作者:陆晨炜(花名遣云)阿里巴巴智能引擎事业部数据开发
前言:
2022年的双11,阿里淘宝搜推集群承载上千万每秒的的流量峰值,消费者的每一次浏览、点击都通过搜推集群进行流转,与往年双11不同的是,降本增效在今年也变成了特别重要的一个技术课题。在此背景下,阿里搜索推荐团队与Hologres深度合作,在技术上,通过将传统的Text Array升级为JSONB,并使用JSONB列式存储,相比去年双11实现查询性能提升 400%+ ,存储下降45%,共资源节省数千core(预计节省成本数百万元),接受住双11生产稳定性考验,真正实现降本增效。
通过本文我们将会详细介绍Hologres JSONB在阿里搜索推荐团队的实践,以帮助更多企业通过技术手段助力业务快速增长。
业务介绍
阿里巴巴搜索推荐事业部的实时数据仓库承载了阿里巴巴集团淘宝、淘宝特价版、饿了么等多个电商业务的实时数仓场景,提供了包括实时大屏、实时报表、实时算法训练、实时A/B实验看板等多种数据应用支持。从2019年开始,搜索团队开始与Hologres进行共建,通过Hologres支撑了搜索推荐的多个应用场景,包括即席多维分析,A/B test等,详情可以查看往期精彩内容:
阿里巴巴电商搜索推荐实时数仓演进之路
Hologres在阿里搜索推荐实时数据场景下即席多维分析的最佳实践
通天塔是搜索团队对外提供的实时数据分析产品,提供了手淘搜索、手淘推荐、拍立淘等多个业务的实时A/B报表服务,其重要功能之一为对A/B实验进行实时的对比观测。举个例子,算法同学需要看实验分层layerA下的1、2两个分桶的效果对比,需要从实时的数据分别统计 layerA:1、layerA:2 两个桶的指标,并计算GAP值。算法同学通常会通过通天塔报表查询实时的A/B实验效果,并对算法模型进行评估和调整。在实时报表中,我们还提供了各种维护的筛选项帮助用户对数据进行深入分析,如:用户属性、商品属性、类目属性、卖家属性等。
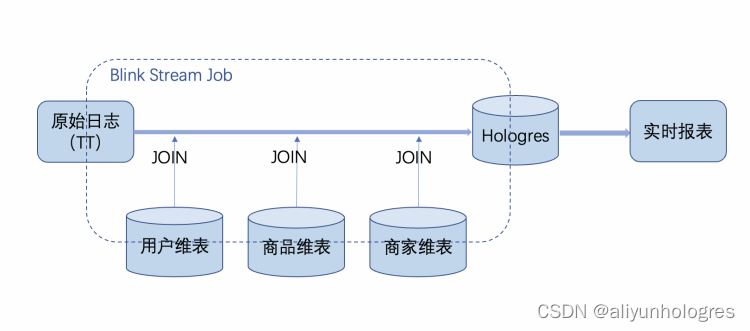
下图为通天塔主要的实时数据链路示意图,我们将采集到原始日志从TT(Datahub)中读取,在Flink流作业中,我们会对日志进行ETL处理,其中包括根据日志中的用户ID、商品ID、商家ID等关联对应的维表,并将相关属性字段一同存储到Hologres表,最后通过实时报表生成SQL Query,进行实时数据的查询分析。
我们近年来一直使用Hologres作为通天塔的实时数据查询引擎,因为我们的业务场景中,有很多的用户标签、商品标签、卖家标签和算法桶号等多值属性,以用户标签为例,业务上对用户的画像属性不是一成不变的,业务可能随时需要新增一类属性进行观测,如果每次都需要用一个新的字段来存储新的用户属性,那在整个实时链路上都会显得低效。因此在建表时,我们通常使用Text Array(text [])类型作为多值字段的存储格式。
用户属性相关的标签都会以Text Array的形式存储到同一个字段中,需要业务有变化需要新增字段,Flink任务、Hologres表、实时报表中都不需要进行额外的修改。这从运维效率和数据时效性来看,都是很合适的选择。对于商品、卖家等属性标签和算法桶号,也同样是这些优点驱动我们选择了使用Text Array,并稳定支撑了历年的双11,其中2021年双11 Text Array的平均查询延迟为1070ms。
但Text Array也并不是完美无缺的,在有限的资源配置下,当查询QPS较高时,尤其是大促期间,我们会遇到查询慢、查询超时的问题,经分析这与Text Array自身在查询性能上的限制有较大关系,这就使得我们不得不断累加资源来提升性能,从而也导致我们的成本剧增。
为了解决这一问题,并实现降本提效的目标,本次双11前,通过与Hologres团队的合作,我们成功将Text Array 升级为性能更高、存储更低的 JSONB 格式作为算法桶号、用户标签等多值字段的存储格式,并在今年双11生产路落地,支撑上百万写入RPS,查询性能提升400%+,节约数千core资源。
业务实践:Text Array格式升级为JSONB格式
1. 原Text Array格式
1.1 表结构与数据示例
我们之前使用Hologres(Text Array格式)存储了实时的明细数据,表的结构如下:
CREATE TABLE wireless_pv (
second_timestamp timestamp with time zone NOT NULL,
pk text NOT NULL,
uid text NOT NULL,
item_id bigint NOT NULL,
seller_id bigint NOT NULL,
cate_id bigint,
bts_tags text[] NOT NULL
,PRIMARY KEY (pk, user_name)
);
这张表为曝光明细表,其中主要的字段包括:
- 时间戳
- pk,用于写入去重
- UID
- 商品ID
- 卖家ID
- 类目ID
- 分层分桶标签,字段类型为text array,存储该用户所属的多个分层、分桶
数据示例:
| second_timestamp | pk | UID | … | bts_tags |
