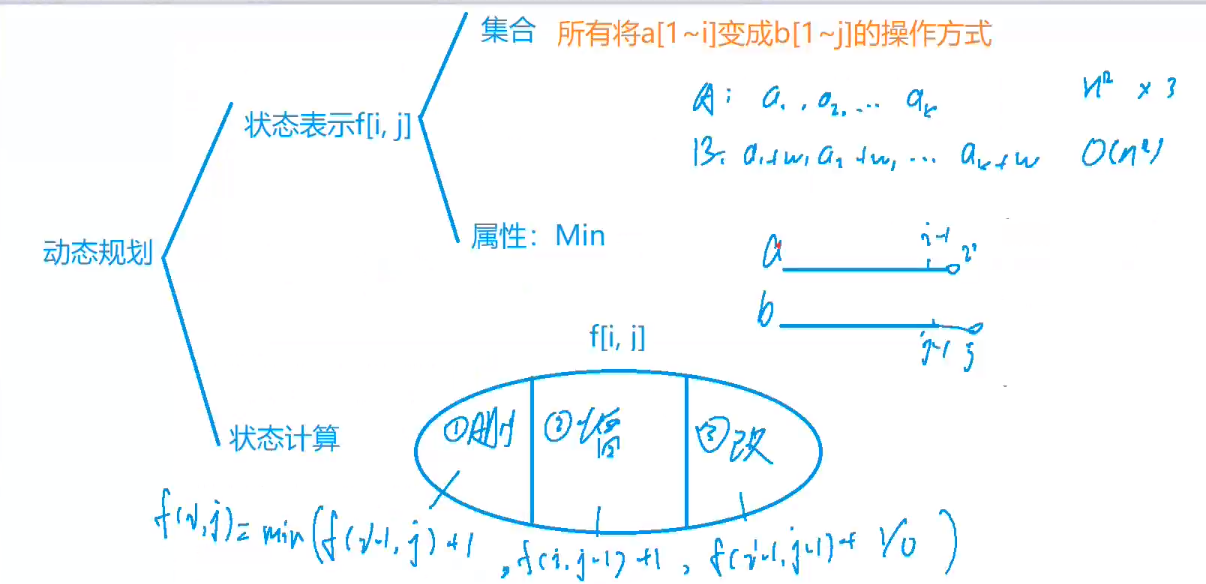
一、半监督学习的总体框架

二、一致性正则化模型
该算法旨在:一个模型对于同一个未标记图像,在图像添加额外噪声前后的预测值应该保持一致。
添加噪声的方法,如图像增强(空间维度增强、像素维度增强)。
同样,Dropout可在模型结构中引入噪声。

1、Π模型
论文链接:TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
- 将一幅图像进行两种不同尺度的数据增强变换(主要是增加噪声信息)。
- 将不同噪声增强后的两幅图像先后次序输入到同一个带有Dropout模型中(进行了两次前向运算)。
- 判断两幅噪声增强图像的特征提取结果分布的一致性差异(如使用KL散度等方法),如果原始图像存在label数据,则还判断与真实label的交叉熵信息损失。
- 将分布一致性差异损失和交叉熵信息损失进行加权求和,得到最终的loss,然后进行梯度反传。

模型缺点:每个输入需要进行两次前向传播来计算一致性损失,效率可能比较低。
2、Temporal ensembling模型
论文链接:TEMPORAL ENSEMBLING FOR SEMI-SUPERVISED LEARNING
该算法在训练中产生一个用于比较的标准值 ,每次的模型的输出都和该标准值进行分布一致性差异比较。
- 将一张图像进行加噪增强。
- 将加噪后的图像输入到模型中(仅进行一次前向运算)。
- 将模型的提取结果同生成的标准值进行分布一致性比较,如果原图像存在label,则还计算与label的交叉熵信息差异。
- 将分布一致性差异损失和交叉熵信息损失进行加权求和,得到最终的loss,然后进行梯度反传。
注:其中标准值每次前向传播中不是固定的,而是通过指数移动平均法(EMA)算法计算求得(利用之前epoch的结果计算求所得),关于EMA算法,公式如下。


