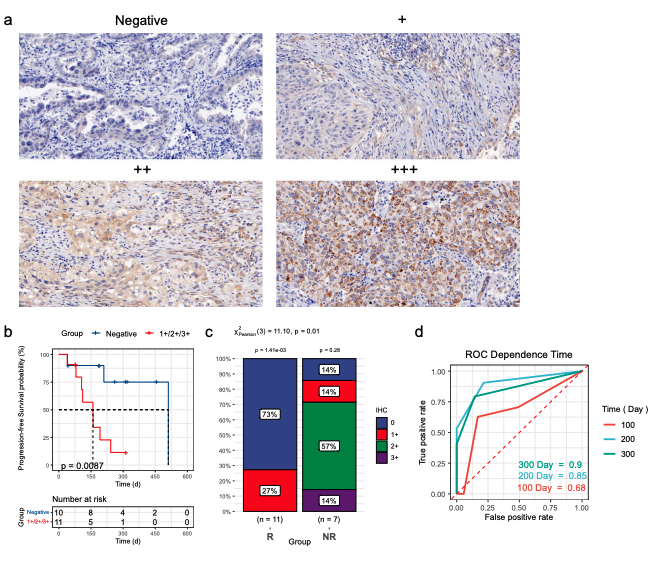
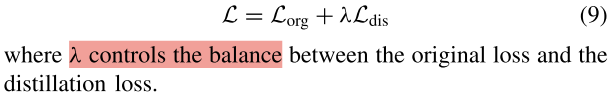作者:Benjamin Trent

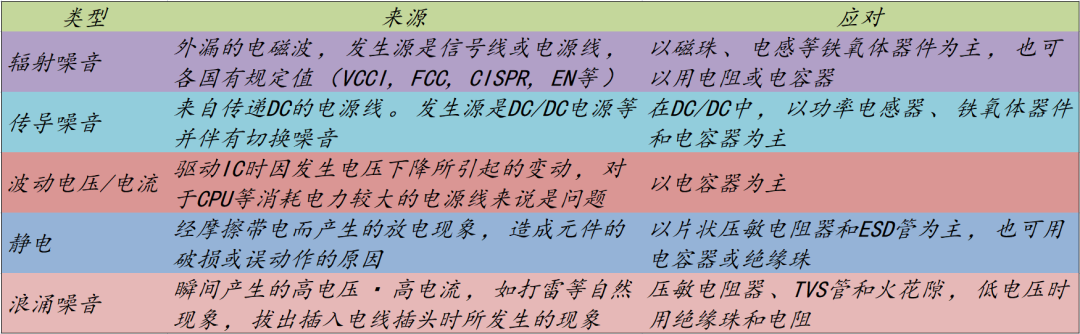
向量搜索是信息检索工具箱中的一个强大工具。 将向量与词法搜索(如 BM25)一起使用很快变得司空见惯。 但向量搜索中仍然存在一些痛点需要解决。 主要的一个是文本嵌入模型和处理更大的文本输入。
像 BM25 这样的词法搜索已经是为长文档设计的,而文本嵌入模型却不是。 所有嵌入模型都对其可以嵌入的 token 数量有限制。 因此,对于较长的文本输入,必须将其分成比模型限制短的段落。 现在,你不再拥有一份包含所有元数据的文档,而是拥有多个段落和嵌入。 如果你想保留元数据,则必须将其添加到每个新文档中。

解决这个问题的一种方法是使用 Lucene 的 join 功能。 这是 Elasticsearch 嵌套 (nested) 字段类型的一个组成部分。 它使具有多个嵌套文档的顶级文档成为可能,允许你搜索嵌套文档并连接回其父文档。 这听起来非常适合属于单个顶级文档的多个段落和向量! 这太棒了! 但是,等等,Elasticsearch® 不支持嵌套字段中的向量。 为什么不呢?需要改变什么?
kNN 问题中的父子关系
关键问题是 Lucene 在搜索子向量段落时如何连接回父文档。 就像 kNN
预过滤与后过滤一样,join 发生的时间决定了结果的质量和数量。 如果用户搜索与查询向量最接近的前四个父文档(不是段落),他们通常期望四个文档。 但是,如果他们正在搜索子向量段落并且所有四个最近的向量都来自同一父文档怎么办? 这最终只会返回一份父文档,这将是令人惊讶的。 后过滤也会出现同样的问题。

让我们使用查询向量 A 进行搜索,四个最近的段落向量是 6、7、8、9。使用 “post joining”,你最终只会检索父文档 10。
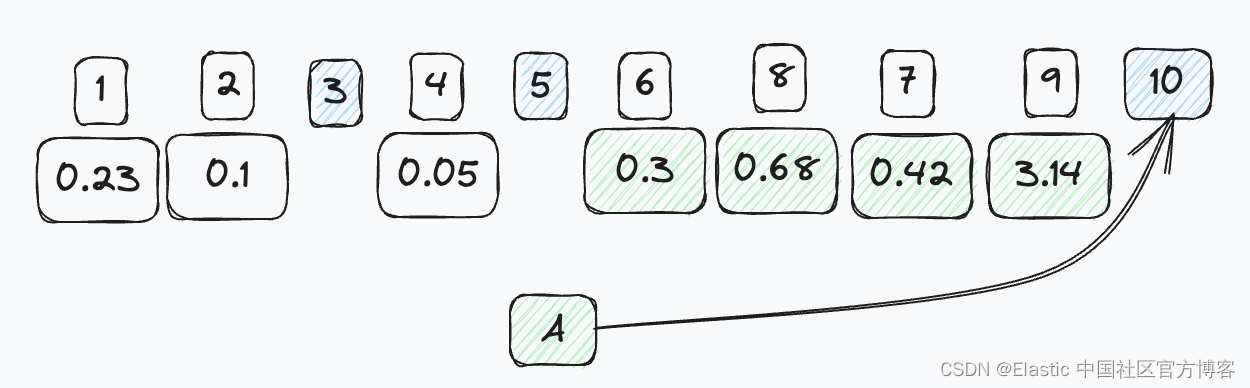
对于这个问题我们能做些什么呢? 一种答案可能是,“只需增加返回向量的数量即可!” 然而,从规模来看,这是站不住脚的。 如果每个父至少有 100 个孩子,而你想要前 1,000 个最近邻居,该怎么办? 这意味着你必须寻找至少 100,000 个孩子! 这很快就会失控。 那么,还有什么解决方案呢?
Pre-joining 加入救援
解决 “post-joining” 问题的方法是 “pre-joining”。 最近对 Lucene 添加的更改允许在搜索 HNSW 图时加入父文档! 与 kNN 预过滤一样,这确保当要求查找查询向量的 k 个最近邻居时,我们可以返回的不是由密集向量表示的 k 个最近的段落,而是返回 k 个最近的文档,由它们的子段落表示与查询向量最相似。 这在实践中实际上是什么样的?
假设我们正在搜索与以前相同的嵌套文档:

当我们搜索文档并对其进行评分时,我们不是跟踪子文档,而是跟踪父文档并更新其分数。 图 5 显示了一个简单的流程。 对于访问的每个子文档,我们都会获取其分数,然后通过其父文档 ID 对其进行跟踪。 这样,当我们搜索向量并对向量进行评分时,我们只收集父 ID。 这确保了结果的多样化,并且使用 Lucene 中现有的强大工具不会增加 HNSW 算法的复杂性。 所有这一切只需要存储每个向量一个额外的内存位。
图 5:当我们搜索向量时,我们会评分并收集相关的父文档。 仅当分数比之前的分数更具竞争力时才更新分数。
但是,这如何有效呢? 很高兴你问了! 有一些限制提供了一些非常好的捷径。 从前面的示例中可以看出,所有父文档 ID 都大于子文档 ID。 此外,父文档本身不包含向量,这意味着子文档和父文档是纯粹不相交的集合 (disjoint sets)。 这通过位集(bit sets)提供了一些很好的优化。 位集提供了一种异常快速的结构,用于 “告诉我下一个设置的位”。 对于任何子文档,我们可以询问位集,“嘿,集合中比我大的数字是多少?” 由于这些集合是不相交的,我们知道设置的下一位是父文档 ID。
结论
在这篇文章中,我们探讨了支持大规模密集文档检索的挑战以及我们提出的使用 Lucene 中的嵌套字段和 join 的解决方案。 Lucene 中的这项工作为更自然地存储和搜索文档中长文本段落的密集向量以及 Elasticsearch 中向量搜索的文档建模的整体改进铺平了道路。 这是 Elasticsearch 中向量搜索向前迈出的非常激动人心的一步!
如果你想讨论此问题或与 Elasticsearch 中的向量搜索相关的任何其他内容,请加入我们的讨论论坛。