目录
- 一、并行成像
- 二、SENSE重建
- 三、SMASH重建
- 四、灵敏度校准
- 五、AUTO-SMASH和VD-AUTO-SMASH
- 六、GRAPPA重建
- 七、SPACE RIP重建算法
- 八、PILS重建算法
- 九、PRUNO重建算法
- 十、UNFOLD算法
一、并行成像
并行MR成像(pMRI):相位阵列接受线圈不但各有自己专用的接受通道,而且以欠采样方式同时采集数据,利用接受线圈灵敏度的空间信息作为梯度相位编码行不足的补充,用特定的算法重建出无混叠的最终图像。
并行成像由于降低了扫描时间,SNR总是较低,另外还有额外的SNR惩罚。在SENSE中图像混叠解卷绕进一步方法了图像噪声。在SMASH中,在复合K空间组合来自各个线圈的数据,产生部分信号对消导致在图像中某些部分SNR降低。在并行成像中,通常噪声方差也是空间变化的。
使用并行成像的另一种方式是降低回波列脉冲序列(如EPI、fSE)的伪影。EPI由于偏离共振效应遭受几何畸变伪影,而fSE由于T2衰减遭受模糊。对于固定的回波间隔,回波列越长,伪影越重。并行成像减少K空间行数,反过来降低了回波列长度,从而降低了伪影。
并行成像是从多线圈欠采样K空间数据重建图像,可通过与用此阵列线圈全采样K空间数据重建的图像进行比较、核对,以检验其一致性。
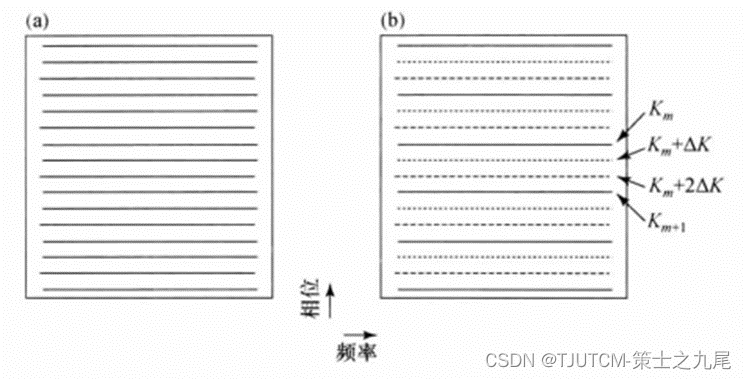
(a)图为全采样空间。
(b)加速因子R=3并行成像K空间,虚线代表没有采的K空间行,两个测量的行Km和Km+1之间缺失的两行分别是Km+ΔK,Km+2ΔK(ΔK是奈奎斯特取样定理要求的相位编码步距)。
在笛卡尔采集中扫描时间正比于相位编码步数。利用多线圈以欠采样方式同时采集数据,从而节省了时间,提高了扫描速度。增大K空间行的间距R倍,而保持覆盖的最大K空间范围(空间分辨率)不变,则扫描时间将降低R倍,于是 在并行成像中R被称为“加速因子”或(扫描时间的)“降低因子” 。
增大相位编码行的间距会导致FOV减小,如果物体延申到缩小的FOV外面,就会发生混叠或卷绕伪影。
并行成像可分为K空间方法和图像空间方法。 SENSE重建 是在图像空间中处理数据解决问题,被称为“图像空间方法”;而 SMASH重建 是在K空间中处理数据解决问题,故被称为“K空间方法”。
二、SENSE重建
SENSE方法是 将各个接受线圈的K空间数据分别进行离散傅里叶变换,得到有混叠的图像,然后在图像空间利用各个线圈的灵敏度map信息,将对应线圈的混叠图像通过解混叠算法而形成一帧帧无混叠的中间图像,最后 把这些中间图像用平方和方法拼成一帧全视野的完整的图像。
