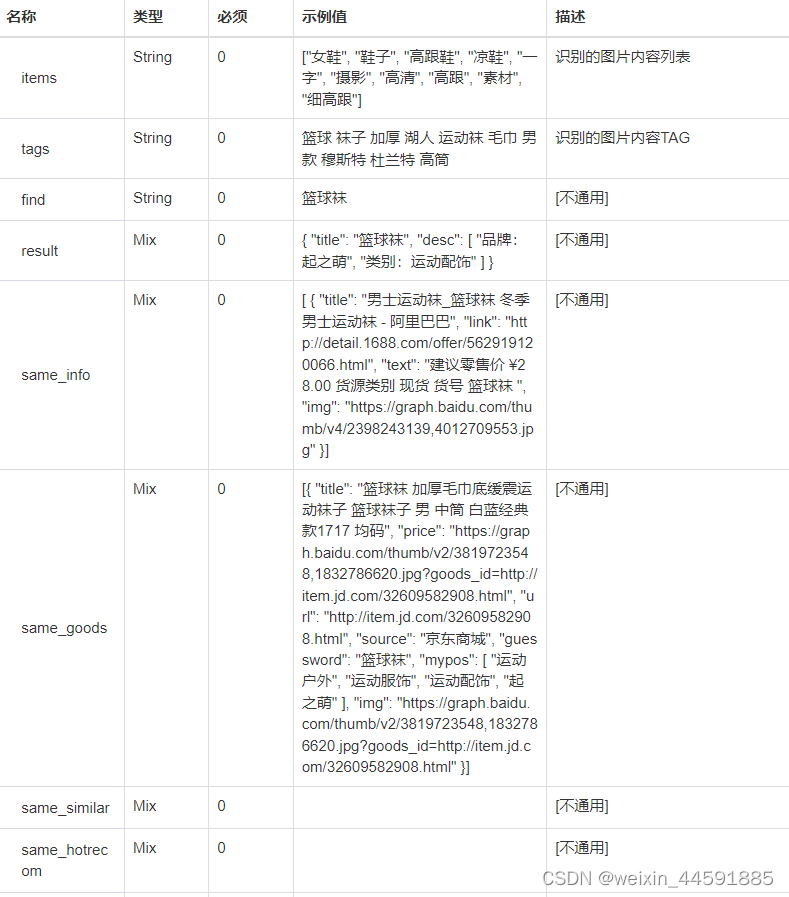
主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
1、MySQL主从复制原理
1.1、MySQL的复制类型
基于语句的复制
基于行的复制
混合类型的复制
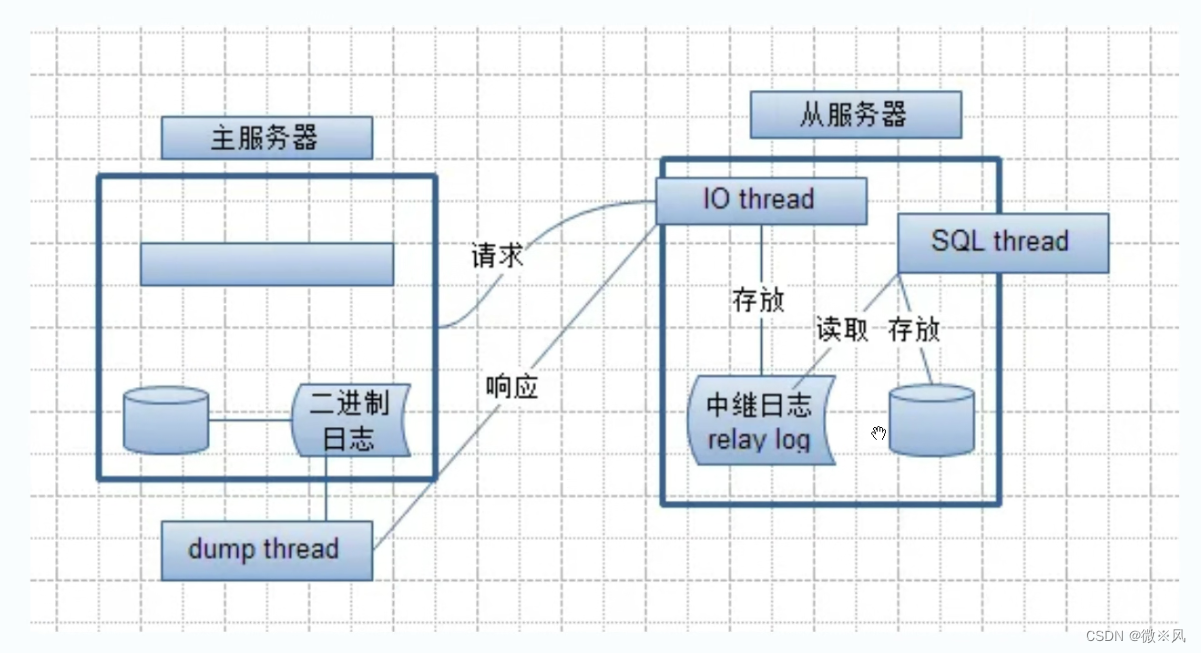
1.2、MySQL主从复制的工作过程

