文章目录
- 1. rotated_fcos_head.py
- 1.1 __init__函数
- 1.2 forward_single 函数
- 1.2.1 父类的forward_single 函数(anchor_free_head.py)
- 1.2.2 _init_layers 函数
- 1.3 loss 函数
- 1.3.1 get_targets 函数
- 1.3.1.1 _get_target_single 函数
- 1.3.2 prior_generator.grid_priors函数
- 1.3.2.1 single_level_grid_priors函数
1. rotated_fcos_head.py
1.1 __init__函数
这个是FCSO的初始化类
def __init__(self,
num_classes,
in_channels,
regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),
(512, INF)),
center_sampling=False,
center_sample_radius=1.5,
norm_on_bbox=False,
centerness_on_reg=False,
separate_angle=False,
scale_angle=True,
h_bbox_coder=dict(type='DistancePointBBoxCoder'),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='IoULoss', loss_weight=1.0),
loss_angle=dict(type='L1Loss', loss_weight=1.0),
loss_centerness=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
norm_cfg=dict(type='GN', num_groups=32, requires_grad=True),
init_cfg=dict(
type='Normal',
layer='Conv2d',
std=0.01,
override=dict(
type='Normal',
name='conv_cls',
std=0.01,
bias_prob=0.01)),
**kwargs):
self.regress_ranges = regress_ranges
self.center_sampling = center_sampling
self.center_sample_radius = center_sample_radius
self.norm_on_bbox = norm_on_bbox
self.centerness_on_reg = centerness_on_reg
self.separate_angle = separate_angle
self.is_scale_angle = scale_angle
super().__init__(
num_classes,
in_channels,
loss_cls=loss_cls,
loss_bbox=loss_bbox,
norm_cfg=norm_cfg,
init_cfg=init_cfg,
**kwargs)
self.loss_centerness = build_loss(loss_centerness)
if self.separate_angle:
self.loss_angle = build_loss(loss_angle)
self.h_bbox_coder = build_bbox_coder(h_bbox_coder)
num_classes(int):目标类别的数量。
in_channels(int):输入特征图的通道数。
regress_ranges(tuple of tuples):定义不同级别的回归范围。每个元组表示一个回归范围的上下限。
center_sampling(bool):是否在计算目标时对中心进行采样。
center_sample_radius(float):中心采样的半径。
norm_on_bbox(bool):是否在归一化回归目标时考虑缩放因子。
centerness_on_reg(bool):是否将中心度应用于回归。
separate_angle(bool):是否在预测目标角度时进行分离。
scale_angle(bool):是否缩放角度预测。
h_bbox_coder(dict):边界框编码器的配置。
loss_cls(dict):分类损失函数的配置。
loss_bbox(dict):回归损失函数的配置。
loss_angle(dict):角度损失函数的配置(如果 separate_angle 为真)。
loss_centerness(dict):中心度损失函数的配置。
norm_cfg(dict):归一化的配置。
init_cfg(dict):初始化的配置。
kwargs:额外的关键字参数。
1.2 forward_single 函数
# 通过调用父类的 'forward_single' 方法来获取类别得分,边界框预测和分类回归特征
cls_score, bbox_pred, cls_feat, reg_feat = super().forward_single(x) 详见1.2.1

# 检查是否使用中心度计算在回归特征或分类特征上
if self.centerness_on_reg:
centerness = self.conv_centerness(reg_feat) 默认
else:
centerness = self.conv_centerness(cls_feat) 详见1.2.2

# 使用提供的 'scale' 模块对不同级别的边界框预测进行调整并转换为浮点数
bbox_pred = scale(bbox_pred).float()
if self.norm_on_bbox:
# 如果 self.norm_on_bbox 为 True,则对 bbox_pred 进行调整
将所有小于0的值设置为0。这个操作确保边界框的坐标预测不会出现负值
bbox_pred = bbox_pred.clamp(min=0)
# 如果不处于训练模式下,根据步长对 bbox_pred 进行调整
if not self.training:
bbox_pred *= stride
else:
# 如果 self.norm_on_bbox 为 False,则对 bbox_pred 进行指数函数处理
bbox_pred = bbox_pred.exp()

# 使用 'conv_angle' 层计算角度的预测
angle_pred = self.conv_angle(reg_feat) 详见1.2.2
if self.is_scale_angle: 详见1.2.2
# 如果 self.is_scale_angle 为 True,则对角度预测进行缩放处理
angle_pred = self.scale_angle(angle_pred).float()
# 返回类别得分,边界框预测,角度预测和中心度预测
return cls_score, bbox_pred, angle_pred, centerness

1.2.1 父类的forward_single 函数(anchor_free_head.py)

def forward_single(self, x):
"""处理单个尺度级别的特征图的前向传播。
Args:
x (Tensor): 指定尺度级别的FPN特征图。
Returns:
tuple: 每个类别的得分,边界框预测,经过分类和回归卷积层后的特征图,
某些模型(例如FCOS)需要这些特征图。
"""
# 将输入特征图用于分类和回归特征
cls_feat = x
reg_feat = x
# 通过遍历分类卷积层对分类特征进行前向传播
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
# 使用 'conv_cls' 层计算类别得分
cls_score = self.conv_cls(cls_feat)
# 通过遍历回归卷积层对回归特征进行前向传播
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)
# 使用 'conv_reg' 层计算边界框预测
bbox_pred = self.conv_reg(reg_feat)
# 返回类别得分,边界框预测,分类特征和回归特征
return cls_score, bbox_pred, cls_feat, reg_feat

1.2.2 _init_layers 函数
def _init_layers(self):
"""Initialize layers of the head."""
super()._init_layers()
self.conv_centerness = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.conv_angle = nn.Conv2d(self.feat_channels, 1, 3, padding=1)
self.scales = nn.ModuleList([Scale(1.0) for _ in self.strides])
if self.is_scale_angle:
self.scale_angle = Scale(1.0)
1.3 loss 函数
def loss(self,
cls_scores,
bbox_preds,
angle_preds,
centernesses,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
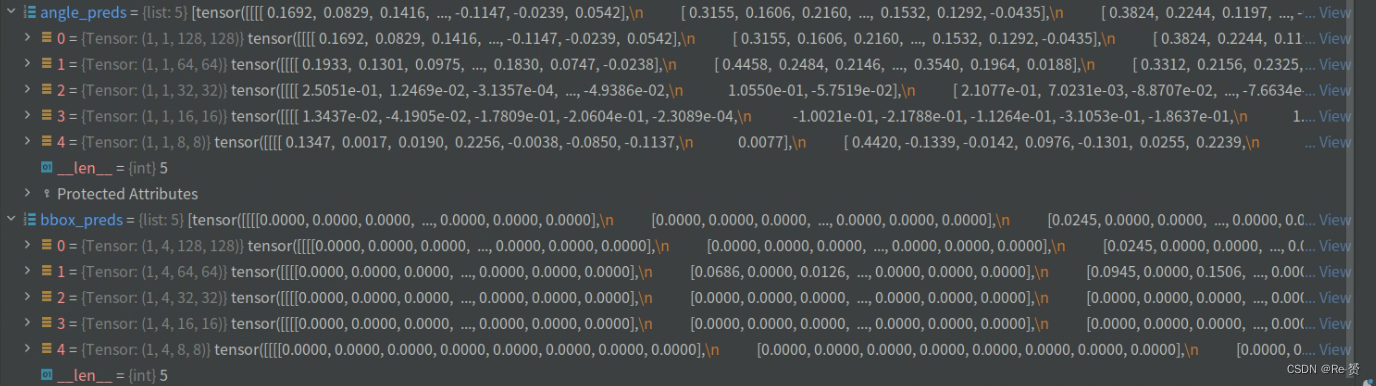
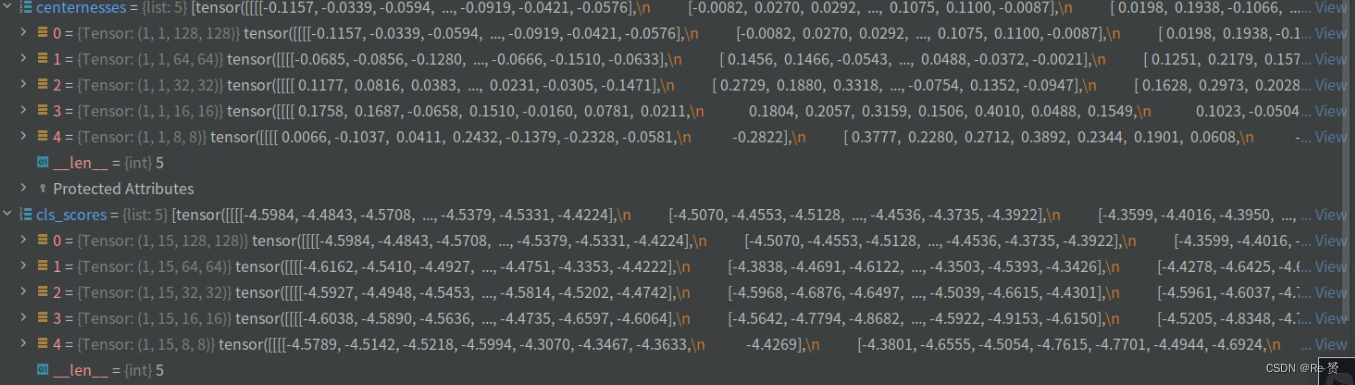

assert len(cls_scores) == len(bbox_preds) \
== len(angle_preds) == len(centernesses)
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
使用断言来确保所有的预测结果张量(cls_scores、bbox_preds、angle_preds 和 centernesses)具有相同的长度
算了每个特征层的空间尺寸(高度和宽度)。featmap_sizes 是一个列表,其中包含了每个特征层的尺寸。

all_level_points = self.prior_generator.grid_priors(
featmap_sizes,
dtype=bbox_preds[0].dtype,
device=bbox_preds[0].device)
使用 self.prior_generator 的 grid_priors 方法,根据特征层的尺寸生成一组先验框的坐标

labels, bbox_targets, angle_targets = self.get_targets(
all_level_points, gt_bboxes, gt_labels)
调用了 self.get_targets 方法,根据生成的先验框坐标、真实边界框和真实标签来计算分类、边界框和角度的目标。



num_imgs = cls_scores[0].size(0)
取了输入张量中的图片数量
flatten_cls_scores = [
cls_score.permute(0, 2, 3, 1).reshape(-1, self.cls_out_channels)
for cls_score in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
for bbox_pred in bbox_preds
]
flatten_angle_preds = [
angle_pred.permute(0, 2, 3, 1).reshape(-1, 1)
for angle_pred in angle_preds
]
flatten_centerness = [
centerness.permute(0, 2, 3, 1).reshape(-1)
for centerness in centernesses
]
将每个特征图的分类得分、边界框预测、角度预测和中心度预测展平
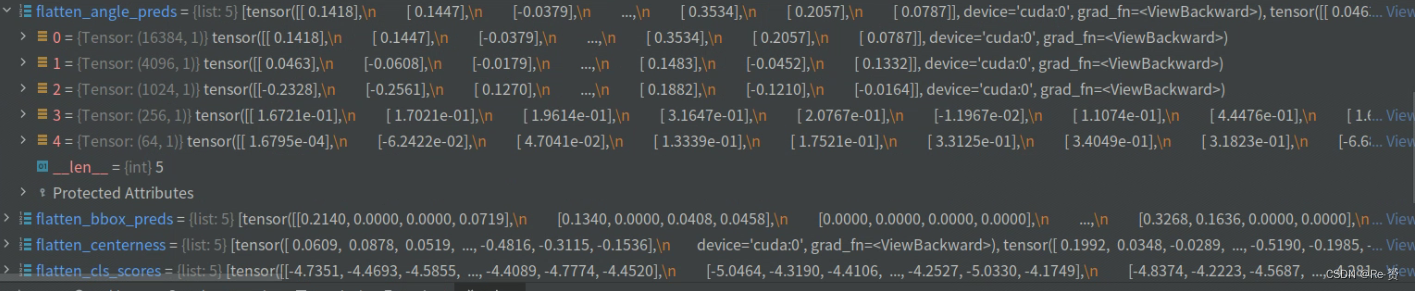


flatten_cls_scores = torch.cat(flatten_cls_scores)
flatten_bbox_preds = torch.cat(flatten_bbox_preds)
flatten_angle_preds = torch.cat(flatten_angle_preds)
flatten_centerness = torch.cat(flatten_centerness)
将前面得到的展平后的张量列表通过 torch.cat 操作进行连接,得到完整的展平后的张量。

flatten_labels = torch.cat(labels)
flatten_bbox_targets = torch.cat(bbox_targets)
flatten_angle_targets = torch.cat(angle_targets)
将分类标签、边界框目标和角度目标也展平为一维张量
flatten_points = torch.cat(
[points.repeat(num_imgs, 1) for points in all_level_points])
将每个特征层上的先验框坐标 all_level_points 重复 num_imgs 次,从而使得坐标与之前展平的结果 flatten_bbox_preds 对齐
bg_class_ind = self.num_classes
将背景类的索引设置为 num_classes
pos_inds = ((flatten_labels >= 0)
& (flatten_labels < bg_class_ind)).nonzero().reshape(-1)
用于获取正样本的索引
num_pos = torch.tensor(
len(pos_inds), dtype=torch.float, device=bbox_preds[0].device)
num_pos = max(reduce_mean(num_pos), 1.0)
计算了正样本的数量,并且将其转换为张量 num_pos,后使用 reduce_mean 函数来计算正样本数量的平均值,并使用 max 函数确保这个平均值至少为1.0。

loss_cls = self.loss_cls(
flatten_cls_scores, flatten_labels, avg_factor=num_pos)
使用分类损失函数 self.loss_cls 来计算分类损失

pos_bbox_preds = flatten_bbox_preds[pos_inds]
pos_angle_preds = flatten_angle_preds[pos_inds]
pos_centerness = flatten_centerness[pos_inds]
pos_bbox_targets = flatten_bbox_targets[pos_inds]
pos_angle_targets = flatten_angle_targets[pos_inds]
pos_centerness_targets = self.centerness_target(pos_bbox_targets)
通过索引 pos_inds 从之前展平的张量中提取了正样本对应的
边界框预测、角度预测、中心度预测、边界框目标、角度目标和中心度目标
centerness_denorm = max(
reduce_mean(pos_centerness_targets.sum().detach()), 1e-6)
计算了正样本的中心度目标之和,并通过 reduce_mean 函数计算平均值。然后使用 max 函数确保分母至少为1e-6


if len(pos_inds) > 0:
# 如果存在正样本
pos_points = flatten_points[pos_inds]
# 从所有点坐标中提取正样本的点坐标
if self.separate_angle:
# 如果模型设置了分离角度
bbox_coder = self.h_bbox_coder
# 使用分离角度的边界框编码器
else:
bbox_coder = self.bbox_coder
# 否则使用常规边界框编码器
pos_bbox_preds = torch.cat([pos_bbox_preds, pos_angle_preds],
dim=-1)
pos_bbox_targets = torch.cat(
[pos_bbox_targets, pos_angle_targets], dim=-1)
# 如果不分离角度,则将边界框预测和角度预测在最后一个维度上连接,
# 并将边界框目标和角度目标连接起来


pos_decoded_bbox_preds = bbox_coder.decode(pos_points,
pos_bbox_preds)
pos_decoded_target_preds = bbox_coder.decode(
pos_points, pos_bbox_targets)
# 使用边界框编码器解码正样本的边界框预测和目标

loss_bbox = self.loss_bbox(
pos_decoded_bbox_preds,
pos_decoded_target_preds,
weight=pos_centerness_targets,
avg_factor=centerness_denorm)
# 计算边界框损失,使用解码后的边界框预测和目标值,
# 并根据中心度目标值进行加权平均
if self.separate_angle:
loss_angle = self.loss_angle(
pos_angle_preds, pos_angle_targets, avg_factor=num_pos)
# 如果分离角度,计算角度损失
loss_centerness = self.loss_centerness(
pos_centerness, pos_centerness_targets, avg_factor=num_pos)
# 计算中心度损失

else:
# 如果没有正样本
loss_bbox = pos_bbox_preds.sum()
# 边界框损失设置为边界框预测值的和
loss_centerness = pos_centerness.sum()
# 中心度损失设置为中心度预测值的和
if self.separate_angle:
loss_angle = pos_angle_preds.sum()
# 如果分离角度,角度损失设置为角度预测值的和
if self.separate_angle:
return dict(
loss_cls=loss_cls,
loss_bbox=loss_bbox,
loss_angle=loss_angle,
loss_centerness=loss_centerness)
else:
return dict(
loss_cls=loss_cls,
loss_bbox=loss_bbox,
loss_centerness=loss_centerness)
1.3.1 get_targets 函数
def get_targets(self, points, gt_bboxes_list, gt_labels_list):
"""Compute regression, classification and centerness targets for points
in multiple images.
Args:
points (list[Tensor]): Points of each fpn level, each has shape
(num_points, 2).
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image,
each has shape (num_gt, 4).
gt_labels_list (list[Tensor]): Ground truth labels of each box,
each has shape (num_gt,).
Returns:
tuple:
concat_lvl_labels (list[Tensor]): Labels of each level. \
concat_lvl_bbox_targets (list[Tensor]): BBox targets of each \
level.
concat_lvl_angle_targets (list[Tensor]): Angle targets of \
each level.
"""

assert len(points) == len(self.regress_ranges)
num_levels = len(points)
# 将回归范围扩展以与点对齐,points[i].new_tensor(self.regress_ranges[i]) 创建一个与 points[i] 具有相同数据类型和设备的新张量,其值为 self.regress_ranges[i]
expanded_regress_ranges = [
points[i].new_tensor(self.regress_ranges[i])[None].expand_as(
points[i]) for i in range(num_levels)
]

# 连接所有级别的点和回归范围
concat_regress_ranges = torch.cat(expanded_regress_ranges, dim=0)
concat_points = torch.cat(points, dim=0)
#num_points 列表中存储了每个级别中的点的数量
num_points = [center.size(0) for center in points]


labels_list, bbox_targets_list, angle_targets_list = multi_apply( 详见1.3.1.1
self._get_target_single,
gt_bboxes_list,
gt_labels_list,
points=concat_points,
regress_ranges=concat_regress_ranges,
num_points_per_lvl=num_points)
将 _get_target_single 方法应用到多个图像上,以计算每个图像中的回归、分类和角度目标
gt_bboxes_list 是一个列表,每个元素是一个张量,表示一个图像中的真实边界框。
gt_labels_list 是一个列表,每个元素是一个张量,表示一个图像中的真实类别标签。
concat_points 是一个张量,表示连接所有级别的点。
concat_regress_ranges 是一个张量,表示连接所有级别的回归范围。
num_points_per_lvl 是一个列表,每个元素表示每个级别中点的数量。


# 将目标分割为每个图像的每个级别
labels_list = [labels.split(num_points, 0) for labels in labels_list]
bbox_targets_list = [
bbox_targets.split(num_points, 0)
for bbox_targets in bbox_targets_list
]
angle_targets_list = [
angle_targets.split(num_points, 0)
for angle_targets in angle_targets_list
]



# 连接每个级别中每个图像的目标
concat_lvl_labels = []
concat_lvl_bbox_targets = []
concat_lvl_angle_targets = []
for i in range(num_levels):
concat_lvl_labels.append(
torch.cat([labels[i] for labels in labels_list]))
bbox_targets = torch.cat(
[bbox_targets[i] for bbox_targets in bbox_targets_list])
angle_targets = torch.cat(
[angle_targets[i] for angle_targets in angle_targets_list])
if self.norm_on_bbox:
bbox_targets = bbox_targets / self.strides[i]
concat_lvl_bbox_targets.append(bbox_targets)
concat_lvl_angle_targets.append(angle_targets)
# 返回包含连接后的每个级别的分类标签、回归目标和角度目标的元组
return (concat_lvl_labels, concat_lvl_bbox_targets, concat_lvl_angle_targets)



1.3.1.1 _get_target_single 函数
def _get_target_single(self, gt_bboxes, gt_labels, points, regress_ranges,
num_points_per_lvl):
"""Compute regression, classification and angle targets for a single
image."""

# 获取当前级别的点数和ground truth框数
num_points = points.size(0)
num_gts = gt_labels.size(0)
# 如果没有ground truth框,返回全零的分类标签、回归目标和角度目标
if num_gts == 0:
return gt_labels.new_full((num_points,), self.num_classes), \
gt_bboxes.new_zeros((num_points, 4)), \
gt_bboxes.new_zeros((num_points, 1))

# 计算ground truth框的面积
areas = gt_bboxes[:, 2] * gt_bboxes[:, 3]
# 将面积扩展为和点数一致的形状
areas = areas[None].repeat(num_points, 1)

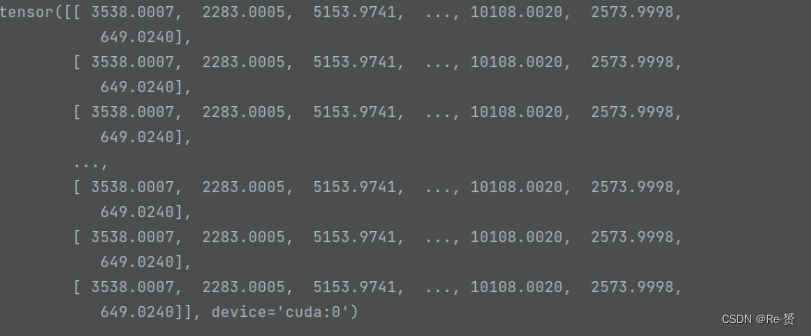
# 扩展回归范围,使其和点数、ground truth框数一致
regress_ranges = regress_ranges[:, None, :].expand(
num_points, num_gts, 2)
# 扩展points,使其和点数、ground truth框数一致
points = points[:, None, :].expand(num_points, num_gts, 2)
# 扩展gt_bboxes,使其和点数、ground truth框数一致
gt_bboxes = gt_bboxes[None].expand(num_points, num_gts, 5)


# 分别获取ground truth框的中心点、宽高和角度信息
gt_ctr, gt_wh, gt_angle = torch.split(gt_bboxes, [2, 2, 1], dim=2)
# 计算cos和sin角度值
cos_angle, sin_angle = torch.cos(gt_angle), torch.sin(gt_angle)
# 构建旋转矩阵
rot_matrix = torch.cat([cos_angle, sin_angle, -sin_angle, cos_angle],
dim=-1).reshape(num_points, num_gts, 2, 2)




# 计算点到中心点的偏移,并在旋转矩阵的作用下,得到相对于中心点的偏移
offset = points - gt_ctr
offset = torch.matmul(rot_matrix, offset[..., None])
offset = offset.squeeze(-1)

# 获取宽和高信息
w, h = gt_wh[..., 0], gt_wh[..., 1]
# 获取x和y方向上的偏移
offset_x, offset_y = offset[..., 0], offset[..., 1]
# 计算回归目标的左、右、上、下边界值
left = w / 2 + offset_x
right = w / 2 - offset_x
top = h / 2 + offset_y
bottom = h / 2 - offset_y
# 将左、右、上、下边界值拼接成一个张量
bbox_targets = torch.stack((left, top, right, bottom), -1)




# 判断每个点是否在ground truth框内部
inside_gt_bbox_mask = bbox_targets.min(-1)[0] > 0

#检查模型是否启用了中心采样
创建一个形状与偏移量(offset)相同的全零张量
将预定义的中心采样半径赋值给变量radiu
if self.center_sampling:
# condition1: 判断是否在中心区域内
radius = self.center_sample_radius
stride = offset.new_zeros(offset.shape)
# 通过循环遍历每个层级的索引(lvl_idx)以及每个层级的点数
计算当前层级的终止索引
将当前层级内的点的偏移设置为当前层级的步幅(stride)乘以中心采样半径
将终止索引更新为下一个层级的起始索引,以便继续迭代下一个层级
lvl_begin = 0
for lvl_idx, num_points_lvl in enumerate(num_points_per_lvl):
lvl_end = lvl_begin + num_points_lvl
stride[lvl_begin:lvl_end] = self.strides[lvl_idx] * radius
lvl_begin = lvl_end


# 判断是否在中心框内
inside_center_bbox_mask = (abs(offset) < stride).all(dim=-1)
# 将中心框内的点同时满足在ground truth框内
inside_gt_bbox_mask = torch.logical_and(inside_center_bbox_mask,
inside_gt_bbox_mask)

# condition2: 限制每个位置的回归范围
计算每个点的预测回归距离中的最大值
根据预定义的回归范围,生成一个布尔张量inside_regress_range
max_regress_distance = bbox_targets.max(-1)[0]
inside_regress_range = (
(max_regress_distance >= regress_ranges[..., 0])
& (max_regress_distance <= regress_ranges[..., 1]))


# 对于一个位置仍然有多个对象的情况,
# 我们选择面积最小的一个对象作为目标
areas[inside_gt_bbox_mask == 0] = INF
areas[inside_regress_range == 0] = INF
min_area, min_area_inds = areas.min(dim=1)

# 获取每个点的标签
labels = gt_labels[min_area_inds]
# 如果最小面积为INF,将其标签设为背景类别
labels[min_area == INF] = self.num_classes
# 获取每个点的回归目标
bbox_targets = bbox_targets[range(num_points), min_area_inds]
# 获取每个点的角度目标
angle_targets = gt_angle[range(num_points), min_area_inds]
# 返回每个点的标签、回归目标和角度目标
return labels, bbox_targets, angle_targets



1.3.2 prior_generator.grid_priors函数
def grid_priors(self,
featmap_sizes,
dtype=torch.float32,
device='cuda',
with_stride=False):
"""Generate grid points of multiple feature levels.
Args:
featmap_sizes (list[tuple]): List of feature map sizes in
multiple feature levels, each size arrange as
as (h, w).
dtype (:obj:`dtype`): Dtype of priors. Default: torch.float32.
device (str): The device where the anchors will be put on.
with_stride (bool): Whether to concatenate the stride to
the last dimension of points.
Return:
list[torch.Tensor]: Points of multiple feature levels.
The sizes of each tensor should be (N, 2) when with stride is
``False``, where N = width * height, width and height
are the sizes of the corresponding feature level,
and the last dimension 2 represent (coord_x, coord_y),
otherwise the shape should be (N, 4),
and the last dimension 4 represent
(coord_x, coord_y, stride_w, stride_h).
"""

#断言语句确保 self.num_levels(设置的尺度级别数量)与 featmap_sizes(特征图大小列表)的长度相同
assert self.num_levels == len(featmap_sizes)
multi_level_priors = []
for i in range(self.num_levels):
priors = self.single_level_grid_priors(
featmap_sizes[i],
level_idx=i,
dtype=dtype,
device=device,
with_stride=with_stride)
multi_level_priors.append(priors)
return multi_level_priors
调用 self.single_level_grid_priors 函数生成单个尺度级别的先验框

1.3.2.1 single_level_grid_priors函数
def single_level_grid_priors(self,
featmap_size,
level_idx,
dtype=torch.float32,
device='cuda',
with_stride=False):
"""Generate grid Points of a single level.
Note:
This function is usually called by method ``self.grid_priors``.
Args:
featmap_size (tuple[int]): Size of the feature maps, arrange as
(h, w).
level_idx (int): The index of corresponding feature map level.
dtype (:obj:`dtype`): Dtype of priors. Default: torch.float32.
device (str, optional): The device the tensor will be put on.
Defaults to 'cuda'.
with_stride (bool): Concatenate the stride to the last dimension
of points.
Return:
Tensor: Points of single feature levels.
The shape of tensor should be (N, 2) when with stride is
``False``, where N = width * height, width and height
are the sizes of the corresponding feature level,
and the last dimension 2 represent (coord_x, coord_y),
otherwise the shape should be (N, 4),
and the last dimension 4 represent
(coord_x, coord_y, stride_w, stride_h).
"""
feat_h, feat_w = featmap_size
stride_w, stride_h = self.strides[level_idx]
shift_x = (torch.arange(0, feat_w, device=device) +
self.offset) * stride_w
从 featmap_size 中解包出特征图的高度和宽度,分别赋值给 feat_h 和 feat_w。
从 self.strides 中解包出当前尺度级别的水平和垂直步幅(stride),分别赋值给 stride_w 和 stride_h。
创建一个在 [0, feat_w) 范围内的张量,表示特征图上的水平坐标
将 self.offset (0.5) 添加到上述水平坐标中,并乘以水平步幅 stride_w,以计算出先验框的水平偏移

# keep featmap_size as Tensor instead of int, so that we
# can convert to ONNX correctly
shift_x = shift_x.to(dtype)
shift_y = (torch.arange(0, feat_h, device=device) +
self.offset) * stride_h
# keep featmap_size as Tensor instead of int, so that we
# can convert to ONNX correctly
shift_y = shift_y.to(dtype)
用 torch.arange 函数创建一个在 [0, feat_h) 范围内的张量
将 self.offset 添加到上述垂直坐标中,并乘以垂直步幅 stride_h,以计算出先验框的垂直偏移

shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
用于根据给定的水平和垂直偏移值 shift_x 和 shift_y 创建一个网格矩阵
_meshgrid 函数会接收两个一维的张量作为输入,网格矩阵的大小是 len(shift_x) 行乘以 len(shift_y) 列

if not with_stride:
shifts = torch.stack([shift_xx, shift_yy], dim=-1)
else:
# use `shape[0]` instead of `len(shift_xx)` for ONNX export
stride_w = shift_xx.new_full((shift_xx.shape[0], ),
stride_w).to(dtype)
stride_h = shift_xx.new_full((shift_yy.shape[0], ),
stride_h).to(dtype)
shifts = torch.stack([shift_xx, shift_yy, stride_w, stride_h],
dim=-1)
all_points = shifts.to(device)
return all_points
如果 with_stride 为 False (默认),表示不需要包含步幅信息,那么就会将之前生成的 shift_xx 和 shift_yy 合并成一个张量 shifts
如果 with_stride 为 True,表示需要包含步幅信息,那么会为每个中心坐标 (x, y) 额外添加步幅信息










![java八股文面试[多线程]——AQS 详细介绍](https://img-blog.csdnimg.cn/img_convert/b93de999f282b24932796045b9ef42fd.png)

