docker容器监控
一、docker介绍
Docker的中文意思就是码头工人,进入到Docker的官方网站后,也可以看到Docker的图标,如下图所示。

这个Docker图标上就是一条鲸鱼,上面有很多集装箱,集装箱就相当于虚拟环境,每个集装箱有自己的虚拟环境,Docker中文意思是码头工人,相当于把集装箱从鲸鱼身上取下来,然后使用这个集装箱的虚拟环境。
Docker搭建虚拟环境包括三个要素,Registry,Contaniner和Image。如下图所示。
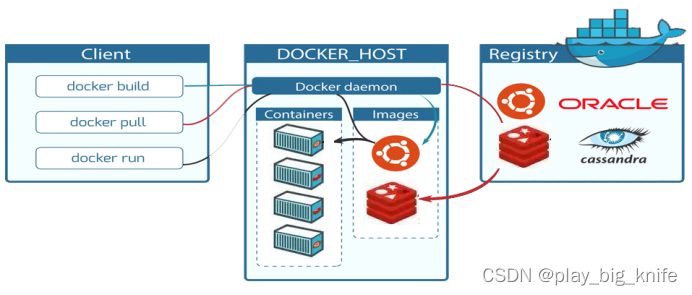
从图中可以看出,Registry是一个远程的仓库,从远程的仓库可取拉取一个镜像到本地,拉取镜像后可以运行成一个容器。客户端可以使用docker pull从远程仓库拉取一个镜像,docker run指令可以将一个镜像运行成一个容器,进入这个容器需要使用docker exec指令,可以进入到运行中的容器中,docker build可以把一个设置成功的虚拟环境容器再打包成环境。这系列操作可以通过以下简单实现。
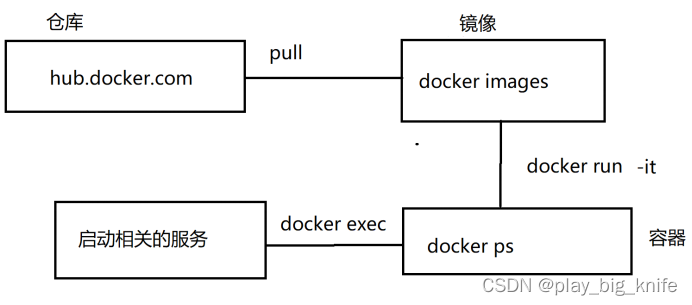
这里的元程仓库是hub.docker.com,这里包括很多的docker镜像。
二、windows中docker的安装
进入docker官网下载地址docker下载,下载Windows版本。
下载之后双击打开,按默认设置点击安装,完成后界面如下,点击close and restart重启完成安装。
进入docker主界面,左下角显示绿色,则表示docker安装成功。
在docker设置中添加镜像网址"registry-mirrors":["https://docker.mirrors.ustc.edu.cn/"]。添加完成后点击右下角蓝色按钮应用设置。
在power shell中输入具体的docker指令。
三、docker实现容器式监控
docker程序还是安装在硬盘上的,随着程序的增加,程序运行时间就会长,需要的内存就会大,硬盘的数据也会多。 这就带来性能上的优化问题。解决内存、硬盘、网络接口速度不能超过限额也就成为一个问题。
也就是,如果多个容器运行,需要收集docker各容器的运行状态和运行信息,也就是需要监控模块的参与。
docker运行的监控原理图如下所示。
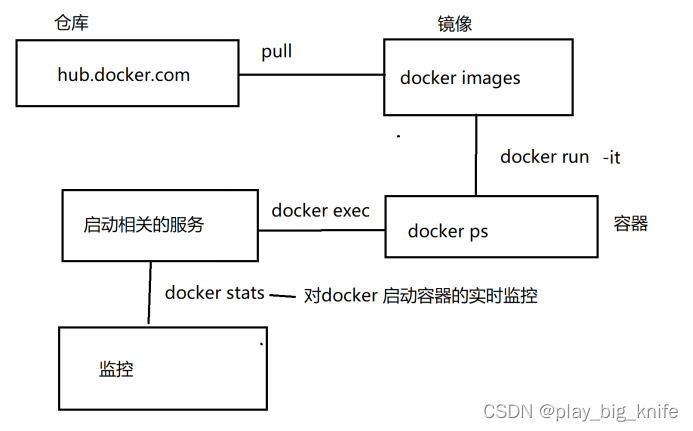
图中指示可以使用docker stats去查看每个容器的运行状态。
#docker stats
使用这个指令后的运行结果如下所示。
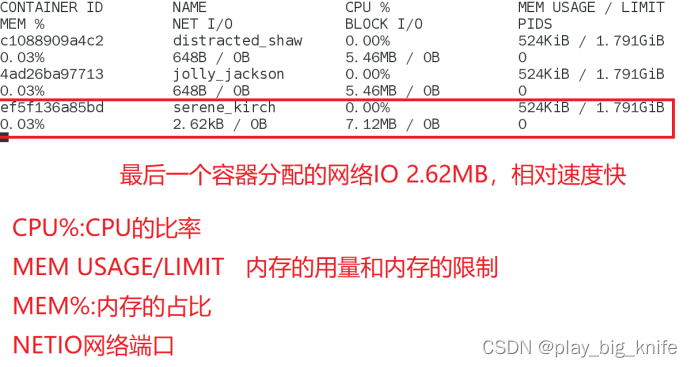
对这个结果也可以进行格式化提取,使用—format参数对输出的格式进行初始化。
如单纯提取出ContainerId,指令如下。
docker stats –format “{{.Container}}”
这个指令把docker stats中的第一列的维度Container做为format的参数,然后输出了容器运行的相关信息。
如果输出再添加上CPU的占比信息,这里把Container和CPU的信息以“:”号隔开。
docker stats –format “{{.Container}}:{{.CPUPerc}}”
注意:这里提取CPU的百分比信息,需要把CPU%列维度的名称中“%”替换为Perc,即可。
如果再把内存的占比信息
Docker stats –format “{{.Container}}:{{.CPUPerc}}:{{MemPerc}}”
接下来进入监控的实现,监控实现的时候,不会直接在宿主机中监控,这样不利于管理,因为监控需要提取相关的重要信息,收集信息后还需要使用一些有利的语言工具进行分析,进而进行图形展示。如使用python,matplotlib,tensorflow,web这样的技术架构形成分析界面,这样就需要服务器也要安装这样的资源才能进行分析,cpu的资源又被无端被占用。可以使用docker容器配置环境,进行环境监控。
监控方法的原理图如下所示。

从图中可以得出。需要把Docker stats信息传入到docker容器中,然后在容器安装python,去完成监控信息的分析即可。
解决方法:把docker stats的输出结果放在文件里,文件挂载容器数据卷持久到容器中,运行python程序对数据进行提取。
这里提到了一个技术“挂载”,Docker容器启动的时候,如果要挂载宿主机的一个目录,可以用-v参数指定。可以这样理解,挂载相当于docker的虚拟环境可能使用主机中文件信息。
具体把docker stats的监控信息挂载到docker虚拟机中进行分析的流程如下。
第一步:实时流的获取
docker stats --format "ContainerID:{{.Container}}:CPU%:{{.CPUPerc}}:MEM%:{{.MemPerc}}">info.txt
第二步:运行后ctrl+c中止
第三步:使用ftp软件下载info.txt文件到本地
第四步,写一段程序分解info.txt
import pandas
data=pandas.read_csv("info.txt",sep=":",names=["name1","container_id","name2","cpu%","name3","Mem%"])
data=data[["container_id","cpu%","Mem%"]]
#有几个容器就有几条指令,通过unique()方法对容器进行汇总去重统计
container_length=data["container_id"].unique().size
while True:
print(data.tail(container_length))
第五步,接下来,就需要在宿主机建一个文件夹,管理这两个文件,一个是把文件能够在docker虚拟机中执行,一个是收集到的容器信息info.txt。
第六步:现在使用-v实现挂载目录,把宿主机目录挂载到虚拟环境中,需要使用docker pull python3拉取一个python3的容器。然后使用下面的指令进行挂载。
Docker run –it -v /home/monitor python /bin/bash
这样可以进入到启动容器中,进入容器后,在这里使用pip3安装pandas软件,使用指令如下。
pip install pandas
如图;
第七步:保留进程退出宿主机
Ctrl+p+q
第八步:先删除宿主机文件info.txt,然后运行docker stats一边收集docker容器的相关信息,一边在宿主机中启动 python程序进行实时流的分析,先重新收集docker容器的相关信息。命令如下。
