 |2.000
4. Mysql bigdecimal 与 float的区别
在MySQL中,BigDecimal和Float是用于存储和处理数值类型的数据的两种不同的数据类型,它们具有以下几个重要的区别:
-
精度:BigDecimal是一种高精度的数值类型,可以存储任意精度的数值,而Float是一种单精度浮点数类型,具有固定的位数限制。一般来说,BigDecimal可以存储更大范围的数值,并保留更高的精度。
-
四舍五入:由于浮点数在二进制表示中的限制,Float类型的数值在进行计算和存储时可能会产生舍入误差。这意味着在进行精确计算时,BigDecimal通常比Float更可靠,因为BigDecimal采用了基于十进制的表示方式,能够精确地进行四舍五入。
-
存储空间:Float类型的数据占用的存储空间通常比BigDecimal要小。对于大量的数值数据,使用Float类型可能会节省存储空间。
-
计算性能:由于BigDecimal是基于BigInteger的,在进行计算时可能会比Float类型更加耗费计算资源。Float类型可以使用硬件浮点数运算指令进行快速计算,而BigDecimal则需要进行更复杂的算法计算。
综上所述,当需要精确计算和高精度存储时,尤其是在金融领域或需要精确计算的场景中,推荐使用BigDecimal。而当对精度要求不高,且需要节省存储空间和提高计算性能时,可以考虑使用Float类型。
5. 隐式内连接与显示内连接 (INNER可省略)
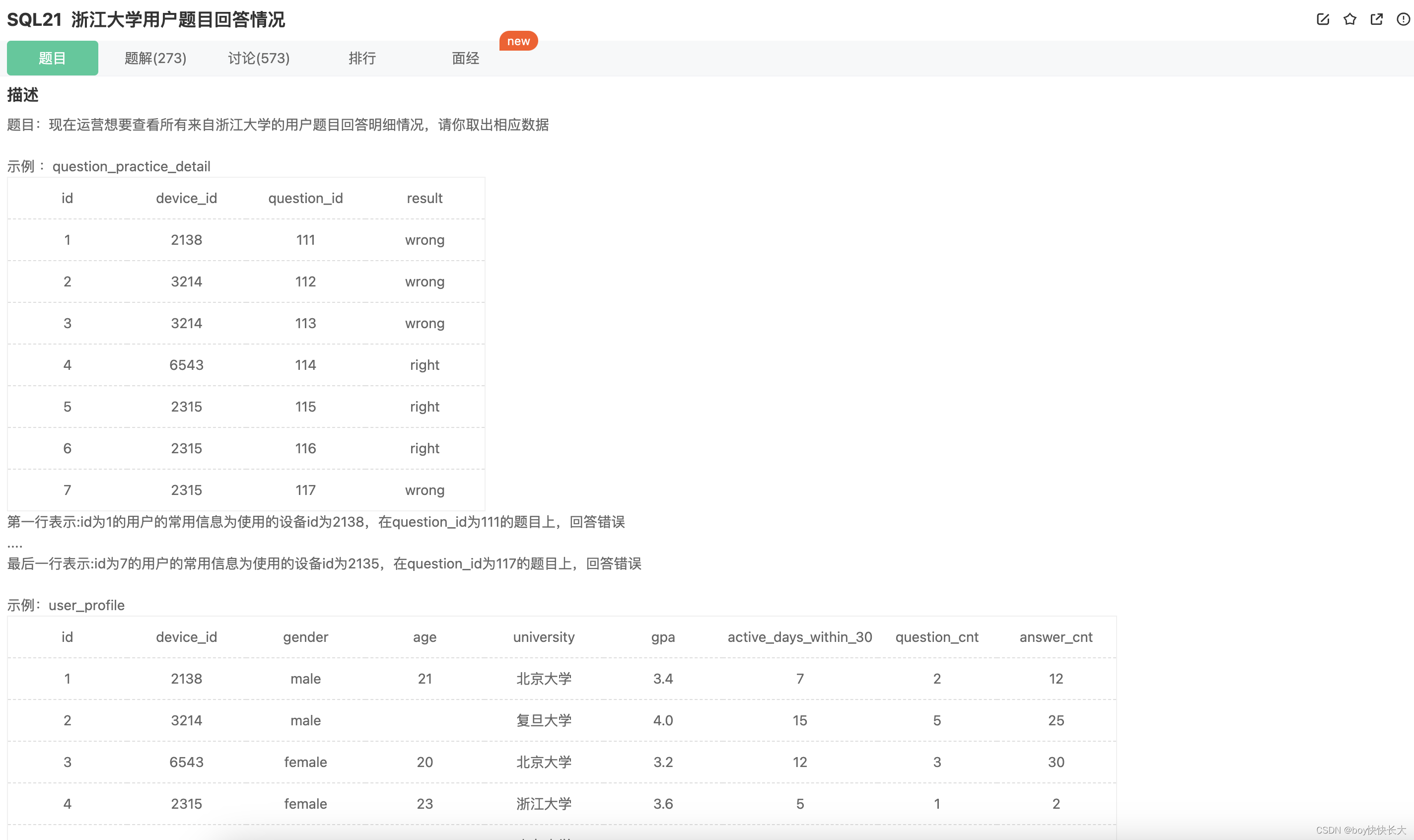
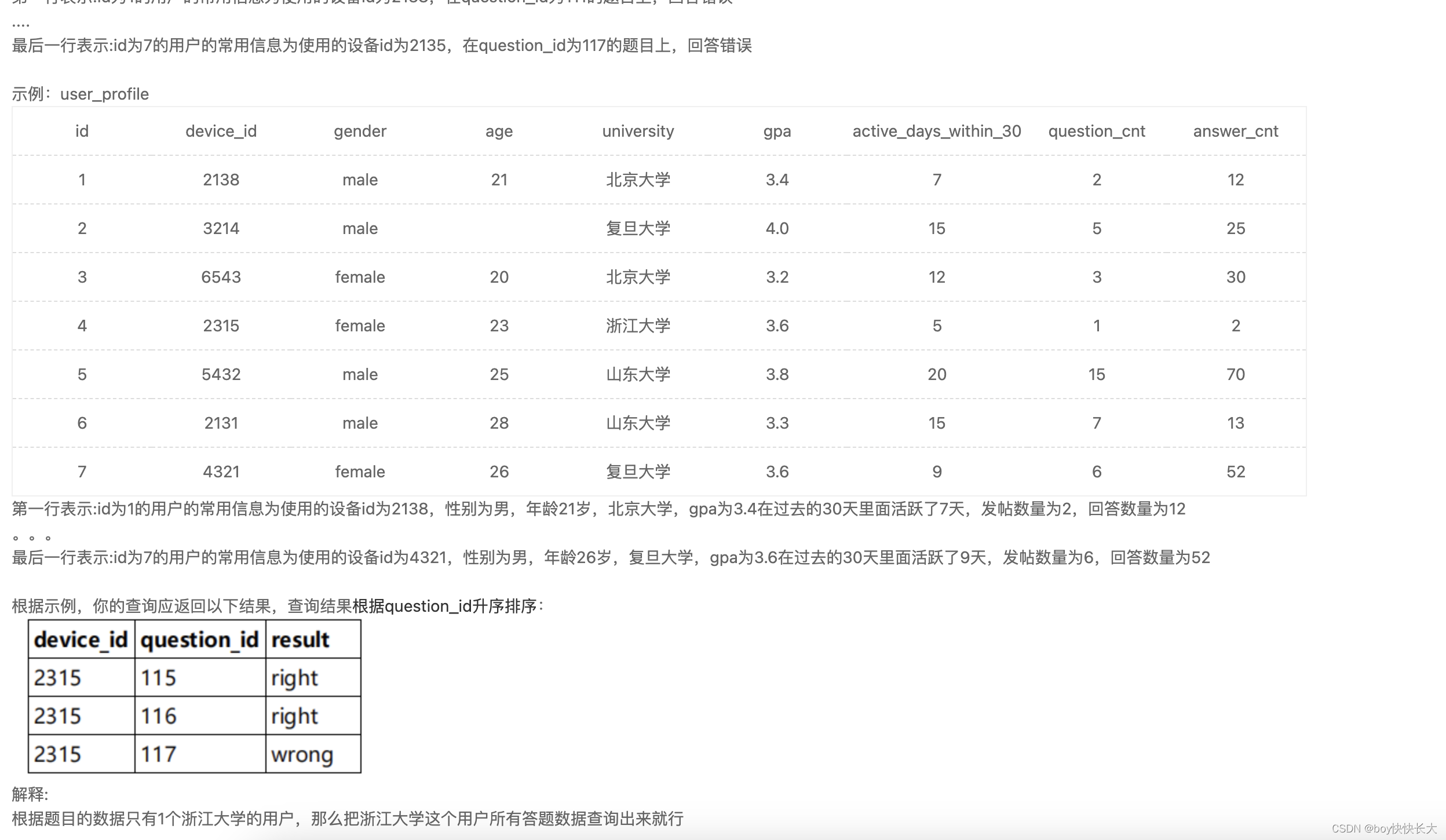
-- 隐式内连接
SELECT
q.device_id,
q.question_id,
q.result
FROM
question_practice_detail q,
user_profile u
WHERE
q.device_id = u.device_id
AND u.university = '浙江大学';
-- 显示内连接 (INNER可省略)
SELECT
q.device_id,
q.question_id,
q.result
FROM
question_practice_detail q
INNER JOIN user_profile u
ON q.device_id = u.device_id
WHERE
u.university = '浙江大学';