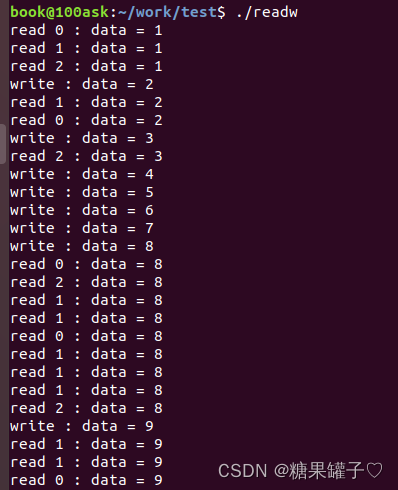
目录
监督学习 与 无监督学习
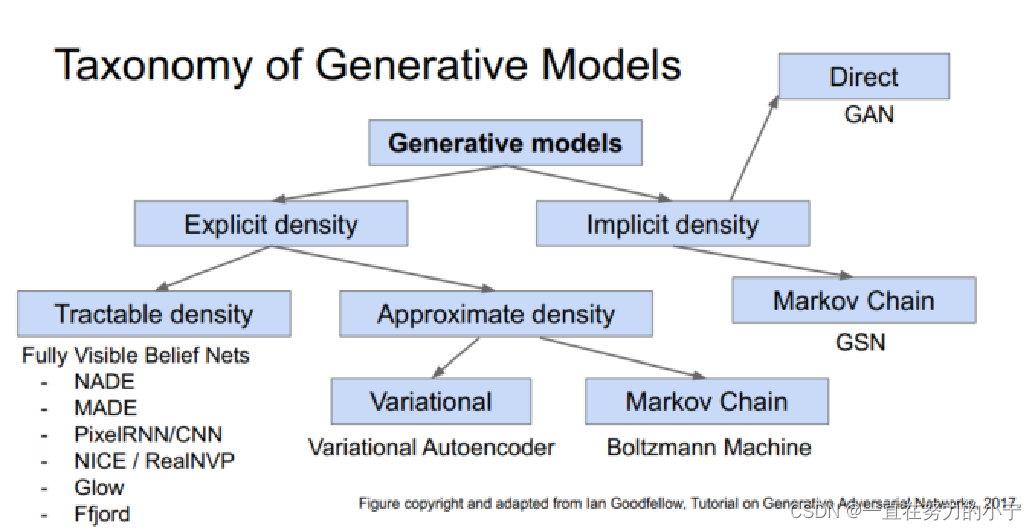
生成模型
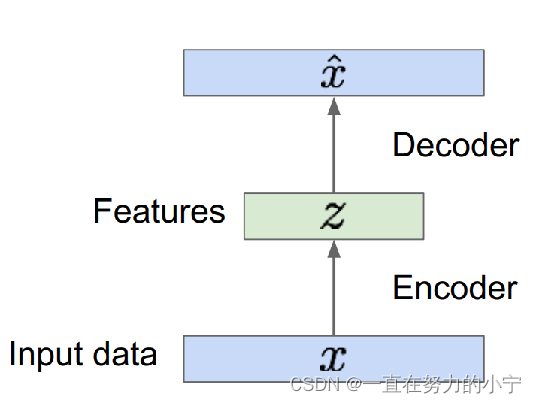
自编码器
从线性维度压缩角度: 2D->1D
线性维度压缩: 3D->2D
推广线性维度压缩
流形
自编码器:流形数据的维度压缩
全图像空间
自然图像流形
自编码器的去噪效果
自编码器的问题
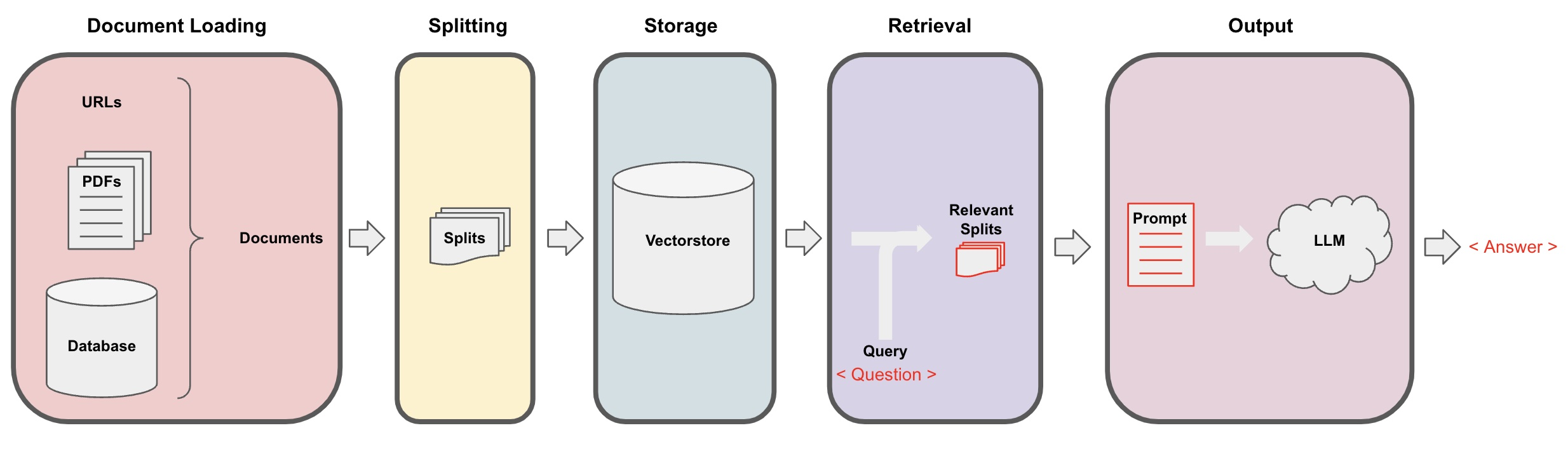
图像预测 (“结构化预测”)
显式密度模型
RNN
PixelRNN [van der Oord et al. 2016]
PixelCNN [van der Oord et al. 2016]
Variational Auto-Encoder (变分自编码器 VAE)
变分自编码器 VAE
VAE vs PixelRNN
编辑
隐变量模型
VAE的“不温顺”:Intractability
Generative Adversarial Network (对抗生成网络 GAN)
训练判别器网络预测图像是否真实
GAN模型
模式崩溃(Mode Collapse)
Diffusion扩散模型
AIGC
监督学习 与 无监督学习
监督学习
数据:(x, y) X是数据,Y是标签
目标:学习一个从x到y的函数映射
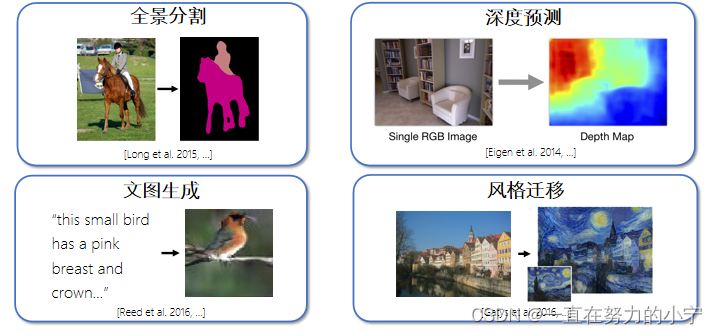
样例:分类、回归、物体检测、语义分割、描述
无监督学习
数据:(x) 只有数据,没有标签!
目标:从数据x中学习其固有的结构信息
样例:聚类、维度压缩、表征学习、密度估计
生成模型
定义:给定训练数据,生成与训练数据服从相同分布的新样本
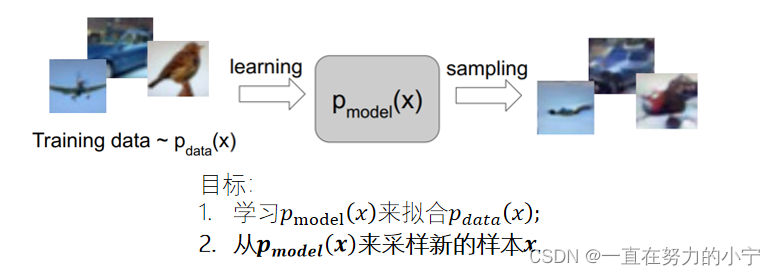