|---|---|---|---|---|
| 2022-11-11 00:00:00+08 | 858739e966f7ebd1cfaa49c564741360 | 1 | {“layerA:1”, “layerB:11”, “layerC:111”} | |
| 2022-11-11 00:00:01+08 | e7e3d71fac5a92b87c3278819f6aff8c | 2 | {“layerA:1”, “layerB:12”, “layerC:112”} | |
| 2022-11-11 00:00:01+08 | 828f07dc16f4fa2f4be5ba3a9d38f12a | 3 | {“layerA:2”, “layerB:11”, “layerC:111”} | |
| 2022-11-11 00:00:02+08 | b0c419c119658dfa0fd5f914e251af1d | 4 | {“layerA:2”, “layerB:12”, “layerC:112”} |
1.2 Text Array查询语法与示例
我们在查询时使用了Hologres提供的array_extract()函数进行了桶号等Text Array字段的分组统计,使用 &&操作符进行数据过滤,具体查询示例如下:
SELECT
array_extract (bts_tags, ARRAY['layerA:1', 'layerA:2']) AS "bts_tags",
count(1) AS "pv"
FROM
wireless_pv
WHERE
second_timestamp >= TIMESTAMPTZ '2022-11-11 00:00'
AND second_timestamp <= TIMESTAMPTZ '2022-11-11 23:59'
AND bts_tags && ARRAY['layerA:1', 'layerA:2']
GROUP BY
array_extract (bts_tags, ARRAY['layerA:1', 'layerA:2'])
;
如果业务需要临时变更标签属性,那么我们可以通过Text Array非常灵活的增加字段,对我们的开发效率和运维效率来说也是非常高效的。这种查询方式我们已经稳定使用了几年,能满足日常的业务需求,但美中不足的是,当数据量变大时,要计算的标签变多,尤其是大促期间,如上的SQL示例,如果我们要取某个标签的数据,需要经过一系列的Array解析,查询延迟就会增加,这就导致我们需要通过加资源的方式去支撑性能,我们期望能够用一种更加友好的方式,在不牺牲灵活性的前提下,平衡好性能和资源之间的关系。
2. 升级为JSONB格式并开启列式存储
Hologres从 V0.9版本就开始支持JSON了,但是在查询效率上还是不能够满足业务需求,因为要把一个JSON里面把所有的value都解析一遍,比较费劲。正好Hologres在1.3版本支持了JSON的列存存储,可以减少JSONB的存储并加速查询(关于JSONB的列式存储详细介绍可以参考Hologres的文档)。为了解决Text Array的性能问题,于是我们将实例升级到了1.3版本,并使用JSONB列式存储来替换原先的Text Array。
2.1 表结构与数据示例
升级后的表结构如下所示,我们将text[] 字段改成了JSON类型,这里仅以分层分桶字段作为示例:
CREATE TABLE wireless_pv (
second_timestamp timestamp with time zone NOT NULL,
pk text NOT NULL,
uid text NOT NULL,
item_id bigint NOT NULL,
seller_id bigint NOT NULL,
cate_id bigint,
bts_tags JSONB
,PRIMARY KEY (pk, user_name)
);
-- 同时需要打开JSONB列式存储优化
ALTER TABLE <table_name> ALTER COLUMN <column_name> SET (enable_columnar_type = ON);
我们使用Flink将实时数据从TT写入Hologres,由于TT中存储的bts_tags字段是用分隔符分隔的多个分层分桶,因此我们还实现了UDF,将分隔符分隔的字符串数据转换为JSON格式的字符串。因为是直接写入JSON格式,因此也能达到像Array一样的灵活性,即使需要加标签,也可以随时加,不会牺牲开发效率。
写入后的数据示例如下,其中分层分桶字段是符合JSON的格式:
| second_timestamp | pk | UID | … | bts_tags |
|---|---|---|---|---|
| 2022-11-11 00:00:00+08 | 858739e966f7ebd1cfaa49c564741360 | 1 | {“layerA”:“1”, “layerB”:“11”, “layerC”:“111”} | |
