1. YOLOv7模型介绍
YOLOv7是目标检测算法YOLO(You Only Look Once)的第七个版本,也是目前较流行的YOLO算法版本之一。
YOLOv8主要结构:
1. Backbone网络:采用CSPDarknet53作为主干网络,在不增加参数数量的情况下提高了网络效果。CSPDarknet53使用多层跨层连接(Cross Stage Partial)实现,可以缓解梯度弥散,提高了特征表达能力。
2. Neck:采用YOLONeck模块作为连接头,用于整合backbone网络输出的不同尺度特征图,提供更丰富的语义信息给下一步的处理。
3. Head:使用YOLOv7Head模块,具有多任务同时实现物体识别和定位,且充分利用不同分辨率的特征图,使得对不同尺寸物体的检测有更好的性能。
4. 损失函数:采用YOLOv3采用的损失函数,由于该损失函数在训练过程中可以平衡不同尺寸目标框的权重,使得算法对大、小目标框有更好的检测效果。
相较于其他YOLO系列算法:
1. 网络结构:YOLOv7采用了CSPDarknet53作为主干网络,使用多层跨层连接,提高了特征表达能力,同时采用了YOLONeck模块和YOLOv7Head模块,使得对不同尺寸物体的检测有更好的性能。
2. 数据增强:YOLOv7引入新的数据增强策略,增加训练数据的难度,提高算法的鲁棒性和泛化能力。
3. 训练策略:YOLOv7使用动态权重更新技术,可根据目标的重要性自适应地调整权重,同时使用注意力机制和最大建模平均池化等技术,提高了检测性能。
4. 精度和速度:YOLOv7采用上述改进方案,提高了算法的精度和速度,具有更好的鲁棒性和泛化性能。
YOLOv7在COCO数据集的评测结果为,使用YOLOv7-S模型,测试时使用图像的每个正方形区域都被分为2个子区域的方法,得到的F1值可以达到46.9%,可以满足一些低精度的检测应用。同时,使用YOLOv7母型模型在图像尺寸为608×608的情况下,在COCO最新测试集上,获得的FPS为76.5,同时平均准确率F1值为54.2%,相较于其它目标检测算法,YOLOv7的检测速度和准确度都具有一定优势。
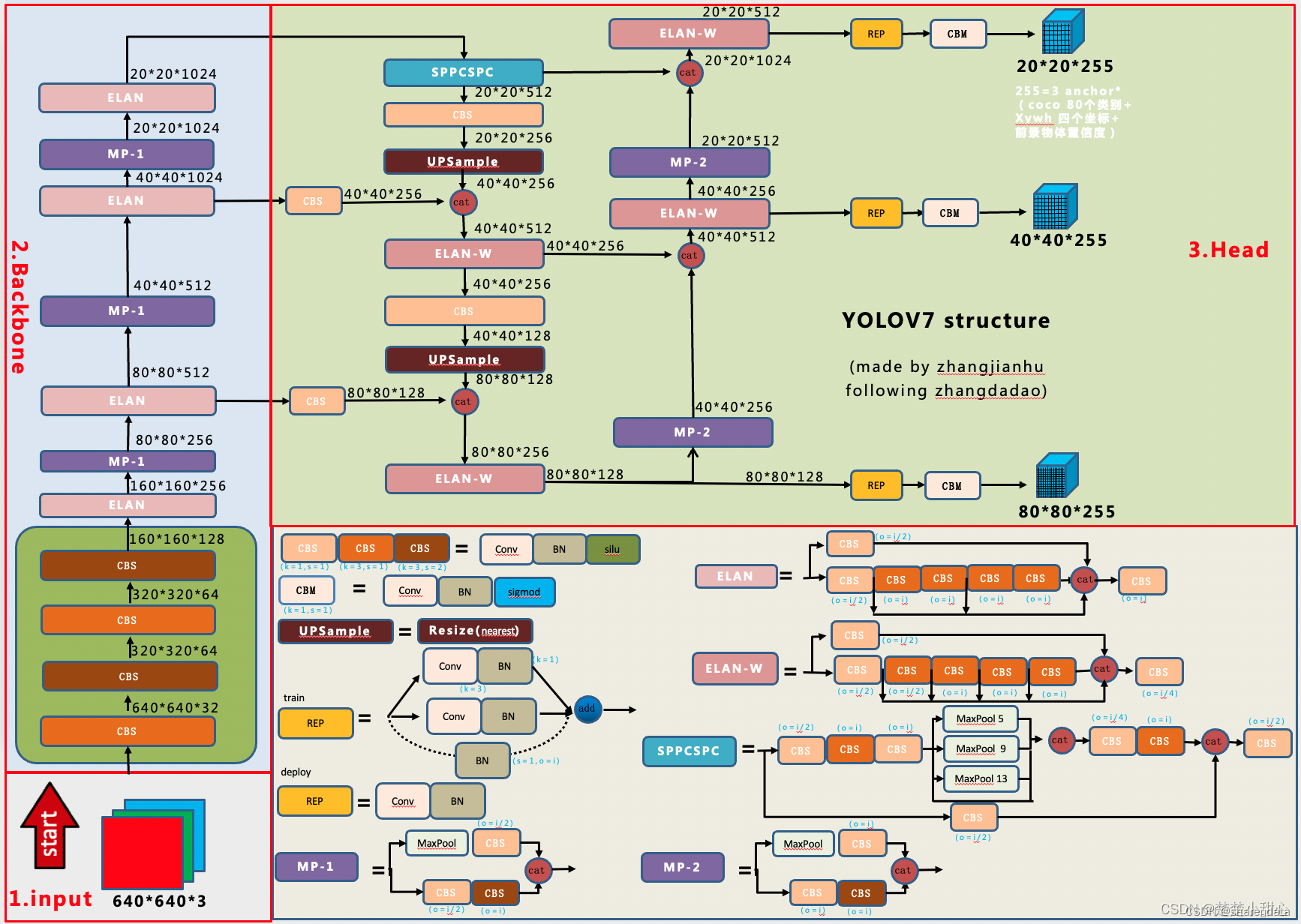
YOLOv7结构图来源:YOLOV7详细解读(一)网络架构解读
YOLOv7的主干特征提取网络:
from functools import wraps
from tensorflow.keras import backend as K
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Add, BatchNormalization, Concatenate, Conv2D, Layer,
MaxPooling2D, ZeroPadding2D)
from tensorflow.keras.regularizers import l2
from utils.utils import compose
class SiLU(Layer):
def __init__(self, **kwargs):
super(SiLU, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.sigmoid(inputs)
def get_config(self):
config = super(SiLU, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_initializer' : RandomNormal(stddev=0.02), 'kernel_regularizer' : l2(kwargs.get('weight_decay', 0))}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2, 2) else 'same'
try:
del kwargs['weight_decay']
except:
pass
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_SiLU(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
if "name" in kwargs.keys():
no_bias_kwargs['name'] = kwargs['name'] + '.conv'
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(momentum = 0.97, epsilon = 0.001, name = kwargs['name'] + '.bn'),
SiLU())
def Transition_Block(x, c2, weight_decay=5e-4, name = ""):
x_1 = MaxPooling2D((2, 2), strides=(2, 2))(x)
x_1 = DarknetConv2D_BN_SiLU(c2, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x_1)
x_2 = DarknetConv2D_BN_SiLU(c2, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
x_2 = ZeroPadding2D(((1, 1),(1, 1)))(x_2)
x_2 = DarknetConv2D_BN_SiLU(c2, (3, 3), strides=(2, 2), weight_decay=weight_decay, name = name + '.cv3')(x_2)
y = Concatenate(axis=-1)([x_2, x_1])
return y
def Multi_Concat_Block(x, c2, c3, n=4, e=1, ids=[0], weight_decay=5e-4, name = ""):
c_ = int(c2 * e)
x_1 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
x_2 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
x_all = [x_1, x_2]
for i in range(n):
x_2 = DarknetConv2D_BN_SiLU(c2, (3, 3), weight_decay=weight_decay, name = name + '.cv3.' + str(i))(x_2)
x_all.append(x_2)
y = Concatenate(axis=-1)([x_all[id] for id in ids])
y = DarknetConv2D_BN_SiLU(c3, (1, 1), weight_decay=weight_decay, name = name + '.cv4')(y)
return y
def darknet_body(x, transition_channels, block_channels, n, phi, weight_decay=5e-4):
ids = {
'l' : [-1, -3, -5, -6],
'x' : [-1, -3, -5, -7, -8],
}[phi]
x = DarknetConv2D_BN_SiLU(transition_channels, (3, 3), strides = (1, 1), weight_decay=weight_decay, name = 'backbone.stem.0')(x)
x = ZeroPadding2D(((1, 1),(1, 1)))(x)
x = DarknetConv2D_BN_SiLU(transition_channels * 2, (3, 3), strides = (2, 2), weight_decay=weight_decay, name = 'backbone.stem.1')(x)
x = DarknetConv2D_BN_SiLU(transition_channels * 2, (3, 3), strides = (1, 1), weight_decay=weight_decay, name = 'backbone.stem.2')(x)
x = ZeroPadding2D(((1, 1),(1, 1)))(x)
x = DarknetConv2D_BN_SiLU(transition_channels * 4, (3, 3), strides = (2, 2), weight_decay=weight_decay, name = 'backbone.dark2.0')(x)
x = Multi_Concat_Block(x, block_channels * 2, transition_channels * 8, n=n, ids=ids, weight_decay=weight_decay, name = 'backbone.dark2.1')
