锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

任何原始格式的数据载入DataFrame后,都可以使用类似 DataFrame.to_csv()的方法输出到相应格式的文件或者目标系统里。
支持导出的格式比较多,常用的有csv,excel,sql,html等。

导出CSV文件
导出csv文件我们使用to_csv()方法,pandas2提供了丰富的参数来实现强大的导出功能,我们看下to_csv()方法的参数:
def to_csv(
self,
path_or_buf: FilePath | WriteBuffer[bytes] | WriteBuffer[str] | None = None,
sep: str = ",",
na_rep: str = "",
float_format: str | Callable | None = None,
columns: Sequence[Hashable] | None = None,
header: bool_t | list[str] = True,
index: bool_t = True,
index_label: IndexLabel | None = None,
mode: str = "w",
encoding: str | None = None,
compression: CompressionOptions = "infer",
quoting: int | None = None,
quotechar: str = '"',
lineterminator: str | None = None,
chunksize: int | None = None,
date_format: str | None = None,
doublequote: bool_t = True,
escapechar: str | None = None,
decimal: str = ".",
errors: OpenFileErrors = "strict",
storage_options: StorageOptions | None = None,
)to_csv() 是 pandas 中用于将 DataFrame 导出为 CSV 文件的重要方法。以下是该方法的参数详解:
基本参数
-
path_or_buf (str, path object, file-like object, 默认为 None)
-
文件路径或文件对象
-
如果为 None,则返回 CSV 字符串
-
-
sep (str, 默认为 ',')
-
指定分隔符
-
例如:
sep='\t'表示制表符分隔
-
-
na_rep (str, 默认为 '')
-
缺失值表示方式
-
例如:
na_rep='NA'会将缺失值显示为 NA
-
-
float_format (str, 默认为 None)
-
浮点数格式字符串
-
例如:
float_format='%.2f'保留两位小数
-
-
columns (sequence, 可选)
-
指定要写入的列
-
例如:
columns=['col1', 'col3']
-
-
header (bool or list of str, 默认为 True)
-
是否写入列名
-
如果传入列表,则用作列名
-
-
index (bool, 默认为 True)
-
是否写入行索引
-
-
index_label (str or sequence, 默认为 None)
-
索引列的列名
-
如果传入列表且有多级索引,则为每级指定名称
-
编码与日期格式
-
encoding (str, 默认为 None)
-
编码方式
-
例如:
encoding='utf-8'或encoding='gbk'
-
-
date_format (str, 默认为 None)
-
日期格式字符串
-
例如:
date_format='%Y-%m-%d'
-
性能相关参数
-
mode (str, 默认为 'w')
-
Python 写入模式
-
'w' 表示写入,'a' 表示追加
-
-
compression (str or dict, 默认为 'infer')
-
压缩方式
-
可选: 'infer', 'gzip', 'bz2', 'zip', 'xz', None
-
-
quoting (int or csv.QUOTE_*, 默认为 csv.QUOTE_MINIMAL)
-
引用约定
-
选项:
-
csv.QUOTE_ALL (引用所有字段)
-
csv.QUOTE_MINIMAL (仅引用包含特殊字符的字段)
-
csv.QUOTE_NONNUMERIC (引用所有非数字字段)
-
csv.QUOTE_NONE (不引用)
-
-
-
quotechar (str, 默认为 '"')
-
用于引用的字符
-
-
line_terminator (str, 默认为 '\n')
-
行结束符
-
其他参数
-
chunksize (int, 默认为 None)
-
按指定行数分批写入
-
-
doublequote (bool, 默认为 True)
-
引用字段中的引号是否双写
-
-
escapechar (str, 默认为 None)
-
用于转义的字符
-
-
decimal (str, 默认为 '.')
-
小数点的字符表示
-
例如:
decimal=','用于欧洲格式
-
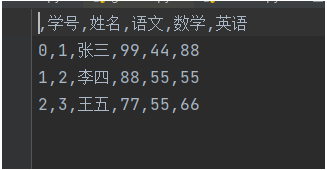
我们先看最简单的一个示例,用字典构造一个DataFrame对象,然后直接导出csv文件:
import pandas as pd
d = {'学号': [1, 2, 3],
'姓名': ['张三', '李四', '王五'],
'语文': [99, 88, 77],
'数学': [44, 55, 55],
'英语': [88, 55, 66]}
df = pd.DataFrame(d)
print(df)
df.to_csv('out/student.csv')我们运行看下导出的csv文件:
默认是有含行索引的,如果不需要的话,我们加下index=False参数:
df.to_csv('out/student2.csv', index=False) # 不需要行索引运行导出的csv文件:

