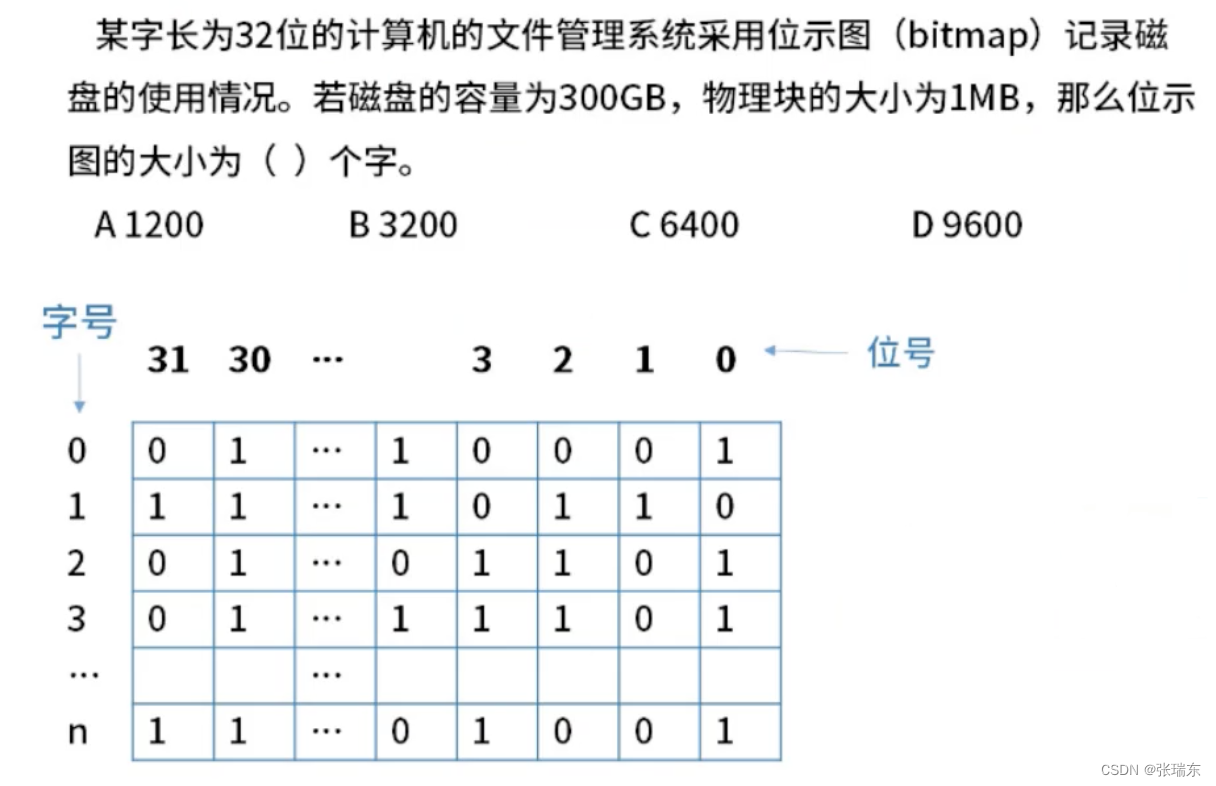
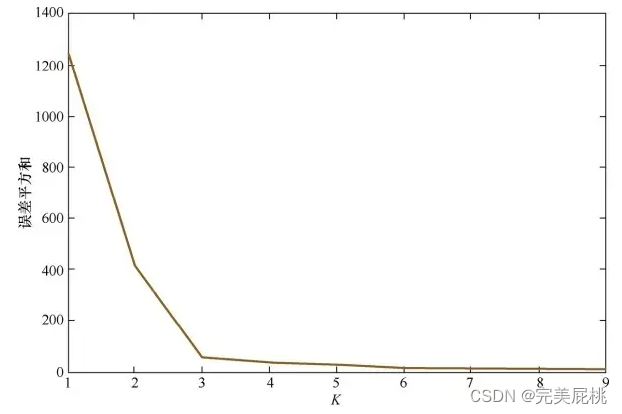
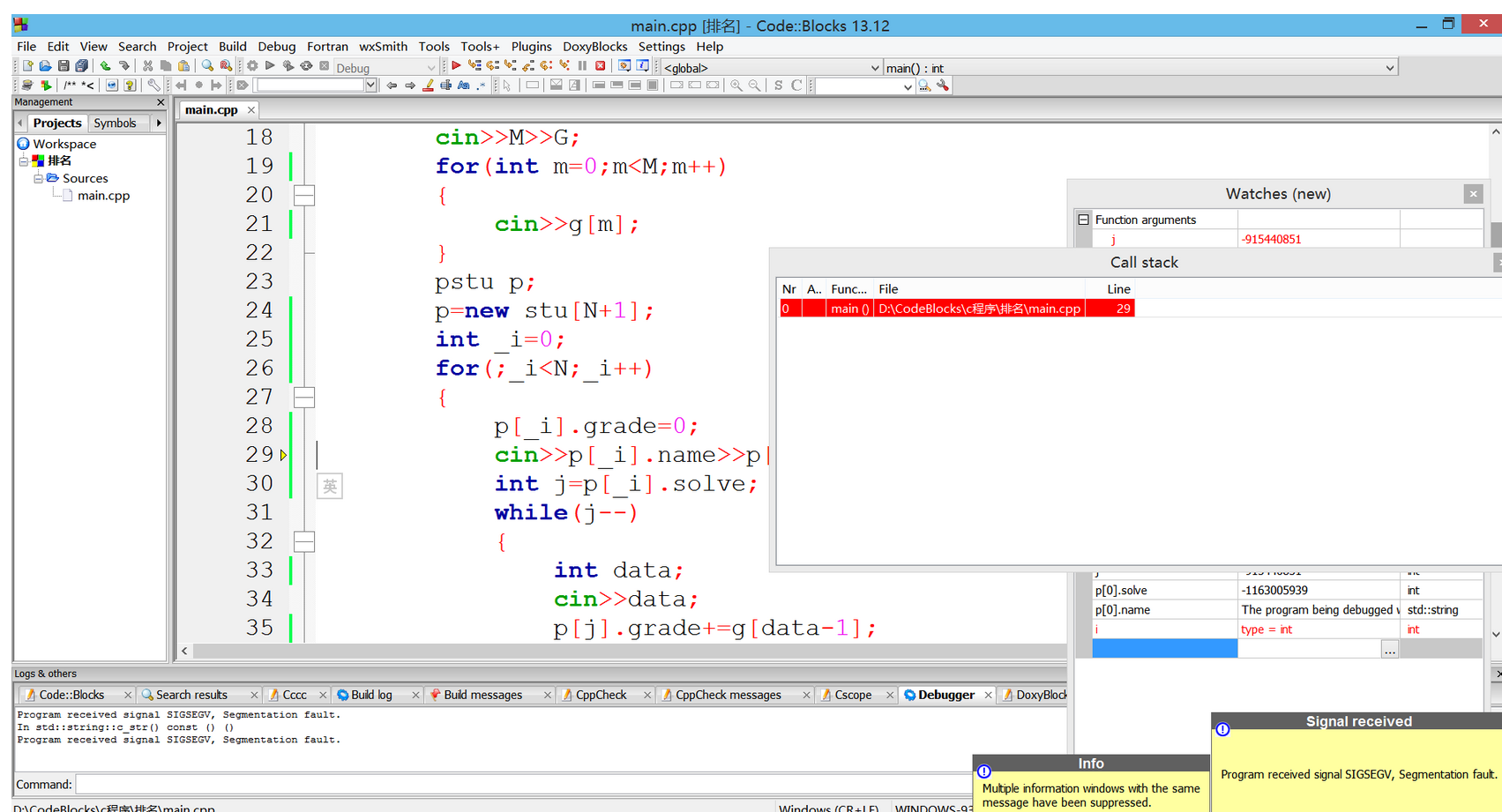
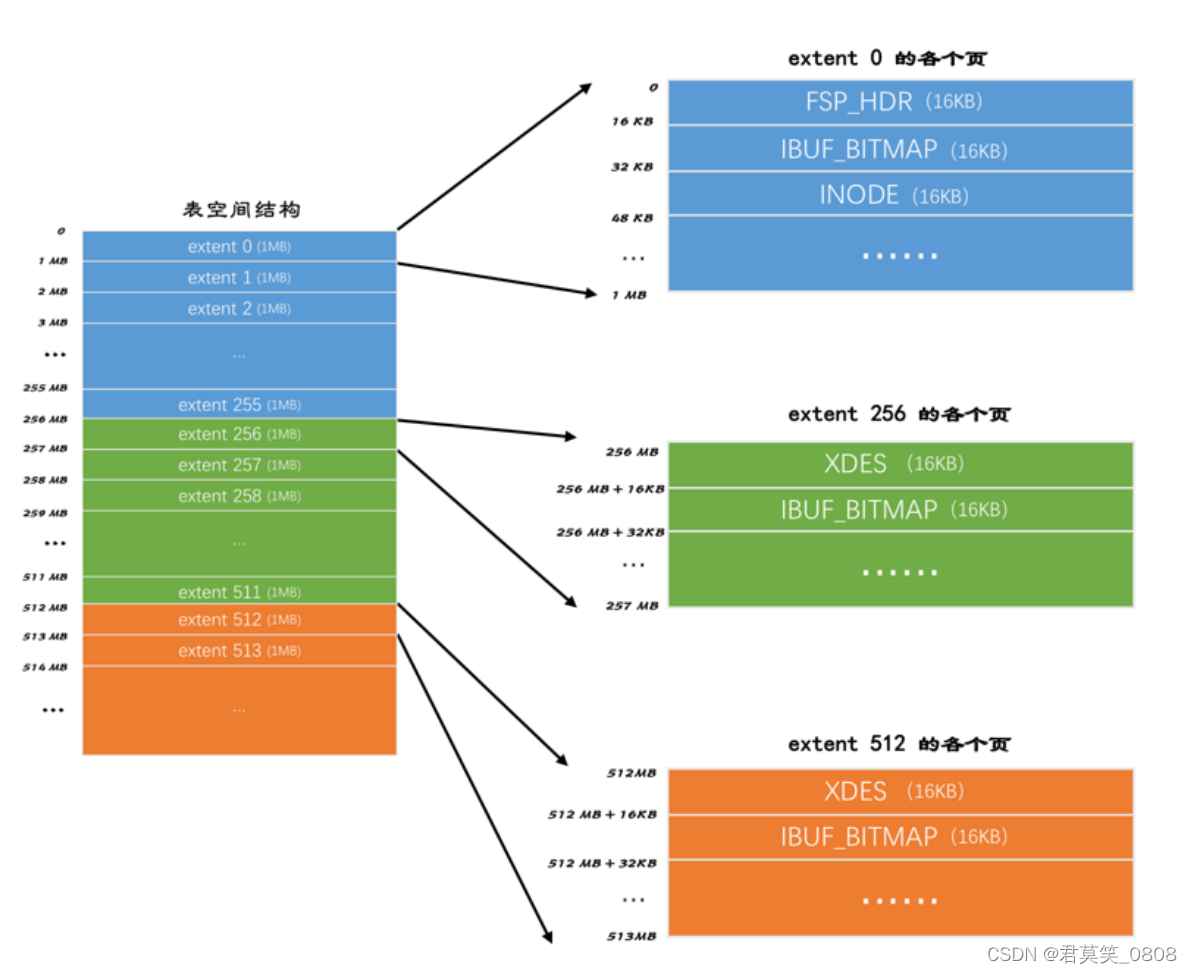
静态网页爬取练习
- 中央气象局预报简介
- 前期准备步骤
- Python爬取每日预报结果—以降水为例
中央气象局预报简介
-
中央气象台是中国气象局(中央气象台)发布的七天降水预报页面。这个页面提供了未来一周内各地区的降水预报情况,帮助人们了解即将到来的降水情况,以做出相应的应对措施。页面中的预报内容通常包括以下要点:
-
地区分布:页面展示了中国各地区的降水预报情况。各地区可能会以地图、表格或其他形式展示,以显示降水预期的空间分布。
-
时间范围:预报涵盖的时间一般为未来一周,通常显示的是每日的降水预报。用户可以根据这些信息来预测未来几天的降水情况。
-
预报值:每个地区的预报值通常以毫米(mm)为单位,表示在特定时间段内预期的降水量。这可以帮助人们了解降水的强度和持续时间。
-
趋势分析:有些预报页面可能提供关于未来几天降水的趋势分析,例如是否逐渐增加或减少,以及可能的降水类型(如雨、雪、冻雨等)。
-
预警信息:有时,页面可能还会显示与降水相关的预警信息,例如暴雨、大雪等气象灾害预警,以提醒人们采取相应的预防措施。
-
前期准备步骤
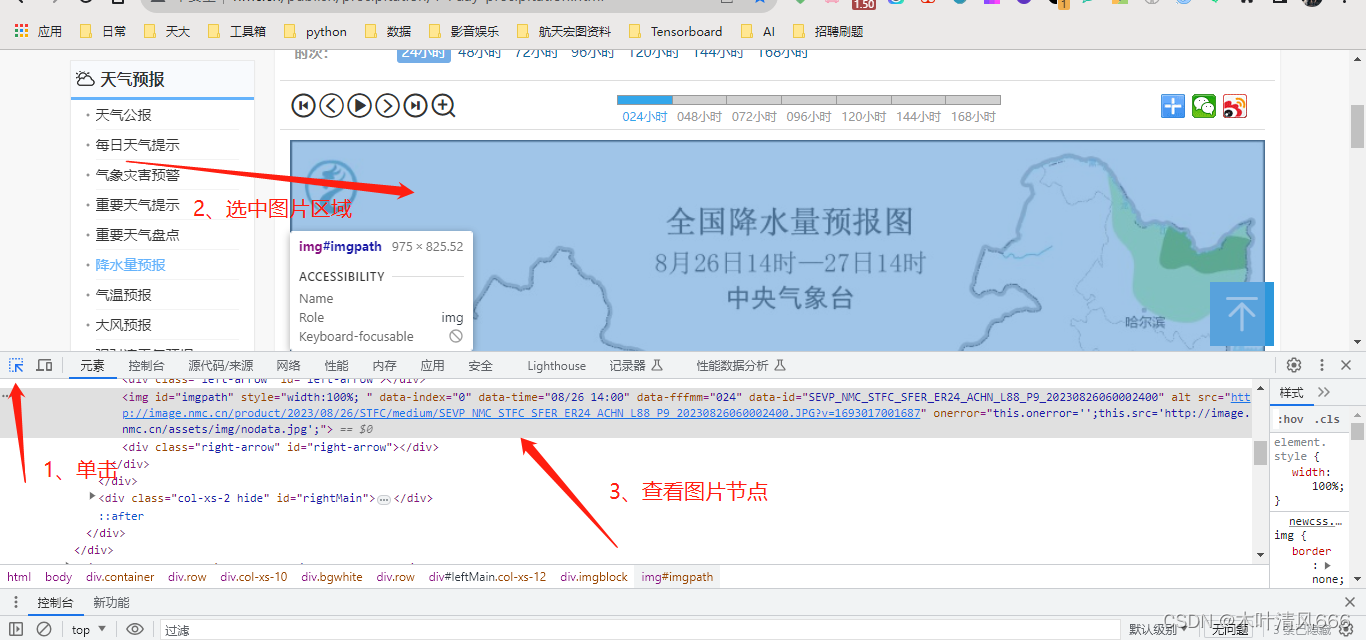
- 打开中央气象局网站http://www.nmc.cn/publish/precipitation/1-7day-precipitation.html,单击右键,检查
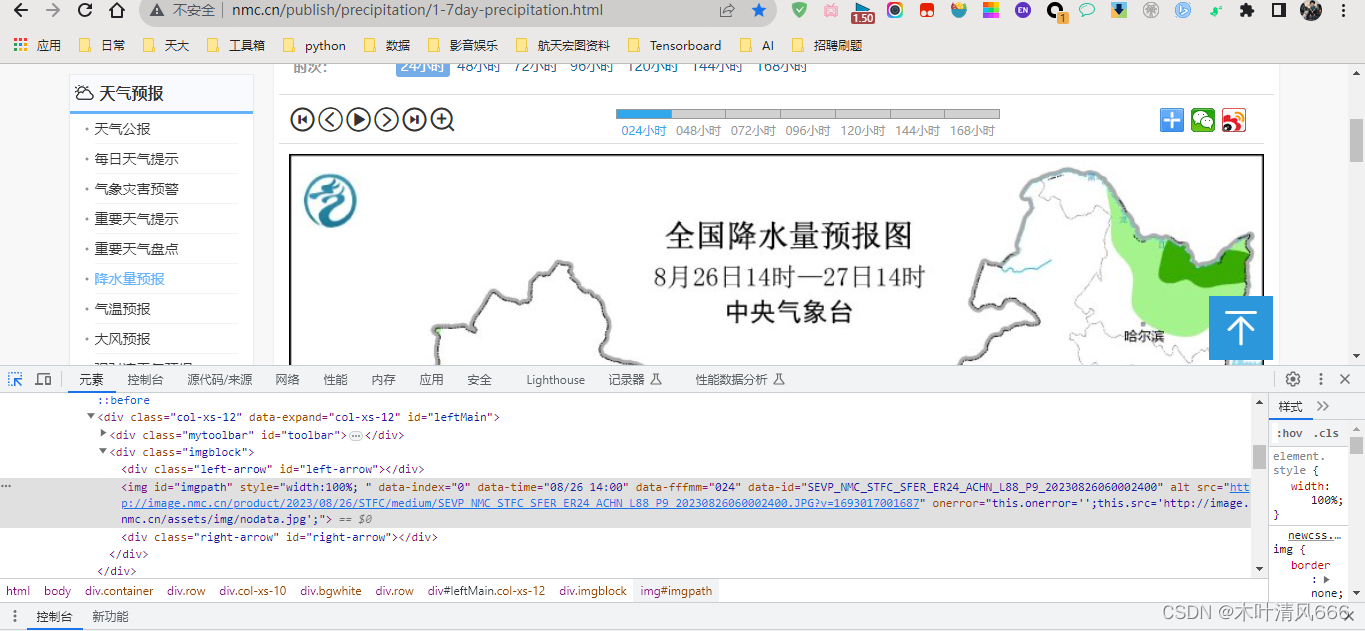
- 查看图片节点
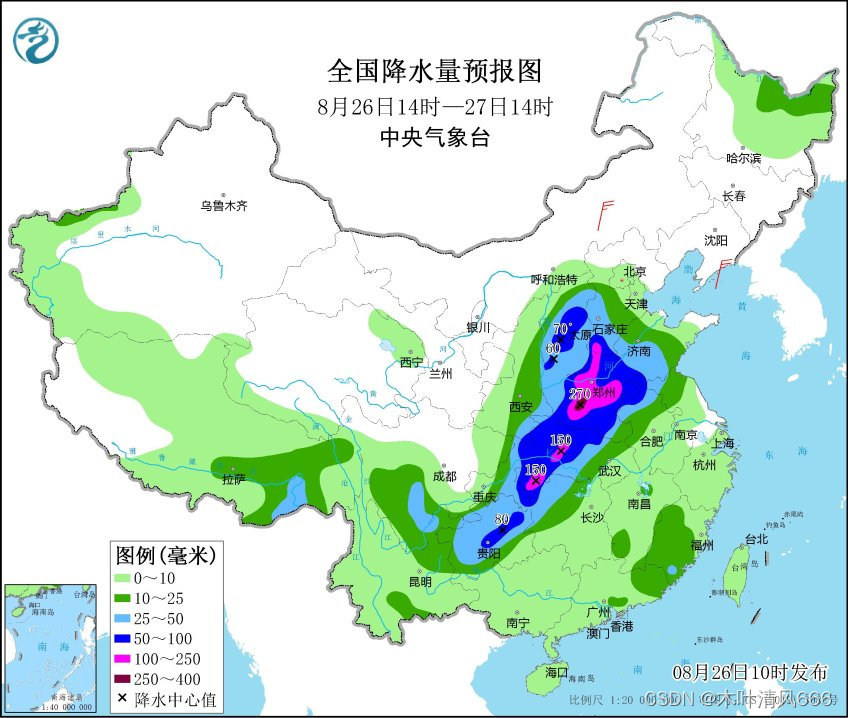
Python爬取每日预报结果—以降水为例
- python代码爬取
import requests
from bs4 import BeautifulSoup as BS
# 获取中央气象局HTML信息
url = requests.get("http://www.nmc.cn/publish/precipitation/1-7day-precipitation.html")
# 解析中央气象局HTML信息
url_soup = BS(url.content, 'html.parser', from_encoding='utf-8')
# 查找网页中的预报图像 —— 查看网页源码,查找相应内容
image_node = url_soup.find('img', id='imgpath')
# 获取预报图像链接
image_url = image_node["src"]
# 获取图像
response = requests.get(image_url)
image_data = response.content
# 保存图像
with open('downloaded_image.jpg', 'wb') as f:
f.write(image_data)
print("图片已下载并保存为 downloaded_image.jpg")
- 爬取结果



![[Android AIDL] --- AIDL工程搭建](https://img-blog.csdnimg.cn/d82923ad99334993ab634ef916cc5ad1.png)