本篇文章记录下 chatglm-6B 训练和推理过程
环境:Ubuntu 20.04 + 1.13.0+cu116
chatglm-6B 源代码仓库:链接
chatglm-6B 模型权重:链接
源代码及模型 clone 到本地
这里使用的是 THUDM 在 hugging face 开源的模型。
因为模型比较大,仓库保存模式使用的是 git lfs 模式,再 clone 之后再使用 git lfs pull 去 download 大文件。
clone chatglm6B 代码
git clone https://github.com/THUDM/ChatGLM-6B
git lfs 在 ubuntu 的安装方式。参考
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
clone 模型权重到本地,并且使用 git lfs pull 最新版本的模型权重。参考
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b
git lfs pull
chatglm-6B ptuning 训练
THUDM提供的 ptuning 方式 链接 链接
这里需要配置的执行脚本如下:
# train.sh
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file /data/AdvertiseGen/train.json \
--validation_file /data/AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /data/chatglm-6b \
--output_dir /data/chatglm-6b-output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 100 \
--logging_steps 10 \
--save_steps 50 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
在显卡内存较低情况下可以使用 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 ,这种配置下 INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。
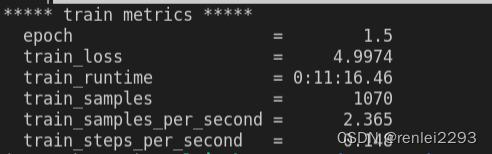
训练输出的 metrics 如下:
chatglm-6B 推理
推理阶段使用的是训练导出的 checkpoint 文件。对应好训练阶段 的 PRE_SEQ_LEN LR 以及训练 STEP ,配置方式如下
# evaluate.sh
PRE_SEQ_LEN=128
CHECKPOINT=adgen-chatglm-6b-pt-128-2e-2
STEP=100
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_predict \
--validation_file /data/AdvertiseGen/dev.json \
--test_file /data/AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /data/chatglm-6b \
--ptuning_checkpoint /data/chatglm-6b-output/$CHECKPOINT/checkpoint-$STEP \
--output_dir /data/chatglm-6b-output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
运行结果
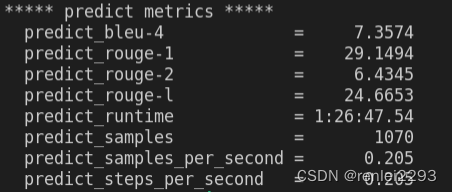
web_demo 执行
相关参考
1、https://zhuanlan.zhihu.com/p/627358709
遇到的问题
1、RuntimeError: Internal: src/sentencepiece_processor.cc(1101) [model_proto->ParseFromArray(serialized.data(), serialized.size())]
这是模型权重文件下载不完全或者版本不一致导致的。
解决方法是 git lfs pull 最新的权重文件。参考
2、NameError: name ‘round_up’ is not defined
这是没有安装 cpm_kernels 的缘故。使用 pip 安装即可。 参考