| 2022-11-11 00:00:01+08 | e7e3d71fac5a92b87c3278819f6aff8c | 2 | {“layerA”:“1”, “layerB”:“12”, “layerC”:“112”} | |
| 2022-11-11 00:00:01+08 | 828f07dc16f4fa2f4be5ba3a9d38f12a | 3 | {“layerA”:“2”, “layerB”:“11”, “layerC”:“111”} | |
| 2022-11-11 00:00:02+08 | b0c419c119658dfa0fd5f914e251af1d | 4 | {“layerA”:“2”, “layerB”:“12”, “layerC”:“112”} |
2.2 JSONB查询语法与示例
在对JSONB格式数据查询和过滤时,我们主要使用了 ->>操作符提取JSONB中的value,这里分组查询时候变得更为简单,不再需要使用性能相对一般的array_extract函数,相应的查询示例如下:
SELECT
'layerA:' || (bts_tags ->> 'layerA') AS "bts_tags",
COALESCE(sum(scene_count), 0) AS "pv"
FROM
wireless_pv
WHERE
second_timestamp >= TIMESTAMPTZ '2022-11-11 00:00'
AND second_timestamp <= TIMESTAMPTZ '2022-11-11 23:59'
AND bts_tags ->> 'layerA' IN ('1', '2')
GROUP BY
'layerA:' || (bts_tags ->> 'layerA')
;
3. 数据验证与性能测试
3.1 性能测试准备
在对Hologres格式正式升级切换前,我们对JSONB存储的数据和Text Array对比进行了性能验证。
- 准备相同Text Array和JSON数据:从日常的查询中采样一部分Text Array Query,将Query转为JSONB查询语法,然后将转换前后的Query分别进行查询,并对比查询结果是否一致。
- 导入手淘搜索数据,时间范围为:20220920 11:00-15:00
set hg_experimental_enable_result_cache=off;不查缓存
3.2查询性能测试结果
在同一个集群下,依次执行以上Query,循环6次,统计每个Query的平均耗时(毫秒):
| 表名 | Array格式查询平均延迟(ms) | JSONB格式查询平均延迟(ms) | JSONB性能提升 |
|---|---|---|---|
| wireless_pv | 5975.5 | 1553.8 | 280% |
| wireless_dpv | 862.5 | 455.8 | 89% |
可以看到:在同等资源配置下,在手淘搜索查询的典型场景下,分层分桶等多值字段升级到JSONB格式后,将带来至少100%以上的查询耗时降低。这一性能上的巨大提升,大大改善了我们之前遇到的查询高峰期的查询慢和查询超时问题;同时按此估算,我们可以对当前Hologres实例的CPU资源缩减一半以上,有力推动完成降低成本的目标。
3.3存储成本对比
同时,上文也提到,我们开启了Hologres的JSONB列式存储,通过对比,我们也发现开启列式存储之后,数据的存储也有一定的下降。以淘宝搜索的曝光、点击表为例,
| 表名 | Array 格式存储量 | JSONB格式存储量 | 存储下降% |
|---|---|---|---|
| wireless_pv | 35 TB | 15 TB | -57% |
| wireless_dpv | 3472 GB | 1562 GB | -55% |
可以看到:升级到JSONB列式存储后,表存储整体下降了55%+,这也可以进一步帮助业务节省存储资源。
接受双11生产考验,JSONB查询性能提升400%+
在今年双11,搜推集群承载了上千万每秒的流量峰值,上百万每秒的查询流量峰值,同时JSONB升级也在部分业务场景中上线,历经双11大促流量高峰的考验,写入RPS达百万每秒,在未对写入和查询执行限流的情况下,Flink实时写入未发生延迟问题,平均查询延迟仅199ms。
相比去年双11,升级JSONB格式后,查询性能提升400%+(2021双11平均查询延迟为1070ms),存储下降45%,资源节省数千core,有效节约数百万元成本,真正实现降本增效,而系统的灵活性和业务开发效率没有丝毫下降,进一步助力万千消费者买到心仪物品,进一步提升购物体验!
在后续的工作中,我们也准备对通天塔接入其他业务,根据业务特点设计JSON格式,对实时数据表进行JSONB格式的升级,预计将带来接近50%的Hologres计算成本的降低。
了解Hologres:https://www.aliyun.com/product/bigdata/hologram
![[附源码]Python计算机毕业设计高校学生心理健康信息咨询系统Django(程序+LW)](https://img-blog.csdnimg.cn/0463643c4db043068452dafd2818d168.png)