目录
1.简介
2.YOLOv5改进
2.1增加以下yolov5s_botnet.yaml文件
2.2common.py配置
2.3 yolo.py配置修改
1.简介
论文地址
Paper

本文提出的BoTNet是一种简单高效的网络,有效的将SA应用到多种视觉任务,如图像识别、目标检测、实例分割任务。通过将ResNet50中最后三个bottleneck模块的空间卷积替换为全局的SA操作,有效提升了基线模型在签署任务上的性能。
Section I
常用的CNN大多采用3x3的卷积核,鉴于卷积操作可以有效的不糊哦局部信息,但是对于一些视觉任务如目标检测、实例分割、关键点检测还需要建立长程依赖关系。比如实例分割中需要收集场景相关的信息才能学习物体之间的关系;那么为了吧局部信息聚合就需要堆叠多个卷积层。但基于non-local操作可以更有效,也不需要堆叠那么多层。
而建模长程依赖对NLP任务也十分重要,Self-Attention可以有效学习每一对实体之间的关联,基于SA组成的Transformer已经成为NLP的主流,如GPT和BERT。

SA应用于视觉的一种简便方法及时将卷积层替换为MHSA层,参见Fig 1。按照这种思路有两种改进方向,一是将Resnet中的卷积层替换为各种SA操作,比如SASA,AACN,SANet;二是将图像切分成互补重叠的patch然后送入堆叠的Transformer模块。
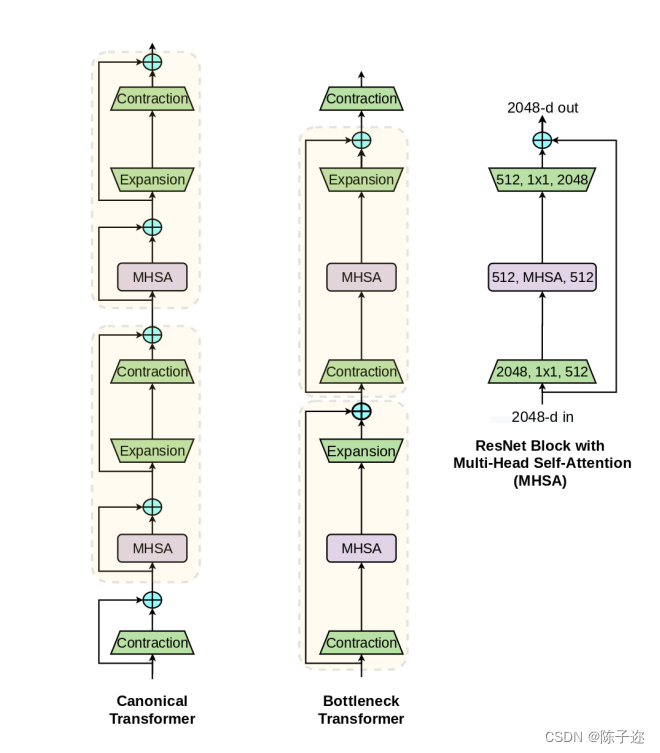
虽然看起来是两种不同类型的体系结构,但是事实并非如此。本文提出ResNet 模块中使用MHSA层可以看做是一种带有瓶颈结构的Transformer模块,只不过有细微的变化比如残差连接、归一化层的选择上。因此本文将带有MHSA层的ResNet模块称之为BoT模块,具体结构参见Fig3.
