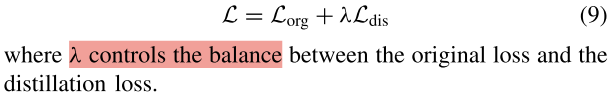Multipatch Progressive Pansharpening With Knowledge Distillation
(基于知识蒸馏的多面体渐进锐化算法)
在这篇文章中,我们提出了一种新的多面体和多级泛锐化方法与知识蒸馏,称为PSDNet。不同于现有的pansharpening方法,通常输入单一大小的补丁到网络,并在整个阶段实现pansharpening,我们设计了多patch的输入和多级网络更准确,更精细的学习。首先,多面体输入允许网络通过减少对象类型的数量来学习更准确的空间和光谱信息。我们采用小patch在早期部分学习准确的本地信息,因为小patch包含较少的对象类型。然后,后一部分利用大的patch来微调它的整体信息。其次,多级网络的设计,以减少以前的单步泛锐化的难度,并逐步产生详细的结果。此外,代替传统的感知损失,这几乎没有涉及到特定的任务或设计的网络,我们引入蒸馏损失,以加强指导的地面真相。
INTRODUCTION
低分辨率多光谱(LRMS)图像和全色(PAN)图像是两种由卫星获取的不同形态的遥感图像。由于LRMS图像中的空间信息和PAN图像中的光谱信息的缺乏限制了它们的进一步应用(例如,目标探测和环境监测),高分辨率多光谱(HRMS)图像的需求量很大。然而,由于设备的限制,直接捕获HRMS图像几乎是难以处理的。为了科普这一挑战,出现了通过结合LRMS图像和PAN图像的优点来产生HRMS图像的泛锐化技术。早期的全色锐化研究都是传统的方法。它们可以分为基于组件替换(CS)的方法,基于多分辨率分析(MRA)的方法,CS-MRA混合方法和基于模型的方法。通常,它们利用先验知识来对HRMS图像和源图像之间的连接进行建模。然而,这些模型大多是手工制作的,先验知识是否被准确地表达也是值得怀疑的。上述挑战限制了传统方法的性能。
近年来,由于神经网络强大的特征表示能力,深度学习已被广泛应用于众多任务中,包括图像恢复,图像配准,图像融合等。基于深度学习的泛锐化方法通常不依赖于任何先验知识。他们擅长从数据分布自动学习有用的信息,实现了显着的改进传统的全色锐化方法。一般来说,基于深度学习的方法包括基于卷积神经网络(CNN)的方法和基于生成对抗网络(GAN)的方法。前者利用CNN来提取特征,后者在生成器和鉴别器之间建立对抗游戏。现有的泛锐化方法虽然取得了显著的效果,但在某些方面仍有改进的空间。首先,以前的方法通常将通过下采样获得的单尺寸补丁或多尺度输入馈送到网络中。它们未能利用原始MS或PAN图像中的对象分布的规律性。具体来说,它们往往忽略了相邻对象之间的相似性和相关性,这导致融合图像无法有效地利用相似对象的分布来促进彼此之间的全色锐化过程。
如图1所示。将一个大面片裁剪为四个小面片。显然,具有相似大小或形状的对象(用黄色椭圆标记)通常出现在集群中。它保证较小的面片更有可能包含较少类型的对象。因此,较小的补丁更容易学习准确的本地内核信息。在已知局部信息的情况下,较大的补丁可以平滑且容易地针对全局信息对其进行微调。其次,几乎所有以前的泛锐化方法采用单阶段策略。然而,不容易在单个阶段中产生期望的结果。最后,大多数算法仅考虑生成的结果和地面实况之间的L1损失或MSE损失。一些方法考虑感知损失;然而,他们需要依赖于与他们自己的网络无关的其他网络(VGG 16或VGG 19)。应设计更合理的损失,以综合利用地面实况。