PixelRNN/CNN较为常用
为什么需要生成模型?
实际应用(图像修复,艺术生成等)
为下游任务(如分类)创造样本做表征学习
生成样本量极少的高维数据(物理、医疗图像等)
模拟环境用于决策判断(机器人、强化学习等)
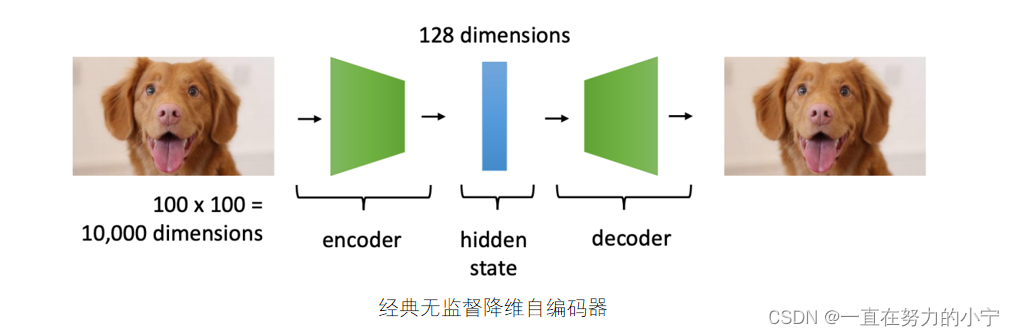
自编码器
自编码器(Auto-Encoders):通过对编码层限制维度(Dimensionallity)、强制稀疏(Sparsity)、加入噪声(Denoising)等方法,来迫使模型学习数据的结构化表征
!!缺乏采样生成手段
简单来说就是:用无监督方法来获取无标签训练数据的低维表征
z一般比x的维度小 为什么维度小?
数据压缩可以获得“有意义的信息”
怎么做到?
训练完去掉解码器