x = Transition_Block(x, transition_channels * 4, weight_decay=weight_decay, name = 'backbone.dark3.0')
x = Multi_Concat_Block(x, block_channels * 4, transition_channels * 16, n=n, ids=ids, weight_decay=weight_decay, name = 'backbone.dark3.1')
feat1 = x
x = Transition_Block(x, transition_channels * 8, weight_decay=weight_decay, name = 'backbone.dark4.0')
x = Multi_Concat_Block(x, block_channels * 8, transition_channels * 32, n=n, ids=ids, weight_decay=weight_decay, name = 'backbone.dark4.1')
feat2 = x
x = Transition_Block(x, transition_channels * 16, weight_decay=weight_decay, name = 'backbone.dark5.0')
x = Multi_Concat_Block(x, block_channels * 8, transition_channels * 32, n=n, ids=ids, weight_decay=weight_decay, name = 'backbone.dark5.1')
feat3 = x
return feat1, feat2, feat3
YOLOv7特征金字塔部分:
import numpy as np
from tensorflow.keras.layers import (Add, BatchNormalization, Concatenate, Conv2D, Input,
Lambda, MaxPooling2D, UpSampling2D)
from tensorflow.keras.models import Model
from nets.backbone import (DarknetConv2D, DarknetConv2D_BN_SiLU,
Multi_Concat_Block, SiLU, Transition_Block,
darknet_body)
from nets.yolo_training import yolo_loss
def SPPCSPC(x, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13), weight_decay=5e-4, name=""):
c_ = int(2 * c2 * e) # hidden channels
x1 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
x1 = DarknetConv2D_BN_SiLU(c_, (3, 3), weight_decay=weight_decay, name = name + '.cv3')(x1)
x1 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv4')(x1)
y1 = Concatenate(axis=-1)([x1] + [MaxPooling2D(pool_size=(m, m), strides=(1, 1), padding='same')(x1) for m in k])
y1 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv5')(y1)
y1 = DarknetConv2D_BN_SiLU(c_, (3, 3), weight_decay=weight_decay, name = name + '.cv6')(y1)
y2 = DarknetConv2D_BN_SiLU(c_, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
out = Concatenate(axis=-1)([y1, y2])
out = DarknetConv2D_BN_SiLU(c2, (1, 1), weight_decay=weight_decay, name = name + '.cv7')(out)
return out