灵敏度编码(sensitivity encoding, SENSE)是一种技术图像域的重建方法。SENSE方法 采用多个接收线圈用于信号采集,允许对K空间欠采样。欠采样的过程中会丢失一些空间编码信息,所以SENSE重建时,利用各个线圈的空间灵敏度对丢失的信息进行恢复,将混叠的图像进行展开,得到没有伪影的图像。
SENSE重建可以 减少K空间采集线数,缩短扫描时间。但是由于欠采样导致图像信噪比降低;而且SENSE重建需要估计线圈敏感度信息,重建过程比较麻烦;且线圈敏感度信息很难准确估计,其误差会导致重建图像伪影。
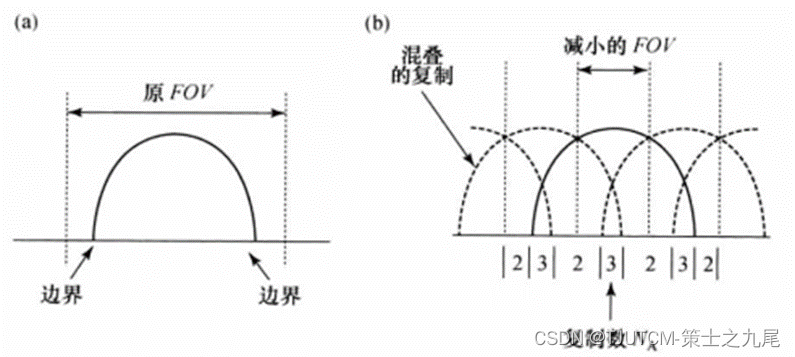
(a)图为正常的FOV。
(b)图为对于并行成像R=3降低的FOV。在y方向各位置混叠的复制数NA依赖于边缘位置和加速因子R。
SENSE方法要求估计线圈灵敏度,灵敏度可用另外的校准扫描来估计,校准扫描要覆盖用并行成像扫描的整个体积。另一个做法是通过用全奈奎斯特采样测量K空间中央部分,得到低分辨率灵敏度估计;而用欠采样测量K空间外围区域,以加速采集,可把这些步骤建立、集成在并行成像序列中。
规则化就是说给损失函数加上一些限制,通过这种规则去规范他们再接下来的循环迭代中,不要自我膨胀(正则化是为了防止过拟合)。
奇异值分解就是在低维空间中寻找最接近原矩阵A的低维矩阵M ,说白了就是 数据降维。
用传统平方和重建,由于各线圈欠采样,图像混叠程度或次数随R增大而增大。而用 SENSE重建的图像没有任何混叠伪影,只是在高R情况噪声分布不均匀。两个相位编码方向SENSE图像的噪声差很明显,源于其几何因子不同。对于下图所示线圈排列,显然选择竖直相位编码更优越。SENSE理论不对线圈构型、相对排列位置或者K空间采样提出任何限制。
SENSE 包括强重建技术和弱重建技术两种,前者严格地对每个体素的形状进行优化,而后者更多地关注信噪比。因为两种算法都是 混合编码重建,故不能直接使用快速傅里叶变换(FFT)。
SENSE技术的第一步就是让线圈阵列的每个线圈数据经离散傅里叶变换,形成各个有混叠伪影的图像;第二步是要 将第一步所得到的混叠图像解混叠后拼合而形成一帧完整的图像。
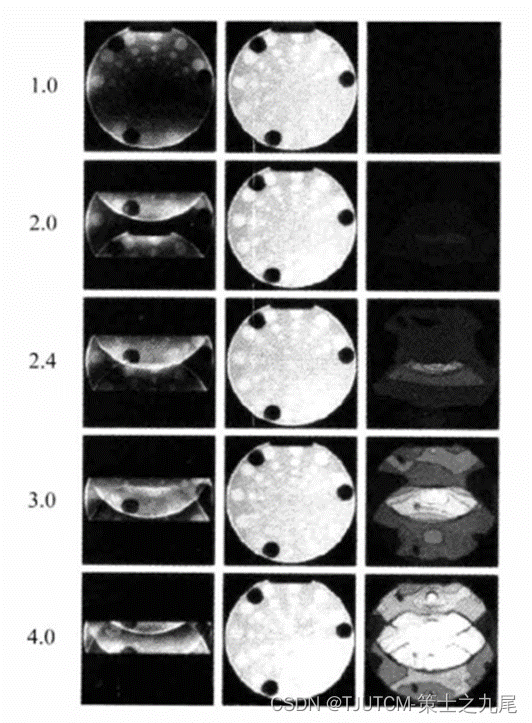
时间降低因子从1到4,相位编码在水平方向,左列是传统平方和像;中列是同样数据SENSE重建的像;右列是SENSE理论预期的噪声水平map。
SENSE也可推广应用于非笛卡尔K空间轨迹,比如径向轨迹、spiral轨迹等。对于spiral扫描和其他非直线K空间数据的具有最佳图像质量的并行成像重建算法要求矩阵求逆,被求逆矩阵比直线轨迹产生的矩阵大两个数量级。这样的矩阵一般要求迭代求逆方法,譬如共轭梯度法。
共轭梯度法 是求解稀疏对称正定线性方程组的最流行和最著名的迭代技术之一。用来求解线性方程A x = b 的一种方法,特别是稀疏线性方程组迭代求解法里面最优秀的方法,其被称为线性共轭梯度法。后来,人们把这种方法慢慢推广到了非线性问题求解中,称为非线性共轭梯度法。
三、SMASH重建
SMASH方法将线圈的灵敏度信息和各线圈欠采样的数据均放在K空间中处理,通过拟合线圈灵敏度构造出低阶空间谐波成分,并利用各线圈欠采样的K空间数据建造对应全视野的复合K空间数据,然后经一次傅里叶变换得到无伪影的终像。
SMASH重建算法通过线圈采集的原始数据和灵敏度的线性组合,恢复因欠采样而丢失的K空间相位编码行数据。利用线圈灵敏度提供接受信号的空间权重,线圈灵敏度的线性组合可近似给出缺失的空间编码行所对应的复指数函数。
与线圈阵列中线圈数目相等阶次的谐波有时难以构建出来,而推广SMASH可用靠近Km+1行的第一个负谐波来代替靠近Km行的第二个正谐波。因合成较低谐波,比合成高谐波更准确。
另一个推广是 块重建,用多测量行合成缺失的谐波行Km+pΔK。这种推广提高了拟合精度,特别是对于难以用线圈灵敏度线性组合来逼近的复指数函数的线圈排列。构建缺失的K空间行所用测量行越多,图像质量越好,代价是重建速度越慢。
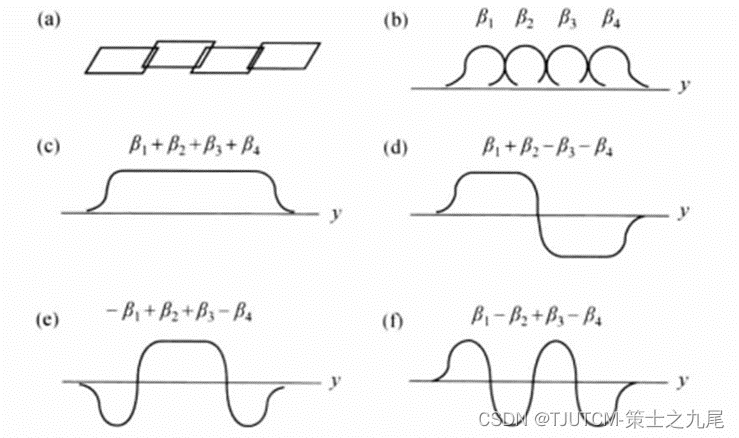
(a)图为可用于SMASH的四线圈阵列
(b)图为线圈灵敏度
©图为线圈灵敏度之和(1)
(d)、(e)、(f)为灵敏度组合
对于SMASH最佳线圈几何或许是沿一直线放置的线圈阵列,虽然对于任意线圈几何SMASH也能产生高质量图像。并行成像也可应用到3D扫描的第二个相位编码。在高场SNR很高,并行成像最有用,最成功的应用之一是对比剂增强的MRA。降低扫描时间对于捕捉团注通过的峰值,缩短屏住呼吸时间是有利的。用SSFP梯度回波序列(比如True FISP)对心脏扫描给出足够的SNR允许加速因子R>=2。这导致较短的屏住呼吸时间、较好的空间分辨或时间分辨。
大多数线圈阵列都专门设计得灵敏度之和近似是一常数,为的是能 给出近似均匀的图像信号(对于均匀物体)。
四、灵敏度校准
所有并行采集成像的图像质量都取决于线圈灵敏度的估计,差的估计将导致有些混叠无法校正及SNR低。
(1)直接灵敏度测量:用较低空间分辨率测量数据,以节省时间,采集的图像数据的体积必须包围用并行成像重建的整个区域,校准扫描通常是二维(2D)或三维(3D)梯度回波。也可在并行成像扫描时用可变密度采样,即 在靠近K空间中心的行用奈奎斯特频率采样,而高K空间区域用欠采样,低K空间数据用于重建低分辨率的灵敏度map。