docker stats
dokcer stats --format "ContainerID:{{.Container}}:CPU%:{{.CPUPerc}}:MEM%:{{.MemPerc}}">/home/monitor/info.tx
第九步:再次进入容器,启动python test.py
这里可以看到收集到的实时信息,分析和后续的web展示先略。
四、google方案的图形展示
前面介绍了启动docker stats来收集容器信息,这里也可以不必启动docker stats,可以根据需求监控docker的具体工作目录。Google提供的cadvisor可以监控/var/lib/docker ,第二/sys,第三/var/run,其中var/lib/docker是docker中的相关信息,/sys是系统的相关信息,/var/run是系统运行的相关信息,这些收集的技术的原理图如下图所示。
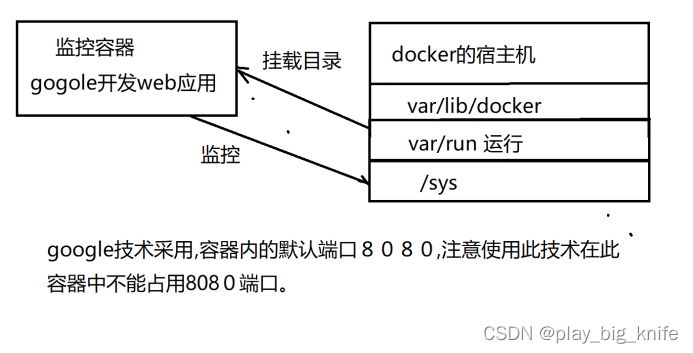
这里提醒了大家,google使用这个技术默认采用8080端口,这个端口是启动容器中不能占用的端口。监控容器的应用使用cadvisor。
拉取镜像的命令如下。
docker pull google/cadvisor
这里为了更好的验证google/cadvisor,在启动google/cadvisor之前首先需要启动三个centos容器。便于监控使用。启动google/cadvisor容器指令如下。
docker run -it -p 8890:8080 -v /var/run:/var/run -v /var/lib/docker:/var/lib/docker:ro -v /sys:/sys:ro google/cadvisor /bin/bash
启动后,在地址栏输入虚拟机的ip+端口号
如http://192.168.110.148:8890/containers/

进入首页,可以查看整体运行情况。进入首页后,点击第一项:Docker Containers,就可以查看到所有的容器名称,可以点击进入到其中一个容器。
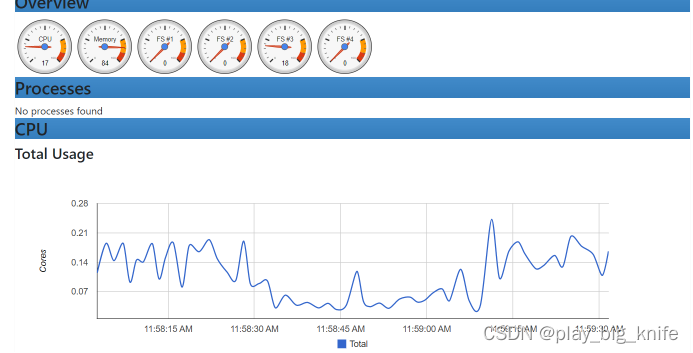
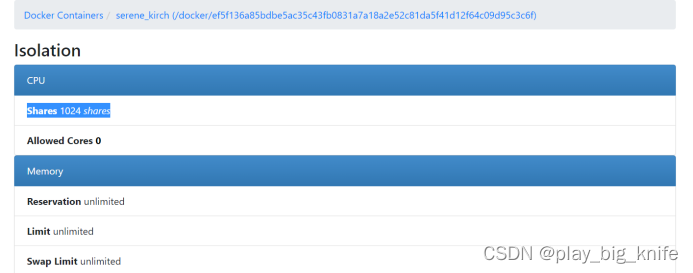
这里可查看容器的运行情况,如下图所示。
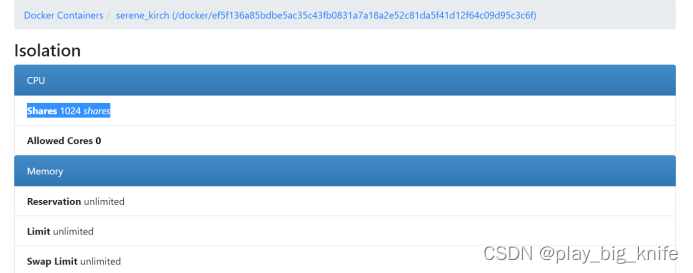
这里CPU shares 1024shares表示了CPU进行了限额设置。
比如A容器设置1024,B容器1024C容器1024,A/B/C就可以得到1:1:1,意味着系统平分CPU的占比。
如果A容器设置512,假定启动了centos;B容器设置1024 ,假定启动了apache小程序,C容器设置2048,假设启动 python机器学习。那么A:B:C=1:2:4表示在CPU空闲时间内,C优先级比A/B都高,C占cpu的比率就会大。
具体cpu限额的设置方法,可以在启动容器时设定这个值。指令参数如下。
Docker run --cpu-shares 1024
还可以从前台查看docker服务环境的运行情况,专业术语叫巡检。巡检界面如下图所示。
这里图形显示,显示的内容是实时的,这条曲线也会一直在运动着。
通过google/cadvisor监控查看运转情况的原理图如下 。