def fusion_rep_vgg(fuse_layers, trained_model, infer_model):
for layer_name, use_bias, use_bn in fuse_layers:
conv_kxk_weights = trained_model.get_layer(layer_name + '.rbr_dense.0').get_weights()[0]
conv_1x1_weights = trained_model.get_layer(layer_name + '.rbr_1x1.0').get_weights()[0]
if use_bias:
conv_kxk_bias = trained_model.get_layer(layer_name + '.rbr_dense.0').get_weights()[1]
conv_1x1_bias = trained_model.get_layer(layer_name + '.rbr_1x1.0').get_weights()[1]
else:
conv_kxk_bias = np.zeros((conv_kxk_weights.shape[-1],))
conv_1x1_bias = np.zeros((conv_1x1_weights.shape[-1],))
if use_bn:
gammas_kxk, betas_kxk, means_kxk, var_kxk = trained_model.get_layer(layer_name + '.rbr_dense.1').get_weights()
gammas_1x1, betas_1x1, means_1x1, var_1x1 = trained_model.get_layer(layer_name + '.rbr_1x1.1').get_weights()
else:
gammas_1x1, betas_1x1, means_1x1, var_1x1 = [np.ones((conv_1x1_weights.shape[-1],)),
np.zeros((conv_1x1_weights.shape[-1],)),
np.zeros((conv_1x1_weights.shape[-1],)),
np.ones((conv_1x1_weights.shape[-1],))]
gammas_kxk, betas_kxk, means_kxk, var_kxk = [np.ones((conv_kxk_weights.shape[-1],)),
np.zeros((conv_kxk_weights.shape[-1],)),
np.zeros((conv_kxk_weights.shape[-1],)),
np.ones((conv_kxk_weights.shape[-1],))]
gammas_res, betas_res, means_res, var_res = [np.ones((conv_1x1_weights.shape[-1],)),
np.zeros((conv_1x1_weights.shape[-1],)),
np.zeros((conv_1x1_weights.shape[-1],)),
np.ones((conv_1x1_weights.shape[-1],))]
# _fuse_bn_tensor(self.rbr_dense)
w_kxk = (gammas_kxk / np.sqrt(np.add(var_kxk, 1e-3))) * conv_kxk_weights
b_kxk = (((conv_kxk_bias - means_kxk) * gammas_kxk) / np.sqrt(np.add(var_kxk, 1e-3))) + betas_kxk
# _fuse_bn_tensor(self.rbr_dense)
kernel_size = w_kxk.shape[0]
in_channels = w_kxk.shape[2]
w_1x1 = np.zeros_like(w_kxk)
w_1x1[kernel_size // 2, kernel_size // 2, :, :] = (gammas_1x1 / np.sqrt(np.add(var_1x1, 1e-3))) * conv_1x1_weights
b_1x1 = (((conv_1x1_bias - means_1x1) * gammas_1x1) / np.sqrt(np.add(var_1x1, 1e-3))) + betas_1x1
w_res = np.zeros_like(w_kxk)