(2)间接灵敏度测量:在间接灵敏度测量方法中,在K空间中央(额外)采样一或多个奈奎斯特行,类似于自校准方法。这组奈奎斯特采样行被称为自校准信号,避免了在校准扫描和并行成像扫描之间病人运动带来的不一致问题。
间接灵敏度测量中,因为 校准行是全采样的,比分开的校准扫描和并行成像扫描加起来的总时间短。自校准扫描也可用在并行成像重建中,从而减少了必须校正的固有混叠量并且给出更高的SNR。
3)目标函数归一化:不论是SENSE还是SMASH,最终图像的强度权重可通过适当归一化表面线圈灵敏度数据而进行操纵。各终像是被目标灵敏度加权的,可让其表面线圈校准像被体线圈校准像除,乘以带体线圈灵敏度权重的SENSE像,将产生一个相对均匀的图像。目标函数归一化不影响SENSE图像中的SNR(相当于对其同时乘以信号和噪声)。
灵敏度归一化问题:并行成像技术所重建的图像总有一些线圈灵敏度权重。因为所有MR数据都无法避免被线圈灵敏度加权,纯线圈灵敏度测量是不可能的。
如果线圈的空间灵敏度map能够相当准确地得到,则应首选SENSE。如果采集的线圈灵敏度map较差,应选用自校准技术如GRAPPA(例如病人运动包括呼吸运动,导致采集的线圈灵敏度map很差,特别是在线圈边缘,其灵敏度变化比较急剧)。又譬如在单射EPI中,某些区域严重畸变,线圈灵敏度map也很差。
最佳灵敏度校准取决于不同的应用。如果病人呼吸运动是关注的问题,为 最小化校准 和 并行成像数据之间的不一致,自校准可能是优越的。然而,如果运动不一致并不是主要问题,而扫描时间很重要,例如对比度增强的体MRA或实时成像,分开的校准可能是优越的。
如果用较高的加速因子(例如R>=4),也应该选择分开的校准扫描。因为随加速因子增大,在总扫描时间中自校准扫描占据较高百分数。GRAPPA和AUTO-SMASH本身被限制到自动校准。这种情况,在ACS行数与扫描时间之间必须这种。更多的ACS行一般导致更好的图像质量,但要付出扫描时间长的代价。
五、AUTO-SMASH和VD-AUTO-SMASH
AUTO-SMASH是SMASH改进的具有自校准功能的变型。SMASH扫描时,采R-1行,用于自动校准。
以K空间测量行和附近缺失行构成一块(block)的话,AUTO-SMASH只有K空间中心一块的采样是满足奈奎斯特判据的,而(变密度)VD-AUTO-SMASH则在K空间中央区域有不止一块的采样时满足奈奎斯特判据。
在VD-AUTO-SMASH中,采一组或多组额外的ACS行以改进拟合的精确性,得到更好的线性权重因子aj,p。同一个aj,p可用来计算填充缺失的K空间行。像对传统SMASH那样,代替用Km的正谐波合成缺失的行,可用Km+1的负谐波合成这些缺失的行,以尽量提高拟合的准确性。
