继承的概念
继承机制是面向对象程序设计当中,非常重要且好用的手段,这种手段可以允许程序员在原有的类的特性基础之上,进行拓展从而产生新的类,这些新产生的类,我们成为派生类。在以前,我们实现的复用是函数的复用,现在衍生到类的设计层次上的复用,就是继承,就是一种对类设计上的复用。
C++ 在此处设计的理念是,父亲干父亲的活,孩子干孩子的活,具体的可以在文章当中去感受。
比如一个在一个学校当中有,很多的个学生和老师,在一个学校当中学生和老师的信息就有相同的,和自己类独特的。比如学生和老师有名字,电话,家庭住址,邮箱等等这些信息是每一个老师和学生都有的信息;
而对于学生,宿舍号,学号,专业等等就是属于学生这个类的独有信息;工号,所属学院,职称等等这些是属于老师的独有信息;所谓独有信息就是两个类之间不共有的信息。
当然,在一个学校当中不只有学生和老师两个“类”,还有食堂工作人员,保安等等多个职位,这些职位都是有共同之处的,比如:都有名字,电话,住址等等这些信息,如果我们把这些“类”都重新设计成各自的类,是不是就是非常的冗余了。
基于上述的问题,继承的作用就非常明显了,基于上述例子,我们可以搞一个 person类,这个类当中存储的是学校的当中所有人员的所共有的信息,比如:名字,年龄,电话号码,住址等等。
然后,所创建的 Student类 , teacher类 等等在类当中只需要写出自己类所独有的信息,再去继承 person 这个类就行了。
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "peter"; // 姓名
int _age = 18; // 年龄
};
// 继承后父类的Person的成员(成员函数+成员变量)都会变成子类的一部分。这里体现出了
//Student和Teacher复用了Person的成员。下面我们使用监视窗口查看Student和Teacher对象,可
//以看到变量的复用。调用Print可以看到成员函数的复用。
class Student : public Person
{
protected:
int _stuid; // 学号
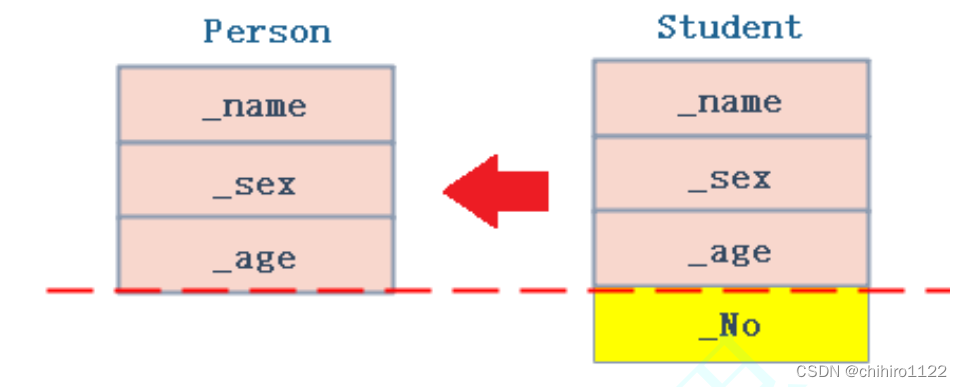
};如上述,Student类 继承了 person类。
而派生类当中(成员函数肯定不存储在类和对象当中)也不止 _stuid 这个成员,除了自己的成员之外,派生类的当中还有从父类当中继承过来的 成员;
也就是说,派生类当中分为两个部分,一个是 派生类 本身的成员部分;另一个是 派生类 从父类当中继承过来的 成员部分。
继承的语法
如下图所示:Person是父类,也称作基类。Student是子类,也称作派生类。

继承关系和访问限定符
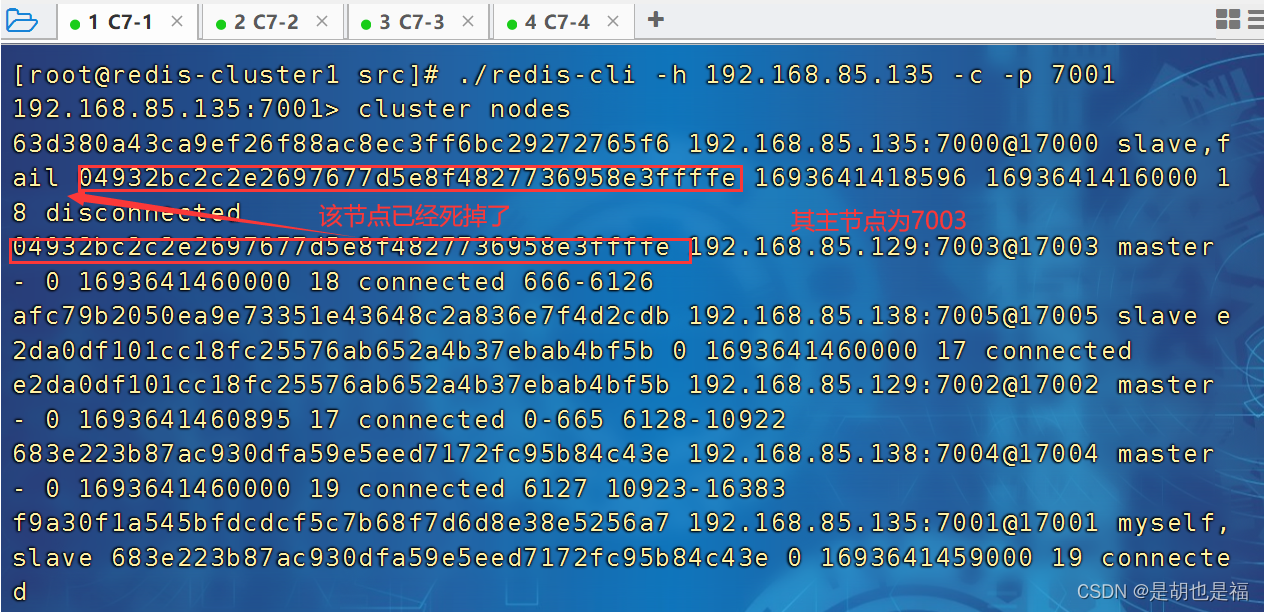
在上述的语法介绍当中我们发现,有继承方式这一个语法,在C++当中的继承规则这一块其实设计还是有点复杂的,如下图所示,根据父类当中的访问限定符有三种,继承方式同样有三种,如下图所示:

在C++当中是以 父类当中访问限定符 和 继承方式两两组合,形成一种新的访问限定,那么总结下来,在继承当中就有 9 种访问方式,如下图所示:
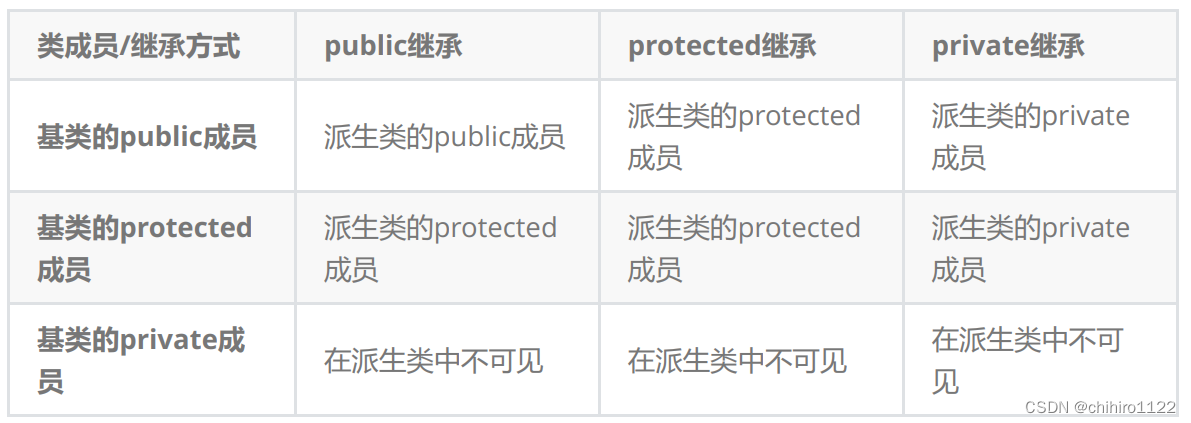
对于上述 9 种结果,其实是有规则可循的,总结如下:
- 基类的private成员,在派生类当中都是不可见的。而 不可见 是 语法上限制访问(类里和类外都不能使用),而private是类外不能使用,类当中说可以使用的。(父类的私有成员,子类无论以什么方式继承不能用)
- 实际上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected> private(取两者小的那一个访问方式,作为最后的访问方式)