在有标注的数据集上微调编码器
有监督的数据可以让编码器获得“有意义的信息”
但这样无法采样z,因为不知道它的分布

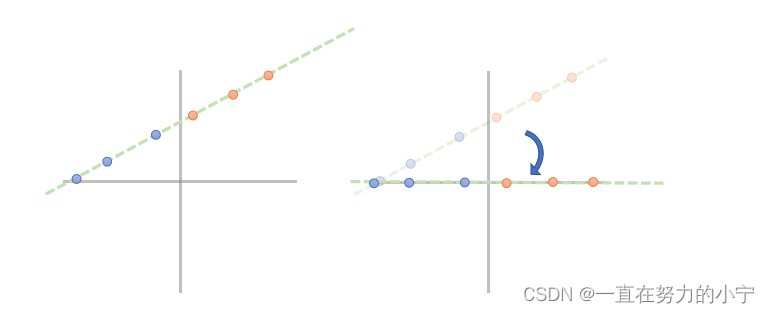
从线性维度压缩角度: 2D->1D
考虑在二维平面上的点 这些点都在一条直线上
我们可以通过投影的方式把它们压缩到一维且保留相互之间的关系
线性维度压缩: 3D->2D
与一维类似,我们可以把点投影到平面上 进行 “平面拟合”
我们需要记录的数据从三维变成了二维+平面的参数
可以想象成把空间的点投影到一张纸

推广线性维度压缩
主成分分析 Principal Components Analysis (PCA):
- 根据数据的分布找到数据的主成分
- 每个正交的方向为一个主成分
- 可以保留前k个主成分来做维度压缩
- PCA与数据的特征空间高度相关
流形
一张纸上的点可以用二维空间表示
如果进行折叠,那么它仍然可以用二维表示,但是这张纸却变成了三维物体…
流形(manifold)可以看作这种形式的扩展…
自编码器:流形数据的维度压缩

大多数维度压缩的变换是不可逆的
自编码器所学的是一个从流形数据到低维特征的可逆变换


全图像空间
考虑所有分辨率为 100x100 图像 我们来随机采样…
提问: 完全随机采样的图像长什么样?
pixels = np.random.rand(100,100,3)
结论:大多数图像都是噪声
自然图像流形
大多数图像是噪声
有“意义”的图像一般分布在一个具体的流形上
该流形会包含所有拥有相同“意义”的图像