1.3、mysq支持的复制类型
- STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
- ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
- MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
1.4、 数据流向
主-从 进行复制了解为什么复制? ? ? ?
保证数据完整性谁复制谁 ?
slave角色复制master角色的数据数据放在什么地方?
二进制日志文件当中mwsql-bin.000001------>记录完整的sqslave复制二进制日志到本地节点,保存为中继日志文件的方式最后基于这个中继日志 进行“恢复” 操作,将执行的SQL同步执行在自己的数据库内部,最终达到和master数据一致
dump:
用于监听I/O线程请求
将二进制日志中更新数据发送给slave I/O线程
1.5、主从复制的工作过程
- (1)Master节点将数据的改变记录成二进制日志 (bin lg),当Master上的数据发生改变时,则将其改变写入二进制日志中
- slave节点会在一定时间间隔内Laster的二进制日志进行探测其是否发生改变,如果发生改变,则开始个/0线程请求 aster的二进制事件。
- 同时Master节点为每个I/0线程启动一个dump线程,用于向其发送二进制事件,并保存至SLave节点本地的中继日志(Relaylog)中,Slave节点将启动SOL线程从中继日志中读取二进制日志,在本地重放,即解析成 sgL 语句逐一执行,使得其数据和Master节点的保持一致,最后I/0线程和SOL线程将进入睡眠状态,等待下一次被唤醒。同步复制和异步复制
注: ●中继日志通常会位于 OS 缓存中,所以中继日志的开销很小。
●复制过程有一个很重要的限制,即复制在 Slave上是串行化的,也就是说 Master上的并行更新操作不能在 Slave上并行操作。
1.6、 同步复制与异步复制
异步复制
 同步复制:
同步复制:

半同步复制

同步复制、半同步复制和异步复制是数据库系统中常见的数据复制技术,用于在多个数据库实例之间保持数据一致性和可用性。
1. 同步复制(Synchronous Replication):在同步复制中,当主数据库(源数据库)执行写操作时,它会等待所有从数据库(目标数据库)都确认已成功接收和应用这些写操作后才返回给客户端。只有在所有从数据库都成功接收和应用了相同的写操作后,主数据库才能继续进行下一步操作。这种方式确保了在任何情况下,所有从数据库都与主数据库保持数据的完全一致性。然而,由于需要等待从数据库的确认,同步复制的性能相对较低,并且可能会受到网络延迟和故障的影响。
2. 半同步复制(Semi-Synchronous Replication):半同步复制是同步复制和异步复制的折衷方案。在半同步复制中,主数据库在执行写操作后,至少等待一个从数据库确认接收并应用了这个写操作,然后才返回给客户端。这个确认过程可以通过网络传输完成。与同步复制相比,半同步复制提供了更高的性能,因为主数据库不需要等待所有从数据库的确认。然而,半同步复制仍然保证了至少一个从数据库与主数据库之间的数据一致性。
3. 异步复制(Asynchronous Replication):在异步复制中,主数据库在执行写操作后,不会等待从数据库的确认,而是立即返回给客户端。从数据库会尽快地复制主数据库的写操作,但时间上可能存在延迟。异步复制具有较高的性能,并且不受网络延迟和故障的限制。然而,由于主数据库和从数据库之间存在一定的时间差,异步复制的数据一致性可能会有所降低。
总结来说,同步复制提供了最高的数据一致性,但性能相对较低;半同步复制在性能和数据一致性之间取得了平衡;异步复制提供了最高的性能,但数据一致性可能有所降低。选择适合的数据复制技术取决于应用程序的需求和对数据一致性和性能的权衡考虑。
2、读写分离
2.1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2.2、为什么要读写分离呢?
因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的。 但是数据库的“读”(读10000条数据可能只要5秒钟)。 所以读写分离,解决的是,数据库的写入,影响了查询的效率。
2.3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
2.4、MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
2.5、读写分离的分类:
1、基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。 优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。
但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
2、基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序。
- MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
- Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
- Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。