cuda学习笔记3——cuda常用内存相关函数及其使用示例
- 常用的GPU内存函数
- cudaMalloc()
- cudaMemcpy()
- cudaFree()
- 代码示例
常用的GPU内存函数
cuda程序将系统区分成host和device,二者有各自的memory。kernel可以操作device memory,为了能很好的控制device端内存,CUDA提供了几个内存操作函数:
| c | cuda |
|---|---|
| malloc | cudaMalloc |
| memcpy | cudaMemcpy |
| memset | cudaMemset |
| free | cudaFree |
cudaMalloc()
- (1)函数原型:
cudaError_t cudaMalloc (void **devPtr, size_t size)
-
(2)函数用处:与C语言中的malloc函数一样,只是此函数在GPU的内存你分配内存。
-
(3)注意事项:
可以将cudaMalloc()分配的指针传递给在设备上执行的函数;
可以在设备代码中使用cudaMalloc()分配的指针进行设备内存读写操作;
可以将cudaMalloc()分配的指针传递给在主机上执行的函数;
不可以在主机代码中使用cudaMalloc()分配的指针进行主机内存读写操作(即不能进行解引用)。
cudaMemcpy()
(1)函数原型:
cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)
(2)函数作用:与c语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
(3)函数参数:cudaMemcpyKind kind表示数据拷贝方向,如果kind赋值为cudaMemcpyDeviceToHost表示数据从设备内存拷贝到主机内存。
(4)与C中的memcpy()一样,以同步方式执行,即当函数返回时,复制操作就已经完成了,并且在输出缓冲区中包含了复制进去的内容。
(5)相应的有个异步方式执行的函数cudaMemcpyAsync(),这个函数详解请看下面的流一节有关内容。
cudaFree()
(1)函数原型:cudaError_t cudaFree ( void* devPtr )。
(2)函数作用:与c语言中的free()函数一样,只是此函数释放的是cudaMalloc()分配的内存。
代码示例
test2_cudaMemcpy.cu
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void add( int a, int b, int *c )
{
*c = a + b;
}
int main( void )
{
int c;
int *dev_c;
//cudaMalloc()
cudaMalloc( (void**)&dev_c, sizeof(int) );
//核函数执行
add<<<1,1>>>( 2, 7, dev_c );
//cudaMemcpy()
cudaMemcpy( &c, dev_c, sizeof(int),cudaMemcpyDeviceToHost ) ;
printf( "2 + 7 = %d\n", c );
//cudaFree()
cudaFree( dev_c );
return 0;
}
编译
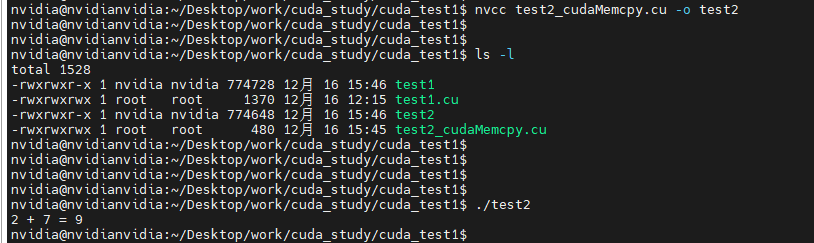
nvcc test2_cudaMemcpy.cu -o test2
运行
$ ./test2
2 + 7 = 9
__global__ void add( int a, int b, int *c )
表示定义了一个核函数。必须要以__global__ 声明。
cudaMemcpy( &c, dev_c, sizeof(int),cudaMemcpyDeviceToHost )
这里表示把cuda运行的结果复制到主机端。
具体核函数可以看:
参考:https://blog.csdn.net/qq_23858785/article/details/96476740




![[附源码]Python计算机毕业设计公立医院绩效考核系统Django(程序+LW)](https://img-blog.csdnimg.cn/727d412053b9475e94d65c850434e850.png)




![[深度学习基础]2.pycharm联合annaconda生成虚拟环境测试yoloV7](https://img-blog.csdnimg.cn/79bcb9c380634d1e8069cd357525c7db.png)