为了科普上述问题,我们提出了一个多补丁和多级网络知识蒸馏。首先,我们引入多面体泛锐化不同的对象分布,所有补丁裁剪原始图像,而不会丢失任何分辨率信息。具体来说,我们利用小补丁首先学习准确的局部信息和大补丁后获得全局信息。其次,我们采用多阶段的策略,将整体pansharpening任务分为多个任务,从而减轻了单阶段的难度。此外,多级策略逐步生成高质量的HRMS图像从局部到全局的空间和光谱信息。最后,运用知识提炼的方法来帮助我们构建一个更合理的损失。具体地,教师网络使用地面实况作为输入。而不是只考虑学生模型的地面真值和最终预测之间的差异,它为学生网络提供了更全面的信息,从而提高了性能。
总体而言,我们的贡献主要体现在以下四个方面:
1)与单一大小的补丁相比,我们设计多面体作为网络的输入。小的补丁允许网络学习更真实的光谱信息,而大的补丁则可以根据整体信息对其进行微调。
2)我们构建了一个多级网络来降低单级网络的难度,并逐步生成具有更精细空间细节的结果。
3)我们采用知识蒸馏的额外损失来实现特征级约束。它与我们的网络高度相关,增强了对地面真相的引导。
4)大量的实验结果表明,我们的方法在所有三颗卫星上都大大超过了以前的最先进的方法。
RELATED WORK
Deep Learning-Based Pansharpening Methods
基于cnn的方法擅长提取各种特征来表达原始图像。卷积神经网络(convolutional neural network, PNN)泛锐化是第一种基于CNN的泛锐化方法,它利用了简单的网络结构,同时获得了令人印象深刻的性能。在PNN的推动下,提出了许多基于cnn的pansharpening算法。例如,He等人设计了两个基于细节注入的cnn,它们可以端到端学习细节。此外,Yang等人提出了一种两流网络来增强残差信息,允许不同分辨率之间的信息交换。此外,一些研究还考虑了多尺度特征。如Wang等人提出了一种典型的多尺度深度剩余网络。Zhang 等人利用三维CNN构建多尺度网络来解决光谱失真和空间损耗问题。此外,Gong等人利用ConvLSTM设计了一个多尺度网络,有效地将多尺度信息关联起来。
基于GAN的方法通常包含生成器和鉴别器。通过对抗博弈,基于GAN的方法可以生成高质量的图像来欺骗鉴别器。例如,生成对抗网络(PSGAN)的泛锐化是第一个基于GAN的方法,利用生成的图像和地面实况作为鉴别器的输入。此外,Ma 等人建议的PanGAN。他们用原始图像替换地面真相以实现无监督的泛锐化。最近,学者们相继提出了具有更复杂和合理的网络结构的新型基于GAN的方法,旨在进一步补充空间和光谱信息,例如MDSSC-GAN光谱角映射器(SAM)、DI-GAN等。
尽管对锐化问题给予了极大的关注,但仍有一些问题需要解决。首先,单一大小的面片由于不同的对象类型而不友好的全色锐化。多尺度方法只关注不同的分辨率而忽略了不同的对象,仍然面临着这一挑战。第二,在整体阶段很难实现泛化。第三,损失函数的设计是均匀的,只关注表面。
Knowledge Distillation
知识蒸馏首先是为了满足轻量级网络和一些高级任务的实时实现的需求,如图像重建,图像分类等。具体来说,他们一般设计一个架构复杂的大型教师网络和一个架构简单的小型学生网络。因此,知识蒸馏通过将知识从教师网络转移到学生网络来减少网络参数。Shi等人引入了用于高光谱图像分类的尺度蒸馏。通过将复杂的多尺度教师网络的知识转移到单尺度学生网络,学生网络具有高的分类精度和较少的参数。还存在一些通过输入地面真值来实现蒸馏的方法。例如,Chen等人提出了一种基于蒸馏的低分辨率图像分类。他们输入高分辨率的图像作为教师网络来指导学生网络的学习,从而充分利用高分辨率的信息。
最近,一些研究人员将知识蒸馏应用于泛锐化,以加强对地面事实的约束。例如,Zhou等人提出了一种异构知识蒸馏网络,它模仿了地面实况的重建过程,减少了结果中的伪影。然而,他们只是简单地用地面实况替换了上采样的LRMS图像,而它们的内容有很大的不同,导致网络学习到的特征不一致。此外,Yan等人采用地面实况作为输入来模拟上采样的LRMS图像。在地面真实值的辅助下,模拟图像比原始上采样图像享有更多的有用信息。此外,Zhou等人引入了一个基于异构任务的泛锐化框架。通过约束教师网络和学生网络之间的特征,后者从地面实况接收更全面的信息。到目前为止,虽然知识蒸馏已被广泛用于高层次的任务,知识蒸馏的潜力pansharpening尚未得到充分利用。以前的工作一般提取知识的异构网络或输入,这限制了他们的性能不一致提取的功能。因此,在这项工作中,我们采用知识蒸馏,并寻求类似的输入和相同的网络,这有利于从地面实况引入更精确的信息的结果。
方法
Proposed Network
多面体和多级是我们的网络的两个主要设计。首先,我们将多面体输入到网络中,以利用聚合对象分布。具体而言,我们利用小补丁在早期学习准确的局部信息,并利用大补丁在后期获得整体信息。其次,我们设计了三个阶段,逐步产生详细的HRMS图像。一方面降低了单阶段的难度。另一方面,在不同的阶段设计不同的结构,以平衡原始分辨率和多个分辨率的信息利用。
如图2所示,整体网络包含三个阶段。LRMS图像和PAN图像在每个阶段都可用,以保证源信息的利用。为了将这三个阶段联系起来,我们采用了两种策略。首先,将早期阶段生成的结果直接添加到后期阶段的输入中。其次,为了进一步巩固中间学习过程,我们设计了传输块(TransBlock),将中间信息从早期阶段传输到后期阶段。
前两个阶段专注于多分辨率特征,因此采用了深度反投影网络(DBPN)和U-shaped网络(UNet)结构,因为它们在处理多分辨率信息方面表现出色。在最后一个阶段,我们设计了没有下采样操作的原始分辨率特征块(OFB),旨在保持更多的原始信息。
在阶段1中,采用DBPN作为主要网络组件。较小的补丁被用作在这个阶段中的输入,以减轻不同的对象的干扰。具体地,我们将原始补丁裁剪为四个不重叠的补丁,表示为PANi,LRMSi,{i = 1,2,3,4}。如上所述,小块更有可能包含更少的对象类型,从而更容易学习准确的内核信息。在阶段1的中间部分中,四个特征块
F
1
F^1
F11、
F
2
F^2
F21、
F
3
F^3
F31和
F
4
F^4
F41沿着列级联以形成两个块,写为
F
1
3
F^13
F131和
F
2
4
F^24
F241。下标“1和“2”分别表示来自阶段1和2的贴片。因此,级1的输出包含两个补片(
I
1
I^1
I11和
I
2
I^2
I21),其然后被馈送到级2中。阶段1中的过程可以形式化如下:

重叠拼接是使用图像拼接领域的基本技术来实现的,以避免边界伪影。具体地,给定相同尺寸W × H′的两个图像Ia和Ib,重叠尺寸为W × D。非重叠区域直接拼接,重叠区域采用加权平均策略拼接。对于后一部分,我们认为重叠区域的最左边的线作为基线,如图3中的蓝色虚线所示。对于红色虚线上的像素,我们将到最左边的线的距离表示为d,并且Ia的权重通过下式计算:
在阶段2中,我们利用UNet架构以更多分辨率提取特征。通过TransBlock,第2阶段不仅接收第1阶段的输出,还接收在阶段1中学习的中间特征。编码器的输出
F
1
F^1
F12和
F
2
F^2
F22以与阶段1相同的方式级联以获得单个特征F2。值得注意的是,我们只在相同分辨率的层之间传输信息,以保持有用的信息传输而不丢失。我们将阶段2的过程表示如下:
在阶段3中,在不丢失信息的情况下设计OFB。与之前的过程类似,阶段3接收阶段2的输出和在阶段2中学习的相同分辨率信息。由于两个特征块之前被级联,阶段2和3的输出仅具有一个块,并且后者被认为是最终结果。我们将阶段3正式化如下:
其中Net3表示阶段3的网络,HF2表示阶段2中的高分辨率特征,I3是我们需要的最终HRMS图像。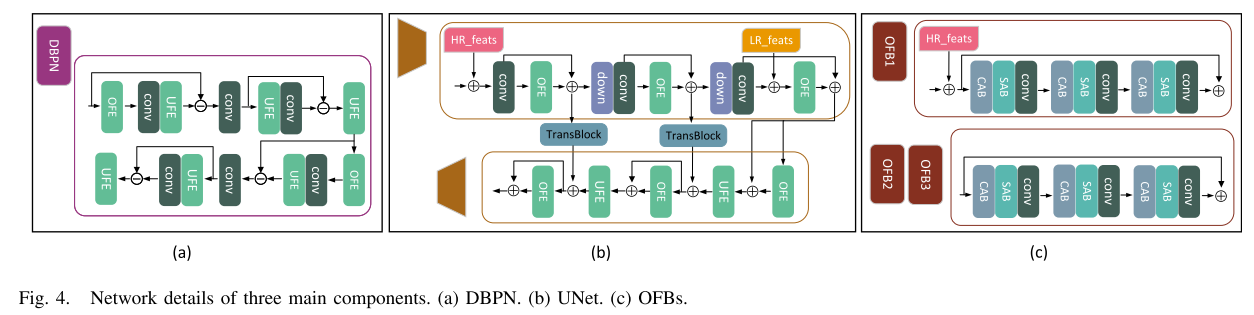
一些基本块的细节显示在图2(c)中。图4中示出了DBPN、UNet和OFB的细节。在每个阶段中,首先使用上采样特征提取器(UFE)或原始特征提取器(OFE)提取特征。随后,级联的特征通过信道注意力块(CAB)和空间注意力块(SAB)以提取注意力特征。然后,它们被馈送到三级的主块(DBPN、UNet和OFB)中。图4(a)-(c)分别表示DBPN、UNet和OFB的网络细节。具体地,如图4(a)所示,DBPN涉及两次轮流的下采样和上采样。通过扩大卷积层中的步幅来实现下采样,并且通过去卷积层来执行上采样。在图4(b)中,Unet的编码器进行两个连续的下采样过程,并且解码器执行对应的上采样过程。使用TransBlock构造编码器和解码器之间的跳过连接。OFB [见图4(c)]由三个连续的CAB和SAB组成,而没有任何上采样或下采样,旨在提取原始分辨率特征。
我们将三级的输出分别表示为I1、I2和I3。基础真值表示为Igt。为了鼓励网络生成接近Igt的理想结果,我们利用L1范数来约束图像级相似性,定义如下: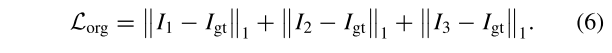
Distillation Learning
为了进一步加强地面实况的指导,我们还引入了特征级损失来约束结果。然而,传统的感知损失严重依赖于其他网络,几乎不涉及自己的设计。相反,我们采用蒸馏损失,这对我们的网络更友好。
具体来说,我们使用一个教师网络,它与学生网络具有相同的架构[见图2(a)]。为了确保教师网络可以学习更强的知识,我们将第二阶段的输入[图中2(a)的黄色阴影对象]替换为第二阶段的输入[图中的黄色阴影对象]。与地面的真相。简化的蒸馏过程如图2(b)所示。尽管教师网络的第一阶段学习的东西并不比学生网络强,但我们仍然保留了它,因为它将信息传输到第二阶段。考虑到第2阶段的原始输入是第1阶段的输出,这接近于真实情况,我们的设计保证了教师网络和学生网络之间一致的网络结构和相似的输入。更明确地,教师网络用以下等式替换(4):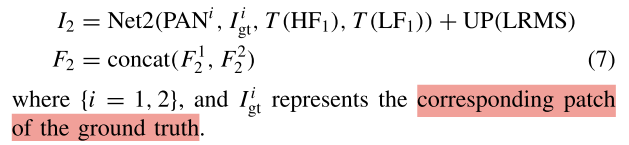
为了构造蒸馏损失,我们将第2阶段和第3阶段中学生网络的最后一层之前的输出限制为与教师网络的输出类似。我们将从学生网络中提取的特征分别表示为阶段2和阶段3的
F
2
F^2
F2org和
F
3
F^3
F3org,并且将教师网络的对应特征表示为
F
2
F^2
F2gt和
F
3
F^3
F3gt。蒸馏损失可以用数学公式表示如下:
最后,总损失函数是原始损失和蒸馏损失的组合,并且其可以写成如下: