上一篇博客中对Langchain中prompt进行了详细的介绍,此篇博客将介绍Langchain中的outparser和memory。当调用大模型生成内容时,返回的内容默认是string类型,这对于我们获取response中的某些内容信息可能会带来障碍,例如返回的内容本身是json string内容,如果能返回json对象的话,那么获取response中某个对象的值就更加容易,那么如何通过Langchain提供的能力,将输出的内容转换成JSON类型呢?来看看下面的例子。
import openai
import os
from langchain.prompts import (
HumanMessagePromptTemplate, SystemMessagePromptTemplate, ChatPromptTemplate)
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import ResponseSchema
from langchain.output_parsers import StructuredOutputParser
openai.api_key = os.environ.get("OPEN_AI_KEY")
customer_review = """\
This leaf blower is pretty amazing. It has four settings:\
candle blower, gentle breeze, windy city, and tornado. \
It arrived in two days, just in time for my wife's \
anniversary present. \
I think my wife liked it so much she was speechless. \
So far I've been the only one using it, and I've been \
using it every other morning to clear the leaves on our lawn. \
It's slightly more expensive than the other leaf blowers \
out there, but I think it's worth it for the extra features.
"""
review_template = """\
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? \
Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product\
to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,\
and output them as a comma separated Python list.
text: {text}
"""
human_template_message = HumanMessagePromptTemplate.from_template(
review_template)
chat_template = ChatPromptTemplate.from_messages([human_template_message])
message = chat_template.format_messages(text=customer_review)
chat = ChatOpenAI(model_name="gpt-3.5-turbo")
response = chat(message)
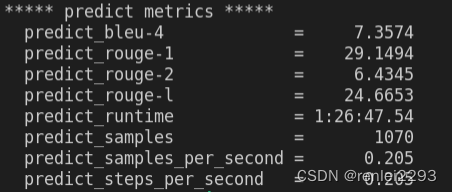
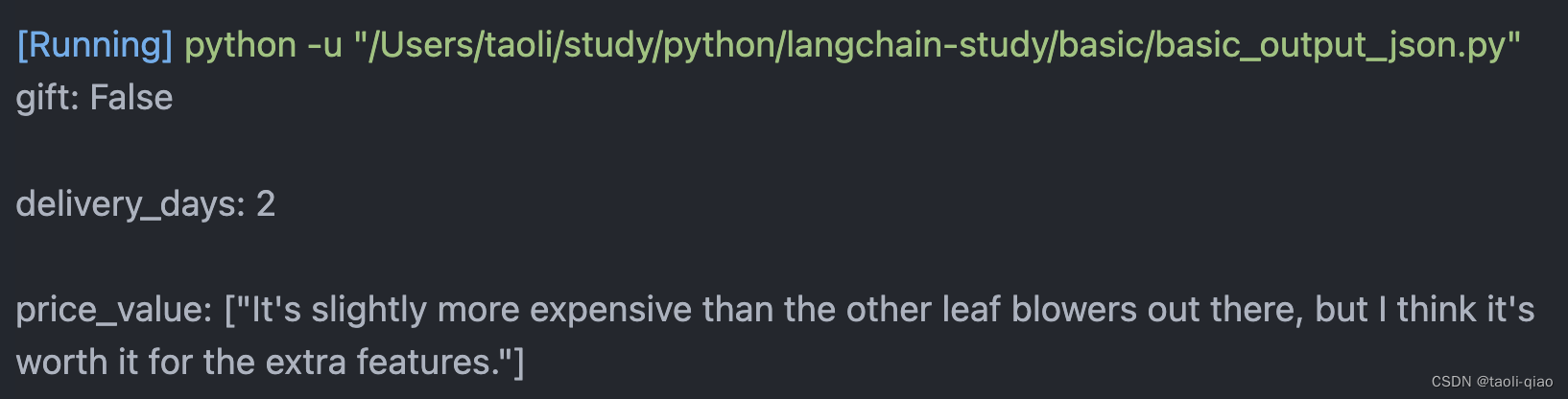
print(response.content)上面的代码生成的结果如下图所示,从一段文本中提取出了gift,delivery_days和price_value.但是因为不是JSON对象,所以,如果要获取提取出来的某个值是不行的。
如果想输出JSON格式的数据,应该如何处理呢?首先在prompt增加了{formact_instruction},通过langchain提供的ResponseSchema定义要提取的字段名称,描述信息;接着通过StructureOutputParser生成parser,再调用parser的get_format_instruction方法生成format_instruction.
review_template_2 = """\
For the following text, extract the following information:
gift: Was the item purchased as a gift for someone else? \
Answer True if yes, False if not or unknown.
delivery_days: How many days did it take for the product\
to arrive? If this information is not found, output -1.
price_value: Extract any sentences about the value or price,\
and output them as a comma separated Python list.
text: {text}
{format_instructions}
"""
gift_schema = ResponseSchema(name="gift",
description="Was the item purchased\
as a gift for someone else? \
Answer True if yes,\
False if not or unknown.")
delivery_days_schema = ResponseSchema(name="delivery_days",
description="How many days\
did it take for the product\
to arrive? If this \
information is not found,\
output -1.")
price_value_schema = ResponseSchema(name="price_value",
description="Extract any\
sentences about the value or \
price, and output them as a \
comma separated Python list.")
response_schema = [gift_schema, delivery_days_schema, price_value_schema]
out_parser = StructuredOutputParser.from_response_schemas(response_schema)
format_instruction = out_parser.get_format_instructions()
# print(format_instrucation)
human_prompt = HumanMessagePromptTemplate.from_template(review_template_2)
chat_prompt = ChatPromptTemplate.from_messages([human_prompt])
message = chat_prompt.format_messages(
text=customer_review, format_instructions=format_instruction)
chat = ChatOpenAI(model_name="gpt-3.5-turbo")
response = chat(message)
print(type(response.content))
result = out_parser.parse(response.content)
print(result)
print(result.get('delivery_days'))
生成的format_instruction如下所示,可以看到实际是一个包含字段名称以及字段类型说明的json对象。
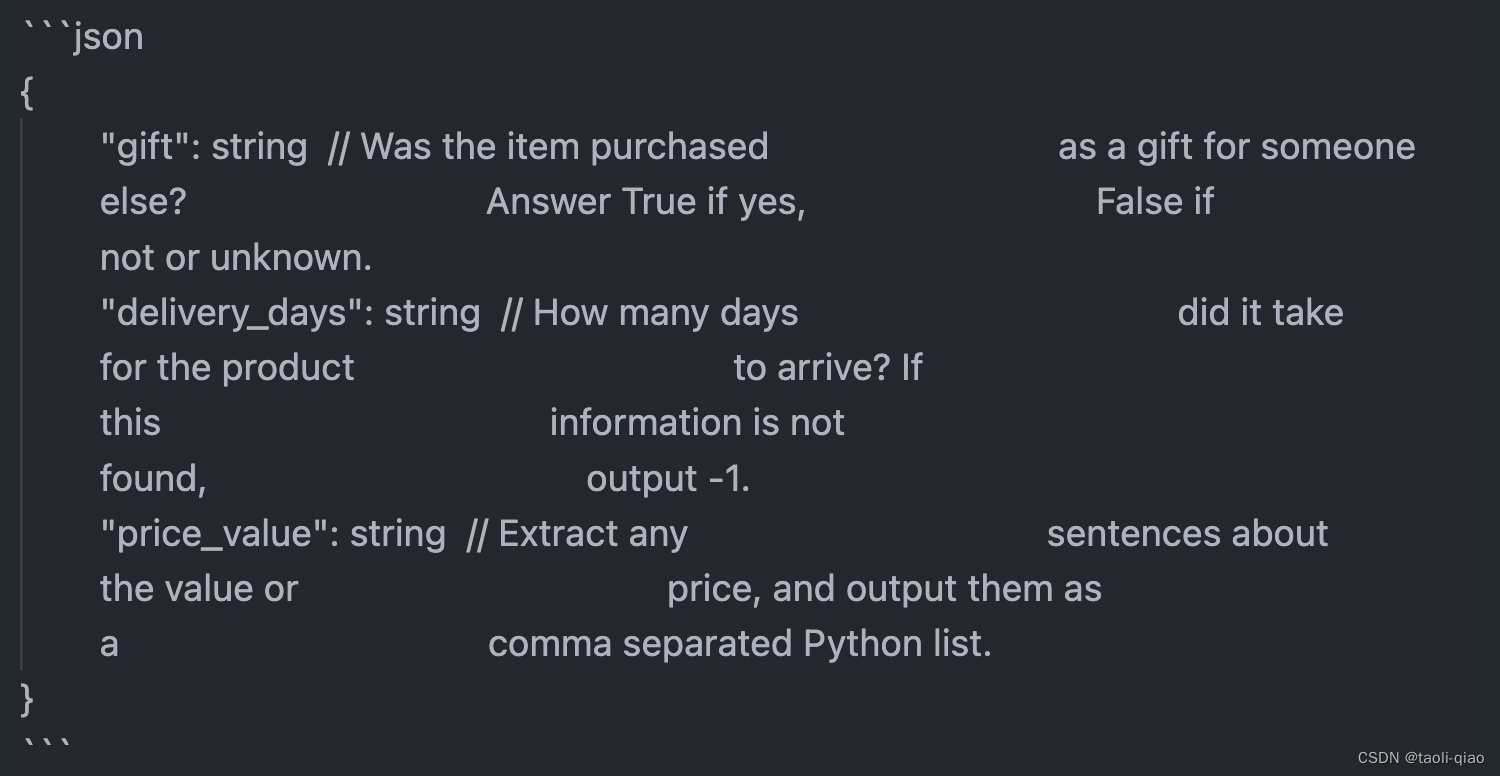
执行完上面的整体代码,结果如下图所示,可以看到返回的是一个json对象,可以单独打印比如delivery_days的值。

以上就是如何让输出的内容是JSON对象的实现说明。
当使用 LangChain 中的储存(Memory)模块时,它可以帮助保存和管理历史聊天消息,以及构建关于特定实体的知识。这些组件可以跨多轮对话储存信息,并允许在对话期间跟踪特定信息和上下文。LangChain 提供了多种储存类型。其中,缓冲区储存允许保留最近的聊天消息,摘要储存则提供了对整个对话的摘要。实体储存 则允许在多轮对话中保留有关特定实体的信息。这些记忆组件都是模块化的,可与其他组件组合使用,从而增强机器人的对话管理能力。储存模块可以通过简单的API调用来访问和更新,允许开发人员更轻松地实现对话历史记录的管理和维护。接下来主要介绍四种类型的Memory,具体如下所示:
- 对话缓存储存 (ConversationBufferMemory)
- 对话缓存窗口储存 (ConversationBufferWindowMemory)
- 对话令牌缓存储存 (ConversationTokenBufferMemory)
