概要
表格数据中常见的数据类型是数值型(包括整数、浮点数)和字符型,除了这两种数据,时间类型数据也是常见数据的重要组成部分,同时也是数据分析中极其重要的信息。无论是金融领域的股票交易数据,还是企业注册、吊销的微观数据,时间数据都包含了宝贵的信息,掌握时间数据的处理方法可以帮助我们进行数据清洗、筛选、排序、分析等任务。本期我们就来学习如何在 Pandas 中处理时间类型数据。
本教程基于 pandas 1.5.3 版本书写。本文中所有 Python 代码均在集成开发环境 Visual Studio Code (VScode) 中使用交互式开发环境 Jupyter Notebook 中编写,本文分享的代码请使用 Jupyter Notebook 打开。
数据表中的时间数据
常见的数据中,统计数据中的时间大多是日期数据,当然也有不少数据或分析场景中会出现精确到时、分或秒的时间数据,不过一般这些时间数据都规范地存储在表格的数据列中。在计算机中,一个时间点用时间戳(Timestamp)来表示,采用格林威治时间标准,是指从 1970 年 1 月 1 日 0 时 0 分 0 秒起到当下时间点经过的总秒数,是一个庞大的数字。例如时间戳1690181977就代表北京时间 2023 年 7 月 24 日 14 时 40 分左右(可能会受到时区的影响而出现差异),而我们习惯将时间数据存储成年-月-日或年-月-日 时:分:秒的格式。由于受到数据文件格式的影响,在 pandas 中经常需要主动将字符型时日期据转换为标准的日期类型,否则当需要根据时间进行筛选和分析时,字符型的日期数据很难参与计算,也非常容易出错。
除了时间类型的应用,时间类型数据在转换时也会遇到各种各样的问题,例如日期中可能包含缺失值、异常值等,下面我们就来学习一下如何解决表格数据中的时间类型问题并进行简单的应用。
读取数据时设置类型
常用的数据类型主要是 Excel 工作表和 csv 数据表,其中 Excel 工作表是二进制文件,能够存储数据的类型,如果其中的时间数据已经事先被设置为日期类型,那么使用 Pandas 读取后日期类型会得到保留,不需要再重新设置数据类型。而 csv 数据表是文本文件,虽然也能够被 Excel / WPS 打开,但文本文件不能保存特殊的数据类型,只能存储字符类型的数据。所以如果要读取 csv 数据表并进行处理,则需要在读取过程中或者读取之后做类型转换。例如现在有一份2021年底清洁生产企业(部分样例数据)的成立与注吊销数据(csv 格式),其中两个字段存储日期数据,如下图所示。

读取数据时能够设置初始字段类型的dtype参数,不过这个参数只能设置整数、浮点数、字符串等常见类型,无法设置日期/时间格式数据,如果希望在读取数据时就设置日期类型,可以在使用pd.read_csv()或pd.read_excel()函数时传入参数parse_dates来实现,parse_dates参数可以接收一个列表,将存储日期类型字段的名称存放在这个列表中,就表示 Pandas 在读取数据时会尝试将parse_dates中的字段类型解析为标准类型的日期,演示代码如下。
import pandas as pd
# 先使用常规的读取方式
Table = pd.read_csv('./清洁生产企业数据1000条.csv')
# 查看读取后所有字段的类型
Table.dtypes
'''
企业名称 object
成立日期 object
注(吊)销日期 object
营业状态(2021年底) object
dtype: object
'''
# 常规读取方式读取后日期字段默认是 object,实际上数据类型为字符型,并不会自动解析为日期类型
# 读取时使用 parse_dates 参数,尝试将日期字段转为标准日期类型
Table = pd.read_csv('./清洁生产企业数据1000条.csv',
parse_dates=['成立日期', '注(吊)销日期'])
# 查看读取后所有字段的类型
Table.dtypes
'''
企业名称 object
成立日期 datetime64[ns]
注(吊)销日期 datetime64[ns]
营业状态(2021年底) object
dtype: object
'''
# 使用 parse_dates 参数后,两个存储日期的字段都被解析为标准的日期类型 datetime64[ns]
通过以上代码可以知道,使用pd.read_csv()或pd.read_excel()函数时,设置parse_dates参数可以有效地将原本是字符型的日期设置为标准日期类型。不过这样做并不一定会成功,这是因为parse_dates参数的含义是尝试性地将传入的字段解析为标准日期,如果传入的字段中包含不能被转换为标准日期的其他数据,例如数字、非日期格式的字符串,那么这个字段就不会被成功地解析为标准日期,依然保持原来的字段类型。
处理数据时转换为标准日期
如上文所述,在读取数据时通过设置参数可以帮助我们规范数据类型,但那种方式还不能帮我们解决全部的类型问题,例如字段中存在异常值时就无法被解析为标准日期类型。此外,当需要从其他格式的数据文件中读取,或者数据处理中途产生日期字段时,上述方法就不能使用了,此时我们就需要掌握将字符型日期转为标准日期的方式。我们在往期文章Pandas 表格字段类型精讲(含类型转换)中介绍过字段类型转换的操作方式,以上文中读取的演示数据为例,我们再次演示如何将字符型日期转为标准的日期类型,代码如下。
# 不使用 parse_dates 参数,读取后再主动转换类型
Table = pd.read_csv('./清洁生产企业数据1000条.csv')
# 使用两种不同的方式将两个字段转为标准日期类型
Table['成立日期'] = Table['成立日期'].astype('datetime64[ns]') # 方式 1,使用 Series.astype() 函数
Table['注(吊)销日期'] = pd.to_datetime(Table['注(吊)销日期']) # 方式 2,使用 pd.to_datetime() 函数
# 查看转换类型后的数据
Table
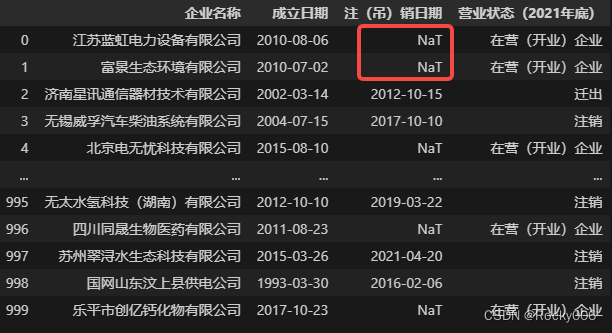
如上图所示,字段注(吊)销日期中存在空值,该字段中的空值表示企业的死亡日期(截至 2021 年底),没有死亡的企业不存在注吊销日期。经过转换后,数据中的空值NaN变为NaT,NaT(not a time)是 Pandas 中的时间空值,可以被表示为 pd.NaT,我们可以把它理解为一个不表示任何时间点的时间数据,同时,任何时间点与NaT进行比较和计算都会得到 False,这一点和NaN(np.NaN)非常相似。
有的数据中可能会包含异常的日期数据,比如010-08-06、2010-13-02、2002-2-30,类似的异常数据会给我们的数据处理带来非常多的麻烦。这里我们手动将演示数据中的几个日期修改为异常日期,生成一个含有异常日期的数据副本,接下来将会演示如何识别和处理异常的日期数据。
## 异常日期存储在 成立日期 字段中的前三年行
# 读取含有异常日期的数据
Table = pd.read_csv('./清洁生产企业数据1000条_ERROR.csv',
parse_dates=['成立日期', '注(吊)销日期'])
# 查看读取后所有字段的类型
Table.dtypes
'''
企业名称 object
成立日期 object
注(吊)销日期 datetime64[ns]
营业状态(2021年底) object
dtype: object
'''
# 如上文所述,当字段中存在异常的日期数据时,即使使用 parse_dates 参数指定了该字段,也不会有实际效果
Table # 查看数据
Pandas 中默认的时间/日期类型是由pd.Timestamp()函数转换的来的,该函数能够表示的时间范围是1678-01-01 00:00:00——2262-04-11 23:47:16,因此不在此时段内的时间数据都会被视作异常值。而 Python 中的标准库datetime下的datetime.datetime()函数也可以进行时间/日期转换,支持的时间范围是0001-01-01 00:00:00——9999-12-31 23:59:59(注意即使是公元 1 年,也必须是四位数字)。无论使用哪种方式,都不允许出现 13 月、2 月 30 日这种绝对错误的日期。
当数据中出现异常的日期数据时,设置parse_dates参数来解析日期字段的方式不再奏效,但依然可以通过 Pandas 的类型转换函数来处理,即使用Series.astype()或pd.to_datetime()函数来实现。但是如果继续像上文中那样直接进行类型转换也会报错,因为默认的转换方式是将字段中的每一个值都转为日期类型,由于字段中包含错误的日期,所以转换时会报错。这时我们可以借助pd.to_datetime()函数中用于控制解析错误处理方式的参数errors来达到目的,示范代码如下。
# 使用 pd.to_datetime 转换日期时,设置参数 errors='coerce',
# 表示类型转换过程中将错误的时间替换为时间空值 NaT
Table['成立日期'] = pd.to_datetime(Table['成立日期'], errors='coerce')
# 查看错误的时间(前三行都是错误的时间)转换后的结果
print(Table['成立日期'][1]) # NaT (空时间类型)
# 查看正确的时间转换后的结果
print(Table['成立日期'][100]) # 2014-04-25 00:00:00 (正常时间类型)
在专门用来将字符日期字段转换为标准日期类型字段pd.to_datetime()函数中,参数errors的作用是控制函数在遇到异常日期(包括错误日期和规定范围之外的日期)时的处置方法,它的默认值是'raise',表示遇到异常日期时报错;也可以设置为'ignore',表示尝试性地将字段设置为日期类型,如果字段中包含异常日期,那么转换不会成功,但也不会报错,注意'ignore'的机制不是将正确的日期转换以及保留异常的日期,而是出现异常日期时不会对字段内任何日期做转换;上述代码使用的参数值为'coerce',这是pd.to_datetime()函数中errors参数独有的可选值(astype()函数也有errors参数,但没有'coerce'选项),表示类型转换过程中将错误的时间替换为时间空值NaT。了解这个机制更有助于我们选择是否使用该参数值,避免数据丢失。
如果你的数据中包含1678年之前或2262之后的日期,那么这就跳出了 Pandas 默认能够接受的时间范围,出现这种情况时,我们可以放弃使用 Pandas 提供的日期转换函数,改用标准库 datetime 中的函数进行日期转换,当然这可能比较麻烦。老规矩,我们先将成立日期字段中前三行数据修改为不受 Pandas 支持的日期,当然这样修改后的数据不符合数据逻辑和真实性,但我们只是为了演
示操作方式而已,代码如下。
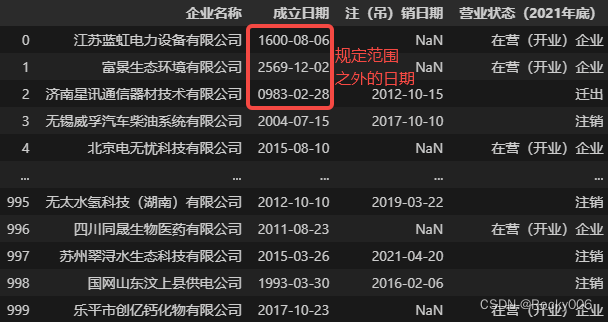
# 先读取含有规定范围之外日期的数据,注意年份一定得是四位数字
Table = pd.read_csv('./清洁生产企业数据1000条_OUT.csv')
Table # 查看数据,此时成立日期字段为字符型
# 将日期转换为 datetime 库中的日期类型
from datetime import datetime
# 定义日期转换函数
def Transform_date(str_date):
# 要求是 year-month-day 格式的日期,也可根据具体数据做调整
date = datetime.strptime(str_date, '%Y-%m-%d')
return date
# 应用上面定义的日期转换函数进行类型转换
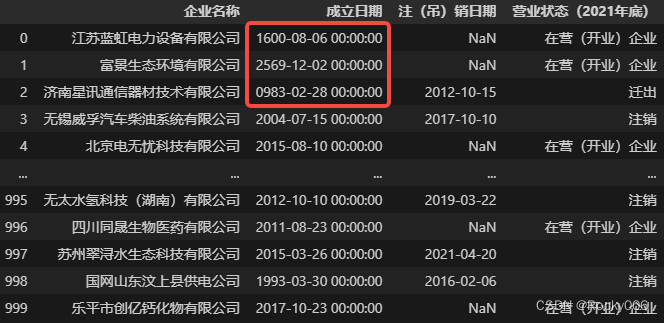
Table['成立日期'] = Table['成立日期'].apply(Transform_date)
# 查看转换后字段内数据值的类型
print(type(Table['成立日期'][2])) # <class 'datetime.datetime'>
print(type(Table['成立日期'][10])) # <class 'datetime.datetime'>
# 转换后字段类型仍未 object,但是内部的数据已经被转为标准的日期,可以正常地进行排序、筛选、分析等操作
Table # 最后查看数据
表格中日期类型的基本使用
1根据日期排序
结构化数据的基本分析中,当涉及到日期数据时,在转换为标准日期类型之后就可以方便地进行筛选排序等操作了。例如可以根据成立日期对数据做降序排序,代码如下。
# 默认升序排序,ascending=False 表示降序
Table_sort = Table.sort_values(by='成立日期', ascending=False)
Table_sort

2根据日期筛选
当然也可以根据日期筛选出符合要求的数据,例如可以筛选出成立日期在 2000 年 10 月 1 日 之前的企业数据,不过这样做需要先创建一个时间点/日期,然后才可以和数据中的成立日期进行对比。在 Python 中创建时间点非常简单,这里介绍两种方式,代码如下。
# 创建时间点/日期的两种方式
# 方式 1,使用 pd.Timestamp() 函数
date1 = pd.Timestamp(2000, 10, 1)
print(date1) # 2000-10-01 00:00:00
# 方式 2,使用 datetime.datetime() 创建
from datetime import datetime # 实际上上文已经导入
date2 = datetime(2000, 10, 1)
print(date2) # 2000-10-01 00:00:00
虽然两种方式创建的日期类型不是同一标准,但是相互之间仍可以进行正常的比较和运算。无论哪种日期类型数据,都有以下几个通用的属性,通过属性我们可以从日期中取出对应的信息,有时根据这些信息就可以进行基本的处理和分析,下面是时间/日期类型常见的属性。
## 时间/日期类型的常见属性
# 先创建时间点:2000 年 10 月 1 日 中午 12 时 30 分 59 秒
date3 = pd.Timestamp(2000, 10, 1, 12, 30, 59)
# 年 属性
print(date3.year) # 2000
# 月 属性
print(date3.month) # 10
# 日 属性
print(date3.day) # 1
# 小时 属性
print(date3.hour) # 12
# 分钟 属性
print(date3.minute) # 30
# 秒 属性
print(date3.second) # 59
# 周几
print(date3.dayofweek) # 6
# 该年第几周
print(date3.weekofyear) # 39
# 该年的第几天
print(date3.dayofyear) # 275
# 当年是否闰年
print(date3.is_leap_year) # True
# 当月总天数
print(date3.days_in_month) # 31
# 哪个季度
print(date3.quarter) # 4
时间点创建后,可以开始筛选数据了,筛选的代码如下。
# 筛选出成立日期在 2000 年 10 月 1 日 之前的企业数据
date1 = pd.Timestamp(2000, 10, 1)
# 开始筛选
Table_before2000 = Table[Table['成立日期'] < date1]
Table_before2000 # 查看筛选结果
3时长数据计算
除了时间的排序和筛选,Pandas 还提供了比较有特色的时间差类型数据值,可以满足我们更加多元的数据分析。例如当分析样例数据中企业的平均存活时间就需要用到时间差(时长)数据,两个日期之间可以进行比较和相减,比较会得到比较结果 True 或 False;而相减则会得到一个时长数据,这个时长数据以日、时、分、秒为单位,为什么不是以年、月来做单位呢,这样不是更方便分析计算吗?实际上这是因为一年或一月的时长是不固定的,存在闰年、闰月的现象。下面是演示代码。
## 先创建两个时间点
date3 = pd.Timestamp(2000, 10, 1, 12, 30, 59)
date4 = pd.Timestamp('now') # 当前时间点:2023-07-26 11:24:58
# 计算时间差,得到时长数据
timedelta = date4 - date3
# 查看时间差
timedelta # Timedelta('8332 days 22:53:59')
也可以直接根据字段进行计算,例如注(吊)销日期字段与成立时间字段相减就可以得到一个正值时长数据,反之将得到负值时长数据,下面是计算企业存活时长的代码。
