前言:Hello大家好,我是小哥谈。PP-LCNet是一个由百度团队针对Intel-CPU端加速而设计的轻量高性能网络。它是一种基于MKLDNN加速策略的轻量级卷积神经网络,适用于多任务,并具有提高模型准确率的方法。与之前预测速度相近的模型相比,PP-LCNet具有更高的准确性。此外,对于计算机视觉的下游任务(如目标检测、语义分割等),该模型的效果也很好。 PP-LCNet还采用了H-Swish激活函数,这是一种优化的激活函数,可以提高性能而几乎不增加预测时间。🌈
 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
YOLOv5算法改进(7)— 添加SimAM注意力机制
YOLOv5算法改进(8)— 替换主干网络之MobileNetV3
YOLOv5算法改进(9)— 替换主干网络之ShuffleNetV2
YOLOv5算法改进(10)— 替换主干网络之GhostNet
YOLOv5算法改进(11)— 替换主干网络之EfficientNetv2
YOLOv5算法改进(12)— 替换主干网络之Swin Transformer
目录
🚀1.论文
🚀2.PP-LCNet网络架构及原理
🚀3.YOLOv5结合PP-LCNet
💥💥步骤1:在common.py中添加PP-LCNet模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
PP-LCNet是百度团队结合Intel-CPU端侧推理特性而设计的轻量高性能网络,所提方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet更优的延迟-精度均衡。论文提出了一种基于MKLDNN加速的轻量CPU模型PP-LCNet,它在多个任务上改善了轻量型模型的性能。🍃