- 对话摘要缓存储存 (ConversationSummaryBufferMemory)
import openai
import os
from langchain.chains import ConversationChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import (
SystemMessagePromptTemplate, HumanMessagePromptTemplate, ChatPromptTemplate, ChatMessagePromptTemplate)
openai.api_key = os.environ.get("OPENAI_API_KEY")
model = ChatOpenAI(model_name="gpt-3.5-turbo")
memory = ConversationBufferMemory()
chat = ConversationChain(llm=model, memory=memory, verbose=True)
chat.predict(input="HI, my name is taoli?")
chat.predict(input="What is 1+1?")
chat.predict(input="what is my name?")
print(memory.buffer)上面的代码使用ConversationBufferMemory来记录整个历史对话,打印memory.buffer的值,结果如下所示:可以看到当第三个问题问AI,what is my name时,AI可以正确回答,应为Memory中存入了整个对话History信息。

除了在ConversationChain中增加memory对象对memory赋值外,实际也可以对memory对象直接调用save_context()进行赋值,input就是human的输入,output模拟AI的返回。
memoryTwo = ConversationBufferMemory()
memoryTwo.save_context({'input': 'Hi I came from china'}, {
'output': 'china is beatiful'})
memoryTwo.save_context({"input": "what is your name"}, {
"output": "my name is chatbot"})
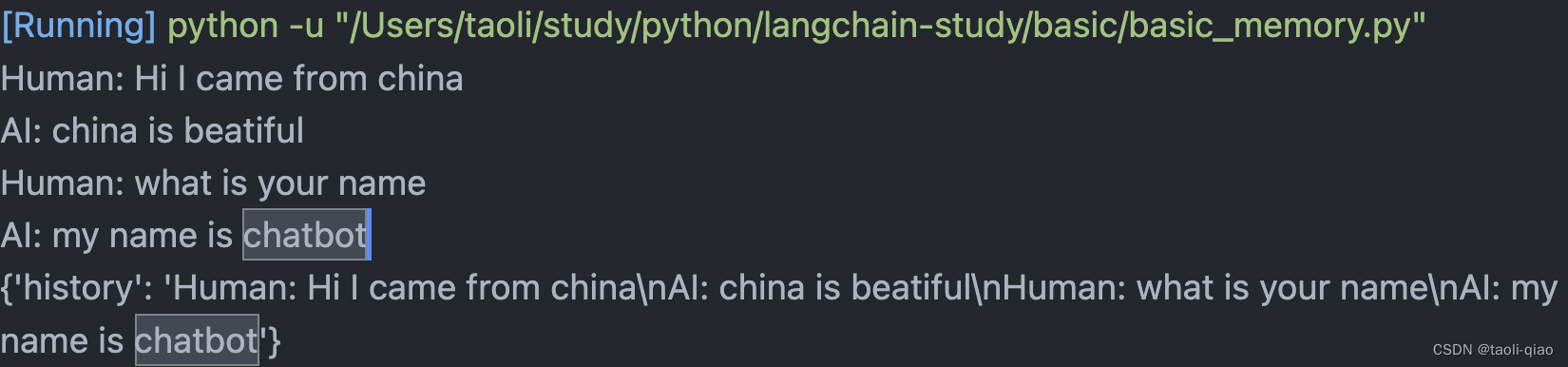
print(memoryTwo.buffer)
print(memoryTwo.load_memory_variables({}))打印的信息如下图所示,buffer中的信息和ConversionChain生成的一样,调用load_memory_variables({})方法,把整个对话信息连接起来,赋值给history变量。
如果把所有的history都记录下来,那么每次传入给LLM的文字太多,token消耗很大,所以,langchain还提供了ConversationBufferWindowMemory,通过定义窗口大小,即K的值来控制记录最新的K轮对话历史信息。memory = ConversationBufferWindowMemory(k=1)。
如果是有大量的文字描述内容,为了节省token以及保证单次对话的token不要超过限制,那么还可以使用ConversationSummaryBufferMemory,使用方式上和ConversationBufferMemory相同。以上就是对Langchain提供的memory的使用介绍。