在前面的文章中,对点对点通信API进行了介绍,本文将对MPI组通信相关API进行介绍
一对多
Broadcast
将一个进程的数据广播到所有其他进程中,函数原型:
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm);
函数参数详解:
- void *buffer:指向待广播的数据的起始地址。
- int count:待广播数据的数量。
- MPI_Datatype datatype:待广播数据的类型。
- int root:广播数据的根进程号。
- MPI_Comm comm:通信域。
使用时,需要指定进行分发数据的根进程号root,该进程的缓冲区中数据将会被复制到所有的当前通信域中的其他进程的缓冲区。
MPI_Bcast 本质上是点对点通信,只不过是一个进程重复的向其他不同进程发送数据的过程。
代码示例:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size, root = 0;
int data[4] = {1, 2, 3, 4};
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (rank == root) {
// 广播数据
MPI_Bcast(data, 4, MPI_INT, root, MPI_COMM_WORLD);
} else {
// 接收广播数据
MPI_Bcast(data, 4, MPI_INT, root, MPI_COMM_WORLD);
}
// 输出每个进程接收到的数据
printf("Process %d received data: %d %d %d %d\n", rank, data[0], data[1], data[2], data[3]);
MPI_Finalize();
return 0;
}

Scatter
将一个进程的数据分割成等量的部分,并将每个部分发送给多个其他进程,每个接收进程接收到完整数据的一部分等量的数据,函数原型:
int MPI_Scatter(void *sendbuf, int sendcount,
MPI_Datatype sendtype, void *recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm);
函数参数含义:
- void *sendbuf:指向待分发数据的起始地址。
- int sendcount:每个分发数据缓冲区的大小。
- MPI_Datatype sendtype:待分发数据缓冲区中数据的数据类型。
- void *recvbuf:指向接收分发数据的缓冲区。
- int recvcount:每个接收分发数据缓冲区的大小。
- MPI_Datatype recvtype:接收分发数据缓冲区中数据的数据类型。
- int root:分发数据的根进程号。
- MPI_Comm comm:通信域。
同样的,MPI_Scatter 函数需要指定分发操作的根进程号 root,该进程的缓冲区中的数据将被分发到所有其他进程的缓冲区中。
代码示例:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size;
int data[8] = {1, 2, 3, 4, 5, 6, 7, 8};
int subdata[2];
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if (size != 4) {
fprintf(stderr, "Number of processes must be 4 for this example\n");
MPI_Abort(MPI_COMM_WORLD, 1);
}
MPI_Scatter(data, 2, MPI_INT, subdata, 2, MPI_INT, 0, MPI_COMM_WORLD);
// 输出每个进程接收到的数据
printf("Process %d received data: %d %d\n", rank, subdata[0], subdata[1]);
MPI_Finalize();
return 0;
}
数据分发过程:

从上图我们不难发现,使用MPI_Scatter发送数据,不仅会和通信域中的其他进程通信,还会给自身发送数据,将数据切割成等分量,依次发送给接收进程,接收进程收到的数据不一样。
多对一
Gather
是一种数据收集和汇总通信操作,该方法将多个进程中的数据收集到同一个进程中进行汇总。
前面讲到的一对多数据一个进程分撒消息,这里是汇总消息。
函数原型:
int MPI_Gather(const void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf,
int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
函数参数含义:
- sendbuf:发送缓冲区指针
- sendcount:发送数据个数
- sendtype:发送数据类型
- recvbuf:接收缓冲区指针
- recvcount:每个进程接收的数据个数
- recvtype:接收缓冲区的数据类型
- root:目的进程的进程号
- comm:通信域