自编码器的去噪效果
自编码器会学习某个在流形上的可逆变换
由于没有“意义”,绝大多数噪声不在流形上
如果我们在输入端就加入噪声,我们就可以得到去噪后的数据

自编码器的问题
自编码器可以还原在流形上的数据点
但是并不能还原该流形上的所有数据点…
无法实现采样确保生成有效的新数据…


图像预测 (“结构化预测”)
我们通常会用类似自编码器的结构来进行 图像到图像之间的迁移
更好的损失函数:更好的生成效果
我们如何设计损失函数,使得不在流形上的数据得到应有的“惩罚”?
设计可学习的损失函数
显式密度模型


RNN

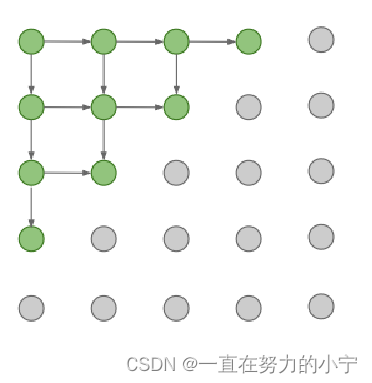
PixelRNN [van der Oord et al. 2016]
从左上角开始生成每个像素
使用RNN和所有已经生成好的像素点生成新的像素点
缺点:顺序生成过程过于缓慢
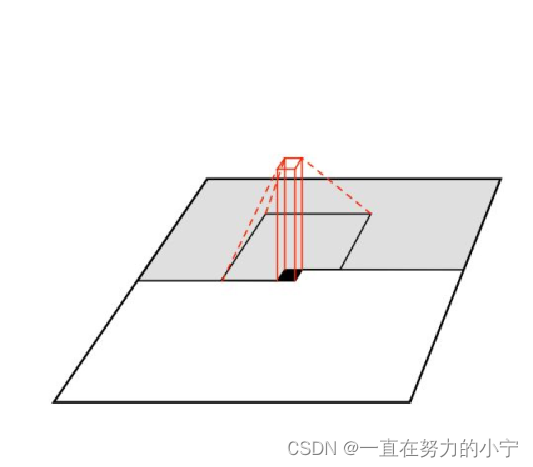
PixelCNN [van der Oord et al. 2016]
同样从左上角开始生成每个像素
仅使用当前像素点周围一个窗口的区域生成当前像素点
比PixelRNN快很多 但仍然很慢

Variational Auto-Encoder (变分自编码器 VAE)

变分自编码器 VAE
变分自编码器(Variational Autoencoders,VAE):通过对中间表征概率建模(Probabilistic Modeling)使隐变量服从先验分布

VAE vs PixelRNN

优点:快,直接可以生成所有的像素点
缺点:“不温顺”,无法直接优化z,只能推出似然估计的下界

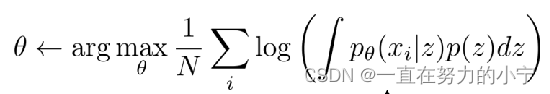

这样学习的问题是什么?
“不温顺”(难以处理的)
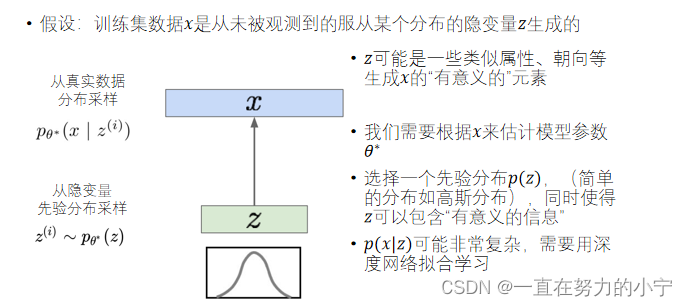
隐变量模型
隐变量模型(Latent Variable Models):学习一个潜在的隐变量空间来解释观测数据的生成过程,可以生成新的样本

VAE的“不温顺”:Intractability

由于z维度较大,较难有效采样 无法通过蒙特卡洛估计 z 来优化p(x│z)