- 基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
- C++当中支持默认继承,如果不写继承方式,使用关键字 class 时默认是私有(private)继承;使用关键字 struct 默认是公有(public)继承。(但是建议写上继承方式)(之所以 class 是私有继承,是防止多次继承对基类的影响。如果继承方式是 protected的,那么子类再被继承,产生的派生类还是可以访问到最开始的基类当中的成员,但是如果基类当中的成员是被private的,那么其子类再被继承而产生的派生类,就不能在访问到基类当中的peivate成员了)
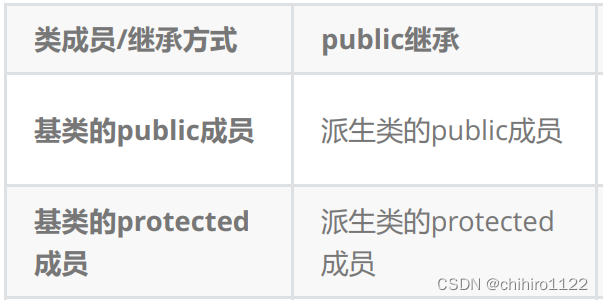
- 在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
实际当中只用如下图所示的访问方式:
基类和派生类的赋值转换
如果是不同类型的内置类型相互赋值,是会发生类型转换的!!
比如:
int a = 1;
double b = 0;
b = a;而类型转换是会产生临时变量来帮助转换的,同样的,基类 和 基类派生出的派生类之间相互赋值也是会发生类型的转换的。
需要注意的是,基类 和 基类派生出的派生类之间相互赋值所发生的类型转换是有条件的。
只能是 派生类赋值给 基类,不能是 基类赋值给 派生类。
因为如果是基类赋值给 派生类,那么对于派生类当中 独有信息 是基类当中没有的,基类无法给派生类当中的 独有信息 进行赋值。
而且对于基类赋值给派生类这一操作,就算给强制类型转换,都是无法使用的语法,这一操作在语法上直接禁掉了。

报错:

而且,对于基类和派生类的类型转换还和我们之前了解的 隐式类型转换和强制类型转换不一样;后两者在转换的时候,会产生临时变量;
而且 基类 和 派生类的类型类型转换不会产生临时变量,他们之间的类型转换 是 赋值兼容(切割,切片)。
我们认为,一个子类对象一定是一个特殊的父类对象,至少子类对象的当中一定有父类的成员。子类赋值给父类的话,会把子类当中父类的成员切割出来,然后再把这些成员拷贝给父类。

如果是父类转化为子类的话,单纯的对象之间是不能转换的,但是如果是引用和指针的话还是可以的,可以使用RTTI(RunTime Type Information)的dynamic_cast 来进行识别后进行安全转换。
验证 赋值兼容 没有产生临时对象
如下例子:
student s; ·········1
person& p = s;
int a = 1; ·········2
double& b = a; 如上所示,我们知道,对于p这个引用,如果是发生在内置类型或者是没有父子关系的对象之间,会发生隐式类型转换,从而产生临时对象,所以如果不是 赋值兼容的 话(如上述例子2),引用应该指向的是 类型转换 所产生的临时变量。
而临时变量具有常性,上述例子2 的引用 b 没有用const 修饰,就会报错。
而反观例子1 ,就不会报错,说明 例子1 当中没有产生临时变量。
此时例子1 当中的 引用 是 s 对象的一个别名。
继承当中的作用域
对于基类 和 基类派生出的派生类,都是有独自的作用域。所以如果你在基类 和 派生类当中定义出相同名字的成员,这个语法是通过的。如下代码所示:
// 父类
class Person
{
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
// 子类
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;
cout << " 学号:" << _num << endl;
}
protected:
int _num = 999; // 学号
};如上代码所示,父类和子类当中都有一个 _num 成员。但是没有报错。
如果我们此时调用 Print()函数,那么打印的 _num 的值是多少呢?