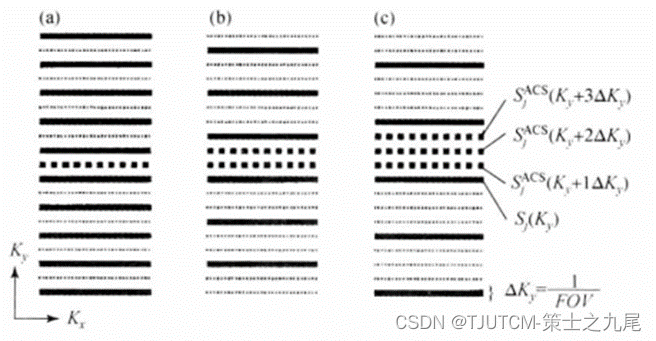
实线表示测量的K空间行,小点线表示缺失的K空间行,在中间区域额外测量的奈奎斯特采样行(大点线)即ACS行用来确定合成缺失行(小点线)的权重因子,相位编码在竖直方向
((a)R=2,(b)R=3,©R=4)
这些额外采集的ACS行是用传统相位编码梯度编码的,这些参考行SjACS和通常SMASH信号行之间的关系可用来确定线性权重因子aj,p
六、GRAPPA重建
GRAPPA是在AUTO-SMASH和VD-AUTO-SMASH基础上改进的一个并行成像方法。不是从单一测量行合成缺失的K空间行,而是从一组测量行来合成缺失的K空间行;而且在GRAPPA中,合成的是各个单线圈的K空间行,而不是对应全视野的复合的K空间行。
这一过程对阵列中的各线圈重复进行,产生Nc个单线圈像,然后 用传统平方和(SOS)重建拼合成一帧完整的终像,这样就有更好的拟合准确度和更高的SNR。
平方和(SOS)算法被认为是在不知道各个相控阵线圈确切的灵敏度情况下最优的图像合成方法。但平方和算法对各个线圈图像采用相等的权重进行合成,同时 对外部噪声不能很好地抑制,导致得到的最终图像存在信号偏差、信噪比低等问题。
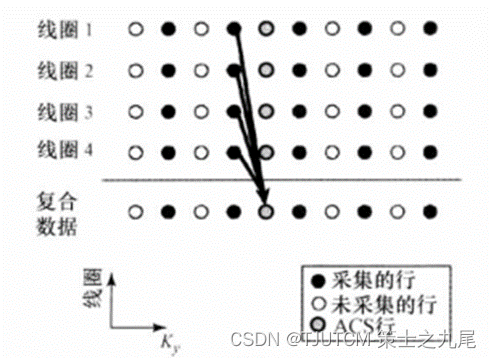
AUTO-SMASH和VD-AUTO-SMASH的K空间ACS行数据重建机制,从多线圈测量行数据合成全视野的符合校正行数据(此例中采集的4行数据用于拟合出覆盖全视野的复合数据)。
GRAPPA假设是:一个单线圈的K空间中每个数据点都可用所有线圈的K空间邻近数据点的线性组合来代表,并且线性组合权重集在K空间位移不变。
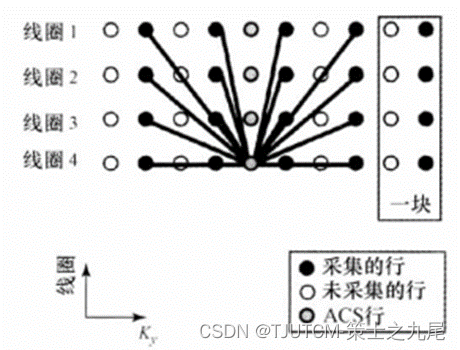
GRAPPA的K空间ACS行数据重建机制,阵列中各个线圈中采集的多块测量行被拟合到阵列中一个单线圈中采集的ACS行(此例中采集的4行数据用于拟合进4号线圈中一个单ACS行,各个圈代表在单一单线圈中采集的数据行)。
用多块测量的K空间行来合成缺失行时,考虑到附近行贡献的信号起支配作用,往往 根据待合成的行的位置来移动测量行块,被称为“滑动块重建”。
因为各块测量行一般对缺失行给出不同的估计,而这一估计可用加权平均组合,以给出更高的SNR和更好的拟合为选择组合的判据。
GRAPPA是一种基于K空间的重建算法,它以满足奈奎斯特采样定律要求的频率采集K空间中心数据作为自动校正数据(Auto-Calibration Signal,ACS),利用多通道K空间相邻的点线性相关性进行每个通道的K空间欠采样的填充,得到每个通道的全K空间,最后通过通道融合(SOS or ACC)得到最终的无卷褶图像。
为重建K空间中缺失的行数据,需要 分两步进行。第一步是校准,即利用K空间中心附近全采样数据行对重建权重A进行校准;第二步是利用校准的A(具有K空间位移不变性)和已测量的行数据合成高K空间缺失的数据。

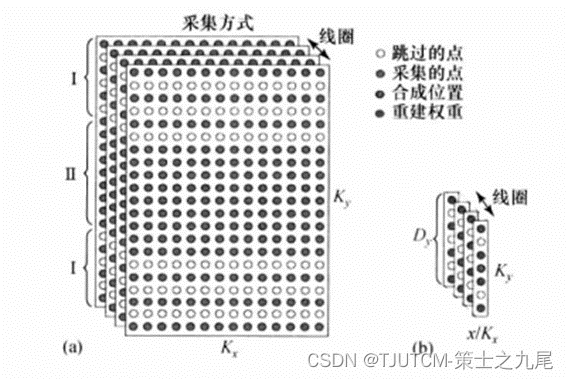
(a)GRAPPA数据采集方式。四线圈中每一个K空间数据都是每隔一相位编码行采一行,以加速采集(R=2)。在K空间中心额外采若干ACS行,以形成全采样校准区域(Ⅱ)。高K空间(Ⅰ)是欠采样的,降低因子R=2。
(b)假定采样方式如(a)所示,由GRAPPA产生的重建权重A的空间表象。
位移不变性指的是 无论物体在图像中的什么位置,卷积神经网络的识别结果都应该是一样的。如果物体在图像中所处的位置,对于模型的预测结果不会产生任何影响,那么就可以说它具备了 位移不变性。因为CNN就是利用一个kernel在整幅图像上不断步进来完成卷积操作的,而且在这个过程中kernel的参数是共享的。这样一来理论上就具备位移不变性了(当然,受限于 步进跨度、 卷积核大小 等因素的影响,某些条件下CNN也可能会存在“漏”的情况)。
目标点总数Nt对于重建来说代表训练例数目。一般来说,训练例数目越大,拟合过程越精确。采更多的ACS行用于增大可利用的训练例数,但以牺牲效率为代价。因为重建是位移不变的,校准可在沿Kx方向所有Nx位置进行,这就进一步增大了Nt。我们称这样的校准策略为“全宽度读出校准”。
原始GRAPPA重建,校准和合成都是在K空间进行的,因此称为“K空间重建”,而且原始GRAPPA重建用的是K空间1D邻居重建。为了提高精度,也可以推广到K空间的2D邻居重建。而且由于系统的线性和FT的可分离性,GRAPPA也可等价地在混合空间(x,Ky)中进行,只要把数据沿Kx进行1DFT,就可以变换进混合空间(x,Kx)中进行,只要把数据沿Kx进行1DFT,就可以变换进混合空间。在混合空间重建时,校准和合成的所有步骤都保持不变,权重系数也一样。对于K空间1D邻居coil-by-coil重建,在混合空间并没有精度或效率优势。然而,推广到K空间2D邻居[Dy*dx]的coil-by-coil重建时,一般是具有精度优势。
七、SPACE RIP重建算法
SPACE RIP算法把pMRI重建表示成一个矩阵求逆问题。这个算法要求很大的矩阵求逆,因此有 很长的重建时间。其优点是灵活度高,任何K空间轨迹都适用,线圈排列也可以是任意的。
图像中的各列是分别重建的。假若图像有N行M列,则矩阵方程中x应取1-M个离散值,对应有M个这样的方程。要重建M列图像,需要对M个灵敏度相位编码矩阵求逆。这里的矩阵不必是方阵,对每一列必须计算其广义逆矩阵。相位编码步数F的选择影响重建质量。增大F导致矩阵的秩增大,产生的广义逆矩阵的条件数好,噪声放大的程度低,信噪比高,但代价是 重建计算量增大。
由于 SPACE RIP对线圈阵列排布的要求不苛刻,所以很适合3D并行采集。

左边的项是有Nc* F个元素的矢量,对于所有Nc个线圈,包含F个相位编码值;最右边的项是代表一列元素的像的N元矢量;中间项是一个有Nc*F行和N列的矩阵,是基于灵敏度轮廓和所用的相位编码构成的。
对于沿x轴各个位置解方程产生图像诸列的重建。
相控阵线圈敏感度值并行编码和重建(SPACE RIP)技术的优势是可以灵活机动地选择K空间的相位编码位置,重建出来图像较其他种并行成像算法有更少的混叠伪影。
八、PILS重建算法
PILS重建算法依据线圈灵敏度区域的中心位置y0和沿相位编码方向的局部成像视野yc的先验知识,在加速因子R小于线圈数Nc的条件下,相位编码步数Ny对于全FOV来说是不满足奈奎斯特判据的欠采样,然而 对于每个单元线圈覆盖的局部FOV来说是满足奈奎斯特判据的全采样。
阵列中各单元线圈采得的数据主要是由近区贡献的,仅在局部区域做傅里叶变换,可得到几乎无混叠伪影的局部图像,然后按照平方和方法拼成全视野图像(剪刀方法)。这种算法很适合 **线圈灵敏度没有交叠**的情况,对于非直线K空间轨迹比如spiral扫描的并行成像数据重建,为最快的算法。
在通过利用线圈灵敏度编码补充梯度编码来加速数据采集这一点上,几乎所有方法都是相同的;在如何解决重建问题以产生最后无混叠图像这方面,则是不同的。基于线圈灵敏度如何从多通道数据被编码可分为两类,即基于物理的重建和基于数据驱动的重建:
第一类pMRI方法包括要求线圈灵敏度函数的明晰的认识以分离混叠信号,比如SENSE、空间谐波同时采集SMASH、改进的SMASH、推广的SMASH、SPACE RIP、PILS、任意K空间轨迹SENSE等。称这类pMRI为“基于物理”的重建,因为其模型与图像采集期间发生的物理过程紧密相关。SENSE是最典型的基于物理的重建算法,所有线圈灵敏度map必须明确地估计出来,因为要用这些map在图像域对图像进行解混叠。基于物理的pMRI方法所重建的图像容易遭受线圈灵敏度校准造成的伪影,比较普遍的校正误差源包括不足够的SNR、Gibbs跳动、运动伪影或受限的FOV。
第二类pMRI方法不要求明晰的线圈灵敏度信息,而是用数据拟合方法通过计算邻近源数据来重建目标数据的线性组合权重,然后利用已测量的数据和这些相应的权重重建出缺失的K空间数据。称这类方法为“数据驱动”重建,因为这些方法基于有限的底层物理过程知识,而依靠训练数据来校准输入(源)数据和输出(目标)之间的关系。这类方法包括AUTO-SMASH、VD-AUTO-SMASH、GRAPPA等,都属于数据驱动重建方法。其中GRAPPA执行coil-by-coil重建,提供了改进的图像质量。由于不要求线圈灵敏度map,coil-by-coil data-driven(CCDD)方法比基于物理的方法更优越,尤其对于精确的线圈灵敏度估计十分困难的情况。
九、PRUNO重建算法
GRAPPA重建在低加速因子能产生很好的图像质量,而加速因子很高时其性能显著退化,除非强加大数目的自校准行(ACS)。而PRUTO是迭代K空间数据驱动pMRI重建算法,比GRAPPA更灵活。
在PRUNO中,数据校准和图像重建化为线性代数问题,迭代共轭梯度算法有效地用于解重建方程,得到的图像质量比GRAPPA更高,而要求的ACS行并不很多,尤其在高加速因子更具优势。
来自所有接受通道的K空间样本本质上是线性相关的,这是灵敏度编码固有性质的一个结果。一旦非零系统矩阵N可以确定,可利用方程ND=0来求解pMRI重建问题,这就是该步骤被命名为PRUNO(parallel reconstruction using null operations)的理由
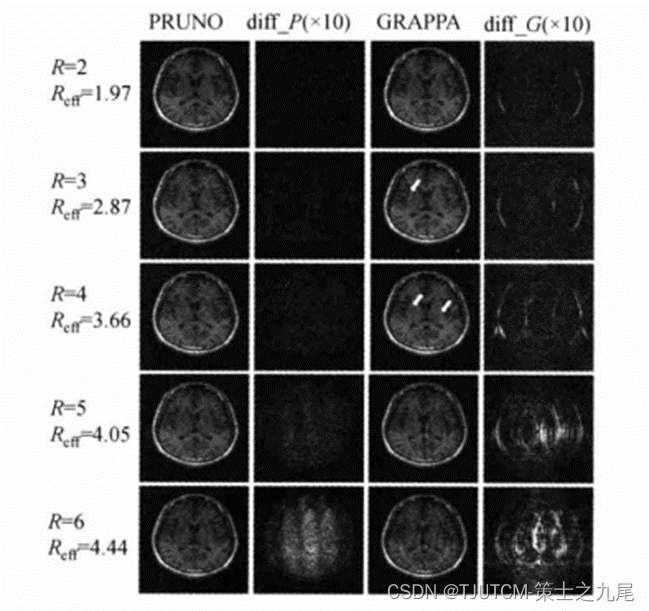
所用加速因子R=2-6,为便于比较差像夸大了10倍,ACS数据也包括在内导致Reff<R。对于GRAPPA,在R=3-4时伪影已经明显可见;而对于PRUNO,只要R<6(Reff<4),图像质量都不错,而且误差(aliasing)分布均匀。
关于线圈灵敏度编码,有两个重要假设如下:
假设1:所有灵敏度map都是带限的,在K空间总宽度为ws,因为线圈灵敏度map在性质上是平滑的,ws通常近似为一个合理的小数目。
假设2:总的灵敏度编码产生良好的正交性。即如果Nc>R,pMRI重建可处理为一个过定问题,并且K空间采样是比较均匀的(R是加速因子,Nc是线圈数)。
这里的N表示非零系统矩阵,其各行通过乘所有线圈的K空间样本而化为零。
十、UNFOLD算法
UNFOLD方法应用于快扫描,类似于并行成像。但只可用于时间序列图像,采样K-t空间,例如功能成像系列、动态成像系列或多相心脏成像序列。UNFOLD用空间混叠以减少扫描时间,在这一点上类似于并行成像,但转换空间混叠为时间混叠,并用时间滤波器消除。
与并行成像不同,UNFOLD不要求多线圈。但UNFOLD也可以与并行成像结合,进一步提高扫描速度或者降低伪影。

![input时间表单默认样式修改(input[type=“date“])](https://img-blog.csdnimg.cn/afcaeb1a697e4aa1b4f3e35c17c04df1.png)