该函数在root进程中创建一个大的接收缓冲区,从其他进程接收数据。每个进程可以通过指定发送缓冲区、发送数据个数和数据类型来向 root 进程发送数据。root 进程需要指定接收缓冲区、每个进程接收的数据个数和数据类型。由于在 MPI_Gather 操作中只有 root 进程需要接收数据,因此其他进程不需要指定 recvbuf 参数,当 MPI_Gather 函数被调用时,其他进程将等待其调用结束。当 MPI_Gather 函数完成时,root 进程将拥有一个大小为 recvcount * size 的接收缓冲区。
代码实例:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size, root = 0;
int data[2];
int* recvdata = NULL;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 为 root 进程分配一个大的接收缓冲区
if (rank == root) {
recvdata = new int[2 * size];
}
// 每个进程向 root 进程发送数据
data[0] = rank * 2;
data[1] = rank * 2 + 1;
MPI_Gather(data, 2, MPI_INT, recvdata, 2, MPI_INT, root, MPI_COMM_WORLD);
// 输出每个进程接收到的数据
printf("Process %d received data: %d %d\n", rank, data[0], data[1]);
// root 进程输出汇总后的数据
if (rank == root) {
printf("Root process received data:");
for (int i = 0; i < 2 * size; i++) {
printf(" %d", recvdata[i]);
}
printf("\n");
delete[] recvdata;
}
MPI_Finalize();
return 0;
}

多对多
Allgather
Allgather在所有进程之间进行全局数据通信,每个进程发送和接收数据,从而实现数据的交换和汇总。
函数原型:
int MPI_Allgather(const void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, MPI_Comm comm)
函数参数详解:
- sendbuf:发送缓冲区指针
- sendcount:发送数据个数
- sendtype:发送数据类型
- recvbuf:接收缓冲区指针
- recvcount:每个进程接收的数据个数
- recvtype:接收缓冲区的数据类型
- comm:通信域
与 MPI_Gather 函数类似,但在 MPI_Allgather 函数中,每个进程都将向所有其他进程发送数据,并从所有其他进程接收数据。因此,MPI_Allgather 可以实现任意进程之间的数据交换和汇总,而 MPI_Gather 只能实现一个进程向其他进程发送数据并在 root 进程中汇总数据的操作。

代码实例
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size;
int senddata[2], recvdata[6];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
// 设置发送的数据
senddata[0] = rank * 2;
senddata[1] = rank * 2 + 1;
// 在所有进程之间进行全局数据通信
MPI_Allgather(senddata, 2, MPI_INT, recvdata, 2, MPI_INT, MPI_COMM_WORLD);
// 输出每个进程接收到的数据
printf("Process %d received data:", rank);
for (int i = 0; i < 6; i++) {
printf(" %d", recvdata[i]);
}
printf("\n");
MPI_Finalize();
return 0;
Reduce 归约
所有进程向同一个进程发送消息,与前面讲到的Broadcast的发送方向相反。
接收进程对收到的所有消息进程归约处理;
常见归约操作:
- MAX
- MIN
- SUM
- PROD
- LAND
- BAND
- LOR
- BOR
- LXOR
- BXOR
- MAXLOC
- MINLOC
几个例子,五个进程拿五个不同的大数字,现在需要对这五个数据进行求和,那么就可以将数据发送给一个进程,操作为SUM。
函数原型:
int MPI_Reduce(const void* sendbuf, void* recvbuf,
int count, MPI_Datatype datatype, MPI_Op op, int root,
MPI_Comm comm)
函数参数详解:
- sendbuf:发送缓冲区的首地址
- recvbuf:用于接收归约结果的本地进程缓冲区的首地址
- count:缓冲区中元素的数量
- datatype:元素类型的 MPI 数据类型句柄
- op:MPI_Op 类型的操作句柄,用作约减运算(如 MPI_SUM、MPI_MAX 等)
- root:接收归约结果的进程号
- comm:进程的 MPI 通信域,即进程所属的组
对于每个连续的缓冲区对,使用 op 句柄中定义的约减函数来将缓冲区中的值合并为一个值,并将结果存储在指定的接收缓冲区中。最终结果只会出现在进程 root 的缓冲区中。
代码实例:
#include <mpi>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size, sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Reduce(&rank, &sum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0) {
printf("Sum of all ranks = %d\n", sum);
}
MPI_Finalize();
return 0;
}
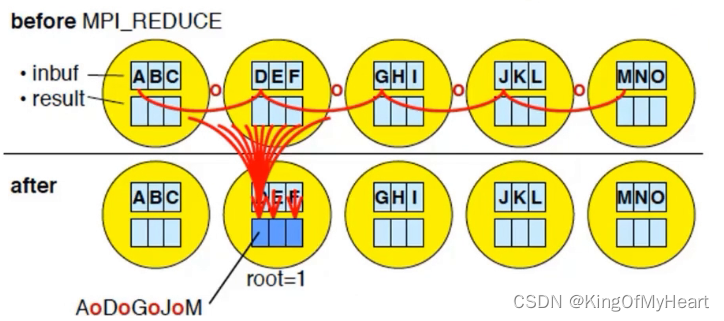
Allreduce
与Reduce不同的是,Allreduce无root参数,所有进程都将获得结果,结果会通过广播的方式传播给其他进程。
函数原型:
int MPI_Allreduce(const void* sendbuf, void* recvbuf,
int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
函数参数:
- sendbuf:发送缓冲区的首地址
- recvbuf:用于接收归约结果的本地进程缓冲区的首地址
- count:缓冲区中元素的数量
- datatype:元素类型的 MPI 数据类型句柄
- op:MPI_Op 类型的操作句柄,用作约减运算(如 MPI_SUM、MPI_MAX 等)
- comm:进程的 MPI 通信域,即进程所属的组
函数通过将每个进程的本地发送缓冲区中的值与其他进程的相应值结合来计算一个约减的全局值,并将结果发送回本地接收缓冲区中。MPI_Allreduce 函数的本质是针对所有进程执行 MPI_Reduce 和 MPI_Bcast 操作的组合。
代码实例:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
int rank, size, sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Allreduce(&rank, &sum, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Rank %d, Sum of all ranks = %d\n", rank, sum);
MPI_Finalize();
return 0;
}

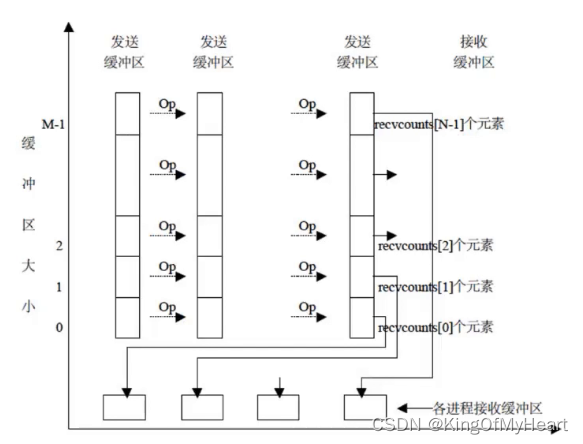
Reduce scatter
MPI_Reduce_scatter 是 MPI 中的一个全局规约通信操作,其作用是将输入缓冲区中的数据进行约简,并将结果分发到多个进程中。MPI_Reduce_scatter 归约操作类似于 MPI_Reduce,但是它对约减结果进行分割并分发到所有进程中。MPI_Reduce_scatter 操作可用于各种规约操作,例如求和、求最大/最小值等。
函数原型:
int MPI_Reduce_scatter(const void *sendbuf, void *recvbuf,
const int recvcounts[], MPI_Datatype datatype,
MPI_Op op, MPI_Comm comm)
函数参数详解:
- sendbuf:发送缓冲区的首地址
- recvbuf:用于接收归约结果的本地进程缓冲区的首地址
- recvcounts:一个数组,描述了每个进程期望接收的元素数量
- datatype:元素类型的 MPI 数据类型句柄
- op:MPI_Op 类型的操作句柄,用作约减运算(如 MPI_SUM、MPI_MAX 等)
- comm:进程的 MPI 通信域,即进程所属的组
函数的作用是将输入缓冲区的数据约减,并按每个进程期望接收的元素数量将结果分发到每个进程中。MPI_Reduce_scatter 函数实际上将 MPI_Reduce 和 MPI_Scatter 功能组合成一个操作。MPI_Reduce_scatter中,每个进程都将输入数组的所有项进行约减操作,并使用 MPI_Scatter 函数将约减后的数据发送到所有进程中。MPI_Reduce_scatter 必须在所有进程中同时调用。
代码实例:
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
int rank, size, sum;
int global_sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int *sendbuf = (int*)malloc(sizeof(int) * size);
int *recvbuf = (int*)malloc(sizeof(int));
for (int i = 0; i < size; i++) {
sendbuf[i] = rank;
}
MPI_Reduce_scatter(sendbuf, recvbuf, &size, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Rank %d, Sum of all ranks = %d\n", rank, *recvbuf);