将注意力应用到视觉领域有以下挑战:
(1)图像一般比用于分类的图像更大,分类一般(224,224)就够了,用于目标检测和实例分割的图像分辨率更高。
(2)SA的计算是输入分辨率的平方项,因此对内存和算力有要求
为了克服以上挑战本文进行以下设计:
(1)使用卷积来高效学习低分辨率、抽象的特征
(2)使用SA来处理、聚合卷积提取到的特征
这种混合设计可以有效利用卷积和SA的优点,同通过卷积进行下采样可以有效处理较高分辨率的输入图像。
因此本文的提出一种简单的设计方案:将ResNet最后三个block替换为BoT模块,其余不做任何改动。再说明白点,只将ResNet最后三个3x3卷积替换为MHSA层。
只做这一小小的改动,就将COCO上目标检测精度提升了1.2%;并且BoTNet在结构上并没什么新颖之处因此本文相信这种简洁性使其可以作为一个值得进一步研究的backbone。
使用BoTNet做实例分割,效果也有显著提升,尤其对小物体有显著提升。
最后本文还对BoTNet进行了放缩,发现BoTNet在更小数据集上没有什么实质性提升,但在ImageNet上达到了84.7%的top-1精度;在TPU-V3硬件测试上比目前流行的EfficientNet块1.64倍。基于BoTNet展现的结果本文希望SA未来可以在视觉任务中广泛使用。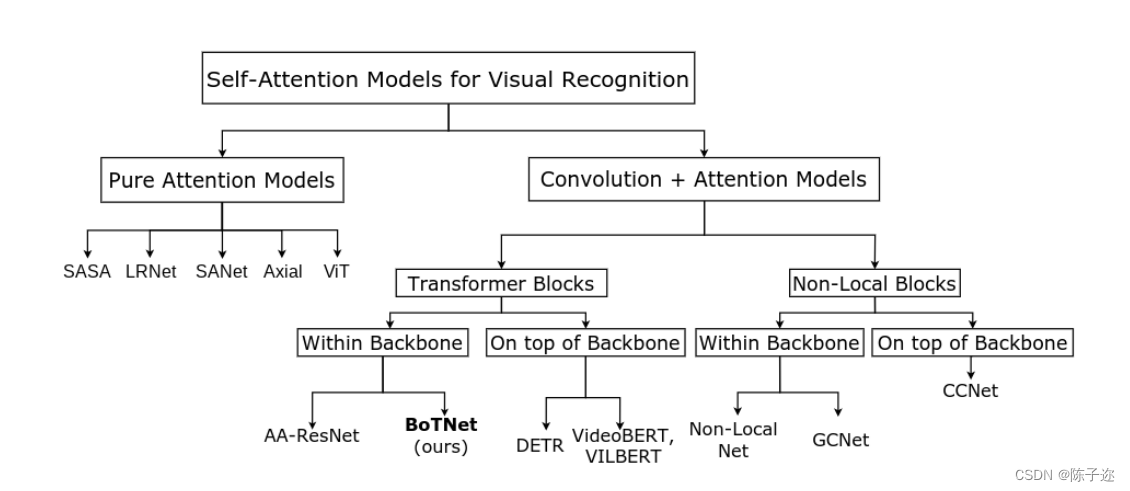
Section II Related Work
Fig 2总结了计算机视觉任务中的注意力,本节主要关注:
(1)Transformer vs BoTNet
(2)DETR vs BoTNet
(3)Bon-Local vs BoTNet
Fig 3中左侧是Transformer ,中间是本文定义的BoT模块,右侧就是ResNet Block中将卷积层替换为MHSA后的结果
Connection to the Transformer
正如标题提到的本文的关键是将ResNet中的block替换为MHSA层,但BoT的架构设计并不是本文的贡献,本文只是指出MHSA ResNet Bottleneck与Transformer之间的关系,从而能够提升对计算机视觉中SA的理解和设计。
除了在Fig 3中恒看出的区别,如残差连接还有一些区别如:
(1)归一化 Transformer使用的是LN而ResNet使用的是BN
(2)非线性 Transforemr在FFN层引入非线性,ResNet则在BoT中使用了3个非线性变换
(3)输出映射 Transformer中的MHSA包含一个输出投影而BoT中没有
(4)一般视觉任务常使用SGD Optimizer而Transformer通常使用Adam Optimizer
Connection to DETR
DETR是基于Transformer的目标检测框架,DETR和BoTNet都尝试使用SA来提升目标检测和实例分割的性能,不同之处在于DETR是在主干之外使用了SA模块,主要目的是为了避免使用RP和非极大值抑制;
BoTNet目的是为了提出一个主干框架直接进行目标检测和实例分割。实验结果显示BoTNet对小物体的检测提升效果明显,相信在未来可以解决DETR对小物体检测不佳的问题。
Connection to Non-Local Neural Nets
Non-Local Nets主要是将Transformer与非局部算法结合,比如在ResNet最后的1-2个stage中引入非局部模块,来提升实例分割、视频分类的效果,BoT是一种混合设计,同时使用了卷积核SA。
Fig 4展示了Non-Local层和SA层的区别:
(1)MHSA中包含多个头来进行Q,K,V的映射
(2)NL Block中通常包含一个通道缩放因子对通道进行缩放,因子通常设置为2,而MHSA中设置为4
(3)NL Block是作为一个额外的模块插入到ResNet Block中 但是BoTNet是直接替换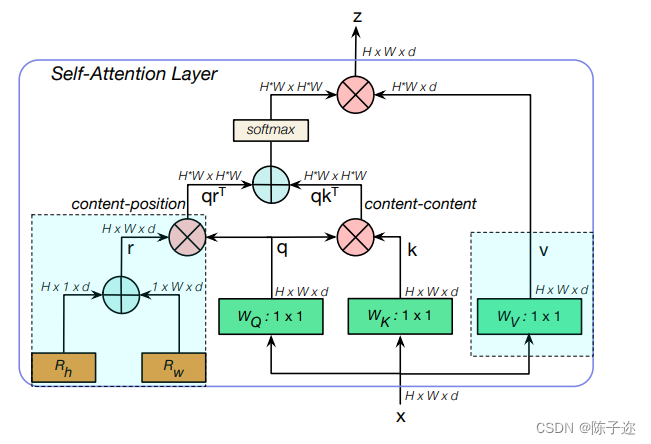
Section III Method
BoTNet的设计很简单,将ResNet的最后三个3x3卷积替换为MHSA,这样就实现了featuremap的全局计算。通常ResNet包含4个stage[c2,c3,c4,c5],每一个stage中堆叠不同的block,并且使用残差连接。