for i in range(in_channels):
w_res[kernel_size // 2, kernel_size // 2, i % in_channels, i] = 1
w_res = ((gammas_res / np.sqrt(np.add(var_res, 1e-3))) * w_res)
b_res = (((0 - means_res) * gammas_res) / np.sqrt(np.add(var_res, 1e-3))) + betas_res
weight = [w_res, w_1x1, w_kxk]
bias = [b_res, b_1x1, b_kxk]
infer_model.get_layer(layer_name).set_weights([np.array(weight).sum(axis=0), np.array(bias).sum(axis=0)])
def RepConv(x, c2, mode="train", weight_decay=5e-4, name=""):
if mode == "predict":
out = DarknetConv2D(c2, (3, 3), name = name, use_bias=True, weight_decay=weight_decay, padding='same')(x)
out = SiLU()(out)
elif mode == "train":
x1 = DarknetConv2D(c2, (3, 3), name = name + '.rbr_dense.0', use_bias=False, weight_decay=weight_decay, padding='same')(x)
x1 = BatchNormalization(momentum = 0.97, epsilon = 0.001, name = name + '.rbr_dense.1')(x1)
x2 = DarknetConv2D(c2, (1, 1), name = name + '.rbr_1x1.0', use_bias=False, weight_decay=weight_decay, padding='same')(x)
x2 = BatchNormalization(momentum = 0.97, epsilon = 0.001, name = name + '.rbr_1x1.1')(x2)
out = Add()([x1, x2])
out = SiLU()(out)
return out
def yolo_body(input_shape, anchors_mask, num_classes, phi, weight_decay=5e-4, mode="train"):
transition_channels = {'l' : 32, 'x' : 40}[phi]
block_channels = 32
panet_channels = {'l' : 32, 'x' : 64}[phi]
e = {'l' : 2, 'x' : 1}[phi]
n = {'l' : 4, 'x' : 6}[phi]
ids = {'l' : [-1, -2, -3, -4, -5, -6], 'x' : [-1, -3, -5, -7, -8]}[phi]
inputs = Input(input_shape)
feat1, feat2, feat3 = darknet_body(inputs, transition_channels, block_channels, n, phi, weight_decay)
P5 = SPPCSPC(feat3, transition_channels * 16, weight_decay=weight_decay, name="sppcspc")
P5_conv = DarknetConv2D_BN_SiLU(transition_channels * 8, (1, 1), weight_decay=weight_decay, name="conv_for_P5")(P5)
P5_upsample = UpSampling2D()(P5_conv)
P4 = Concatenate(axis=-1)([DarknetConv2D_BN_SiLU(transition_channels * 8, (1, 1), weight_decay=weight_decay, name="conv_for_feat2")(feat2), P5_upsample])
P4 = Multi_Concat_Block(P4, panet_channels * 4, transition_channels * 8, e=e, n=n, ids=ids, weight_decay=weight_decay, name="conv3_for_upsample1")
P4_conv = DarknetConv2D_BN_SiLU(transition_channels * 4, (1, 1), weight_decay=weight_decay, name="conv_for_P4")(P4)
P4_upsample = UpSampling2D()(P4_conv)
P3 = Concatenate(axis=-1)([DarknetConv2D_BN_SiLU(transition_channels * 4, (1, 1), weight_decay=weight_decay, name="conv_for_feat1")(feat1), P4_upsample])
P3 = Multi_Concat_Block(P3, panet_channels * 2, transition_channels * 4, e=e, n=n, ids=ids, weight_decay=weight_decay, name="conv3_for_upsample2")
P3_downsample = Transition_Block(P3, transition_channels * 4, weight_decay=weight_decay, name="down_sample1")
P4 = Concatenate(axis=-1)([P3_downsample, P4])
P4 = Multi_Concat_Block(P4, panet_channels * 4, transition_channels * 8, e=e, n=n, ids=ids, weight_decay=weight_decay, name="conv3_for_downsample1")
P4_downsample = Transition_Block(P4, transition_channels * 8, weight_decay=weight_decay, name="down_sample2")
P5 = Concatenate(axis=-1)([P4_downsample, P5])
P5 = Multi_Concat_Block(P5, panet_channels * 8, transition_channels * 16, e=e, n=n, ids=ids, weight_decay=weight_decay, name="conv3_for_downsample2")
if phi == "l":
P3 = RepConv(P3, transition_channels * 8, mode, weight_decay=weight_decay, name="rep_conv_1")
P4 = RepConv(P4, transition_channels * 16, mode, weight_decay=weight_decay, name="rep_conv_2")
P5 = RepConv(P5, transition_channels * 32, mode, weight_decay=weight_decay, name="rep_conv_3")
else:
P3 = DarknetConv2D_BN_SiLU(transition_channels * 8, (3, 3), strides=(1, 1), weight_decay=weight_decay, name="rep_conv_1")(P3)
P4 = DarknetConv2D_BN_SiLU(transition_channels * 16, (3, 3), strides=(1, 1), weight_decay=weight_decay, name="rep_conv_2")(P4)
P5 = DarknetConv2D_BN_SiLU(transition_channels * 32, (3, 3), strides=(1, 1), weight_decay=weight_decay, name="rep_conv_3")(P5)
out2 = DarknetConv2D(len(anchors_mask[2]) * (5 + num_classes), (1, 1), weight_decay=weight_decay, strides = (1, 1), name = 'yolo_head_P3')(P3)