free(sendbuf);
free(recvbuf);
MPI_Finalize();
return 0;
}
Scan
每一个进程都对排在它前面的进程进行归约操作;
MPI_Scan调用的结果是,对于每一个进程i,对于进程0…i的发送缓冲区中的数据进行指定的归约操作,结果存放在进程i的接收缓冲区中。
函数原型:
int MPI_Scan(const void *sendbuf, void *recvbuf,
int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
函数参数详解:
- sendbuf:发送缓冲区的首地址
- recvbuf:用于接收归约结果的本地进程缓冲区的首地址
- count:发送/接收缓冲区中数据的数量
- datatype:元素类型的 MPI 数据类型句柄
- op:MPI_Op 类型的操作句柄,用作归约运算(如 MPI_SUM、MPI_MAX 等)
- comm:进程的 MPI 通信域,即进程所属的组
代码实例:
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
int rank, size, sum;
int global_sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int *sendbuf = (int*)malloc(sizeof(int));
int *recvbuf = (int*)malloc(sizeof(int));
*sendbuf = rank;
MPI_Scan(sendbuf, recvbuf, 1, MPI_INT, MPI_SUM, MPI_COMM_WORLD);
printf("Rank %d, Sum of all ranks = %d\n", rank, *recvbuf);
free(sendbuf);
free(recvbuf);
MPI_Finalize();
return 0;
}
Alltoall
每个进程一次将它的发送缓冲区的第i块数据发送给第i个进程,同时每个进程又都一次从第j个进程接收数据放到各自接收缓冲区的第j块数据区的位置。
函数原型:
int MPI_Alltoall(const void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, MPI_Comm comm)
函数参数详解:
- sendbuf:表示发送缓冲区,用于存储该进程要发送给其他进程的数据。
- sendcount:表示每个发送缓冲区中的元素数量。
- sendtype:表示发送数据的数据类型。
- recvbuf:表示接收缓冲区,用于存储其他进程发送给该进程的数据。
- recvcount:表示每个接收缓冲区中的元素数量。
- recvtype:表示接收到的数据的数据类型。
- comm:表示通信域
代码实例
#include <iostream>
#include <mpi.h>
int main(int argc, char **argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int send_data[4] = {1, 2, 3, 4};
int recv_data[size * 4];
MPI_Alltoall(send_data, 1, MPI_INT, recv_data, 1, MPI_INT, MPI_COMM_WORLD);
for (int i = 0; i < size * 4; i++) {
std::cout << "Process " << rank << " received " << recv_data[i] << " from process " << i / 4 << std::endl;
}
MPI_Finalize();
return 0;
}

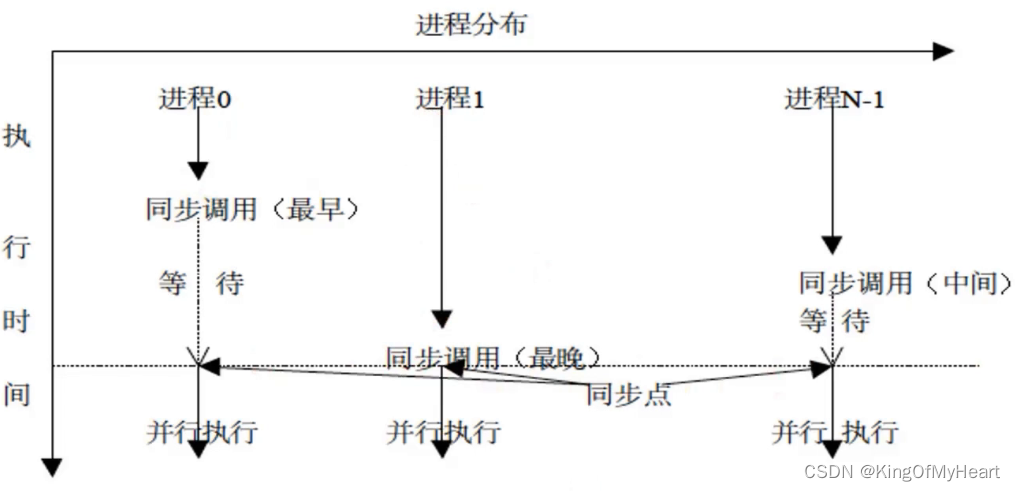
进程同步
Barrier
相当于在某处设置一个栅栏,到达这里的进程需要在这里等待,直到所有的进程都到达这里,做一个同步的动作。
MPI 进程通常是异步执行的,即每个进程独立地执行它们的任务,与其他进程无关。但是,某些应用程序需要确保所有 MPI 进程在某一点上都到达了一个同步状态,这时就可以使用 MPI_Barrier。
函数原型:
int MPI_Barrier(MPI_Comm comm)
函数参数:
- comm:表示通信域,所有在该通信域中的进程将进行 MPI_Barrier 同步。
代码实例:
#include <iostream>
#include <mpi.h>
int main(int argc, char **argv) {
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
std::cout << "Process " << rank << " says hello!" << std::endl;
MPI_Barrier(MPI_COMM_WORLD);
std::cout << "Process " << rank << " says goodbye!" << std::endl;
MPI_Finalize();
return 0;
}