本文的目标就是使用将SA用于高分辨率的实例分割,因此最简单的方法就是在主干网路低分辨率特征图中加入注意力,即c5阶段,c5一般包含3个残差快,因此将这3个残差快替换为MHSA模块就组成了BoTNet。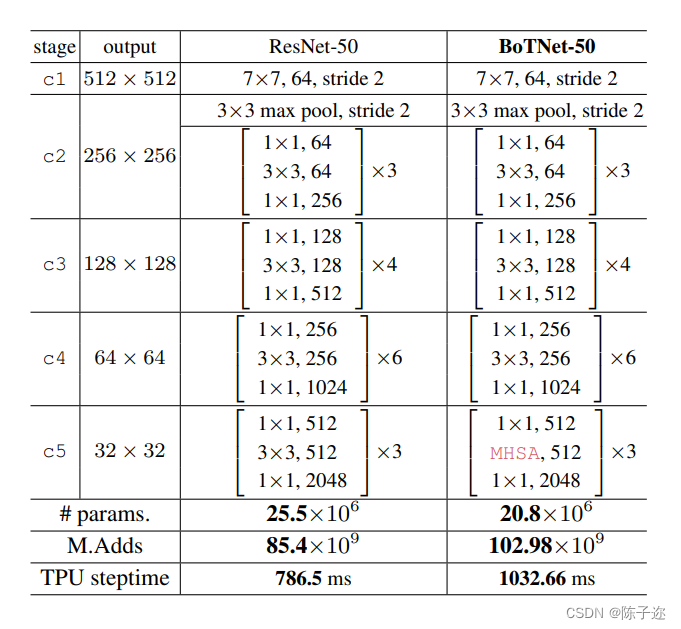
Table 1展示了BoTNet的网络结构,Fig 4展示了MHSA的结构。涉及到步长卷积的操作在本文都替换为了池化操作。
Relative Position Encodings
近期研究表明相对位置编码更有效,因为考虑了不同位置特征之间的相对距离,从而能够有效的将不同内容之间的相对距离考虑进来,因此BoTNet使用的是2D相对位置编码。
2.YOLOv5改进
2.1增加以下yolov5s_botnet.yaml文件
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args] # [c=channels,module,kernlsize,strides]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 [c=3,64*0.5=32,3]
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPPF, [1024,5]],
[-1, 3, BoT3, [1024]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium) [256, 256, 1, False]
[-1, 1, Conv, [512, 3, 2]], #[256, 256, 3, 2]
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large) [512, 512, 1, False]
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.2common.py配置
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4,pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos=pos_emb
if self.pos :
self.rel_h_weight = nn.Parameter(torch.randn([1, heads, (n_dims ) // heads, 1, int(height)]), requires_grad=True)
self.rel_w_weight = nn.Parameter(torch.randn([1, heads, (n_dims )// heads, int(width), 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
#print('q shape:{},k shape:{},v shape:{}'.format(q.shape,k.shape,v.shape)) #1,4,64,256
content_content = torch.matmul(q.permute(0,1,3,2), k) #1,C,h*w,h*w
# print("qkT=",content_content.shape)
c1,c2,c3,c4=content_content.size()
if self.pos:
# print("old content_content shape",content_content.shape) #1,4,256,256
content_position = (self.rel_h_weight + self.rel_w_weight).view(1, self.heads, C // self.heads, -1).permute(0,1,3,2) #1,4,1024,64
content_position = torch.matmul(content_position, q)# ([1, 4, 1024, 256])
content_position=content_position if(content_content.shape==content_position.shape)else content_position[:,: , :c3,]
assert(content_content.shape==content_position.shape)
#print('new pos222-> shape:',content_position.shape)
# print('new content222-> shape:',content_content.shape)
energy = content_content + content_position
else:
energy=content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0,1,3,2)) #1,4,256,64
out = out.view(n_batch, C, width, height)
return out
class BottleneckTransformer(nn.Module):
# Transformer bottleneck
#expansion = 1
def __init__(self, c1, c2, stride=1, heads=4, mhsa=True, resolution=None,expansion=1):
super(BottleneckTransformer, self).__init__()
c_=int(c2*expansion)
self.cv1 = Conv(c1, c_, 1,1)
#self.bn1 = nn.BatchNorm2d(c2)
if not mhsa:
self.cv2 = Conv(c_,c2, 3, 1)
else:
self.cv2 = nn.ModuleList()
self.cv2.append(MHSA(c2, width=int(resolution[0]), height=int(resolution[1]), heads=heads))
if stride == 2:
self.cv2.append(nn.AvgPool2d(2, 2))
self.cv2 = nn.Sequential(*self.cv2)
self.shortcut = c1==c2
if stride != 1 or c1 != expansion*c2:
self.shortcut = nn.Sequential(
nn.Conv2d(c1, expansion*c2, kernel_size=1, stride=stride),
nn.BatchNorm2d(expansion*c2)
)
self.fc1 = nn.Linear(c2, c2)
def forward(self, x):
out=x + self.cv2(self.cv1(x)) if self.shortcut else self.cv2(self.cv1(x))
return out
class BoT3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1,e=0.5,e2=1,w=20,h=20): # ch_in, ch_out, number, , expansion,w,h
super(BoT3, self).__init__()
c_ = int(c2*e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[BottleneckTransformer(c_ ,c_, stride=1, heads=4,mhsa=True,resolution=(w,h),expansion=e2) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
2.3 yolo.py配置修改
然后找到./models/yolo.py文件下里的parse_model函数,将加入的模块名BoT3加入进去
在 models/yolo.py文件夹下



![input时间表单默认样式修改(input[type=“date“])](https://img-blog.csdnimg.cn/afcaeb1a697e4aa1b4f3e35c17c04df1.png)