out1 = DarknetConv2D(len(anchors_mask[1]) * (5 + num_classes), (1, 1), weight_decay=weight_decay, strides = (1, 1), name = 'yolo_head_P4')(P4)
out0 = DarknetConv2D(len(anchors_mask[0]) * (5 + num_classes), (1, 1), weight_decay=weight_decay, strides = (1, 1), name = 'yolo_head_P5')(P5)
return Model(inputs, [out0, out1, out2])
def get_train_model(model_body, input_shape, num_classes, anchors, anchors_mask, label_smoothing):
y_true = [Input(shape = (input_shape[0] // {0:32, 1:16, 2:8}[l], input_shape[1] // {0:32, 1:16, 2:8}[l], \
len(anchors_mask[l]), 2)) for l in range(len(anchors_mask))] + [Input(shape = [None, 5])]
model_loss = Lambda(
yolo_loss,
output_shape = (1, ),
name = 'yolo_loss',
arguments = {
'input_shape' : input_shape,
'anchors' : anchors,
'anchors_mask' : anchors_mask,
'num_classes' : num_classes,
'label_smoothing' : label_smoothing,
'balance' : [0.4, 1.0, 4],
'box_ratio' : 0.05,
'obj_ratio' : 1 * (input_shape[0] * input_shape[1]) / (640 ** 2),
'cls_ratio' : 0.5 * (num_classes / 80)
}
)([*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
2. 数据集简介



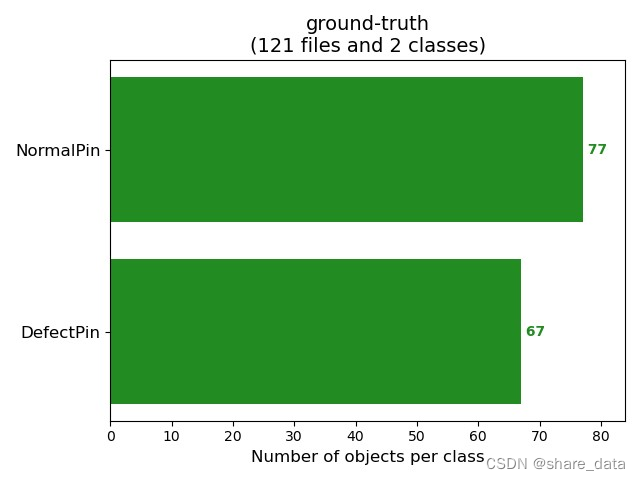
数据集包含1200张图像,利用labelimg标注程序对图像中包含的缺陷进行标注,标注销钉正常与销钉缺失两类目标,标签格式为voc标签。两类标签分布:销钉正常789,销钉异常656。

3. 检测模型训练
3.1 环境准备
训练软件环境:scipy==1.4.1;numpy==1.18.4;matplotlib==3.2.1;opencv_python==4.2.0.34
tensorflow_gpu==2.2.0;tqdm==4.46.1;Pillow==8.2.0;h5py==2.10.0。
硬件环境:Windows11,3060显卡。
3.2 训练参数设置
训练:测试:验证=8:1:1;一开始采用的是Aadm优化器,但训练过程中发现,虽模型拟合速度较快,但训练得到的模型泛化能力很差。采用冻结训练,主要训练参数设置如下:
input_shape = [640, 640]
mosaic = True
mosaic_prob = 0.5
mixup = True
mixup_prob = 0.5
special_aug_ratio = 0.5(前50%轮开启moasic增强)
Init_Epoch = 180
Freeze_Epoch = 50
Freeze_batch_size = 16
UnFreeze_Epoch = 300
Unfreeze_batch_size = 4
Init_lr = 1e-2
Min_lr = Init_lr * 0.01
optimizer_type = "sgd"
momentum = 0.937
weight_decay = 5e-4
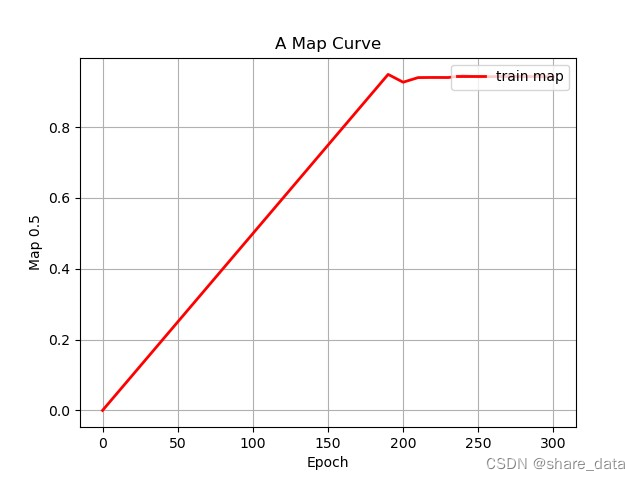
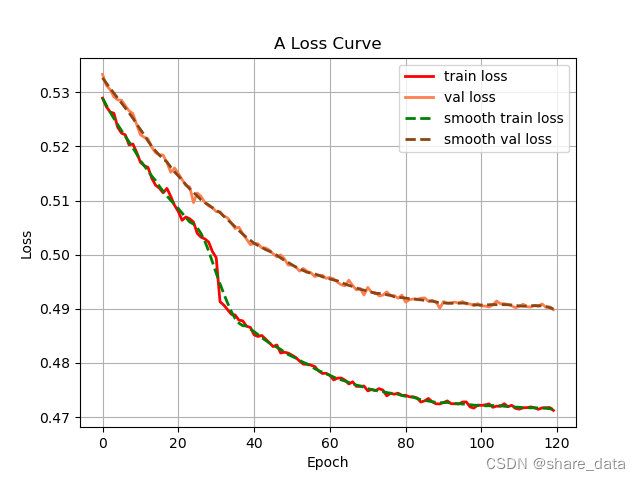
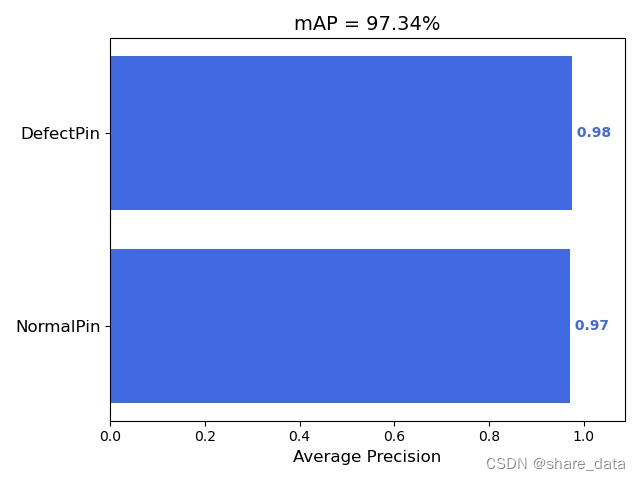
lr_decay_type = 'cos'3.3 训练结果
3.4 测试结果可视化