答案是 999。
- 这是因为,如果在父类和子类当中有同名的成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
显示访问父类成员:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;
cout << " 学号:" << Person::_num << endl;
}
同样的,这样的同名,不仅仅允许在成员,也允许在成员函数,而且同名的成员函数也是和同名的成员一样的,子类会对父类的进行隐藏,默认是调用子类的同名成员函数。当然也可以显示的调用父类的同名成员函数:
class Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;
cout << " 学号:" << Person::_num << endl;
}
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;
cout << " 学号:" << Person::_num << endl;
}
protected:
int _num = 999; // 学号
};
void Test()
{
Student s1;
s1.Person::Print();
};此时的子类当中Print()和父类当中的Print()因为不是在同一作用域,不是构成重载,此时是子类和父类的关系的成员函数满足函数名相同就构成隐藏。
域是查找规则的概念,他规定编译器应该去哪一个域当中去寻找变量或者函数(而且此时的 查找是在编译时期的查找,编译器首先要查找有没有这个变量/函数,没有就要报错。还有一个查找是生成代码之后,更具地址去查找变量/ 函数),所以编译器对于一个域当中没有查找到的变量/函数,他会在下一个域去寻找,而下一个域也是按照顺序来的。比如:子类当中没有的成员,就会在父类当中去寻找。
但是即使是允许子类和父类之间使用同名成员,我们也不建议这样 在继承体系当中 去 定义子类和父类当中的成员和成员函数。
派生类的默认成员函数
一个类当中有 6 个默认成员函数,其中“默认”的意思就是,我们不写这6个成员函数,编译器会自动生成一个。6 个 当中常用的就是 4 个,如下所示:
构造函数 和 拷贝构造函数
派生类 中的 构造函数 当中的初始化列表,只能初始化本派生类的成员,不能初始化父类当中的成员;但是,在构造函数的定义的当中对 父类当中的成员进行修改是可以。
class Person
{
protected:
string _name = "小李子"; // 姓名
};
class Student : public Person
{
Student(const char& name, int num)
:_name(name)
,_num(num)
{
_name = "nnn";
}
protected:
int _num = 999; // 学号
};如上父类当中的 _name 成员不能再 子类 的 构造函数 的初始化列表当中用,但是可以在构造函数的定义的当中被修改:

再如下例子,我们把父类(Person) 的构造函数 和 析构函数写出来,并打印一下名字,方便给出提示,提示我们哪一个函数被调用了。其次,我们在主函数当中只定义子类对象 (Student)。
class Person
{
public:
Person()
{
cout << Person() << endl;
}
~Person()
{
cout << ~Person() << endl;
}
protected:
string _name = "小李子"; // 姓名
};
class Student : public Person
{
Student(int num)
:_num(num)
{
}
protected:
int _num = 999; // 学号
};
int main()
{
Student s;
}打印结果:

但是打印结果 却 打印的父类的 构造函数 和 析构函数名。
这是因为,C++规定,派生类必须调用 父类的构造函数 去初始化父类的成员,不管在主函数当中有没有定义 父类对象。(这种自动调用,都是调用的默认函数,此时就是默认构造函数,如果我们没有提供默认构造就会报错)
所以,如果父类没有默认构造函数,我们就要在子类的初始化列表当中,对父类进行初始化(就像定义一个匿名对象一样)如下代码所示:
class Person
{
public:
Person(const char& name)
:_name(name)
{
cout << Person() << endl;
}
~Person()
{
cout << ~Person() << endl;
}
protected:
string _name = "小李子"; // 姓名
};
class Student : public Person
{
public:
Student(const char& name , int num)
:_num(num)
,Person(name)
{
}
protected:
int _num = 999; // 学号
};注意:
- 而且此时是 Person(name)先初始化,_num 后初始化。因为初始化列表 初始化的顺序 不是跟初始化列表的顺序相同的,是和 各个成员声明的顺序相同的。
- 而此时是继承的关系,子类会优先调用 父类 构造函数去初始化父类的 成员,所以会优先 初始化 Person。
对于拷贝构造函数也是和构造函数是一样的,不能在子类的拷贝构造函数的 初始化列表当中去初始化 父类的 成员;同样会优先调用父类的构造函数,去初始化父类的 成员。
对于拷贝构造函数的 对父类的初始化,我们也是使用 和之前构造函数一样的 类似于匿名对象的用法来初始化。但是此时就会出现一个问题,父类当中的 拷贝构造函数 的参数是 父类的 类型,而在拷贝构造函数当中,我们只有子类的 类型可以传参。此时,不用管这么多,可以直接传入子类。(如下代码所示)
// 父类
class Person
{
public:
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
// 拷贝构造函数,此处传入参数是父类 类型的
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
Person& operator=(const Person& p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name; // 姓名
};
// 子类
class Student : public Person
{
public:
Student(const char* name, int num)
: Person(name)
, _num(num)
{
cout << "Student()" << endl;
}
Student(const Student& s)
: Person(s) // 此时直接传入 子类对象即可
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
~Student()
{
cout << "~Student()" << endl;
}
protected:
int _num; //学号
};因为此处,父类的拷贝构造函数的参数是 引用,如果传入的是 子类的类型对象,会发生 赋值兼容转换,也就是切割,把子类当中父类的成员切割出来,进行赋值。
赋值操作符重载函数
对于 赋值操作符重载函数 ,也是一样的,我们把 子类当中 父类的成员部分,和 子类成员部分 都赋值就行:
Student& operator = (const Student& s)
{
cout << "Student& operator= (const Student& s)" << endl;
if (this != &s)
{
Person::operator =(s); // 父类当中已经直接 operator= 函数,此处直接调用
_num = s._num;
}
return *this;
}需要注意的是,我们上述调用了父类当中的 operator= 函数,如果我们不显示去调用,像如下方式写的话就会 出现 “隐藏”:
operator =(s);上述的代码默认调用 子类 当中的 operator= 函数,就会出现递归死循环,栈溢出代码奔溃。
所以我们要显示调用父类当中的 operator= 函数。
析构函数
析构,同样要析构 派生类自己的,还要析构 派生类父类的;析构父类可以直接调用 父类当中的析构函数,但是不能像父类当中其他函数一样直接调用,需要显示指定类域:
~Student()
{
Person::~Person();
}具体原因是因为C++ 当中多态的原因。析构的函数名被进行了特殊处理。由于要构成多态,被统一处理成了 destructor。
因为都被处理成为了 destructor,所以此处就构成了 隐藏 ,所以要显示调用 父类的析构函数。
但是,上述在程序在执行完之后,结果如下:
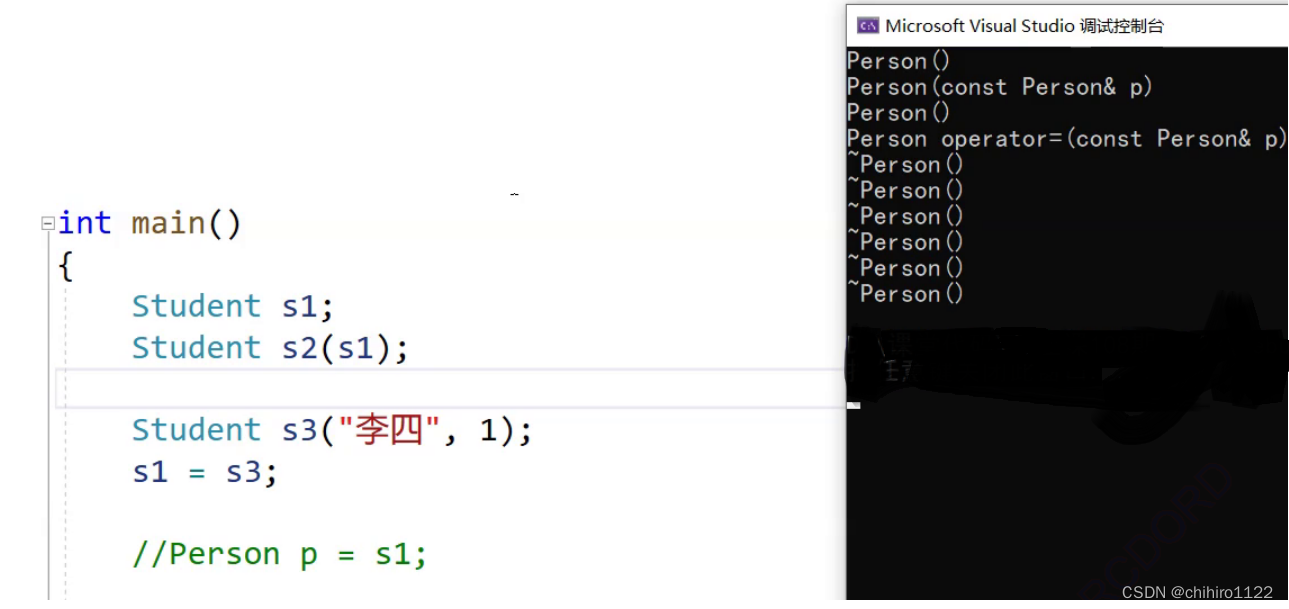
在 3 个子类 Student 当中有 3 个 Person,按道理,在最后应该只调用 3 次 Person 的析构函数,但是此处调用了 6 次。
其实此处是Person 对象自动调用了 自己的析构函数,因为 整个程序 无论你怎么先,都是先构造父类对象,在构造子类对象(也就是说先构造 Person 在构造 Student)····· 这样总共构造了 3 个Student 对象 和 3 个Person对象;
单看一组,根据 先构造的 后 析构,后构造的先析构,那么 Student 对象就会先析构,然后再析构 Person 对象;但是在 Student 的析构函数 已经调用了 Person对象的 析构函数,就在此处发生了重复析构的问题。
如果我们不在 Student 的 析构函数当中去调用 Person对象的析构函数,就是析构3次,是正确的。
因为在构造的时候,是先父后子的顺序进行构造的,所以在析构的时候,应该满足先子后父的析构顺序,但是在子类析构函数当中显示调用 父类析构函数,是无法保证先子后父的析构顺序,所以编译器在子类析构函数完成之后就,自动调用父类析构函数。
其实这里可以不用自动析构,完全可以自己在 子类 Student 的析构函数当中实现上述顺序的 析构顺序。但是C++语法就是有自动调用析构函数,所以我们在 继承体系当中写析构函数的时候,一定要注意这一点,因为多次重复的析构可能会出现问题,比如:重复析构的对象当中有我们自己手动开辟的空间的时候,重复析构就会报错。
为什么在析构的时候要先子后父?
之所以说不能先显示调用父类的析构函数,是因为,在子类的析构函数当中,可能还会用到 父类当中的成员或者成员函数,如果先就析构父类的话,无法调用了,而且在父类当中是不会用到子类当中的成员的,所以我们决定先析构子类,在析构父类。
继承与有元
有元不能继承!!!
也就是,爸爸的朋友不是我的朋友,我爸爸的朋友不能去访问我的成员。
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _stuNum; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
cout << s._stuNum << endl;
}
void main()
{
Person p;
Student s;
Display(p, s);
}上述有元函数 Display 可以访问父类 Person的 _name ;但是不能访问 子类 Student 的 _stuNum成员。
如果想要 友元函数 Display 也能访问到 子类的 _stuNum 成员,需要在子类当中也加上有元声明。
继承与静态成员
如果在父类当中定义了静态成员变量,这个静态成员能不能继承,其实认为可以,和认为不可以都是对的。
在继承当中,子类对象当中都有一个父类对象的存储,相当于是在子类当中构造了一个父类的对象,每一次构造一次子类,都要去调用其父类的构造函数去构造父类出来;但是对于 父类当中的静态成员,究竟是不是 从父类当中拷贝一份到子类当中,我们先看如下例子:
class Person
{
public:
Person() { ++_count; }
public:
static int _count; // 统计人的个数。
string _name; // 姓名
};
// 父类当中的 静态成员变量
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum; // 学号
};
class Graduate : public Student
{
protected:
string _seminarCourse; // 研究科目
};
int main()
{
Person p;
Student s;
Graduate g;
// 父类当中的 非静态成员
cout << &p._name << endl;
cout << &s._name << endl;
cout << &g._name << endl;
cout << "-----这是一个分界线-----" << endl;
// 父类当中的 静态成员
cout << &p._count << endl;
cout << &s._count << endl;
cout << &g._count << endl;
return 0;
}我们把 父类当中 非静态成员 _name 和 静态成员 _count ,在 父类 Person 和 两个子类 Student 和 Graduate 当中打印出地址。
结果输出:
000000EEADF6F508
000000EEADF6F548
000000EEADF6F5A0
-----这是一个分界线-----
00007FF6871B2440
00007FF6871B2440
00007FF6871B2440我们发现,非静态成员的地址是不一样的,说明在子类当中每一次构造对象时候,都对父类当中的非静态成员进行了拷贝构造;
而 下面的 静态成员的地址是一样的,说明后序子类的对父类的构造,并没有对静态成员进行构造,上述的父类和两个子类都是共用一个静态成员变量。
由上述例子,我们得出结论,在父类当中定义的 static 静态成员,则在其整个继承体系当中只有这一个静态成员。而且无论派生出多少个子类,都只会实例化这一个静态成员。
所以我们才会说,对于父类当中的静态成员,其子类其实是继承了,因为可以在子类当中使用这个静态变量;但是这种继承和其他的继承不一样,他不会去在子类当中拷贝构造一个新的静态成员出来,而是整个体系使用一个几台成员。(静态成员继承的是使用权,静态成员同时属于父类和其派生类)
我们上述的例子,还记录了 Person 这个父类,总计创建了多少个派生类(包括Person自己)。实现也非常简单,就是在构造函数当中 ++_count 这个静态成员变量。利用子类在创建时候会先调用父类的构造函数这一特性,来记录派生类创建的个数。
复杂的菱形继承及菱形虚拟继承(多继承)
在现实世界当中,会有一种类别,同时具有两种(多种)类别的特征,也就是同时继承多个父亲。所以在C++当中开发人员也考虑到这种情况的发生,就实现了多继承。
像我们之前的举的例子都是单继承,如下图所示:
而多继承是一个子类有多个父亲:

我们发现,这这种多继承在一般情况下,还是非常符合现实世界的,用起来也是没有问题:
class Student
{
protected:
int _num; //学号
};
class Teacher
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};上述这个人,既是一个老师,又是一个学生,这种是没有问题的。
但是如果 Assistant 这个人继承的 Student , Teacher 两个父类都继承了一个 Person 父类的话,就会出问题:
class Person
{
public:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _num; //学号
};
class Teacher : public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};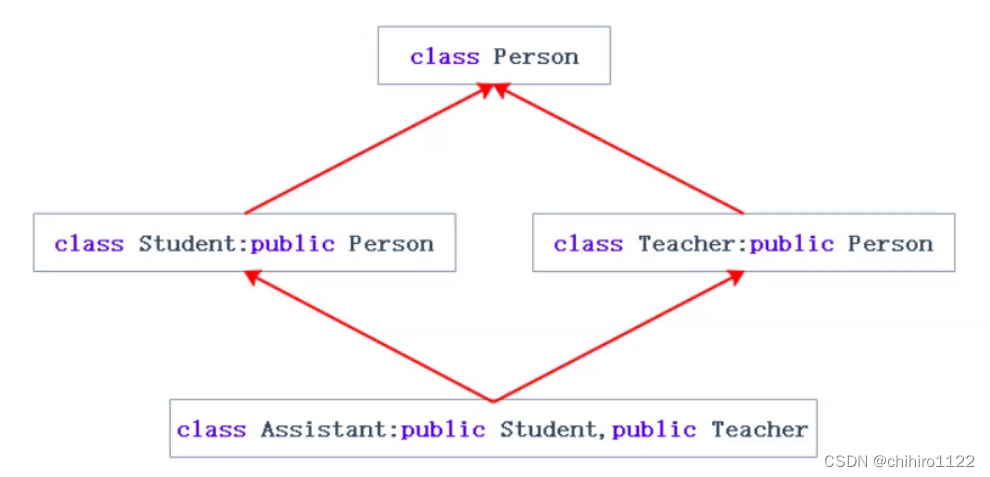
上述这种情况,我们称之为菱形继承。他是多继承的一种特殊情况。
这种情况出现的问题不是对person的多次构造和析构,因为两个构造的person对象是存在于Student 和 Teacher 当中的,不会出问题。
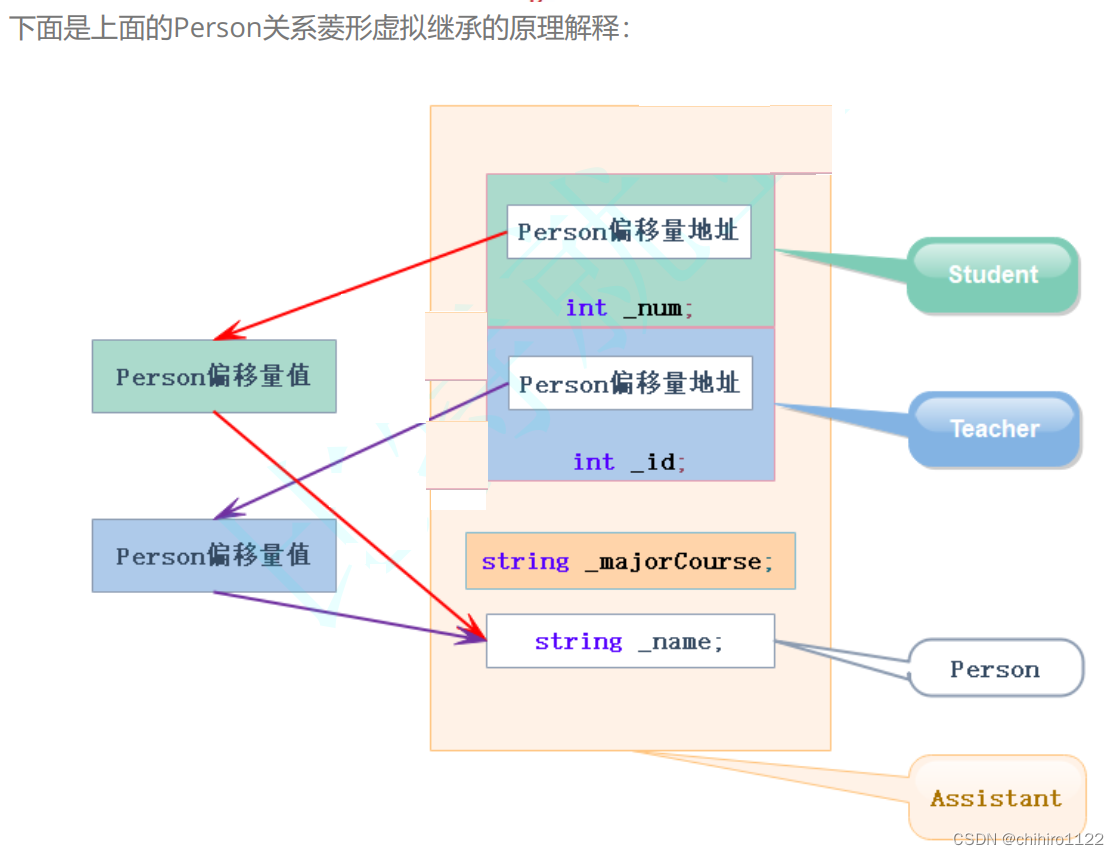
真正的问题是对于 Assistant 对象,拥有了多个 Person 类当中的成员属性。如下图所示:
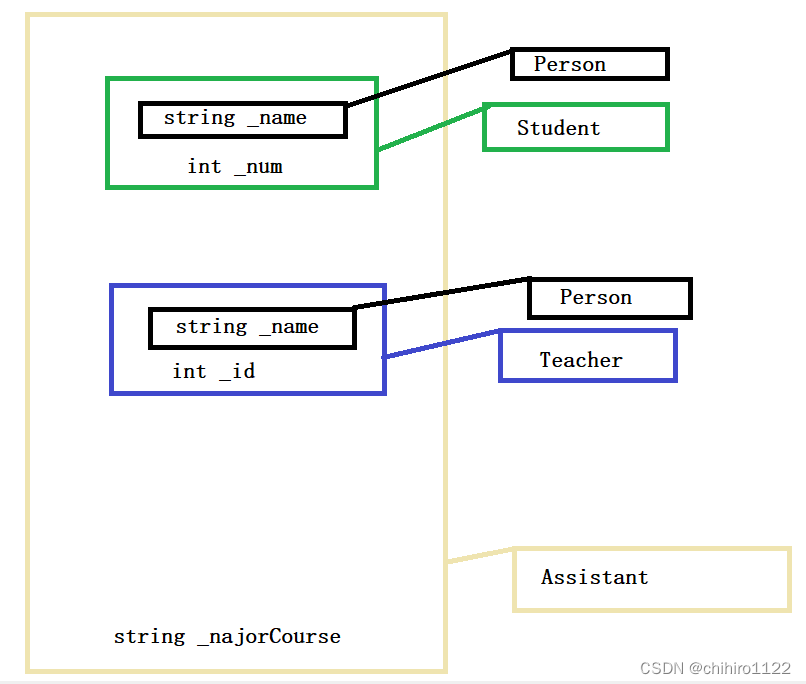
在一个 Assistant 类当中有了 两个 Person 当中的 _name 这个属性,但是不是每一个人都有多个名字,一般一个人经常使用的只有一个名字;此时这种情况就是数据冗余和二义性。
就算你认为一个人可以在不同场景下有两个名字,比如当学生的时候,老师叫你小郑,当老师的时候学生叫你郑老师;其实只是这里的例子太偶然,如果 Person 当中不止一个数据呢?
比如还有 _id 这个成员来表示你的身份证号码,一个人不会有两个身份证号码。
对于上述的 数据冗余 和 二义性所带来的坑是:
- 数据冗余:对于存储空间有一定会的浪费。
- 二义性:在访问的时候不知道要访问哪一个成员。
上述例子,如果直接使用 Assistant 的对象来访问 _name ,就会报错,编译器不知道要访问那一个 _name 。如下代码所示:
void Test ()
{
// 这样会有二义性无法明确知道访问的是哪一个
Assistant a ;
a._name = "peter";
}手动解决二义性(可以显示制定域来访问某一个 _name ,但是 数据同于问题无法解决):
// 需要显示指定访问哪个父类的成员可以解决二义性问题,但是数据冗余问题无法解决
a.Student::_name = "xxx";
a.Teacher::_name = "yyy";只要使用多继承,就有可能会发生菱形继承,因为只要继承了上一个父类,上一个父类的继承关系就会衍生到这一个子类当中。
而对于单继承就不会出现多次继承某一个父亲的情况:
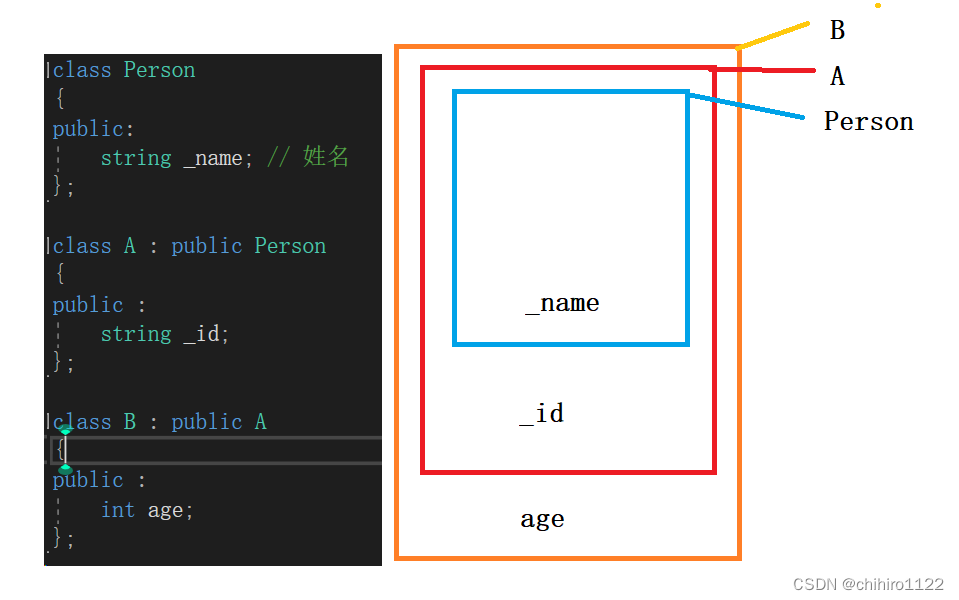
当B对象被构造的时候,会先去构造 B 的父类 A,在构造 A 的时候,又会先构造 Person。所以在B当中是没有两个 Person对象的,Person对象只是在 构造A的时候被构造了一次。
虚继承
C++为了解决 上述菱形继承所带来啊的二义性的问题,增加了一个功能——虚继承。
语法:
在出现菱形继承的“腰部”,使用 virtual 来修饰继承的父类,修饰位置如下所示:

代码:
class Person
{
public :
string _name ; // 姓名
};
// virtual 修饰
class Student : virtual public Person
{
protected :
int _num ; //学号
};
// virtual 修饰
class Teacher : virtual public Person
{
protected :
int _id ; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected :
string _majorCourse ; // 主修课程
};虚继承的原理
菱形继承的存储结构
理解原理之前,我们先来搞清楚菱形继承当中的对象模型,所谓对象模型就是这个对象在内存当中存储的结构。
有下面这个例子:
class A
{
public:
int _a;
};
// class B : public A
class B : public A
{
public:
int _b;
};
// class C : public A
class C : public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
return 0;
}这个例子中当中 A B C D 四个类的继承关系如下图所示:
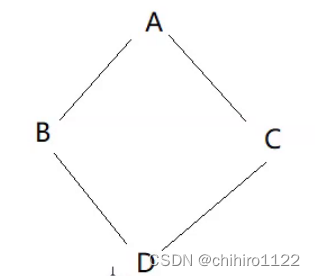
上述例子创建了 一个 D类的对象d,然后把d当中的 B类对象和C类对象当中各自的A类对象中的 _a 成员变量进行了修改,然后再把d当中存储 B类对象当中 _b 成员 和 C 类对象中的 _c 成员修改。最后在对d本身的对象进行修改。
我们在在调试当中查看内存,如下所示:
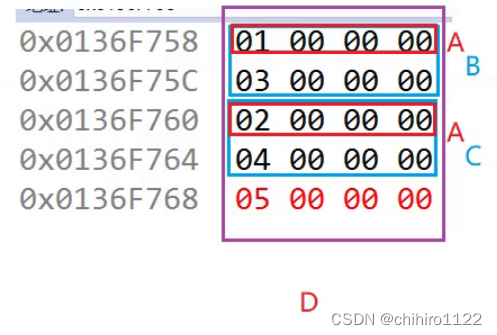
看似菱形继承关系很复杂,其实在内存当中的存储结构就是依次顺序存储。
菱形虚拟继承的存储结构
class A
{
public:
int _a;
};
// class B : public A
class B : virtual public A
{
public:
int _b;
};
// class C : public A
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
d._a = 0; // 不显示指定域,直接就修改
return 0;
}还是上述的例子,但是我们在菱形继承的腰部位置加上了 virtual 修饰(虚拟继承)。
内存中存储如下图所示:

我们发现,菱形继承和菱形虚拟继承不同点在于:对于 A 类(共同继承的父类)的存储空间不在是 B 和 C 当中都有一个了,而是 B C D 三者共用一个 A对象当中的成员。
菱形继承的存储结构 和 菱形虚拟继承的存储结构 两者的不同
在使用 virtual 修饰之后(虚拟继承),共同继承的父类不再是分开存储,而是只存储一个,而派生出的子类(或者是派生类派生出的子类)都共用一个 父类对象。从而,不管是在上述哪一个类当中,修改父类对象当中成员,修改的都是一个对象当中的成员。
而且,不仅仅是这样,我们发现,虚拟继承 比 继承 还多存储了一些东西:

我们调用内存窗口,查看这两个地址位置存储了什么(如下两图所示):

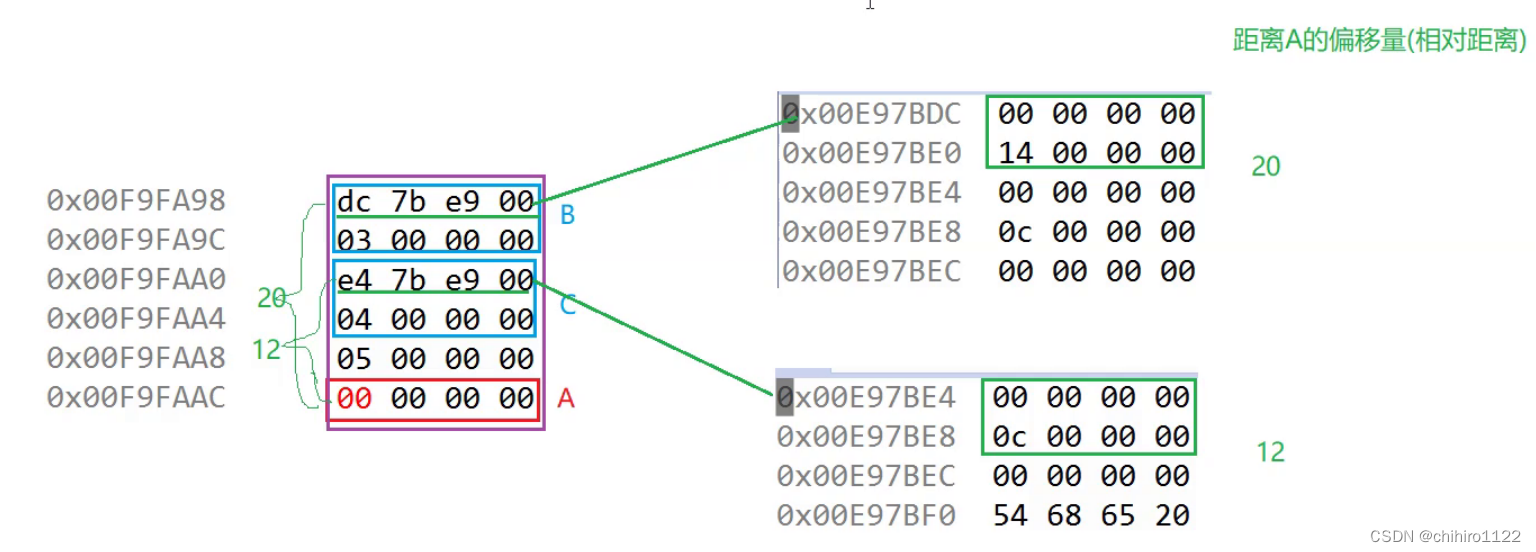
在两个地址位置处,存储的都是0,但是在两地址的下一地址处,存储了一些值;第一个是 14,转换为二进制就是 20;第二个是 0c 转化为二进制就是 12;
这里的 20 和 12 代表的就是 在上图 左侧内存块当中,两个多出来的存储地址,距离 A 对象存储地址位置的相对距离(偏移量);这里可以理解为指向 那 两个多出来的存储地址 的两个指针。
这里之所以使用偏移量这种方式,来代替指针是因为,对于上述例子 D 类的对象可能不会只有一个,虽然可能 不同的 D类对象 当中存储的值不会相同,但是 其中 B类对象 和 C类对象当中对于上述多出的两个地址位置,和D类对象其中的 A类对象 地址位置的偏移量是相同的,所以不需要每创建一次 D类对象,就要把 其中的A类对象的地址保存;只需要使用偏移量来计算出 A类对象的存储位置即可。也就是说所谓的 一表多用。
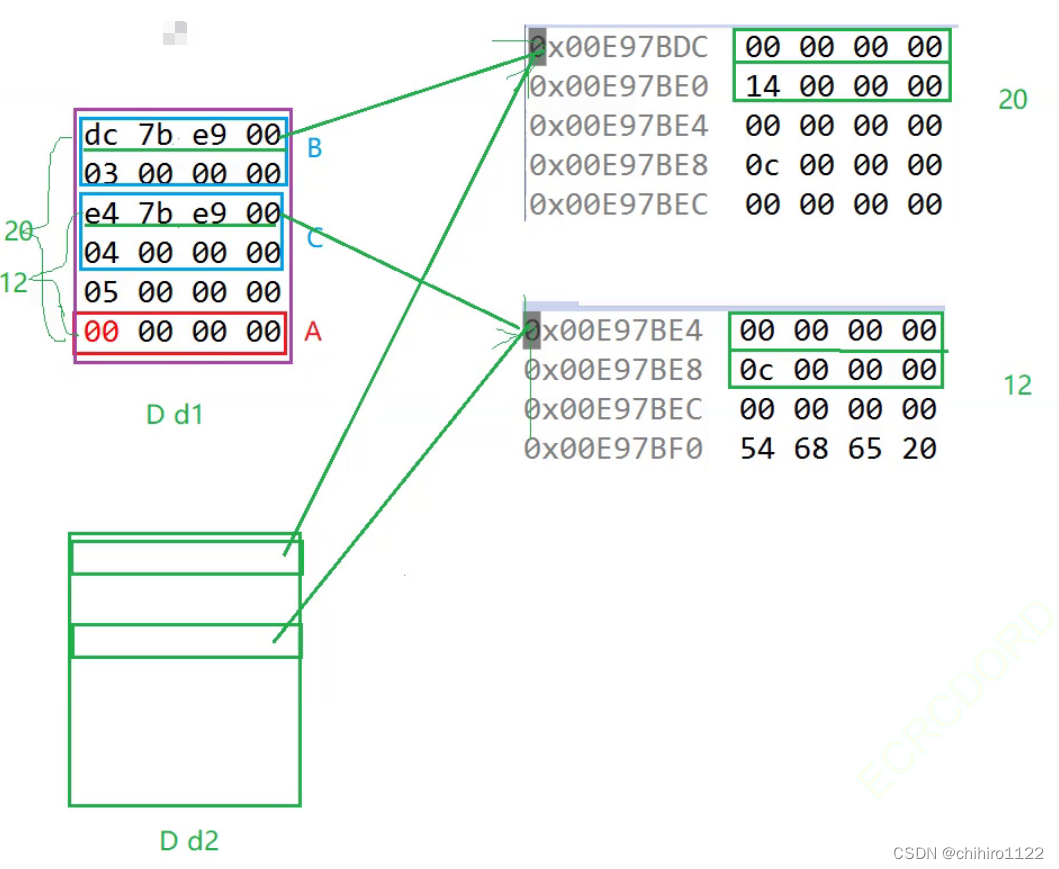
如上图所示,创建了 d1 对象 和 d2 对象都可以使用 右边已经计算好的偏移量表(内存块)。
这里使用 虚基表(存找基类偏移量的表) 的 方式来解决 每创建一个对象都需要 存储 一次 A类对象 地址的问题。
偏移量存储的意义
还是上述的 菱形继承的结构,对于 d1._a 是不需要用偏移量去寻找 A类对象当中的 _a 成员的,因为 在 D类对象当中,所有的 D类成员 和 继承的所以 A B C 三个类的成员,都是有自己的声明定义顺序的(之前也描述过),编译器找 基类 (A类)的 _a 尘缘不需要利用偏移量,编译器知道 虚拟继承后,A类对象就存储在 D类对象空间的最后。
那么既然用不到,那为什么要定义偏移量呢?
其实上述只是一个普通场景,一些特殊场景下会用到,比如下面这个例子:
D d1;
B* pb = &d1;
pb->_a = 0;这里的 pb 是一个B类型的指针,所以,就算pb直线的是 d1 对象的开头,他去数据也只能取到 一个 B类对象 大小的数据,而 存储 _a 的A类对象 是在 d1 对象的末尾,直接取肯定取不到 _a 的。这时候,就可以用偏移量来找到 A类对象的位置。
向上述的 pb 其实发生了 切片,本来 B类对象 数在 d1 这个对象里面的,但是要我指针类型是 B* ,用 pb 访问数据的话,不能把 d1 对象的所以数据都访问完,只能访问到从 d1对象起始位置开头的 B类对象大小的数据,那么其余下面的数据就被切片了。
也正是有了偏移量的存在,在上述这种情况(切片)发生的时候,就不用因为找不到 A类,来进行特殊处理(如果存储的A类地址的话),使用偏移量,在 pb->_a 访问 _a 的时候,只需要按照地址找到 虚基表,计算偏移量就行。
再如下例子感受:
D d;
d->_a = 1;
B b;
b->_a = 2;
B* ptr = &b;
ptr->_a++;
ptr = &d;
ptr->_a++;因为 B类 也是被 virtual 修饰的,所以在 B类 当中的对象模型,和之前的 d1 对象模型是一样的,都是共用一个 A类。
但是,我们知道 b 对象 和 d 对象 两个对象当中存储的 A类对象都是在其对象的 末尾处,但是对于 ptr = &d 上述说过是要发生切片的,此时的 ptr 指针还是只能访问 B类对象大小的数据,而A类数据不在其中。ptr指针 不能分辨 它此时 指向的对象是 b 还是 d,也就是说上述的两种情况 ptr 是分辨的,所以都是使用的 偏移量计算 来得出 A类对象的存储地址,而不是直接从指向对象的末尾处找(如下图所示):
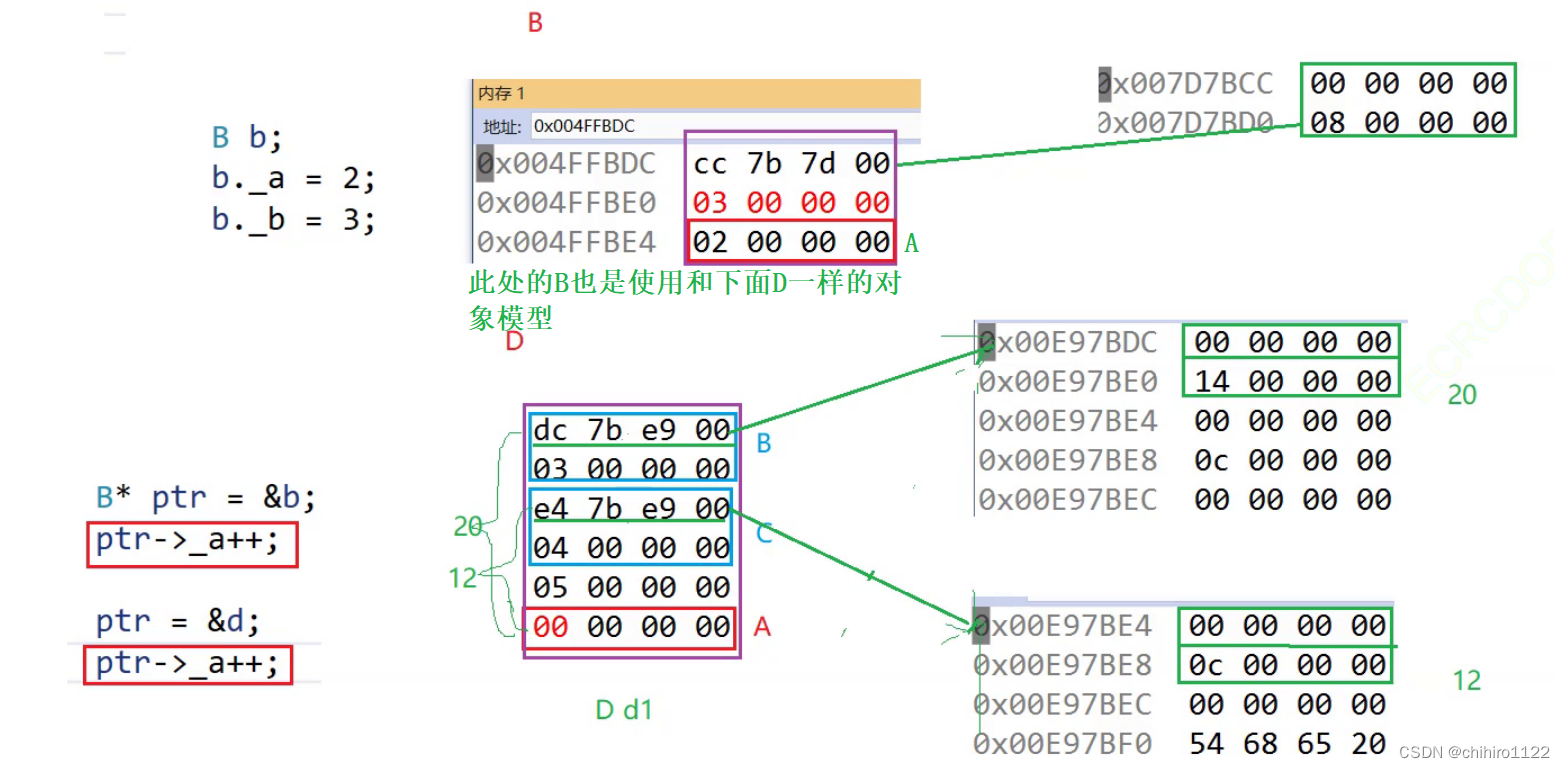
上两处的 ptr->_a++;使用的编译语法都是一样的,都是取 偏移量,计算出 A类对象的地址,然后再对 _a 进行操作。