如下图所示,在图像分类任务方面,所提PP-LCNet在推理延迟-精度均衡方面大幅优于ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet。✅


论文试验结果:
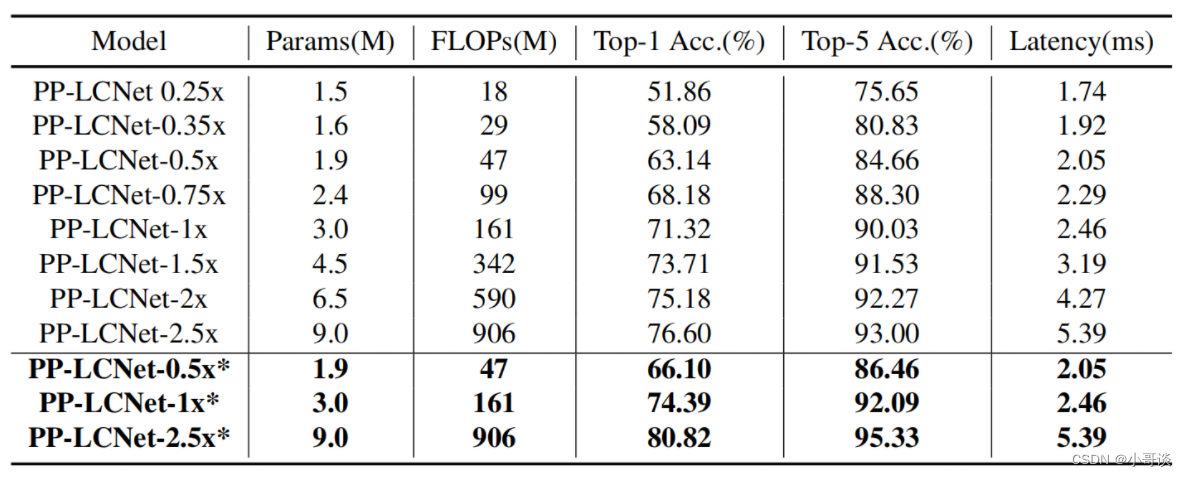
不同尺度的PP-LCNet在ImageNet上的精度和延迟如下表所示:
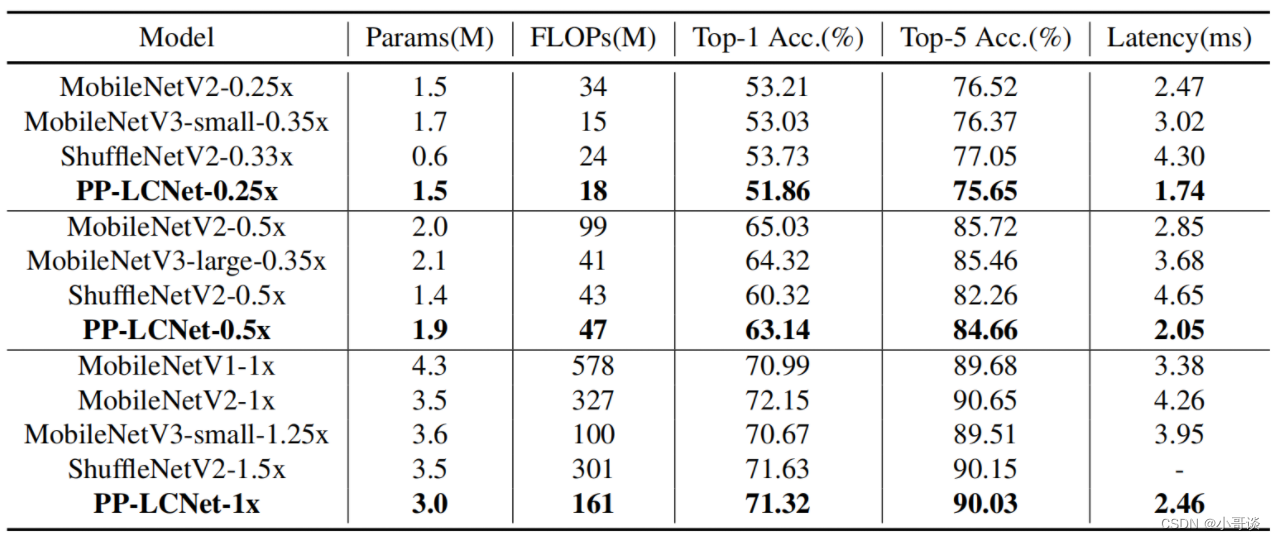
和其它轻量模型的对比如下表所示:
说明:♨️♨️♨️
本文提出一个能够在 CPU 上训练的深度学习网络模型,文章和算法都很简单,很容易复现。✅
文章总结起来就 4 点:
📚(1)使用 H-Swish (替代传统的 ReLU);
📚(2)SE 模块放在最后一层,并使用大尺度卷积核;
📚(3)大尺度卷积核放在最后几层;
📚(4)在最后的 global average pooling 后增加更大尺寸的 1 × 1 卷积层。
论文题目:《PP-LCNet: A Lightweight CPU Convolutional Neural Network》
论文地址: https://arxiv.org/abs/2109.15099
代码实现: GitHub - ngnquan/PP-LCNet: PyTorch implementation of PP-LCNet
🚀2.PP-LCNet网络架构及原理
PP-LCNet网络结构整体如下图所示:
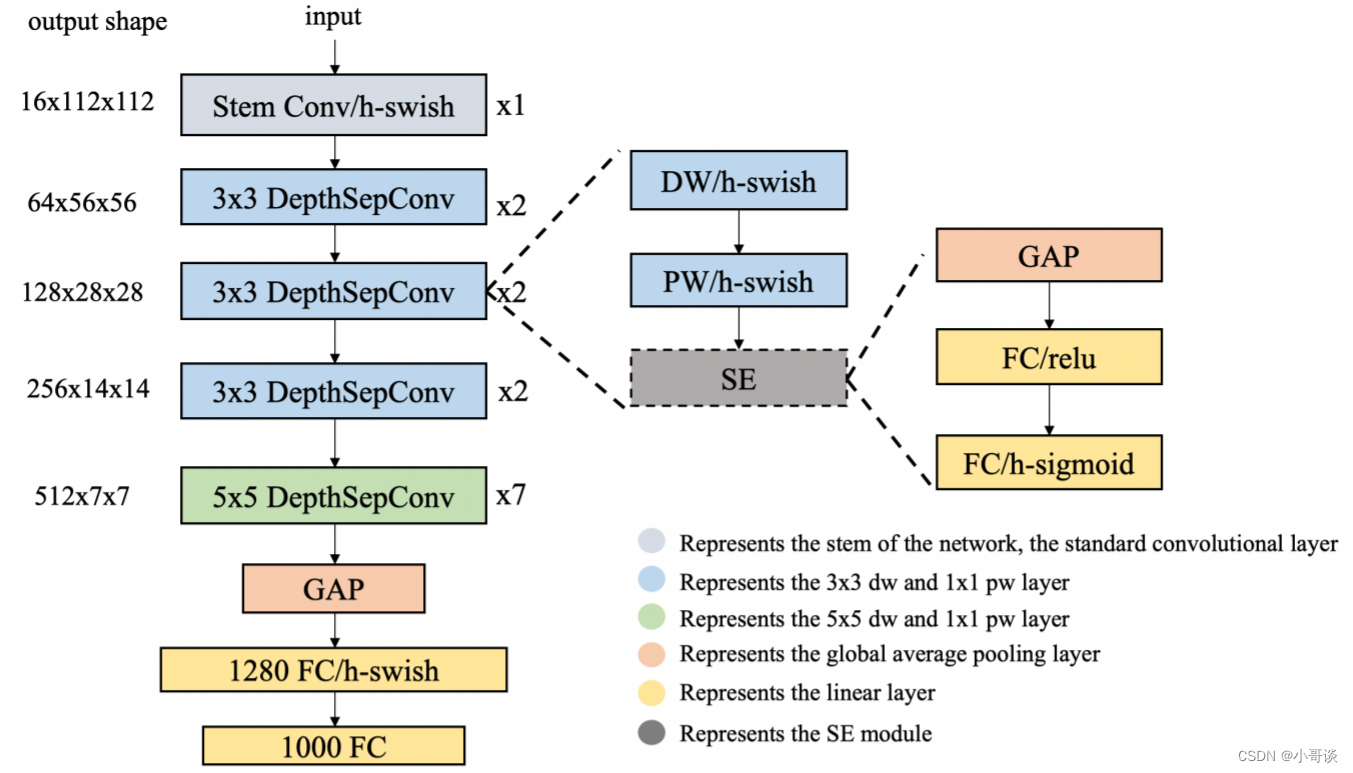
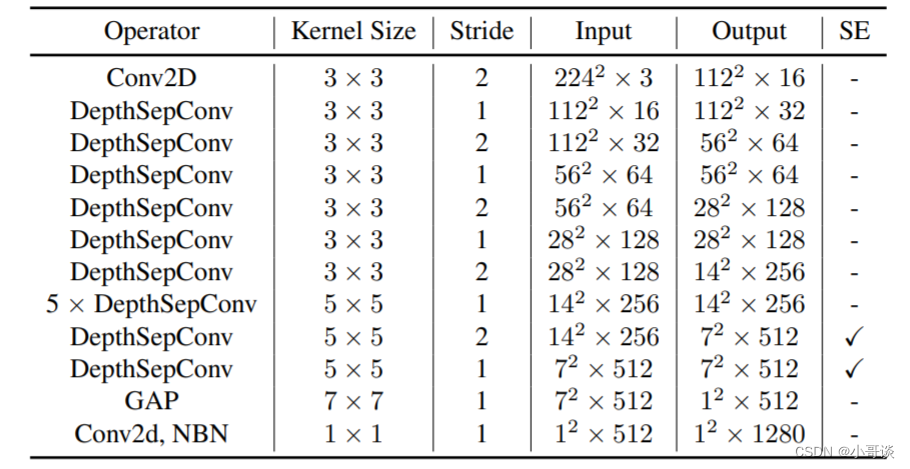
🍀(1)模块
使用了类似 MobileNetV1 中的深度可分离卷积作为基础,通过堆叠模块构建了一个类似 MobileNetV1 的BaseNet,然后组合BaseNet与某些现有技术构建了一种更强力网络PP-LCNet。
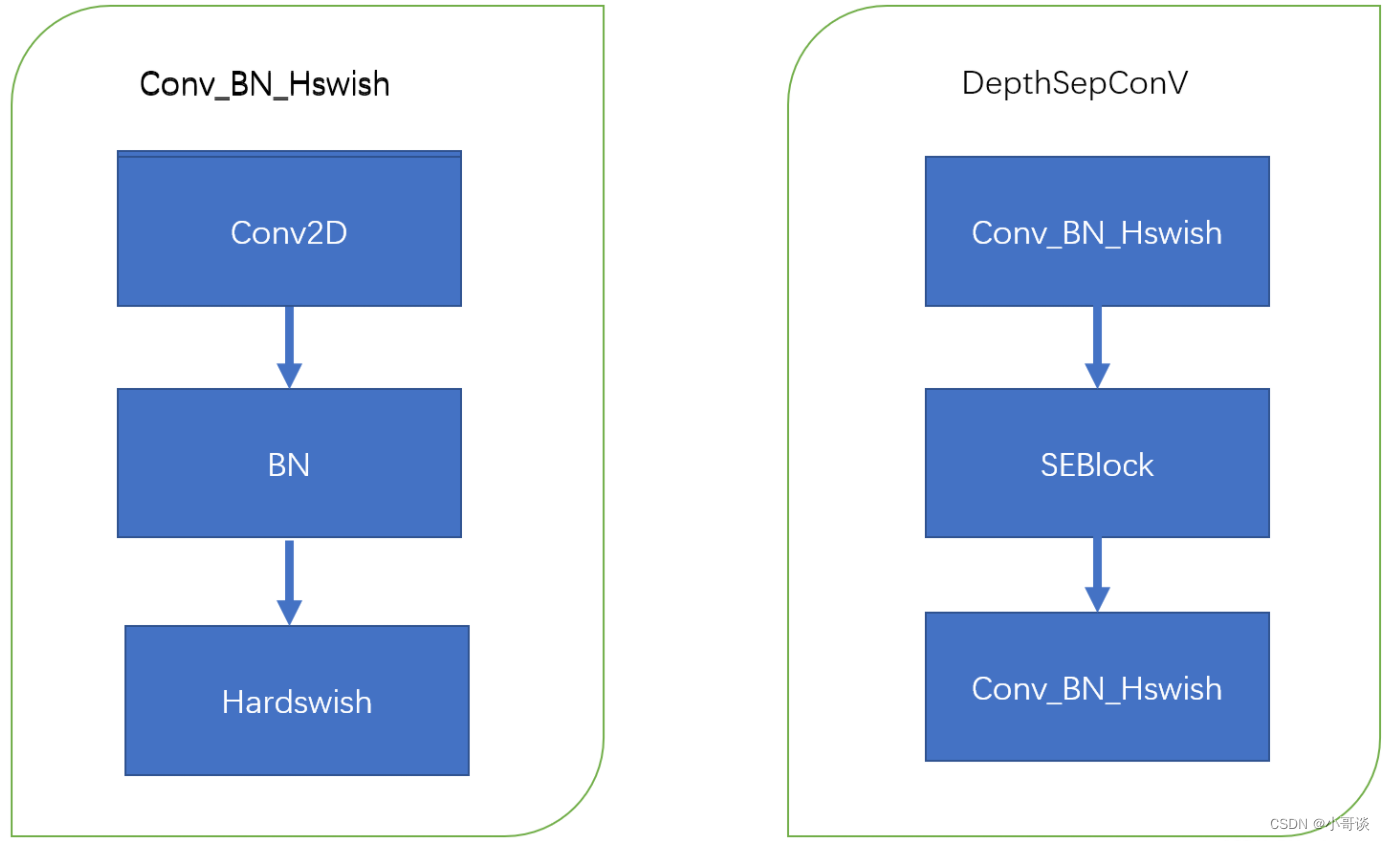
结构图如下,左图是卷积+标准化+激活函数,右图是PP-LCNet中的基础模块,源代码中是先卷积+SE模块+卷积。👇
🍀(2)激活函数的使用
自从卷积神经网络使用了 ReLU 激活函数后,网络性能得到了大幅度的提升,近些年 ReLU 激活函数的变体也相继出现,如 Leaky-ReLU、P-ReLU、ELU 等。2017 年,谷歌大脑团队通过搜索的方式得到了 swish 激活函数,该激活函数在轻量级网络上表现优异,在 2019 年,MobileNetV3 的作者将该激活函数进一步优化为 H-Swish,该激活函数去除了指数运算、速度更快、网络精度几乎不受影响,也经过很多实验发现该激活函数在轻量级网络上有优异的表现。所以在 PP-LCNet 中,选用了该激活函数。🌱


🍀(3)SE 模块
SE模块使用了激活函数ReLU和H-sigmoid。
🍀(4)合适的位置添加更大的卷积核
通过实验总结了一些更大的卷积核在不同位置的作用,类似 SE 模块的位置,更大的卷积核在网络的中后部作用更明显,所以在网络的后部会使用很多5x5的卷积核。
🍀(5)GAP 后使用更大的 1x1 卷积层
在 GoogLeNet 之后,GAP(Global-Average-Pooling)后往往直接接分类层,但是在轻量级网络中,这样会导致 GAP 后提取的特征没有得到进一步的融合和加工。如果在此后使用一个更大的 1x1 卷积层(等同于 FC 层),GAP 后的特征便不会直接经过分类层,而是先进行了融合,并将融合的特征进行分类。这样可以在不影响模型推理速度的同时大大提升准确率。
🚀3.YOLOv5结合PP-LCNet
💥💥步骤1:在common.py中添加PP-LCNet模块
将下面PP-LCNet模块的代码复制粘贴到common.py文件的末尾。
class SeBlock(nn.Module):
def __init__(self, in_channel, reduction=4):
super().__init__()
self.Squeeze = nn.AdaptiveAvgPool2d(1)
self.Excitation = nn.Sequential()
self.Excitation.add_module('FC1', nn.Conv2d(in_channel, in_channel // reduction, kernel_size=1)) # 1*1卷积与此效果相同
self.Excitation.add_module('ReLU', nn.ReLU())
self.Excitation.add_module('FC2', nn.Conv2d(in_channel // reduction, in_channel, kernel_size=1))
self.Excitation.add_module('Sigmoid', nn.Sigmoid())
def forward(self, x):
y = self.Squeeze(x)
ouput = self.Excitation(y)
return x * (ouput.expand_as(x))
class DepthSepConv(nn.Module):
def __init__(self, inp, oup, dw_size, stride, use_se):
super(DepthSepConv, self).__init__()
self.stride = stride
self.inp = inp
self.oup = oup
self.dw_size = dw_size
self.dw_sp = nn.Sequential(
nn.Conv2d(self.inp, self.inp, kernel_size=self.dw_size, stride=self.stride, padding=(dw_size - 1) // 2, groups=self.inp, bias=False),
nn.BatchNorm2d(self.inp),
nn.Hardswish(),
SeBlock(self.inp, reduction=16) if use_se else nn.Sequential(),
nn.Conv2d(self.inp, self.oup, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(self.oup),
nn.Hardswish())
def forward(self, x):
y = self.dw_sp(x)
return y
💥💥步骤2:在yolo.py文件中加入类名
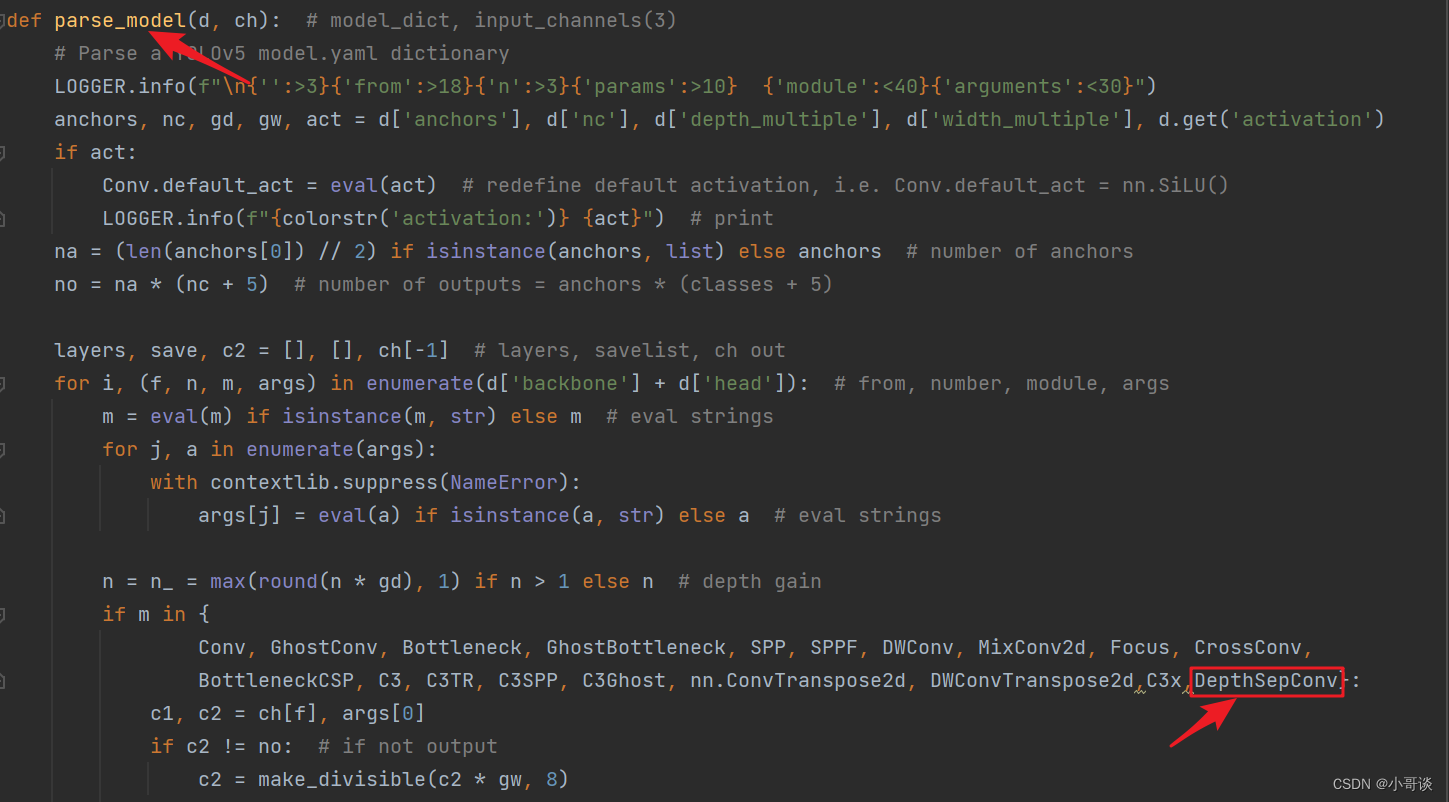
首先在yolo.py文件中找到 parse_model函数这一行,加入DepthSepConv。
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并重命名为yolov5s_PPLCNet.yaml。
然后根据PP-LCNet的网络架构来修改配置文件。

yaml文件修改后的完整代码如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# PP-LCNet backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [16, 3, 2, 1]], # 0-P1/2 ch_out, kernel, stride, padding
[-1, 1, DepthSepConv, [32, 3, 1, False]], # 1
[-1, 1, DepthSepConv, [64, 3, 2, False]], # 2-P2/4
[-1, 1, DepthSepConv, [64, 3, 1, False]], # 3
[-1, 1, DepthSepConv, [128, 3, 2, False]], # 4-P3/8
[-1, 1, DepthSepConv, [128, 3, 1, False]], # 5
[-1, 1, DepthSepConv, [256, 3, 2, False]], # 6-P4/16