# 读取时正确的样例数据(不存在脏数据的)
Table = pd.read_csv('./清洁生产企业数据1000条.csv', parse_dates=['成立日期', '注(吊)销日期'])
# 在合适的位置插入一列空值
Table.insert(3, '存活时间', '')
# 将两个字段做差,得到的序列赋值给刚刚创建的新字段
Table['存活时间'] = Table['注(吊)销日期'] - Table['成立日期']
Table # 查看数据
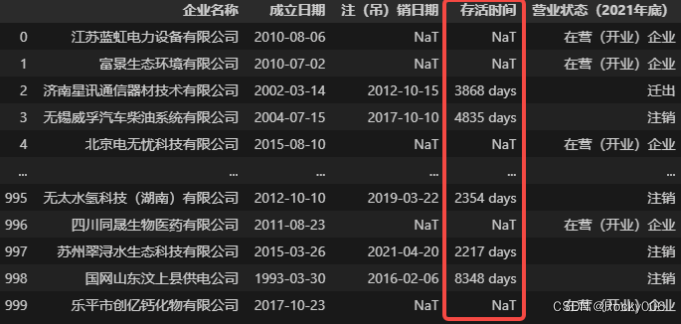
数据中未死亡企业的注(吊)销日期为空,这是正常现象,此处的计算也可以佐证上文的描述,即空日期 NaT 与任何日期数据进行计算都会得到 NaT 本身。运算后就可以得到每个企业的存活时间,进而分析样例数据中企业的平均存活时间了,分析代码如下。
# 先检验是否存在异常数据,即存活时间为 0 或负值的
Error_data = Table[Table['存活时间'] <= pd.Timedelta(0)]
Error_data

发现其中三条数据注册当天就注吊销了,这里我们将其视作脏数据进行清除。
# Error_data.index 表示脏数据 Error_data 的索引值
Table.drop(Error_data.index, inplace=True)
最后在计算企业的平均存活时间。
import datetime # 导入 datetime 库用于做时长转换
# 先筛选出存活时长不为空的数据,即已经死亡的企业,且不是异常值的
Dead_data = Table[Table['存活时间'].notna()]
# 所有死亡企业的存活时长转为以秒为单位的时长,然后加总,
TimeSeries = Dead_data['存活时间'].dt.total_seconds()
Total_seconds = TimeSeries.sum()
# 再换算成以天为单位的时长,因为 pd.Timestamp() 支持的时长太小了,所以才转换
Total_days = datetime.timedelta(seconds=Total_seconds)
# 再除以企业数量,得到平均存活时长
Mean_survival_time = Total_days / Dead_data.shape[0]
Mean_survival_time # datetime.timedelta(days=3814, seconds=69189, microseconds=537223)
最后计算出样例数据中 497 个清洁生产企业(已经死亡的)的平均存活时间约为 3814 天,按一年 365 天计算,每个企业的平均存活时间为 10.4 年。
通过以上代码我们也可以知道,可以使用pd.Timedelta()函数来创建时长数据,例如pd.Timedelta(0)就表示时长为 0 的时长数据,使用pd.Timedelta()创建时长数据的基本用法如下。
# pd.Timedelta()创建时长数据的基本用法
# 一天
pd.Timedelta('1D') # Timedelta('1 days 00:00:00')
# 两周
pd.Timedelta('2W') # Timedelta('14 days 00:00:00')
# 3天4小时5分钟6秒
pd.Timedelta('3d4h5m6s') # Timedelta('3 days 04:05:06')
同时,时长数据也可以进行加、减、乘、除等基础运算,不过 Pandas 支持的运算范围很小,所以上文中的代码在计算时长时先将以天为最大单位的 pd.Timedelta 数据转换为以秒为单位的 datetime.timedelta 数据后才得以进行下去。
以上就是本期文章介绍的所有关于日期/时间数据的基本处理方式啦。
总结
本期文章介绍了 Pandas 中处理日期数据的方法,包括数据类型的解析与转换,日期类型的排序、筛选、计算等方法。在 Pandas 中,无论是日期的范围,还是时长的范围都还不够大,当默认的范围无法解决问题时,最好要学会使用 Python 标准库 datetime 来做补充。常见的面板数据中,日期或时间是非常重要的信息,掌握日期类型的转换和用法是每一个数据人必备的基本技能。