模型缺点:
- 由于每个目标在每个epoch中只更新一次,因此学习到的信息以较慢的速度被纳入训练过程。
- 数据集越大,更新的时间跨度就越长,在在线学习的情况下,尚不清楚如何使用时态模型。
3、Mean teacher模型
论文链接:Mean teachers are better role models:Weight-averaged consistency targets improve semi-supervised deep learning results
该算法中教师模型不同学生模型一样,并不是每个step都进行权重更新,而是将学生模型连续训练若干step后产生的权重平均值作为更新权重。教师模型使用学生模型的EMA权重,而不是与学生模型共享权重。论文中表示平均模型权重往往会产生一个比直接使用最终权重更精确的模型。它可以在每一个step完成后即刻聚合之前学习到的所有信息,而不仅仅在每一个epoch。此外,由于EMA提高了所有层的输出质量,而不仅仅是最后一层的输出,因此模型能够更好地表征中层乃至高层语义信息。这些方面早就了该模型相对于Temporal ensemble的两个优势。首先,更准确的标签使学生和教师模型之间发生更快的反馈循环,从而产生更好的精度。其次,这种方法适用于大型数据集和在线学习。
- 对数据进行两种不同的加噪。
- 将不同噪声增强后的两幅图像分别输入到学生模型的和教师模型。
- 对输出使用softmax激活,计算学生模型输出与教师模型输出的一致性损失函数, 人如果原图像存在label,则还与label计算交叉熵信息损失。
- 用梯度下降法更新学生模型的权重,教师模型的权重用学生权重的指数移动平均法(EMA)更新(一部分权重来自历史的教师模型权重,另一部分来自于当前步学生模型的权重):


模型缺点:
- 教师模型的选择对模型性能至关重要。选择一个不合适的教师模型可能会导致性能下降。因此,需要进行一些实验来确定最佳的教师模型。
- Mean Teacher 模型仍然需要一些有标签的数据来进行监督训练,尤其是在初期阶段。这意味着它不适用于完全无监督的情况。
- Mean Teacher 假设有标签和无标签的数据是从相同的数据分布中生成的。如果这个假设不成立,模型性能可能会受到影响。
- Mean Teacher 模型对数据中的噪声和异常值比较敏感。这可能导致模型在存在异常数据的情况下性能下降。
4、UDA模型
论文链接:Unsupervised Data Augmentation for Consistency Training
UDA(Unsupervised Data Augmentation 无监督数据增强)是Google在2019年提出的半监督学习算法。该算法一改前几种算法的数据增强方式,对于有label数据不进行数据增强,对于无label数据进行增强,并且针对不同不同类型的数据采用不同的增强方法,如图像分类任务使用随机自动增强,文本分类任务使用back translation(将文本翻译成其他语言,再翻译回英文)、TF-IDF(单词替换)。
- 将有label的图像输入到模型中得到预测结果,与label比较计算获得交叉熵信息损失。
- 将无标签图像进行两种不同增强,先后输入模型种,比较两结果的KL散度损失。
- 将KL散度损失和交叉熵信息损失进行加权相加,然后进行后向传播。

模型缺点:
- UDA通常需要大量的无标签数据,以便进行数据增强和自监督学习训练。如果没有足够的无标签数据,模型可能无法充分受益于UDA,这限制了其适用性。
- UDA的性能高度依赖于自监督学习任务的设计。选择不合适的自监督任务可能会导致性能下降。因此,需要仔细选择自监督任务和相应的数据增强策略。
- UDA的性能可能在不同的领域和任务之间差异很大。一个在一个领域表现良好的UDA模型可能不适用于另一个领域。这意味着UDA可能需要在不同任务和领域上进行调整和重新训练。
- UDA侧重于提高无标签数据的性能,但在实际应用中,有时标签数据的质量和数量仍然是关键因素。如果标签数据不足或不准确,UDA可能无法充分弥补这些问题。
三、伪标签模型
该算法旨在:先使用有标签的数据来训练模型,然后利用该模型去预测无标签数据,将置信度高的预测结果作为伪标签,参与模型训练调整。模型同时在真实标签和伪标签数据上进行训练。

1、self-training
论文链接:Effective Self-Training for Parsing
self-training主要思想是利用已有label数据训练一个模型,然后利用其预测无label数据,将置信度高的预测结果作为训练集,加入训练。
- 使用有label数据训练一个任务模型。
- 使用该模型对无label数据进行预测。
- 选取置信度高于某个阈值的预测结果作为对应无label数据的伪label。
- 将伪样本对加入到原始训练集中,并在无label数据集中删除,直到没有了更多可选的伪样本为止(就是直到不再有高于阈值的预测结果,数据集不再变动)。
- 重复以上步骤。

2、co-training
论文链接:Combining labeled and unlabeled data with co-training
co-training训练是一种多视图的半监督算法,主要思想是利用两个模型相互为对方打标签,将对方预测结果中置信度高而自己置信度低的结果作为自己的伪样本。
- 将有label数据分为两个部分,并分别训练两个模型。
- 使用两个模型对同一无label数据进行预测。
- 如果模型1的预测结果高于设定的置信度阈值,而模型2低于阈值,则利用模型1 的预测结果作为模型的伪样本,加入到模型2的训练集中,并在无label数据集中删除对应数据。反之亦然。直到数据集不再变动,任一模型预测结果都不再高于阈值。
- 重复以上步骤。

3、Tri-Training
论文链接:Tri-training: exploiting unlabeled data using three classifiers
Tri-traing 是对 co-training的进一步调整,它也是一种基于分歧的多视图方法。
- 利用bootstrap方法(有放回的随机采样)从有label数据集里选取三个子数据集。利用三个子数据集分别训练三个不同的基模型1,2,3。
- 对于模型1,使用模型2和3来预测所有无label数据集,假设模型2和3的预测结果一致,则将该预测结果作为模型1 的伪label,加入到模型1对应的数据集中,并在无label数据集中删除对应数据。直到模型2和3的所有余下无label数据的预测结果都不一致,数据集不再变动为止。
- 为三个模型分别执行步骤2,并利用三个扩增后的数据集重新训练模型。
- 重复执行2,3,直到模型收敛。
注:在为无label数据贴上伪标签时,可能贴错标签,即在数据集中增加噪声的。但当新增加的数据足够多时,噪声带来的影响是可以被抵消的。

4、Curriculum Labeling
论文链接:Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning
Curriculum Labeling的主要思想是模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。
假设模型预测的伪标签的置信度遵循帕累托分布。相比于固定置信度阈值,该算法在每个迭代轮次将全部标签按置信度排列后,按Percentile进行选取,Percentile随着轮次迭代而逐渐增大,从20%–>100%,到全部伪标签投入训练后即停止训练。
相比于每个训练迭代轮次微调模型,该算法直接在每轮迭代轮次中初始化参数(re-start),这样也有助于避免早期训练的过程中,错误标签累计误导训练,导致概念偏移(concept drift)。

四、整体模型(Holistic Model)
一致性正则化模型 和 伪标签模型 的整合。
1、FixMatch
论文链接:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
FixMatch 是 Google Brain 提出的一种Holistic的半监督学习方法。
- 首先使用有label数据训练一个模型,将预测结果与真实label计算损失,得到监督loss。
- 对于label数据,分别使用弱增强(平移、翻转等)和强增强(cutout、像素失真等)两种方式进行加噪,将两者分别送入使用第一步中训练得到的模型中。
- 对弱增强的预测结果选取置信度最高的类别作为真实类别,制作为one-hot式的伪标签,即认为弱周期的结果为真实结果,将其与强增强的预测结果进行损失计算,得到非监督loss。与前面的SSL算法不同,FixMatch在非监督部分使用的是交叉熵损,因为我们在这里认为弱增强的结果为真实label。
- 将监督损失和非监督损失进行加权融合,得到最终的loss,对其进行反向传播以更新模型。λu 是未标记数据对应损失的权重。

2、Semi-ViT
论文链接:Semi-supervised Vision Transformers at Scale
Semi-ViT是亚马逊在2022年提出的基于Transformer的大规模半监督视觉算法。
- 首先使用MAE掩码式自训练模型在所有数据(包含有label和无label数据进行)进行预训练。
- 将训练好的MAE中的VIT(编码器部分)提取出来,再利用有label数据进行模型微调。
- 将无label数据输入到微调后的模型中,预测结果中的最高置信度若高于所设置的置信度阈值,我们将该置信度对应的类别作为伪标签。
- 将有label数据和第三步生成的伪样本进行shuffle,得到shuffle数据集,将shuffle数据集分别和label数据、无label数据进行MixUp,得到更新过的label数据和无label数据。
- 使用Mean teacher模型进行半监督微调,训练得到最终模型。

五、半监督学习常用数据集