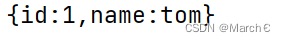1.Maxwell的配置
其实就是配置两端的配置信息,都要能连接上,然后才能去传输数据
config.properties
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db
# MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 过滤gmall中的z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log
# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_key
2.群起脚本
#!/bin/bash
MAXWELL_HOME=/opt/module/maxwell-1.29.2
status_maxwell(){
result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`
return $result
}
start_maxwell(){
status_maxwell
if [[ $? -lt 1 ]]; then
echo "启动Maxwell"
$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemon
else
echo "Maxwell正在运行"
fi
}
stop_maxwell(){
status_maxwell
if [[ $? -gt 0 ]]; then
echo "停止Maxwell"
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
else
echo "Maxwell未在运行"
fi
}
case $1 in
start )
start_maxwell
;;
stop )
stop_maxwell
;;
restart )
stop_maxwell
start_maxwell
;;
esac
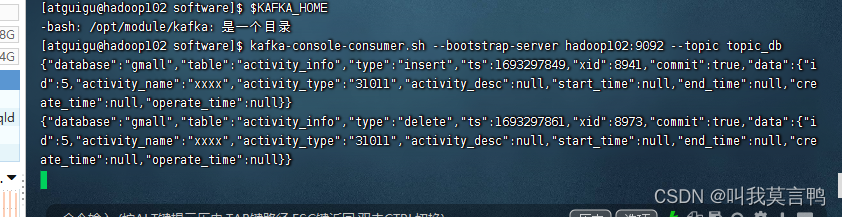
- Kafka消费者开始等待消费
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_db
4.全量同步
/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/module/maxwell/config.properties
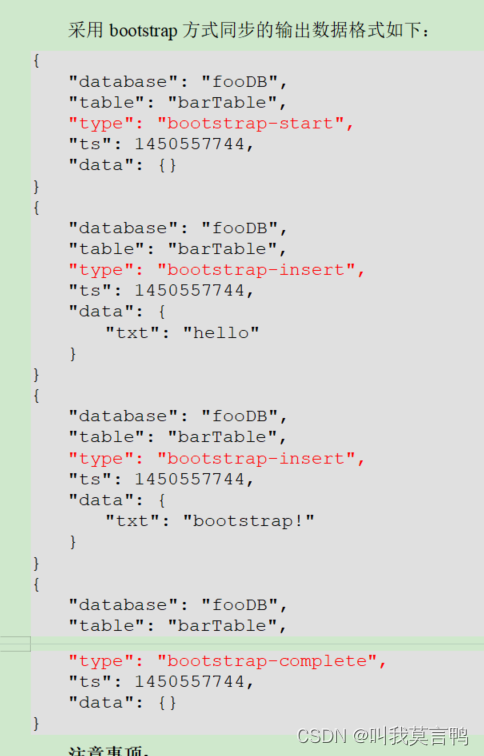
每条数据都有时间戳,这个时间戳是同步的时间
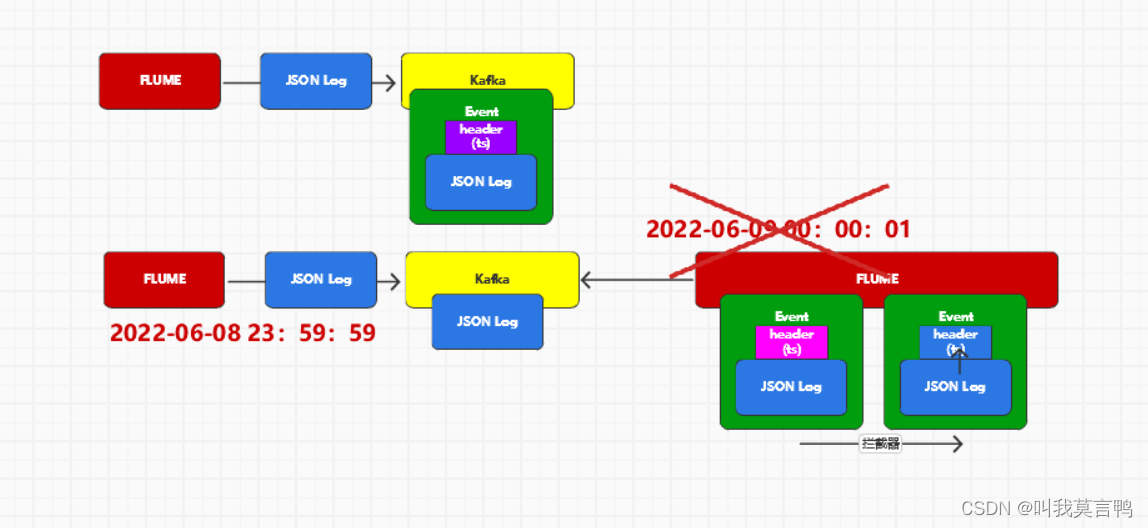
5.为什么Kafka后面需要拦截器?
零点漂移,当为一天末点时,时间戳还是末点,但是到第二个Flume时,时间戳更新,这时候直接到第二天,导致数据与时间不一致.