[-1, 5, DepthSepConv, [256, 5, 1, False]], # 7
[-1, 1, DepthSepConv, [512, 5, 2, True]], # 8-P5/32
[-1, 1, DepthSepConv, [512, 5, 1, True]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [256, False]], # 13
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [128, False]], # 17 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [256, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [512, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
💥💥步骤4:验证是否加入成功
在yolo.py文件里,配置我们刚才自定义的yolov5s_PPLCNet.yaml。

然后运行yolo.py,得到结果。
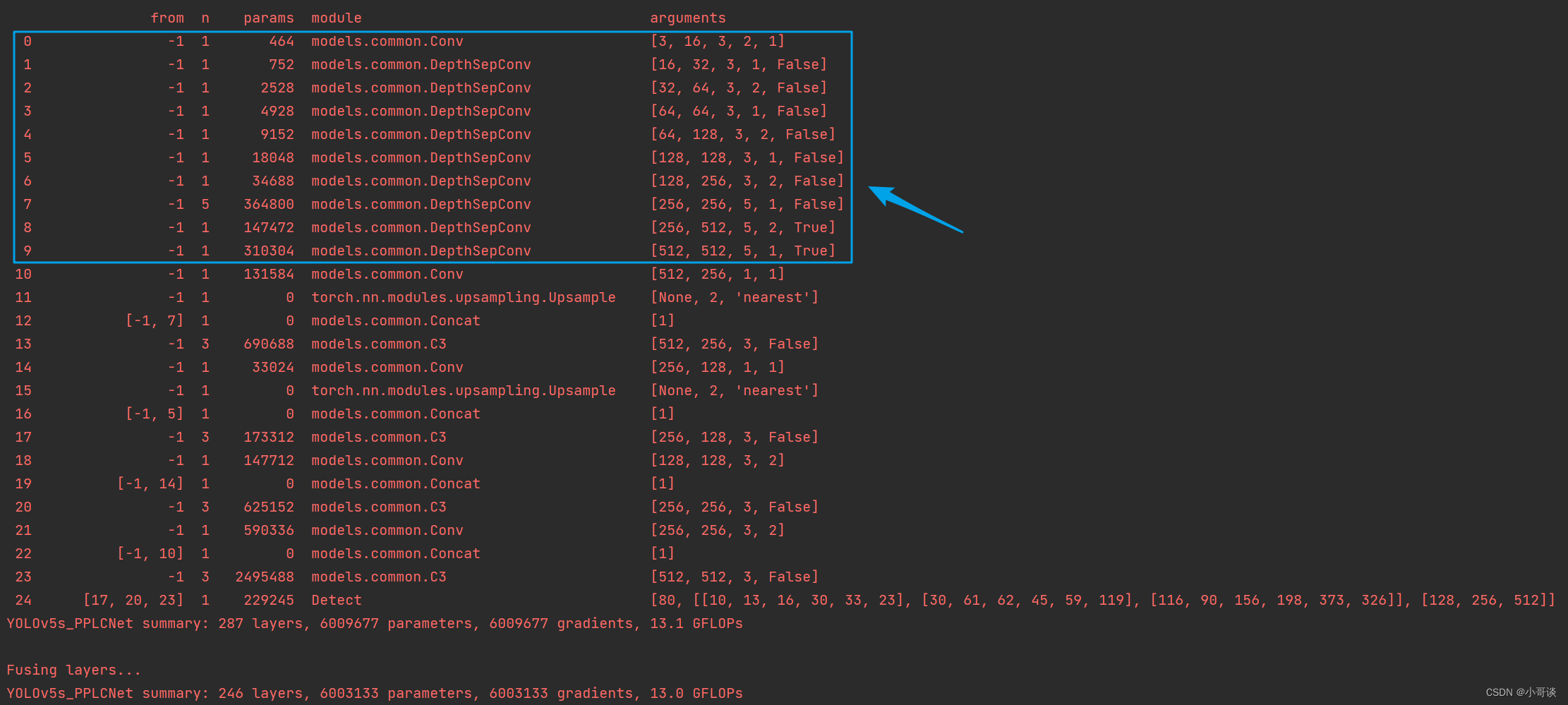
这样就算添加成功了。🎉🎉🎉
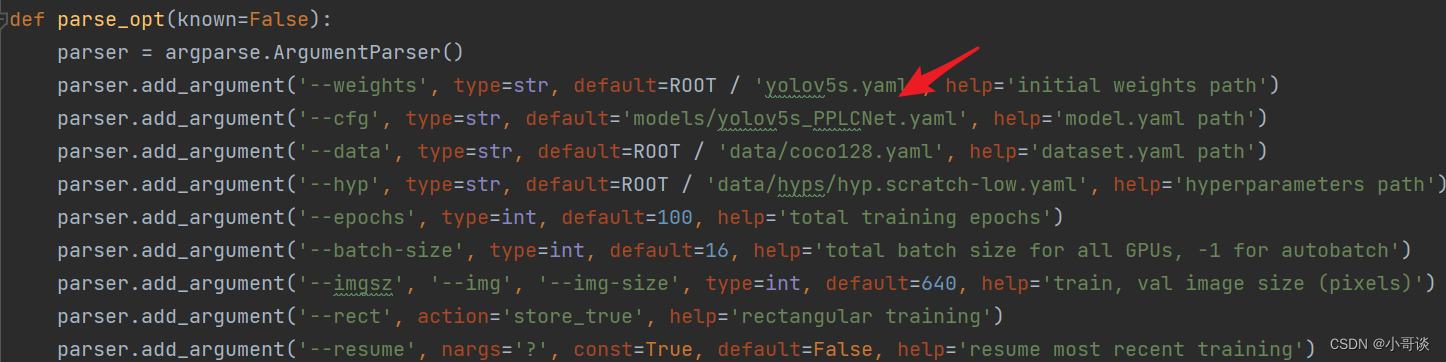
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行 '--cfg' 的default改为 'models/yolov5s_PPLCNet.yaml ',然后就可以开始进行训练了。🎈🎈🎈