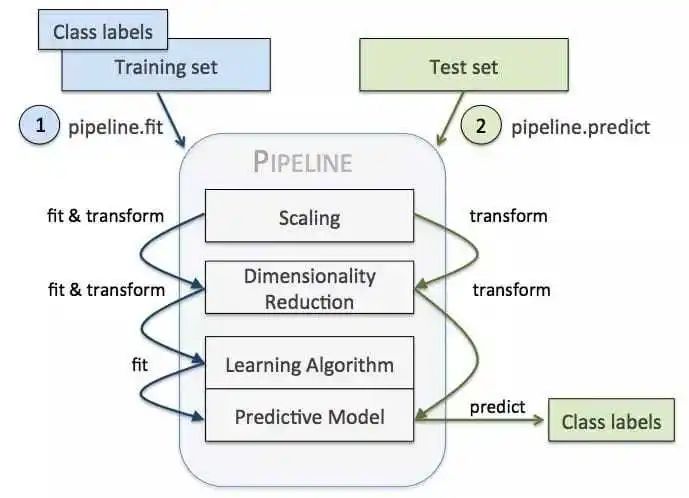
重传机制,流量控制,拥塞控制
1.重传机制:
序列号+确认应答 当发送端的数据到达接收主机的时候,接收端主机会返回一个确认应答消息,表示已经收到消息
当数据发生丢包时,用重传机制解决
重传机制有好几种:超时重传,快速重传,SACK,D-SACK
超时重传:
发送端发送数据后,如果超过指定时间(RTO,超时重传时间,略大于包往返时间RTT,RTT是在动态变化的,所以RTO也是在动态变化的)还没有接收到接收端的ACK确认,就会重新发送数据,
下一次超时重传时,会将下一次超时时间设置为先前值的两倍,两次超时,就说明网络环境差,此时不宜频繁发送
快速重传:
发送端收到3个重复的ACK时,就会触发快速重传,发送端立刻重发丢失的数据包
举例如下:
发送方一共发出五份数据,但是第二份数据(Seq2)丢失了

当收到第一份数据后,接收方发送一个ack2(这是一个正常的ACK),表示期望接下来希望接收第二份数据(编号为2),但是由于第二份数据缺失了,于是发送方并没有接收到ack2
发送发继续发送第三份数据,当接收方接收到第三份数据后,由于没有接收到ack2,所以并没有发送ack4表示希望接下来接收第四份数据,而是再次发送ack2.......
发送端收到了三个 ACK = 2 的确认,知道了 Seq2 还没有收到,就会重传Seq2
最后,服务器收到了Seq2,然后检查一下自己接收到的最大序号是多少,原来是5,于是向客户端发送ack6,表示下一份想接收到的数据是Seq6
这种方法问题在于:如果出现连续丢失多个包的情况,比如Seq2数据包丢失了,Seq3数据包也丢失了,然后成功发送Seq4,Seq5,Seq6,最后客户端重传了Seq2数据包,服务端收到后,就会检查此时收到的最大序号是6,于是向发送方发送ACK7,此时Seq3就彻底丢失了
SACK可以解决连续丢失多个包的情况
SACK也是接收到三个连续重复的ACK就触发重传
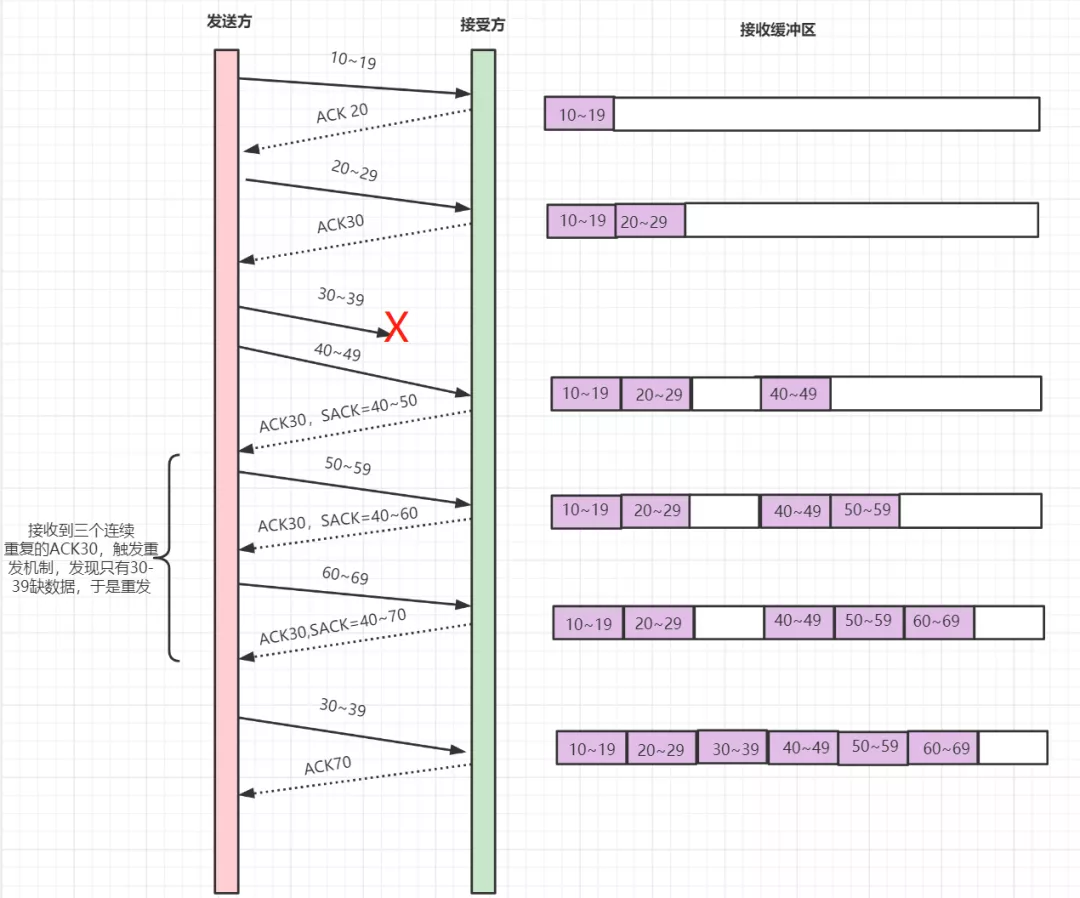
一旦接收端没有收到想要的数据包,发送给发送方的报文中就会带上SACK字段,即ACKX,SACK=M~N,这表示X~M-1的数据包没有成功发送,M~N-1的数据包被成功发送了
比如ACK30,SACK=40~50表示30~39的数据包没有成功发送,40~49的数据包成功发送了
这样就可以解决连续丢包的问题,比如如果连续丢了30~39,40~49两个报文,于是向发送方的报文就是ACK30,SACK=50~60或者ACK30,SACK=50~70......
D-SACK
SACK机制 SACK字段后面只带一个区间
D-SACK机制 SACK字段后面有两个区间
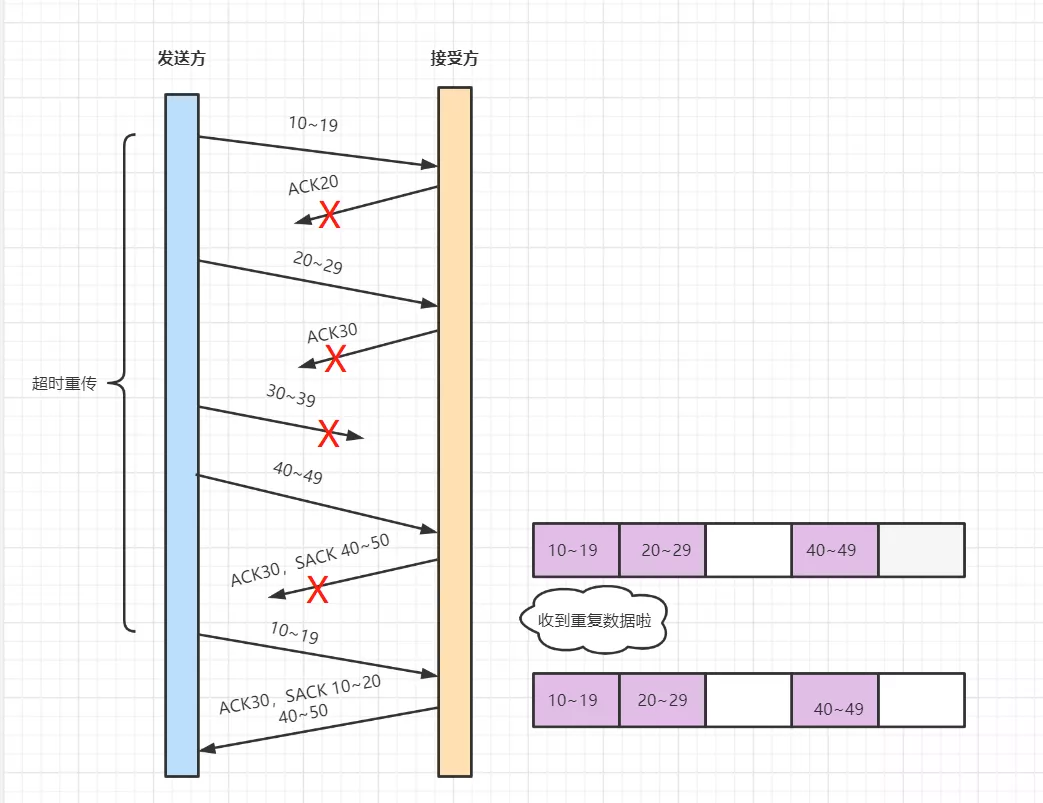
先是连续两次丢失了ACK确认报文
然后又丢失了一次发送报文
然后又丢失了ACK确认报文
最后发送端发送了一个重复报文,接收方发送一个ACK报文(只有发送了重复数据报,才会发送后面带两个区间的SACK字段,否则只发送带一个区间的SACK字段)
ACK30 SACK=10~20 40~50表示你刚刚发送没呢个10~19号已经发送过了,现在是30以前的都有了,40~50也有了,就差30-39没有发送成功了 (也就是SACK第一个字段表示刚才发的那个数据包是重复数据报,第二个字段表示ACK30后面已经收到的数据报)
2.流量控制
控制发送方发送速率,保证接收方来得及接收
TCP 利用滑动窗口实现流量控制,发送方有一个发送方的窗口,接收方有一个接收方的窗口
(发送方的窗口不能大于接收方的窗口大小,否则接收方接受不过来)
接收方给发送方的确认报文里面有一个窗口字段,规定发送方窗口大小,从而影响发送方的发送速率(如果窗口字段为0,表示发送方不能发送数据了)
发送窗口:
可以划分为4个部分:①已经发送并确认②已经发送未确认③未发送但是即将发送的④不能发送的
发送窗口大小就是②已经发送未确认+③未发送但即将发送
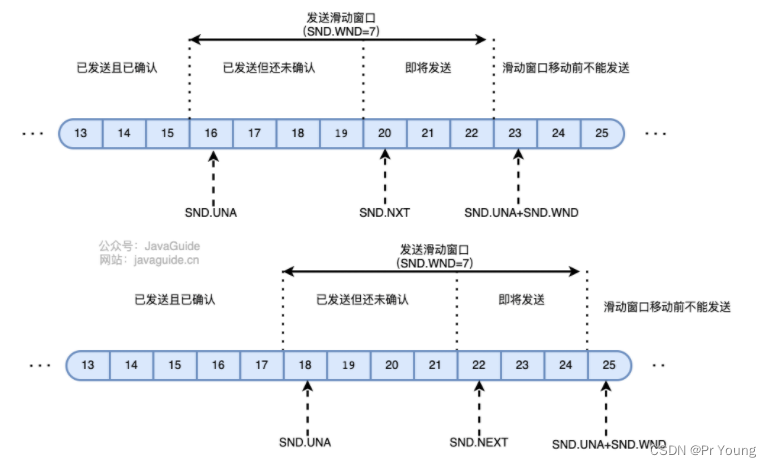
接收窗口:
可以划分为3个部分:①已经接收并确认 ②等待接收还没有接收③不能接收
滑动窗口大小=②等待接收还没有接收
3.拥塞控制
为了避免网络拥塞而采取的对发送方发送速率的控制
发送方会感知网络的拥塞程度(发送方如何感知当前这个网络存在阻塞?只要发生丢包事件,也就是超时就可以认定网络发生了拥塞,那就需要减小窗口大小了)
发送方维护一个拥塞窗口cwnd对发送方的发送速率进行限制,发送方发送窗口大小=Math.min(拥塞窗口大小,接收方接收窗口大小)
发送方会控制发送方发送到连接中但是还没有被接收方确认的数据量
拥塞控制算法:慢开始,拥塞避免,快重传,快恢复
只要网络不堵,我就尽可能去发,如果网络堵,我就减小窗口,这样速率就慢了
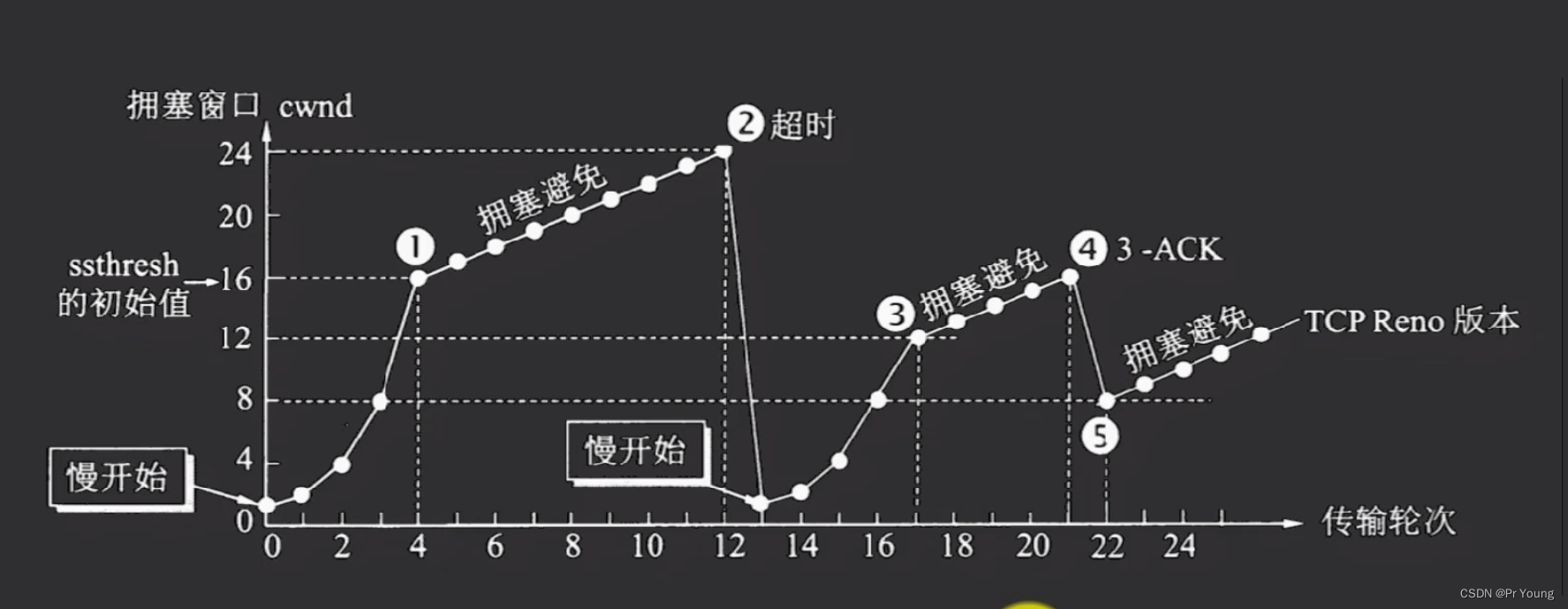
慢开始:开始摸不准网络是否堵塞的情况,那就由小到大逐渐增大窗口的值,如果当前窗口发送的报文全都收到了确认报文,那就将窗口大小乘二,也就是每次窗口大小乘2,所以窗口大小依次为1,2,4,8,16,当窗口大于阈值ssthresh(一般大小为16),就采取拥塞避免算法
拥塞避免算法也是去让拥塞窗口增大的,但是增大的速率没有增长那么快了,而是一个一个去增加的线性增长,直到到达网络拥塞的状态,这个时候就会发生超时,一旦发生超时,就可以认定为发生了网络堵塞,这个时候就把阈值ssthresh变成当前窗口的1/2(图里面当前窗口大小是24,所以阈值ssthresh变成12),,然后又开始使用慢开始算法,窗口又从1开始,1,2,4,8,12
总结:先慢开始,然后拥塞避免,然后又慢开始,然后又拥塞避免,然后又慢开始
快重传:尽可能让发送方知道个别报文段丢失了,要求接收方收到有序报文数据后,就立刻去发送确认报文
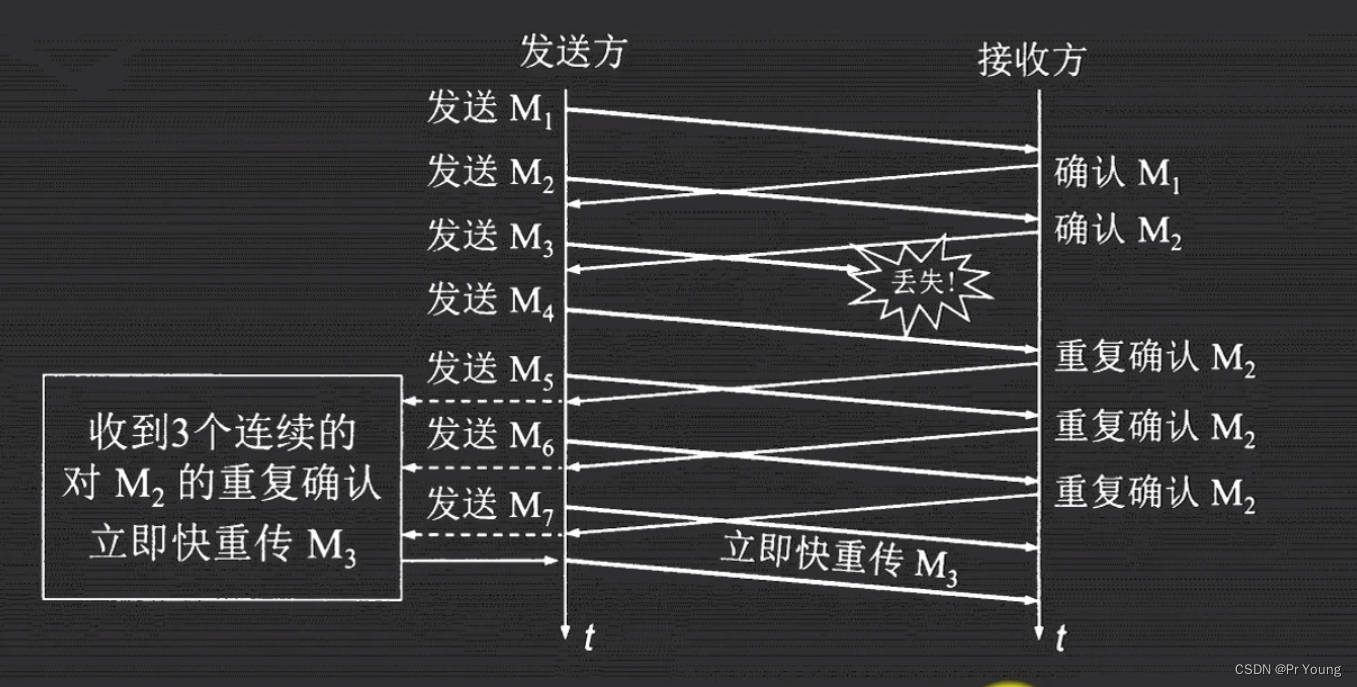
发送方发送M1报文,然后接收方发送一个M1确认报文给发送方
发送方发送M2报文,然后接收方发送一个M2确认报文给发送方
发送M3报文的时候,M3报文丢失了
然后发送方发送M4报文,然后接收方由于没有接收到M3报文,所以接收方还是给发送方发送M2确认报文
.......
如此发送方连续接收到3个异常的连续对M2的重复确认,触发快重传,于是立即重传M3数据报,
本来发送方会等一个超时时间,快速确认三次没有收到,然后马上重传,这个时间是会小于超时时间的
这里可以看到,横坐标为21的时候发生了3次重复确认,发生快重传,快重传之后阈值继续降低,并且从阈值开始(不用从1开始了)直接进入有拥塞避免,省去了慢开始的过程
发生快重传之后窗口大小迅速达到阈值,不用慢开始从1开始,就是快恢复
流量控制:控制发送方的发送速度过快,导致接收方来不及接收数据,缓存溢出,数据丢失
拥塞控制:由于网络自身拥堵,导致发送方的发送能力被遏制住
流量控制和拥塞控制都是对发送方进行控制的,前者是解决发送和接收速率不匹配的问题,后者是网络本身拥堵,发送方不得不采取速率控制来避免网络更加拥堵
拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素(而流量控制需要控制的是发送方和接收方两台主机即可)