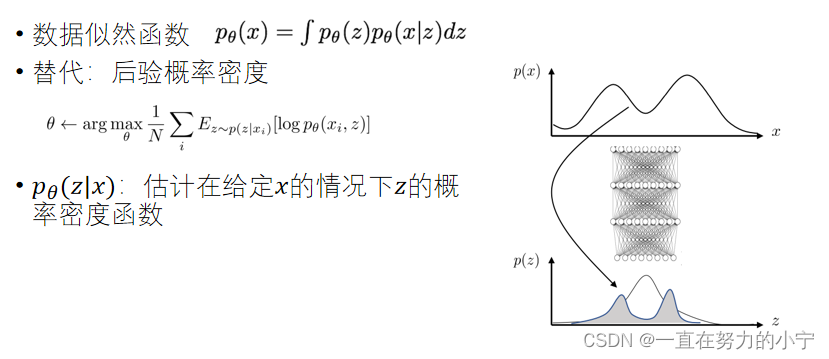
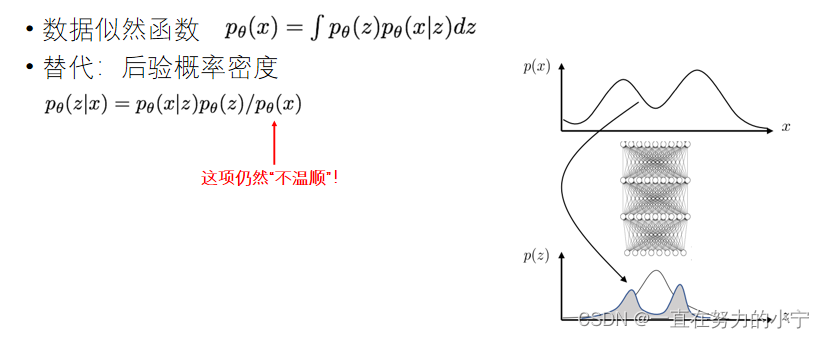




优点: 可以通过微调编码器学习有效编码 理论性更强
缺点: 生成效果一般
研究领域: 解耦表征
Generative Adversarial Network (对抗生成网络 GAN)

训练判别器网络预测图像是否真实
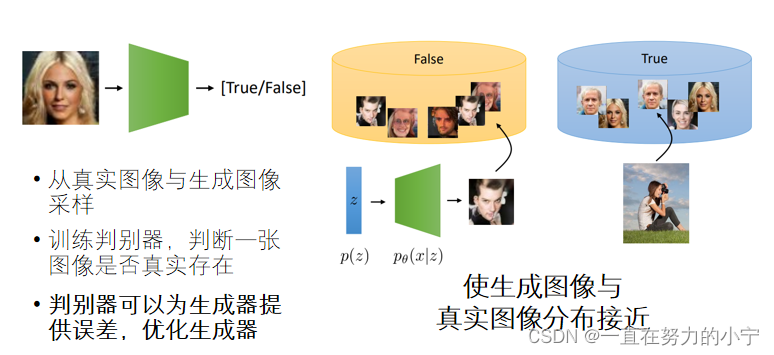
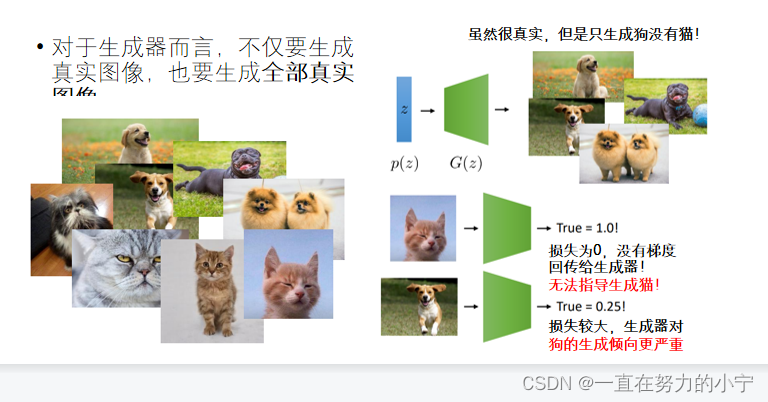
GAN模型

模式崩溃(Mode Collapse)
GAN总结
优点: 效果好!
缺点: 难以训练
改进方式: Wasserstein GAN (WGAN)、梯度惩罚 (Gradient Penalty)、谱标准化 (Spectral Normalization)
Diffusion扩散模型
如何避免对每一个概念训练一个扩散网络?
方法1:加一个标签给扩散网络
方法2:使用语言模型
与GAN的对比
优点: 扩散模型更好训练
缺点: 速度较慢(需要多步迭代)
AIGC

剩下的应用就不记笔记了~有认真看~
完结撒花!!