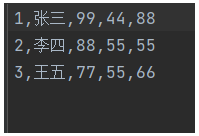
如果不需要表头,可以设置header=False
df.to_csv('out/student3.csv', index=False, header=False) # 不需要行索引,不要表头运行导出的csv文件:
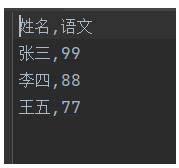
导出指定列数据,可以使用columns参数指定:
df.to_csv('out/student4.csv', index=False, columns=['姓名', '语文']) # 不需要行索引,不要表头运行导出的csv文件:
导出Excel文件
将DataFrame导出为Excel格式也很方便,使用DataFrame.to_excel方法即可。要想把DataFrame对象导出,首先要指定一个文件名,这个文件名必须以.xlsx或.xls为扩展名,生成的文件标签名也可以用sheet_name 指定。
to_excel()方法参数如下:
def to_excel(
self,
excel_writer: FilePath | WriteExcelBuffer | ExcelWriter,
sheet_name: str = "Sheet1",
na_rep: str = "",
float_format: str | None = None,
columns: Sequence[Hashable] | None = None,
header: Sequence[Hashable] | bool_t = True,
index: bool_t = True,
index_label: IndexLabel | None = None,
startrow: int = 0,
startcol: int = 0,
engine: Literal["openpyxl", "xlsxwriter"] | None = None,
merge_cells: bool_t = True,
inf_rep: str = "inf",
freeze_panes: tuple[int, int] | None = None,
storage_options: StorageOptions | None = None,
engine_kwargs: dict[str, Any] | None = None,
) 有个sheet_name标签名称参数,默认值是"Sheet1",其他参数使用和csv基本一致。
下面看一个示例:
import pandas as pd
d = {'学号': [1, 2, 3],
'姓名': ['张三', '李四', '王五'],
'语文': [99, 88, 77],
'数学': [44, 55, 55],
'英语': [88, 55, 66]}
df = pd.DataFrame(d)
df.to_excel('out/student.xlsx', sheet_name="我的标签页", index=False)导出的excel文件:

导出sql
将DataFrame中的数据保存到数据库的对应表中,pandas2提供了to_sql()方法,我们看下to_sql()方法的参数:
def to_sql(
self,
name: str,
con,
schema: str | None = None,
if_exists: Literal["fail", "replace", "append"] = "fail",
index: bool_t = True,
index_label: IndexLabel | None = None,
chunksize: int | None = None,
dtype: DtypeArg | None = None,
method: Literal["multi"] | Callable | None = None,
)to_sql() 是 pandas 中用于将 DataFrame 写入 SQL 数据库的方法,支持多种关系型数据库。以下是该方法的详细参数说明:
基本参数
-
name (str)
-
目标数据库表名
-
如果表已存在,行为取决于
if_exists参数
-
-
con (sqlalchemy.engine.Engine or sqlite3.Connection)
-
数据库连接对象
-
通常使用 SQLAlchemy 引擎创建
-
-
schema (str, 可选)
-
数据库 schema 名称
-
默认为 None,使用数据库默认 schema
-
-
if_exists (str, 默认为 'fail')
-
表已存在时的处理方式:
-
'fail': 抛出 ValueError (默认)
-
'replace': 删除原表后重建
-
'append': 向现有表追加数据
-
-
写入控制参数
-
index (bool, 默认为 True)
-
是否将 DataFrame 的索引作为单独列写入
-
-
index_label (str or sequence, 可选)
-
索引列的列名
-
如果有多级索引,可传入序列
-
-
chunksize (int, 可选)
-
分批写入的行数
-
大数据集时使用可减少内存消耗
-
-
dtype (dict, 可选)
-
指定列的数据类型
-
格式:
{'column_name': sqlalchemy.types.Type} -
例如:
{'price': sqlalchemy.types.Float}
-
类型推断与性能
-
method (str or callable, 可选)
-
控制 SQL 插入方式:
-
None: 标准 SQL INSERT 语句
-
'multi': 单语句多行插入
-
callable: 自定义插入函数
-
-
大数据量时 'multi' 可提高性能
-
-
keys (sequence, 可选)
-
当 method='multi' 时,指定要插入的列
-
其他参数
-
fail_on_extra_columns (bool, 默认为 False)
-
如果为 True,当 DataFrame 包含表中不存在的列时会失败
-
-
alter_schema (bool, 默认为 False)
-
如果为 True,尝试修改表结构以匹配 DataFrame
-
下面是一个导出sql示例:
import pandas as pd
from sqlalchemy import create_engine
d = {'学号': [1, 2, 3],
'姓名': ['张三', '李四', '王五'],
'语文': [99, 88, 77],
'数学': [44, 55, 55],
'英语': [88, 55, 66]}
df = pd.DataFrame(d)
# 创建数据库引擎
# 注意:替换下面的用户名、密码、主机名和数据库名
engine = create_engine('mysql+pymysql://root:123456@localhost:3308/db_xuanke')
df.to_sql('t_student', engine, index_label='id')
运行后,自动建表,以及自动插入数据: